




英伟达发布会:黄仁勋晒”AI核弹“
举个例子,8000个GPU组成的GH100系统,90天内可以训练一个1.8万亿参数的GPT-Moe模型,功耗15兆瓦,而使用一套2000颗GPU的GB200NVL72加速卡,只需要4兆瓦。
据介绍,DGX版GB200NVL72加速计算平台AI训练性能(FP8精度计算)可达720PFLOPs(即每秒72亿亿次),FP4精度推理性能为1440PFLOPs(每秒144亿亿次)。官方称GB200的推理性能在Hopper平台的基础上提升6倍,尤其是采用相同数量的GPU,在万亿参数Moe模型上进行基准测试,GB200的性能是Hopper平台的30倍。
演讲环节,黄仁勋还公布了搭载64个800Gb/s端口、且配备RoCE自适应路由的NVIDIAQuantum-X800InfiniBand交换机,以及搭载144个800Gb/s端口,网络内计算性能达到14.4TFLOPs(每秒14.4万亿次)的Spectrum-X800交换机。两者应对的客户需求群体略有差异,如果追求超大规模、高性能可采用NVLink+InfiniBand网络;如果是多租户、工作负载多样性,需融入生成式AI,则用高性能Spectrum-X以太网架构。
另外,英伟达还推出了基于GB200的DGXSuperPod一站式AI超算解决方案,采用高效液冷机架,搭载8套DGXGB200系统,即288颗GraceCPU和576颗B200GPU,内存达到240TB,FP4精度计算性能达到11.5ELOPs(每秒11.5百亿亿次),相比上一代产品的推理性能提升30倍,训练性能提升4倍。
黄仁勋说,如果你想获得更多的性能,也不是不可以――发挥钞能力――在DGXSuperPod中整合更多的机架,搭载更多的DGXGB200加速卡。
02 NIM+NeMo:构建英伟达版企业用GPTs
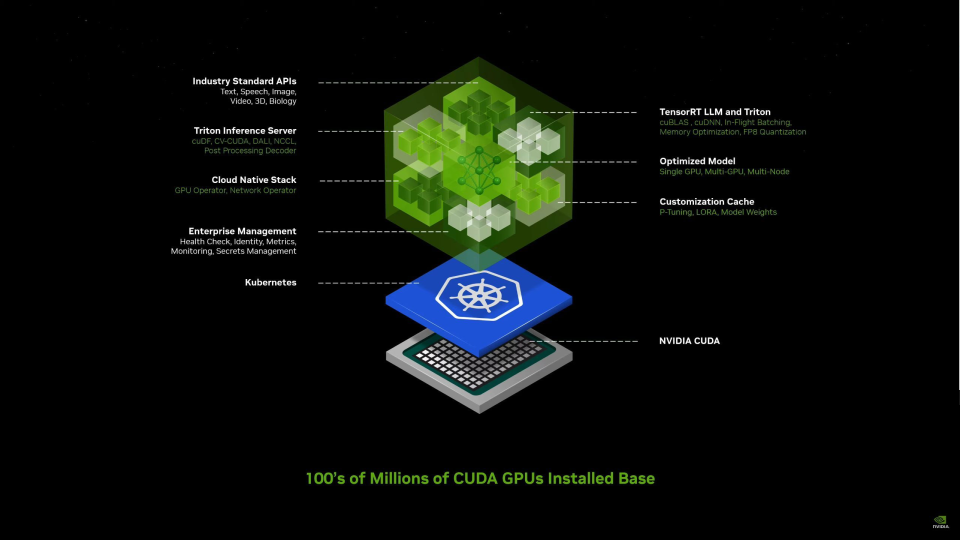
英伟达的另一个杀手锏就是它的软件,它构成了这一万亿帝国至少半条护城河。
诞生于2006年的CUDA被认为是英伟达在GPU上建立霸权的关键功臣――它使得GPU从调用GPU计算和GPU硬件加速第一次成为可能,让GPU拥有了解决复杂计算问题的能力。在它的加持下,GPU从图形处理器这一单一功能发展成了通用的并行算力设备,也因此AI的开发才有可能。
但谈论NVIDIA时,许多人都倾向于使用“CUDA”作为NVIDIA提供的所有软件的简写。这是一种误导,因为NVIDIA的软件护城河不仅仅是CUDA开发层,还包含了其上的一系列连通软硬件的软件程序,比如英伟达开发的用于运行C++推理框架,去兼容Pytorch等模型训练框架的TensorRT;使团队能够部署来自多个深度学习和机器学习框架的任何AI模型的TritonInferenceServer。
虽然有如此丰富的软件生态,但对于缺乏AI基础开发能力的传统行业来讲,这些分散的系统还是太难掌握。
看准了这个给传统企业赋能的赛道,在今天的发布会上,英伟达推出了集成过去几年所做的所有软件于一起的新的容器型微服务:NVIDIANIM。它集成到了不给中间商活路的地步,可以让传统企业直接简单部署完全利用自己数据的专属行业模型。

这一软件提供了一个从最浅层的应用软件到最深层的硬件编程体系CUDA的直接通路。构成GenAI应用程序的各种组件(模型、RAG、数据等)都可以完成直达NVIDIAGPU的全链路优化。
它让缺乏AI开发经验的传统行业可以通过在NVIDIA的安装基础上运行的经过打包和优化的预训练模型,一步到位部署AI应用,直接享受到英伟达GPU带来的最优部署时效,绕过AI开发公司或者模型公司部署调优的成本。Nvidia企业计算副总裁ManuvirDas表示,不久前,需要数据科学家来构建和部署这些类型的GenAI应用程序。但有了NIM,任何开发人员现在都可以构建聊天机器人之类的东西并将其部署给客户。
[物价飞涨的时候 这样省钱购物很爽]
这条新闻还没有人评论喔,等着您的高见呢
据介绍,DGX版GB200NVL72加速计算平台AI训练性能(FP8精度计算)可达720PFLOPs(即每秒72亿亿次),FP4精度推理性能为1440PFLOPs(每秒144亿亿次)。官方称GB200的推理性能在Hopper平台的基础上提升6倍,尤其是采用相同数量的GPU,在万亿参数Moe模型上进行基准测试,GB200的性能是Hopper平台的30倍。
演讲环节,黄仁勋还公布了搭载64个800Gb/s端口、且配备RoCE自适应路由的NVIDIAQuantum-X800InfiniBand交换机,以及搭载144个800Gb/s端口,网络内计算性能达到14.4TFLOPs(每秒14.4万亿次)的Spectrum-X800交换机。两者应对的客户需求群体略有差异,如果追求超大规模、高性能可采用NVLink+InfiniBand网络;如果是多租户、工作负载多样性,需融入生成式AI,则用高性能Spectrum-X以太网架构。
另外,英伟达还推出了基于GB200的DGXSuperPod一站式AI超算解决方案,采用高效液冷机架,搭载8套DGXGB200系统,即288颗GraceCPU和576颗B200GPU,内存达到240TB,FP4精度计算性能达到11.5ELOPs(每秒11.5百亿亿次),相比上一代产品的推理性能提升30倍,训练性能提升4倍。
黄仁勋说,如果你想获得更多的性能,也不是不可以――发挥钞能力――在DGXSuperPod中整合更多的机架,搭载更多的DGXGB200加速卡。
02 NIM+NeMo:构建英伟达版企业用GPTs
英伟达的另一个杀手锏就是它的软件,它构成了这一万亿帝国至少半条护城河。
诞生于2006年的CUDA被认为是英伟达在GPU上建立霸权的关键功臣――它使得GPU从调用GPU计算和GPU硬件加速第一次成为可能,让GPU拥有了解决复杂计算问题的能力。在它的加持下,GPU从图形处理器这一单一功能发展成了通用的并行算力设备,也因此AI的开发才有可能。
但谈论NVIDIA时,许多人都倾向于使用“CUDA”作为NVIDIA提供的所有软件的简写。这是一种误导,因为NVIDIA的软件护城河不仅仅是CUDA开发层,还包含了其上的一系列连通软硬件的软件程序,比如英伟达开发的用于运行C++推理框架,去兼容Pytorch等模型训练框架的TensorRT;使团队能够部署来自多个深度学习和机器学习框架的任何AI模型的TritonInferenceServer。
虽然有如此丰富的软件生态,但对于缺乏AI基础开发能力的传统行业来讲,这些分散的系统还是太难掌握。
看准了这个给传统企业赋能的赛道,在今天的发布会上,英伟达推出了集成过去几年所做的所有软件于一起的新的容器型微服务:NVIDIANIM。它集成到了不给中间商活路的地步,可以让传统企业直接简单部署完全利用自己数据的专属行业模型。
这一软件提供了一个从最浅层的应用软件到最深层的硬件编程体系CUDA的直接通路。构成GenAI应用程序的各种组件(模型、RAG、数据等)都可以完成直达NVIDIAGPU的全链路优化。
它让缺乏AI开发经验的传统行业可以通过在NVIDIA的安装基础上运行的经过打包和优化的预训练模型,一步到位部署AI应用,直接享受到英伟达GPU带来的最优部署时效,绕过AI开发公司或者模型公司部署调优的成本。Nvidia企业计算副总裁ManuvirDas表示,不久前,需要数据科学家来构建和部署这些类型的GenAI应用程序。但有了NIM,任何开发人员现在都可以构建聊天机器人之类的东西并将其部署给客户。
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| 注: | 在此页阅读全文 |
推荐: