




“Љ∞лГrЄсМНђF–‘ƒ№ƒлЙЇ »ю±г“Ћƒ£–ЌљMИF–Ієыу@»Ћ
“ЉВА√ыљ–°∞Їѕ≥…іуќчєѕ°±µƒ–°”ќСт‘шпL√““ЉХr£ђЋьµƒЌжЈ®Ї№ЇЖЖќ£ЇГ…оwѕаЌђµƒЋЃєы„≤‘Џ“Љ∆р£ђХю„Г≥…Єьіуµƒ“Љоw°£∆ѕћ—Їѕ≥…Щ—ћ“£ђЩ—ћ“Їѕ≥…йў„”£ђ„ољKƒњШЋ «Їѕ≥ц“Љоwќчєѕ°£
»зєы∞—я@ћ„яЙЁЛ∞бяM AI оI”т£ђХю∞l…ъ ≤ьN£њ
љь»’£ђ√јЗшіуƒ£–ЌЊџЇѕ∆љћ® OpenRouter ’жµƒ„ц≥цЅЋ“ЉВАƒ№°∞Їѕ≥…іу AI°±µƒЃa∆Ј£ђ√ыЮй Fusion°£‘Џїщ„ЉЬy‘З÷–£ђ»юВА÷–µ»Гrќїµƒƒ£–ЌљЫя^ Fusion µƒЇѕјнЊО≈≈£ђ„ољK±нђFѕµљy–‘µЎ≥ђя^ЅЋЌђ∆ЏЋщ”–Жќ“Љ∆м≈Юƒ£–Ќ°£ґш«“£ђ∞—»юВАЌђШ”µƒƒ£–ЌЇѕ‘Џ“Љ∆р£ђ∆дµ√Ј÷Њє“≤Єямґ‘≠ƒ£–ЌЖќ™Ъ„чірµƒљYєы°£
÷–йgМ”∆љћ®µƒ…ъіжљєС]£ђія…ъЅЋ Fusion
≥…ЅҐмґ 2023 ƒкµƒ OpenRouter£ђњВ≤њќїмґ√јЗшЉ~Љs£ђ «“ЉЉ“ћбє© AI ÷–йgМ”µƒ≥хДУєЂЋЊ°£
ДУ Љ»Ћ÷Ѓ“ЉБЖЪvњЋЋє°§∞ҐЋюј≠£®Alex Atallah£©‘ш‘Џ Palantir Уъ»ќє§≥ћОЯ£ђ2017 ƒк¬УЇѕДУёkЅЋ»Ђ«т÷™√ы NFT£®Ј«Ќђў|їѓіъО≈£©љї“„∆љћ® OpenSea°£Ѕн“Љќї¬УЇѕДУ Љ»Ћ¬Ј“„Ћє°§ЊS∆ж£®Louis Vichy£©Дt «“ЉќїяBјmДУШI’я£ђйL∆ЏМ£„Ґмґй_∞l’яє§Њя≈c∆љћ®М”Ѓa∆Ј°£
OpenRouter Юйй_∞l’яћбє©љy“Љ API ЊWкP£ђљ”»л≥ђ 400 ВАіу’Z—‘ƒ£–Ќ£ђЄ≤…w OpenAI°ҐAnthropic°Ґє»Єи°ҐKimi°ҐDeepSeek µ»÷ч“™ПS…ћ£ђ”ѓјыЈљ љ «≥й»° 5% µƒВтљр°£
Ую∆д≈ы¬ґФµУю£ђ≥…ЅҐ“‘Бн£ђ∆љћ®‘¬ѕыўMљро~“—Пƒ 2024 ƒк 10 ‘¬µƒЉs 80 »f√ј‘™‘цйL÷Ѕ 2025 ƒк 5 ‘¬Љs 800 »f√ј‘™£ђ∆љћ®√њ÷№¬Ј”… token о~ґ»“—я_ 25 »fГ|µљ 27 »fГ|ЅњЉЙ°£»ЏўYЈљ√ж£ђ≤їµљ»юƒк£ђOpenRouter “—ћ§»л™Ъљ«ЂF––Ѕ–°£
µЂ∆д„оіуµƒ…ћШIпLлU «±їј@я^£Ї“Љµ©ƒ≥Љ“о^≤њƒ£–Ќ‘Џƒ≥ВАИцЊ∞√чп@’ЉГЮ£ђй_∞l’яЌк»Ђњ…“‘÷±љ”љ”»л‘УПS…ћµƒ API£ђ≤ї±Ўо~Ќвѕт OpenRouter ÷ІЄґВтљр°£
ЮйС™М¶я@“Љќ£ЩC£ђFusion С™я\ґш…ъ°£ЋыВГ“™ћбє©Жќ“Љƒ£–Ќє©С™…ћґЉЯoЈ®ћбє©µƒњзПS…ћƒ£–ЌЕfЌђ°£
є¶ƒ№МНђFЇЌМНЬy±нђF
Fusion µƒЉ№ШЛіу÷¬»зѕ¬£Ї”√Сф‘Џ API ’И«у÷–÷Єґ®“ЉВА’{”√Јљƒ£–Ќ£ђ’{”√Јљƒ£–ЌЫQґ®ЖҐ”√ Fusion£ђѕµљyМҐћб Њ‘~£®prompt£©БK––Ј÷∞lљo»фО÷√ж∞еƒ£–Ќ£®panel models£©£ђ√њВАƒ£–ЌЌђХrЖҐ”√»юнЧЈюД’ґЋє§Њя£ђ∞ьј®ЊWнУЋ—ЋчЇЌЊWнУ„•»°£ђ“‘Љ∞ bash √ьЅоИћ––£®Linux ЇЌ macOS ѕµљy„о≥£”√µƒ√ьЅо––љвбМ∆ч£©°£
√ж∞еƒ£–ЌЄч„‘™ЪЅҐЌк≥…»ќД’бб£ђ“ЉВА≤√≈–ƒ£–Ќ£®judge model£©МҐ„x»°»Ђ≤њїЎір£ђЃa≥ц“ЉЈЁљYШЛїѓµƒ JSON£®“ЉЈNЌ®”√µƒФµУюљїУQЄс љ£©Ј÷ќц°£„обб‘ў”…’{”√Јљƒ£–Ќїщмґя@ЈЁЈ÷ќц„ЂМС„ољKір∞Є£ђ„ЂМСлAґќ≤ї‘ўЖҐ”√ЊWнУЋ—Ћчє§Њя°£‘Џƒђ’J«йЫrѕ¬£ђ≤√≈–ƒ£–ЌЇЌ’{”√Јљƒ£–Ќ «Ќђ“ЉВАƒ£–Ќ°£
’ыћ„Ѕч≥ћЈв—b‘ЏЈюД’∆чґЋ£ђй_∞l’я÷ї–иМҐƒ£–Ќ„÷ґќћоЮй°∞openrouter/fusion°±Љіњ…’{”√’ыћ„є§Њя£ђ√ж∞е≥…ЖT≈c≤√≈–ƒ£–ЌЊщњ…”…”√Сф„‘ґ®Ѕx°£
Юй±№√вЊО≈≈µƒЯoѕё«ґћ„£ђ√њіќГ»≤њ’И«уґЉХюФyОІ“ЉВА°∞x-openrouter-fusion-depth°±ШЋо^£ђ„и÷є√ж∞еƒ£–ЌЇЌ≤√≈–ƒ£–Ќ‘ўіќћ„Ќё љ’{”√ Fusion°£
ЅƒЌкЩC÷∆£ђFusion ‘Џїщ„ЉЬy‘З÷–µƒМНлH±нђF»зЇќ£њ
2026 ƒк 2 ‘¬£ђPerplexity й_‘іЅЋ“ЉнЧ√ыЮй DRACO µƒїщ„ЉЬy‘З£ђ∞ьЇђ 100 µј…оґ»—–Њњ»ќД’°£я@–©о}ƒњ‘імґ∆љћ® ’Љѓµƒ’жМН”√Сф’И«у£ђ‘uЈ÷ШЋ„ЉЄ≤…w ¬МН„Љі_–‘°ҐЈ÷ќцПVґ»≈c…оґ»°Ґ≥ ђFў|Ѕњ°Ґ“э”√ў|ЅњЋЅВАЊSґ»°£≤њЈ÷ШЋ„ЉОІ”–ЎУЩа÷Ў£ђƒ£–Ќ»зєы’fеeїтћбє©ќ£лUљ®„hЊЌХю±їњџЈ÷£ђя@„МЬР„÷ФµЋҐЈ÷µƒ≤я¬‘лy“‘„а–І°£
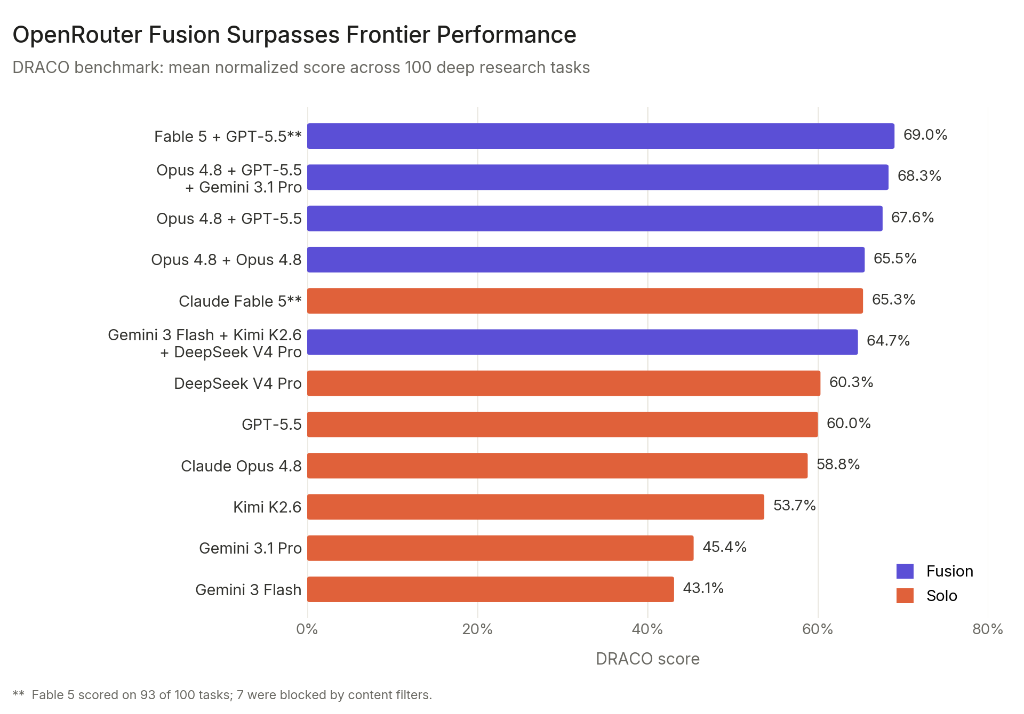
Fusion ‘Џ DRACO …ѕµƒЬy‘ЗљYєып@ Њ£ђFable 5 ≈c GPT-5.5 љM≥…µƒлp√ж∞е£®Їѕ≥…ƒ£–ЌЮй Claude Opus 4.8£©ƒ√µљЅЋ 69.0 Ј÷°£М¶±»÷Ѓѕ¬£ђFable 5 Жќ™Ъ„чірµ√µљ 65.3 Ј÷£ђЖќ™Ъµƒ GPT-5.5 « 60.0 Ј÷°£
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
Ї√–¬¬ДЫ]»Ћ‘u’У‘хьN––£ђќ“Бн’fО„Њд
»зєы∞—я@ћ„яЙЁЛ∞бяM AI оI”т£ђХю∞l…ъ ≤ьN£њ
љь»’£ђ√јЗшіуƒ£–ЌЊџЇѕ∆љћ® OpenRouter ’жµƒ„ц≥цЅЋ“ЉВАƒ№°∞Їѕ≥…іу AI°±µƒЃa∆Ј£ђ√ыЮй Fusion°£‘Џїщ„ЉЬy‘З÷–£ђ»юВА÷–µ»Гrќїµƒƒ£–ЌљЫя^ Fusion µƒЇѕјнЊО≈≈£ђ„ољK±нђFѕµљy–‘µЎ≥ђя^ЅЋЌђ∆ЏЋщ”–Жќ“Љ∆м≈Юƒ£–Ќ°£ґш«“£ђ∞—»юВАЌђШ”µƒƒ£–ЌЇѕ‘Џ“Љ∆р£ђ∆дµ√Ј÷Њє“≤Єямґ‘≠ƒ£–ЌЖќ™Ъ„чірµƒљYєы°£
÷–йgМ”∆љћ®µƒ…ъіжљєС]£ђія…ъЅЋ Fusion
≥…ЅҐмґ 2023 ƒкµƒ OpenRouter£ђњВ≤њќїмґ√јЗшЉ~Љs£ђ «“ЉЉ“ћбє© AI ÷–йgМ”µƒ≥хДУєЂЋЊ°£
ДУ Љ»Ћ÷Ѓ“ЉБЖЪvњЋЋє°§∞ҐЋюј≠£®Alex Atallah£©‘ш‘Џ Palantir Уъ»ќє§≥ћОЯ£ђ2017 ƒк¬УЇѕДУёkЅЋ»Ђ«т÷™√ы NFT£®Ј«Ќђў|їѓіъО≈£©љї“„∆љћ® OpenSea°£Ѕн“Љќї¬УЇѕДУ Љ»Ћ¬Ј“„Ћє°§ЊS∆ж£®Louis Vichy£©Дt «“ЉќїяBјmДУШI’я£ђйL∆ЏМ£„Ґмґй_∞l’яє§Њя≈c∆љћ®М”Ѓa∆Ј°£
OpenRouter Юйй_∞l’яћбє©љy“Љ API ЊWкP£ђљ”»л≥ђ 400 ВАіу’Z—‘ƒ£–Ќ£ђЄ≤…w OpenAI°ҐAnthropic°Ґє»Єи°ҐKimi°ҐDeepSeek µ»÷ч“™ПS…ћ£ђ”ѓјыЈљ љ «≥й»° 5% µƒВтљр°£
Ую∆д≈ы¬ґФµУю£ђ≥…ЅҐ“‘Бн£ђ∆љћ®‘¬ѕыўMљро~“—Пƒ 2024 ƒк 10 ‘¬µƒЉs 80 »f√ј‘™‘цйL÷Ѕ 2025 ƒк 5 ‘¬Љs 800 »f√ј‘™£ђ∆љћ®√њ÷№¬Ј”… token о~ґ»“—я_ 25 »fГ|µљ 27 »fГ|ЅњЉЙ°£»ЏўYЈљ√ж£ђ≤їµљ»юƒк£ђOpenRouter “—ћ§»л™Ъљ«ЂF––Ѕ–°£
µЂ∆д„оіуµƒ…ћШIпLлU «±їј@я^£Ї“Љµ©ƒ≥Љ“о^≤њƒ£–Ќ‘Џƒ≥ВАИцЊ∞√чп@’ЉГЮ£ђй_∞l’яЌк»Ђњ…“‘÷±љ”љ”»л‘УПS…ћµƒ API£ђ≤ї±Ўо~Ќвѕт OpenRouter ÷ІЄґВтљр°£
ЮйС™М¶я@“Љќ£ЩC£ђFusion С™я\ґш…ъ°£ЋыВГ“™ћбє©Жќ“Љƒ£–Ќє©С™…ћґЉЯoЈ®ћбє©µƒњзПS…ћƒ£–ЌЕfЌђ°£
є¶ƒ№МНђFЇЌМНЬy±нђF
Fusion µƒЉ№ШЛіу÷¬»зѕ¬£Ї”√Сф‘Џ API ’И«у÷–÷Єґ®“ЉВА’{”√Јљƒ£–Ќ£ђ’{”√Јљƒ£–ЌЫQґ®ЖҐ”√ Fusion£ђѕµљyМҐћб Њ‘~£®prompt£©БK––Ј÷∞lљo»фО÷√ж∞еƒ£–Ќ£®panel models£©£ђ√њВАƒ£–ЌЌђХrЖҐ”√»юнЧЈюД’ґЋє§Њя£ђ∞ьј®ЊWнУЋ—ЋчЇЌЊWнУ„•»°£ђ“‘Љ∞ bash √ьЅоИћ––£®Linux ЇЌ macOS ѕµљy„о≥£”√µƒ√ьЅо––љвбМ∆ч£©°£
√ж∞еƒ£–ЌЄч„‘™ЪЅҐЌк≥…»ќД’бб£ђ“ЉВА≤√≈–ƒ£–Ќ£®judge model£©МҐ„x»°»Ђ≤њїЎір£ђЃa≥ц“ЉЈЁљYШЛїѓµƒ JSON£®“ЉЈNЌ®”√µƒФµУюљїУQЄс љ£©Ј÷ќц°£„обб‘ў”…’{”√Јљƒ£–Ќїщмґя@ЈЁЈ÷ќц„ЂМС„ољKір∞Є£ђ„ЂМСлAґќ≤ї‘ўЖҐ”√ЊWнУЋ—Ћчє§Њя°£‘Џƒђ’J«йЫrѕ¬£ђ≤√≈–ƒ£–ЌЇЌ’{”√Јљƒ£–Ќ «Ќђ“ЉВАƒ£–Ќ°£
’ыћ„Ѕч≥ћЈв—b‘ЏЈюД’∆чґЋ£ђй_∞l’я÷ї–иМҐƒ£–Ќ„÷ґќћоЮй°∞openrouter/fusion°±Љіњ…’{”√’ыћ„є§Њя£ђ√ж∞е≥…ЖT≈c≤√≈–ƒ£–ЌЊщњ…”…”√Сф„‘ґ®Ѕx°£
Юй±№√вЊО≈≈µƒЯoѕё«ґћ„£ђ√њіќГ»≤њ’И«уґЉХюФyОІ“ЉВА°∞x-openrouter-fusion-depth°±ШЋо^£ђ„и÷є√ж∞еƒ£–ЌЇЌ≤√≈–ƒ£–Ќ‘ўіќћ„Ќё љ’{”√ Fusion°£
ЅƒЌкЩC÷∆£ђFusion ‘Џїщ„ЉЬy‘З÷–µƒМНлH±нђF»зЇќ£њ
2026 ƒк 2 ‘¬£ђPerplexity й_‘іЅЋ“ЉнЧ√ыЮй DRACO µƒїщ„ЉЬy‘З£ђ∞ьЇђ 100 µј…оґ»—–Њњ»ќД’°£я@–©о}ƒњ‘імґ∆љћ® ’Љѓµƒ’жМН”√Сф’И«у£ђ‘uЈ÷ШЋ„ЉЄ≤…w ¬МН„Љі_–‘°ҐЈ÷ќцПVґ»≈c…оґ»°Ґ≥ ђFў|Ѕњ°Ґ“э”√ў|ЅњЋЅВАЊSґ»°£≤њЈ÷ШЋ„ЉОІ”–ЎУЩа÷Ў£ђƒ£–Ќ»зєы’fеeїтћбє©ќ£лUљ®„hЊЌХю±їњџЈ÷£ђя@„МЬР„÷ФµЋҐЈ÷µƒ≤я¬‘лy“‘„а–І°£
Fusion ‘Џ DRACO …ѕµƒЬy‘ЗљYєып@ Њ£ђFable 5 ≈c GPT-5.5 љM≥…µƒлp√ж∞е£®Їѕ≥…ƒ£–ЌЮй Claude Opus 4.8£©ƒ√µљЅЋ 69.0 Ј÷°£М¶±»÷Ѓѕ¬£ђFable 5 Жќ™Ъ„чірµ√µљ 65.3 Ј÷£ђЖќ™Ъµƒ GPT-5.5 « 60.0 Ј÷°£
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
| Ј÷ѕн: |
| „Ґ£Ї | ‘ЏіЋнУйЖ„x»Ђќƒ |
| —”…мйЖ„x |
Ќ∆Ћ]: