



75% 毛利背后:英伟达其实是一家软件公司
数据中心GPU算力营收604亿美元,同比增长77%。但网络营收148亿美元,同比增长199%,增速是GPU的2.6倍,占数据中心总营收比例从去年同期的约12%升至约20%。
客户采购的不只是GPU,而是NVLink(芯片间高速互联技术)、InfiniBand和Spectrum-X构成的全栈系统。据多家媒体报道,主要超大规模客户正在以极快的速度部署GB200 NVL72机架――将72颗GPU、NVLink交换机和液冷封装为一体。一旦采用,其数据中心的计算、存储、网络全部纳入英伟达技术体系。据CFO Kress在电话会中披露,Spectrum-X以太网平台“规模已超过所有以太网同类竞争对手的总和”――在开放标准的以太网领域,英伟达凭借CUDA对网络通信的加速优化取得了超越硬件参数的市场地位。CUDA在网络层面也在发挥作用,而不仅限于GPU计算。
另一个有价值的观察是采购的承诺周期在拉长。据电话会披露,截至Q1末供应保障总额(含库存、采购承诺和预付款)增至约1450亿美元。GTC 2026上,管理层将Blackwell和Rubin平台累计需求展望上修至2027年底约1万亿美元。客户押注的不只是某一代芯片,而是一个由CUDA统一的全栈平台。
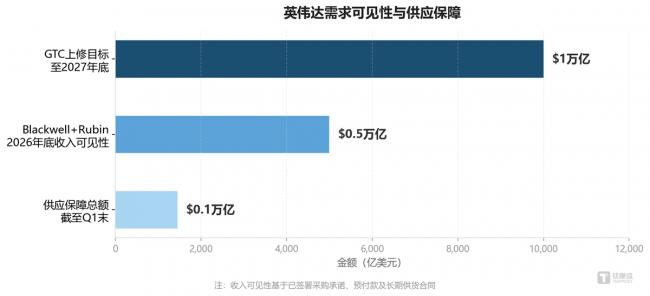
图:英伟达需求可见性与供应保障(亿美元) 数据来源:英伟达FY27 Q1财报、GTC 2026
旧硬件升值:纯硬件逻辑无法解释的现象
电话会中一组数据值得细读:H100租用价格年初至今上涨20%,A100云端定价涨15%。
H100基于2022年Hopper架构,Blackwell已贡献数据中心计算收入约七成,下一代Blackwell Ultra架构样片已开始向客户交付。正常硬件迭代中,新一代上市意味着旧代价格暴跌。英伟达出现了相反趋势。
Kress将此归因于“平台的多样性”和“软件栈带来的持续性能提升”。据MLPerf v6.0官方基准测试结果,Blackwell Ultra在Server场景下DeepSeek-R1推理速度较上一代提升2.77倍。这一性能飞跃来自英伟达所强调的“极致协同设计”――硬件架构、CUDA软件栈与模型的联合优化。
需要考虑的反面解释是:旧硬件升值是否仅仅因为AI算力总需求爆发?这个因素存在,但同一时期其他厂商的旧代GPU并未出现类似升值。H100涨价的特殊性在于,CUDA生态在过去四年中持续为这块硬件扩展新的应用场景和性能空间,使其在折旧期满后仍然具备经济价值。
不妨类比iPhone的旧机型保值逻辑――原因不是硬件折旧更慢,而是iOS生态为旧设备持续提供系统更新,延长了经济生命周期。英伟达正在GPU领域复现同样逻辑。在纯硬件框架中,折旧期满的资产趋于残值;在CUDA框架中,软件迭代持续为旧硬件注入新价值。这是支持“软件定义”论点的最具说服力的单项证据。
对CUDA锁定效应的一个常见质疑是:它是否主要局限于训练阶段?
本季度信号偏积极但不绝对。推理已成为增长主引擎,Blackwell被定义为“推理环节单位token成本最低的平台”。Dynamo 1.0作为英伟达面向大规模分布式推理的生产级系统,与TensorRT-LLM(推理加速库)等优化工具协同,将Blackwell推理效率大幅提升。Blackwell Ultra在MLPerf推理测评中横扫全部基准。
更重要的是,推理场景对软件优化的敏感度远高于训练:涉及长尾模型部署、延迟敏感型应用和成本效率优化,恰恰是CUDA推理工具链最擅长的领域。TensorRT-LLM对大模型推理的优化深度,以及Triton编译器对自定义算子的支持,构成了短期内难以复制的工程壁垒。
但目前的证据尚不足以得出“客户在推理端无法离开CUDA”的确定性结论。Google TPU在内部推理中运行良好,Groq的SRAM架构在特定场景具备竞争力,自研ASIC(专用芯片)在超大规模厂商中持续扩大部署。CUDA在推理端的优势更像是“当前最优解”而非“唯一解”。不过,本季度边缘计算动态几乎全部围绕CUDA展开:自动驾驶平台DRIVE Hyperion(比亚迪、吉利、日产等已采用)、机器人框架Isaac GR00T N等。从云端到物理世界,CUDA正在将推理依赖从单一场景扩展到全场景。
[物价飞涨的时候 这样省钱购物很爽]
无评论不新闻,发表一下您的意见吧
客户采购的不只是GPU,而是NVLink(芯片间高速互联技术)、InfiniBand和Spectrum-X构成的全栈系统。据多家媒体报道,主要超大规模客户正在以极快的速度部署GB200 NVL72机架――将72颗GPU、NVLink交换机和液冷封装为一体。一旦采用,其数据中心的计算、存储、网络全部纳入英伟达技术体系。据CFO Kress在电话会中披露,Spectrum-X以太网平台“规模已超过所有以太网同类竞争对手的总和”――在开放标准的以太网领域,英伟达凭借CUDA对网络通信的加速优化取得了超越硬件参数的市场地位。CUDA在网络层面也在发挥作用,而不仅限于GPU计算。
另一个有价值的观察是采购的承诺周期在拉长。据电话会披露,截至Q1末供应保障总额(含库存、采购承诺和预付款)增至约1450亿美元。GTC 2026上,管理层将Blackwell和Rubin平台累计需求展望上修至2027年底约1万亿美元。客户押注的不只是某一代芯片,而是一个由CUDA统一的全栈平台。
图:英伟达需求可见性与供应保障(亿美元) 数据来源:英伟达FY27 Q1财报、GTC 2026
旧硬件升值:纯硬件逻辑无法解释的现象
电话会中一组数据值得细读:H100租用价格年初至今上涨20%,A100云端定价涨15%。
H100基于2022年Hopper架构,Blackwell已贡献数据中心计算收入约七成,下一代Blackwell Ultra架构样片已开始向客户交付。正常硬件迭代中,新一代上市意味着旧代价格暴跌。英伟达出现了相反趋势。
Kress将此归因于“平台的多样性”和“软件栈带来的持续性能提升”。据MLPerf v6.0官方基准测试结果,Blackwell Ultra在Server场景下DeepSeek-R1推理速度较上一代提升2.77倍。这一性能飞跃来自英伟达所强调的“极致协同设计”――硬件架构、CUDA软件栈与模型的联合优化。
需要考虑的反面解释是:旧硬件升值是否仅仅因为AI算力总需求爆发?这个因素存在,但同一时期其他厂商的旧代GPU并未出现类似升值。H100涨价的特殊性在于,CUDA生态在过去四年中持续为这块硬件扩展新的应用场景和性能空间,使其在折旧期满后仍然具备经济价值。
不妨类比iPhone的旧机型保值逻辑――原因不是硬件折旧更慢,而是iOS生态为旧设备持续提供系统更新,延长了经济生命周期。英伟达正在GPU领域复现同样逻辑。在纯硬件框架中,折旧期满的资产趋于残值;在CUDA框架中,软件迭代持续为旧硬件注入新价值。这是支持“软件定义”论点的最具说服力的单项证据。
对CUDA锁定效应的一个常见质疑是:它是否主要局限于训练阶段?
本季度信号偏积极但不绝对。推理已成为增长主引擎,Blackwell被定义为“推理环节单位token成本最低的平台”。Dynamo 1.0作为英伟达面向大规模分布式推理的生产级系统,与TensorRT-LLM(推理加速库)等优化工具协同,将Blackwell推理效率大幅提升。Blackwell Ultra在MLPerf推理测评中横扫全部基准。
更重要的是,推理场景对软件优化的敏感度远高于训练:涉及长尾模型部署、延迟敏感型应用和成本效率优化,恰恰是CUDA推理工具链最擅长的领域。TensorRT-LLM对大模型推理的优化深度,以及Triton编译器对自定义算子的支持,构成了短期内难以复制的工程壁垒。
但目前的证据尚不足以得出“客户在推理端无法离开CUDA”的确定性结论。Google TPU在内部推理中运行良好,Groq的SRAM架构在特定场景具备竞争力,自研ASIC(专用芯片)在超大规模厂商中持续扩大部署。CUDA在推理端的优势更像是“当前最优解”而非“唯一解”。不过,本季度边缘计算动态几乎全部围绕CUDA展开:自动驾驶平台DRIVE Hyperion(比亚迪、吉利、日产等已采用)、机器人框架Isaac GR00T N等。从云端到物理世界,CUDA正在将推理依赖从单一场景扩展到全场景。
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| Note: | _VIEW_NEWS_FULL |
| 延伸阅读 |
 大温软件公司入选最佳雇主 正招聘 大温软件公司入选最佳雇主 正招聘 |
不靠软件的美国软件公司日赚$5亿 遭做空机构盯上 |
| 锡安国家公园:40岁软件公司CEO 攀岩坠深谷不治… |
美软件公司黑客勒索,波及上千企业 |
| 美防毒软件公司始创人 涉诈骗投资 |
丰田投3000亿建智能化软件公司 |
| 华裔税务软件公司 洗脱欺诈罪名 (1条评论) |
招揽人才 Facebook收购温哥华软件公司 |
| IBM收购加国软件公司 华裔科学家创办 (3条评论) |
推荐: