




逆天 哥大华裔学生开发人脸机器人 表情超逼真(图)
研究人员将静止面部地标定义为前五帧的平均地标,目标面部地标则定义为与静止面部地标差异最大的地标。
静态面部地标的欧氏距离与其他帧的地标的欧氏距离会不断变化,并且可以区分。
因此,研究人员可以通过地标距离相对于时间的二阶导数来计算表情变化的趋势。
研究人员将表情变化加速度最大时的视频帧作为 “激活峰值”。
为了提高准确性并避免过度拟合,研究人员通过对周围帧的采样来增强每个数据。
具体来说,在训练过程中,预测模型的输入是从峰值激活前后总共九帧图像中任意抽取四帧图像。
同样,标签也是从目标脸部之后的四帧图像中随机取样的。
数据集共包含 45 名人类参与者和 970 个视频。其中 80% 的数据用于训练模型,其余数据用于验证。
研究人员对整个数据集进行了分析,得出人类通常做出面部表情所需的平均时间为 0.841 ± 0.713 秒。
预测模型和逆向模型(仅指研究人员论文中使用的神经网络模型的处理速度)在不带 GPU 设备的 MacBook Pro 2019 上的运行速度分别约为每秒 650 帧(fps)和 8000 帧(fps)。
这一帧频还不包括数据捕获或地标提取时间。
研究人员的机器人可以 0.002 秒内成功预测目标人类面部表情并生成相应的电机指令。这一时间留给捕捉面部地标和执行电机指令以在实体机器人面部生成目标面部表情的时间约为 0.839 秒。
为了定量评估预测面部表情的准确性,研究人员将研究人员的方法与两个基线进行了比较。
第一种基线是在逆模型训练数据集中随机选择一张图片作为预测对象。
该基线的数据集包含大量由咿呀学语产生的机器人表情图片。
第二条基线是模仿基线,它选择激活峰值处的面部地标作为预测地标。如果激活峰值接近目标脸部,那么该基线与研究人员的方法相比就很有竞争力。
然而,实验结果表明,研究人员的方法优于这一基线,表明预测模型通过归纳面部的细微变化,而不是简单地复制最后输入帧中的面部表情,成功地学会了预测未来的目标面部。
图 4B 显示了对预测模型的定量评估。
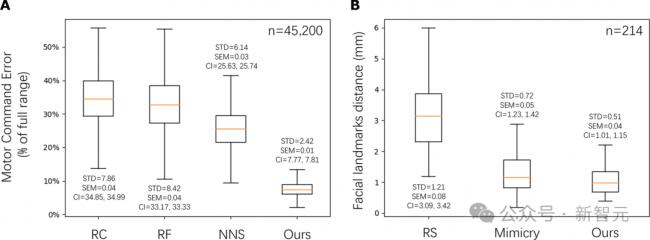
研究人员计算了预测地标与地面实况地标之间的平均绝对误差,地面实况地标由维度为 113×2 的人类目标面部地标组成。
表格结果(表 S2)表明,研究人员的方法优于两种基线方法,表现出更小的平均误差和更小的标准误差。
Emo 下一步:接入大模型
有了能够模拟预测人类表情的能力之后,Emo 研究的下一步便是将语言交流整合到其中,比如接入 ChatGPT 这样的大模型。
随着机器人的行为能力越来越像人类,团队也将关注背后伦理问题。
研究人员表示,通过发展能够准确解读和模仿人类表情的机器人,我们正在向机器人可以无缝地融入我们的日常生活的未来更近一步,为人类提供陪伴、帮助。
想象一下,在这个世界,与机器人互动就像与朋友交谈一样自然和舒适。
作者介绍
[物价飞涨的时候 这样省钱购物很爽]
这条新闻还没有人评论喔,等着您的高见呢
静态面部地标的欧氏距离与其他帧的地标的欧氏距离会不断变化,并且可以区分。
因此,研究人员可以通过地标距离相对于时间的二阶导数来计算表情变化的趋势。
研究人员将表情变化加速度最大时的视频帧作为 “激活峰值”。
为了提高准确性并避免过度拟合,研究人员通过对周围帧的采样来增强每个数据。
具体来说,在训练过程中,预测模型的输入是从峰值激活前后总共九帧图像中任意抽取四帧图像。
同样,标签也是从目标脸部之后的四帧图像中随机取样的。
数据集共包含 45 名人类参与者和 970 个视频。其中 80% 的数据用于训练模型,其余数据用于验证。
研究人员对整个数据集进行了分析,得出人类通常做出面部表情所需的平均时间为 0.841 ± 0.713 秒。
预测模型和逆向模型(仅指研究人员论文中使用的神经网络模型的处理速度)在不带 GPU 设备的 MacBook Pro 2019 上的运行速度分别约为每秒 650 帧(fps)和 8000 帧(fps)。
这一帧频还不包括数据捕获或地标提取时间。
研究人员的机器人可以 0.002 秒内成功预测目标人类面部表情并生成相应的电机指令。这一时间留给捕捉面部地标和执行电机指令以在实体机器人面部生成目标面部表情的时间约为 0.839 秒。
为了定量评估预测面部表情的准确性,研究人员将研究人员的方法与两个基线进行了比较。
第一种基线是在逆模型训练数据集中随机选择一张图片作为预测对象。
该基线的数据集包含大量由咿呀学语产生的机器人表情图片。
第二条基线是模仿基线,它选择激活峰值处的面部地标作为预测地标。如果激活峰值接近目标脸部,那么该基线与研究人员的方法相比就很有竞争力。
然而,实验结果表明,研究人员的方法优于这一基线,表明预测模型通过归纳面部的细微变化,而不是简单地复制最后输入帧中的面部表情,成功地学会了预测未来的目标面部。
图 4B 显示了对预测模型的定量评估。
研究人员计算了预测地标与地面实况地标之间的平均绝对误差,地面实况地标由维度为 113×2 的人类目标面部地标组成。
表格结果(表 S2)表明,研究人员的方法优于两种基线方法,表现出更小的平均误差和更小的标准误差。
Emo 下一步:接入大模型
有了能够模拟预测人类表情的能力之后,Emo 研究的下一步便是将语言交流整合到其中,比如接入 ChatGPT 这样的大模型。
随着机器人的行为能力越来越像人类,团队也将关注背后伦理问题。
研究人员表示,通过发展能够准确解读和模仿人类表情的机器人,我们正在向机器人可以无缝地融入我们的日常生活的未来更近一步,为人类提供陪伴、帮助。
想象一下,在这个世界,与机器人互动就像与朋友交谈一样自然和舒适。
作者介绍
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| 注: | 在此页阅读全文 |
推荐: