




[сRЋєњЋ] сRЋєњЋ OpenAI Anthropic»ЂґҐ…ѕЌђ“ЉЉю ¬ AIЊёо^ЉѓуwёDѕт
1.
OpenAI µƒГ…іуЋёФ≥ Anthropic ЇЌсRЋєњЋ£ђЈ≈ѕ¬–ƒ÷–≥…“К÷ЃббљKмґ‘Џ‘¬≥хљY√ЋЅЋ°£
‘ЏіЋ÷Ѓ«∞£ђAnthropic ЇЌсRЋєњЋµƒкPѕµБK≤ї»Џ«Ґ£Їљсƒк 2 ‘¬£ђсRЋєњЋяА‘Џ„‘ЉЇµƒ X ў~ћЦ÷ЄЎЯ A …з°Єwoke°є°Є–∞РЇ°є°ЄЈі»ЋоР°є£®misanthropic£©£ђ’fя@Љ“єЂЋЊ°Є≥р“Хќƒ√ч°є°£
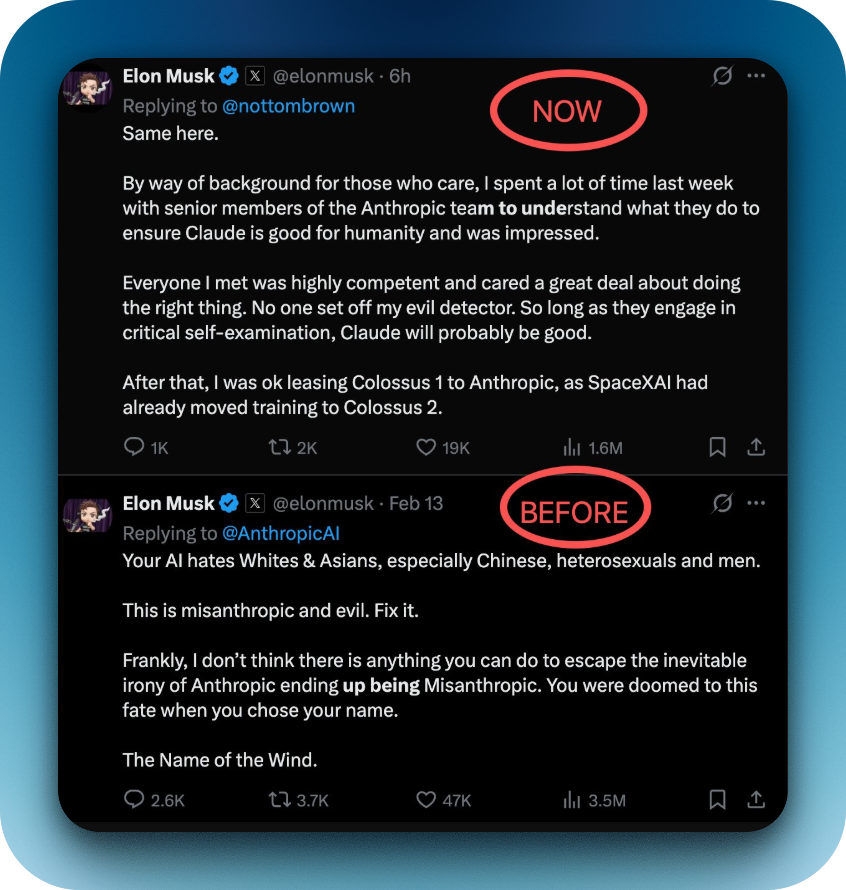
¬ббБнњі£ђя@іќє•УфБKЈ«сRЋєњЋ«е–¬√УЋ„µƒ–‘Єс є»ї£ђґш « Anthropic Ћщ„цµƒƒ≥–© ¬«й”|≈цµљЋыµƒ…сљЫ£ђ ¬≥ц”–“т°£
‘ЏіЋ÷Ѓ«∞£ђxAI Г»≤њ є”√ Cursor є§„ч£ђµЂ «љсƒкƒк≥хЖTє§∞lђF£ђClaude ƒ£–ЌЌї»ї‘Џ xAI µƒ Cursor єЂЋЊў~ћЦ—e≤їƒ№ є”√ЅЋ°£
ЃФХrяА‘Џ xAI …ѕ∞аµƒ¬УЇѕДУ Љ»ЋЕ«”оС—£ђ‘Џ»ЂЖT–≈—e «я@ьN’fµƒ£Ї°ЄAnthropic Єь–¬ЅЋ’ю≤я£ђ“™«у Cursor ≤їµ√ѕт∆д÷ч“™ЄВ†ОМ¶ ÷ћбє© Claude ƒ£–Ќ’{”√ƒ№Ѕ¶°£°є
ббБн£ђxAI ’ыВА¬УДУИFꆴЉ…ҐїпЅЋ£ђМНуw“≤Єъ SpaceX ЇѕБK£ђ≥…Юй°ЄSpaceXAI°є°£µЂЃФХr£ђЕ«”оС—‘Џ–≈÷–МСЅЋ“ЉЊд‘Т£ђоHЮй”–»§£Ї
°Єя@ «ЙƒѕыѕҐ“≤ «Ї√ѕыѕҐ°£ќ“ВГµƒ…ъЃaЅ¶Хю±ї”∞нС£ђµЂя@“≤ґЎіўќ“ВГй_∞l„‘ЉЇµƒЊОіaЃa∆ЈЇЌƒ£–Ќ°£°є
Юй ≤ьNЃФХr xAI µƒЄяМ”’JЮй£ђй_∞l„‘ЉЇµƒЊОіaЃa∆Ј «кPжI£њ

ббБн∞l…ъµƒ ¬«й£ђіуЉ“ґЉ÷™µјЅЋ°£xAI µƒ¬УДУИFк†ѕ§Фµ≈№¬Ј£ђсRЋєњЋ“ЉЪв÷Ѓѕ¬М¶ Cursor є”√ЅЋвnƒ№Ѕ¶±ЎЪҐ£Ї
…ѕВА‘¬µ„£ђSpaceX ЇЌ Cursor є≤Ќђ–ы≤Љ£ђМҐ‘ЏЊО≥ћЇЌ÷™„RоРє§„ч AI ƒ£–Ќµƒ”ЦЊЪ…ѕ£ђ’єй_«∞Ћщќі”–µƒС𬑯ѕ„ч£їБK«“£ђSpaceX яАЂ@µ√ЅЋ“‘ 600 Г|√ј‘™ ’ўП Cursor µƒЩајы£ђїтѕтбб’я÷ІЄґ 100 Г|√ј‘™Їѕ„чўM”√°£
„Ґ“вЊО≥ћя@ВАкPжIґ®’Z£ђбб√жяАХю call back.
2.
„ољь£ђќ“њіЅЋ“ЉЧl Cursor ‘з∆ЏЌґўY»Ћ°ҐAnthropic іуЗК„”°ҐT3 ДУ Љ»Ћ Theo Browne µƒ“Хоl°£
±ЊБньcяM»• «њіЋыЗК A …зЇЌ SpaceX ‘хьNѕЙ†IєЈєґ£ђљYєыЫ]ѕлµљ£ђЕsњіµљЅЋкPмґ SpaceX + Cursor Їѕ„чµƒ£ђ“ЉВАЉ»ЅноРЕs”÷ШOґ»ЇѕјнµƒЈ÷ќц£Ї
≤ї’f 600 Г|µƒ ’ўП£ђЊЌ÷ї’f 100 Г|µƒЇѕ„чўM°™°™Theo ‘Џ“Хоl—e±н Њ£ђ„‘ЉЇ’JЮй°Єƒƒ≈¬÷ї «љїУQµљ Cursor µƒ”√СфФµУю£ђя@ 100 Г|“≤÷µїЎ∆±ГrЅЋ°£°є
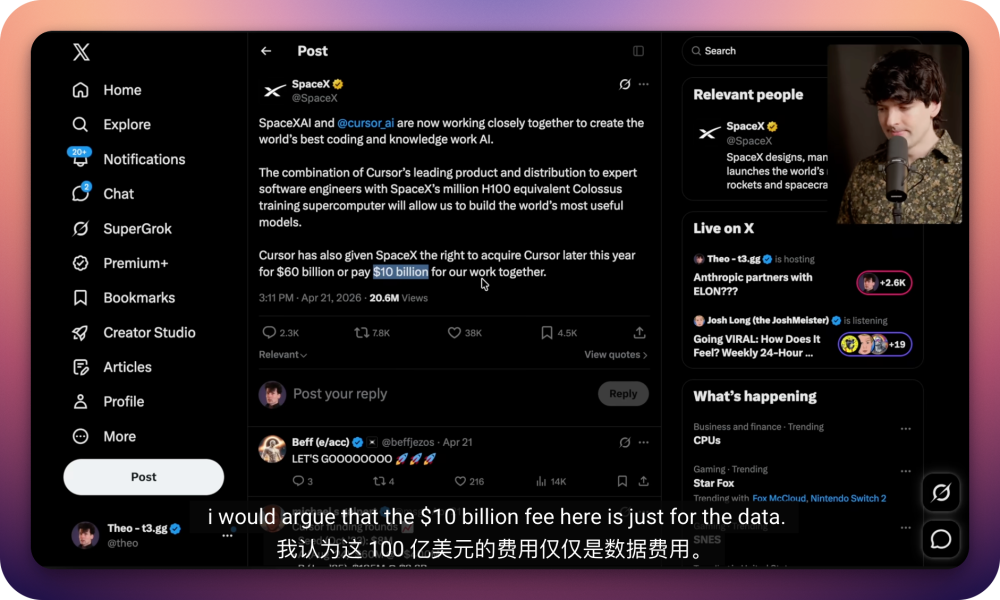
Ћщ“‘ « ≤ьNФµУю£њ»зєыƒг“≤»•њі Theo я@Чl“Хоl£ђЋыХю÷vµ√Ј«≥£«е≥ю°£µЂЮйЅЋєЭЉsХrйg£ђќ“ВГ‘Џя@—eЇЖЖќЄ≈ј®“Љѕ¬£Ї
ќ“ВГЇЌ AI µƒМ¶‘Т «“ЉБн“ЉїЎµƒ£ђƒгћб≥цЖЦо}/–и«у£ђЋьљoƒгљвір£їcoding agent Ќђјн£ђ÷ї≤їя^ЈµїЎµƒ «іъіa°£

“ЉіќЄяў|ЅњµƒМ¶‘Т£ђ’ыВАя^≥ћ£ђ∞ьј®”√Сфћб Њ°Ґƒ£–ЌЋЉњЉ°Ґagent “ОДЭ°ҐЁФ≥ціъіa°ҐтЮ„C°™°™Ћщ”–я@–©Ц|ќчЇѕ∆рБн£ђњ…“‘ЈQЮй“ЉВАЌк’ыµƒ Agentic Loop°™°™ЊЌ≥…ЮйЅЋЄяГr÷µµƒ”ЦЊЪФµУю£ђ‘ўќєљoƒ£–Ќ»•яM––ПКїѓМWЅХ£ђЊЌƒ№яM“Љ≤љћбЄяƒ£–Ќ‘ЏМНСрИцЊ∞ѕ¬µƒ±нђFЋЃ„Љ°£

Cursor ”–µƒ£ђSpaceX ѕл“™µƒ£ђЊЌ «я@–©ФµУю°£
њ…я@–©ФµУюПƒƒƒ—eБнƒЎ£њ
ір∞ЄЇ№ЇЖЖќ£Ї„чЮйƒ£–ЌПS…ћ£ђя@ЈNЄяў|ЅњФµУюµƒ„о÷±љ”Бн‘і£ђ÷їƒ№ «ƒг„‘ЉЇй_∞lµƒ coding agent Ѓa∆Ј°™°™“≤Љі Anthropic µƒ Claude Code°ҐOpenAI µƒ Codex°ҐKimi µƒ Kimi Code°£
ђF‘ЏƒгС™‘У√ч∞„ЅЋ£ђЮй ≤ьN±ї Anthropic°ЄЈвћЦ°є÷Ѓбб£ђЕ«”оС—Хю‘Џ»ЂЖT–≈—eћб≥цй_∞l xAI „‘ЉЇµƒ coding Ѓa∆ЈЇЌƒ£–Ќя@Љю ¬ЅЋ°£я@Љю ¬ xAI ‘ЏЃФХr“—љЫњі«е≥юЅЋ£Ї
Ы]”–„‘ЉЇµƒЊОіaЃa∆Ј£ђЊЌЫ]”–Єяў|ЅњµƒПКїѓМWЅХФµУю£їЫ]”–Єяў|ЅњµƒФµУю£ђЊЌ”ЦЊЪ≤ї≥ц’ж’эМНСрƒ№Ѕ¶ПКµƒ coding ƒ£–Ќ°£
лm»ї”–ьc±©’У£ђµЂђF‘Џќ“ВГњ…“‘ьcо}ЅЋ£Їƒ£–ЌПS…ћѕл„ц≥цБн’ж’эƒ№ітµƒЊО≥ћƒ£–Ќ£ђ„ц„‘ЉЇµƒ coding agent Ѓa∆Ј «ќ®“Љµƒ¬ЈПљ°£
3.
іу’Z—‘ƒ£–ЌѕсВАЋЃЊІ«т£ђ”√»ЂЊWµƒ’ZЅѕ”ЦЊЪ≥цБн£ђЋ∆Їхƒ№Йтљвір»fќп£ђµЂБK≤їіъ±нЋь‘ЏЋщ”–ЖЦо}…ѕґЉƒ№љo≥цЄяў|Ѕњµƒір∞Є°£
”√ GitHub …ѕФµ“‘Г|”ЛµƒіъіaЧlƒњ”ЦЊЪ£ђЃФ»ї“≤ƒ№”ЦЊЪ≥ц coding ƒ£–Ќ°£я@ «°ЄМWЅХљYєы°єµƒяЙЁЛ£ђ“≤ «Ы]ЖЦо}µƒ°£ЃЕЊєЊОіa»ќД’µƒљYєы «њ…“‘тЮ„Cµƒ£Їіъіaƒ№≤їƒ№я\––£ђЬy‘Зƒ№ЈсЌ®я^£ђљYєыФ[‘Џƒ«—e°£
µЂ «£ђЌ®ЌщљYєыµƒя^≥ћ£ђ «“ЉВА…жЉ∞ґа≤љуEЫQ≤я°Ґеe’`Љm’э°Ґ“вИDМ¶эRµƒПЌлsжЬЧl°£√њ“Љіќ”√Сфµƒљ” №°ҐЊ№љ^°Ґ—a»Ђ°Ґ≥ЈдN°Ґ„ЈЖЦ°Ґ…х÷ЅЃФƒ£–ЌЇ√О„іќґЉЄг≤їґ®їт’яЌк»ЂЄгеeХrµƒ»иЅR°™°™ґЉ «я@“ЉжЬЧl…ѕµƒя^≥ћ–≈ћЦ°£

ПКїѓМWЅХ”–Г…ЈN±OґљЈљ љ£ђ“ЉЈNљ–„цљYєы±Oґљ£ђ÷їњі„обб «Јс≈№Ќ®°£µЂ «љYєы±OґљХюія…ъ°Є™ДДоЇЏњЌ°єµƒђFѕу£Їƒ£–ЌЮйЅЋƒ№≈№Ќ®њ…ƒ№МС≥ц»я”а°Ґіа»х°ҐОІяЙЁЛ¬©ґіµƒіъіa£ђµЂ“тЮйЬy‘Зя^ЅЋ£ђƒ£–Ќ“‘Юй„‘ЉЇМWМ¶ЅЋ°£
ґшЅн“ЉЈNљ–„ця^≥ћ±Oґљ£ђМ¶Ќ∆јн¬ЈПљ…ѕµƒ√њ“Љ≤љяM––ітЈ÷°£…ѕ ця@–©я^≥ћ–≈ћЦ£ђ÷ї”–‘Џ coding agent я\––≠hЊ≥—e≤≈ƒ№’Q…ъ°£GitHub В}Ом—e÷ї”–љYєы£ђƒƒ≈¬ «»•њіЖќ™ЪµƒћбљїЪv Ј£ђњі PR£ђґЉ’“≤їµљ”––Іµƒя^≥ћ–≈ћЦ°£
‘Џ»±Ј¶”––І°Ґ„‘÷чњ…Ђ@µ√µƒя^≥ћ–≈ћЦµƒХrЇт£ђ“Љ–©ƒ£–ЌПS…ћХю≤…”√°Є’фрs°єµƒЈљ љ£ђя@ВА ¬«йіуЉ“С™‘У“—љЫ÷™µјЅЋ°£
’фрsµƒяЙЁЛЇ№ЇЖЖќ£ђљoЌђШ”µƒЁФ»л£ђјѕОЯƒ£–ЌЁФ≥ц ≤ьN£ђМW…ъƒ£–ЌЊЌМW÷шЁФ≥ц ≤ьN°£µЂ «Ќ®я^’фрs£ђЉі±гњ…“‘Ђ@»°µљЋЉЊSжЬ£ђµ√µљµƒ»‘»їЄьѕс «љYєы£ђґшЈ«±ї’фрsµƒјѕОЯƒ£–ЌГ»≤њµƒЄ≈¬ Ј÷≤Љ°£
“Љµ©МW…ъ‘ЏЌ∆јн÷–∆ЂлxЅЋјѕОЯµƒ№ЙџE£ђƒƒ≈¬“ЉВА token ≤їЈыЇѕ£ђґЉ”–њ…ƒ№∞l…ъ∆Ђлx°£

я@±≥бб «ПКїѓМWЅХµƒїщµAѕё÷∆£Ї≤я¬‘ћЁґ»ґ®јн“™«у£ђГЮїѓШ”±Њ„оЇ√”…ЃФ«∞’э‘ЏГЮїѓµƒƒ£–Ќ„‘ЉЇ»•Ѓa…ъ°£я@ЈNФµУюљ–„ц on-policy ФµУю°£ґшЌ®я^’фрsДeЉ“ƒ£–Ќ£ђ‘ЏДe»ЋµƒЃa∆Ј—eЃa…ъµƒФµУю£ђБн”ЦЊЪ„‘ЉЇƒ£–Ќ£ђґЉМўмґ off-policy ФµУю°£ƒ£–ЌЃФ»їњ…“‘Пƒ÷–МWµљЦ|ќч£ђµЂМW≤їµљјѕОЯƒ£–ЌГ»≤њµƒЄ≈¬ Ј÷≤Љ–≈ѕҐ°£
ґшѕс Cursor я@Ш”„‘ЉЇЊЌ « coding agent Ѓa∆ЈµƒєЂЋЊ£ђ’∆ќ’÷ш„о’жМН°Ґ”––І°ҐЄяў|Ѕњµƒ”ЦЊЪФµУю°£Cursor Ѓa∆Ј±Њ…н£ђЊЌ « coding ƒ£–Ќ‘ЏМНСр≠hЊ≥÷–µƒ„оЉ—”ЦЊЪИц°£
ќ“ВГњ…“‘Ќ®я^ Cursor ƒк≥хµƒ°ЄЈ≠№З°є£ђБн„C√чя@ВАяЙЁЛ°£
4.
APPSO „x’яС™‘У”Ыµ√£ђƒк≥х Cursor ∞l≤ЉЅЋ Composer 2£ђћЦЈQ°Єѕ¬“ЉіъМ£”√ЊО≥ћƒ£–Ќ°є£ђЉЉ–gИуµјМСµƒѕаМ¶±£ Ў£ђ„‘ИуЉ“йT «–¬ƒ£–Ќ£ђ“≤Ы]”–ћбє©Њяуwµƒƒ£–Ќµ„„щ–≈ѕҐ°£

љYєыЇ№њм£ђЊW”—ЊЌ‘ЏєЂй_іъіa∆ђґќ—e∞lђFЅЋ Kimi µƒƒ£–Ќ ID£ђљЎИDВч±йЅЋй_∞l’я…з»Ї£ђ±∆µ√ Cursor Є±њВ≤√ Lee Robinson ≥ц√ж≥ќ«е£Ї°ЄComposer 2 і_МН «Пƒй_‘іµ„„щ≥ц∞lµƒ°£„ољKƒ£–ЌіуЉs÷ї”– 1/4 µƒЋгЅ¶Бн„‘µ„„щ£ђ £ѕ¬ 3/4 «ќ“ВГ„‘ЉЇ”Ц≥цБнµƒ°£°єО„–°Хrбб£ђCursor ¬УДУ Aman Sanger “≤Єъ÷ш∞lЅЋ“ЉЧlµј«Є£Ї°Є“Љй_ ЉЫ]ћб Kimi µ„„щ «ВА І’`°£°є

ќйћмбб£ђCursor Ј≈≥цЅЋЌк’ыµƒ Composer 2 ЉЉ–gИуЄж£ђп@ Њµ„„щµƒі_ « Kimi K2.5£ђ ЏЩаЈљДt « Firworks AI£ђіу÷¬Ѕч≥ћ «‘Џ K2.5 …ѕ„ц”ЦЊЪ£ђ‘ўј^јm„ціу“Оƒ£ПКїѓМWЅХ£®RL£©°£
µЂкPжI÷ЃћО‘Џмґ£ђComposer 2 µƒ RL «я\––‘Џ’жМНµƒ Cursor Хю‘ТЃФ÷–£ђ є”√≈c…ъЃa≤њ рЌк»ЂѕаЌђµƒє§ЊяЇЌ harness°£
Cursor МҐя@ћ„Ѕч≥ћљ–„ц°ЄМНХrПКїѓМWЅХ°є(real-time RL)£ђ“≤ЉіМҐƒ£–Ќµƒ checkpoint ÷±љ”≤њ рµљ Cursor …ъЃa≠hЊ≥÷–£ђ”^≤м”√СфµƒнСС™£ђ ’ЉѓФµУю£ђЊџЇѕ≥…™ДДо–≈ћЦ£ђ„оњмњ…“‘√њ 5 ВА–°Хrµьіъ“Љіќƒ£–Ќ∞ж±Њ£ђ»їббј^јm≤њ рµљ Cursor —e£ђ—≠≠hЌщПЌ°£
„оШO÷¬µƒ∞Єјэ « Cursor µƒ„‘Д”їѓіъіa—a»Ђє¶ƒ№ Tab£ђ√њћмћОјн≥ђя^ 4 Г|іќ’И«у£ђ√њЃФ”√СфЁФ»л„÷Јы°Ґ“∆Д”євШЋХr£ђƒ£–ЌґЉХюоAЬyѕ¬“Љ≤љД”„ч£ђ»зєыоAЬy÷√–≈ґ»Єя£ђДtп@ Њљ®„h£ђ”√Сф∞іѕ¬ tab Љіљ” №„‘Д”—a»Ђ°£
‘Ує¶ƒ№≤…”√µƒ «‘ЏЊАПКїѓМWЅХ£ђ‘Џ––ШIГ»ШOЊяћЎ…Ђ°£Cursor њ…“‘“‘ШOЄяµƒоl¬ £®„оњмњ…я_√њ“ЉВА∞л–°ХrµљГ…–°Хr£©Єь–¬ Tab µƒƒ£–Ќƒ№Ѕ¶љo”√Сф£ђ÷±љ”‘ЏЃa∆ЈГ» ’Љѓ on-policy ФµУюяM––”ЦЊЪ°£
я@ЈNЄяоl°Ґљ”љьМНХrµƒЈірБїЎ¬Ј£ђ„М Tab њ…“‘МWЅХµљШO∆䝥√оµƒ”√Сф“вИD°£Cursor Јљ√жЌЄ¬ґ£ђя@ЈNЈљЈ®„М Tab љ®„hµƒЊ№љ^¬ љµµЌ 21%£ђљ” №¬ ћбЄяЅЋ 28%°£
їЎµљ Composer ƒ£–Ќ±Њ…н°£‘Џ ¬«йЄг«е≥юЅЋ÷Ѓбб£ђ“Љ–© Kimi ЖTє§“≤ДhµфЅЋ÷Ѓ«∞Ќ¬≤џµƒЌ∆ќƒ£ђKimi єўЈљў~ћЦ∞l±нЅЋ„£ўR°£
“ЉЉ“єј÷µ 600 Г|√ј‘™£®їщмґсRЋєњЋљoµƒФµ„÷£©£ђ≤ї„ц„‘ЉЇµƒƒ£–Ќїщ„щµƒ coding agent С™”√М”єЂЋЊ£ђ»‘»їњ…“‘Ќ®я^Ѓa∆Ј„‘…нµƒФµУюпwЁЖ£ђRL ≥ц≥ђ‘љїщ„щƒ£–ЌµƒМ£”–ЊО≥ћƒ£–Ќ°£
Ћщ“‘≈c∆д’f Cursor Ј≠ЅЋ№З£ђ≤ї»з’fя@Јіґш « coding agent Ѓa∆Ј÷Ў“™–‘µƒљ^Љ—јэ„C°£

Cursor ‘ЏЅн“Љ∆™кPмґМНХr RL µƒќƒ’¬—eМСµљ£Ї°Є£®”ЦЊЪЊО≥ћƒ£–Ќ£©„оіуµƒјІлy‘Џмґљ®ƒ£”√Сф°£Composer µƒ…ъЃa≠hЊ≥—e≤ї÷ї”–Ић––√ьЅоµƒ”ЛЋгЩC£ђяА”–±OґљЇЌ÷ЄМІЋьµƒ»Ћ°£ƒ£ФM”ЛЋгЩC»Ё“„£ђƒ£ФM є”√Ћьµƒ»ЋЕsЇ№лy°£°є
я@Њд‘Т£ђђF’э‘Џ÷рЭu≥…ЮйЅЋ‘ЏЊО≥ћƒ£–ЌЈљ√ж„я‘Џ«∞—Ўµƒƒ£–ЌПS…ћ÷Ѓйgµƒє≤„R°£»зєыƒг»•њі benchmark ∞сЖќЇЌ”√Сф∆’±й‘uГr£ђХю∞lђFƒ«–©о^≤њµƒПS…ћґЉ‘Џ∞lЅ¶„ц„‘ЉЇµƒ coding agent/ЊО≥ћЃa∆Ј°£Е^Дe÷ї‘Џмґ’lлx”√СфЄьљь°£
ќ“ВГ“‘ SWE-bench°ҐLLM-Stats µ»ѕаМ¶ЩаЌюµƒ∞сЖќЮйјэ£ђClaude°ҐGPT°ҐGemini°ҐKimi µ»ƒ£–Ќїщ±Њ∞‘∞с«∞ ∞£ђ«е“Љ…ЂґЉ «”–„‘ЉЇй_∞l coding agent Ѓa∆Ј£®∞ьј® CLI°ҐIDE°ҐЉѓ≥… coding agent µƒ„ј√жњЌСфґЋ£©µƒƒ£–ЌПS…ћ°£
‘Џ≤њЈ÷∞сЖќ…ѕХю≥цђF…ўФµЈіјэ£ђ»з Meta (Muse Spark)°ҐMinimax°ҐDeepSeek µ»£ђЫ]”–й_∞l„‘ЉЇµƒ coding agent°£
≤їя^ƒгХю∞lђF£ђя@–©Јіјэƒ£–Ќ£ђ‘ЏЄьЉ”љ”љь’жМНИцЊ∞°Ґ±№√вќџ»ЊµƒЄьЩаЌю benchmark …ѕЊЌЇ№лy…ѕ∞сЅЋ°£“‘ DeepSeek Юйјэ£ђЋь‘Џ SWE-bench bash only …ѕЈ÷Фµ « 70%£ђ≈≈√ыµЏЊ≈£ђ‘Џ SWE-bench Pro …ѕЈ÷ФµЕsµфµљЅЋ 15% „у”“°£
OpenRouter µƒ’жМНЅчЅњФµУюњ…“‘љвбМя@ЈNЈі≤о£Ї‘У∆љћ® 2025 ƒкИуЄжп@ Њ£ђClaude token ѕыўM 80% “‘…ѕ”√мґЊО≥ћЇЌЉЉ–g»ќД’£ђґш DeepSeek token ѕыўM÷ч“™Љѓ÷–мґйfЅƒЇЌљ«…Ђ∞з—Ё°£
Ы]”–„‘Љ“ coding Ѓa∆ЈµƒПS…ћ£ђ‘Џ“Љ–© coding »ќД’ benchmark …ѕƒ№ФDяMо^≤њ£ђµЂ‘ЏЄьлyµƒ’жМНє§≥ћ benchmark …ѕ£ђ‘Џ”√Сф”√ token ѕыўMЌґ∆±µƒ’жМНЅчЅњ÷–£ђґЉХю‘≠–ќЃЕ¬ґ°£
≤їГH « Cursor£ђAnthropic ‘Џ 2025 ƒк 11 ‘¬∞lµƒ“Љ∆™’Уќƒ—e£ђ“≤√чі_ЌЄ¬ґ„‘ЉЇ‘Џ„ц“Љƒ£“ЉШ”µƒ ¬«й£Ї°Єќ“ВГ‘Џ Anthropic „‘Љ“µƒ’жМН…ъЃaЊО≥ћ≠hЊ≥…ѕ„ц”ЦЊЪ°£°є“≤Љі Anthropic ∞—„‘ЉЇЖTє§ є”√ Claude Code µƒљїї•ФµУю£ђЈі≤Єљo Claude ƒ£–Ќ”√Бн”ЦЊЪ°£

5.
‘Џ AI µƒ—ЁяMЪv≥ћ÷–£ђ…ъЃa“™ЋЎµƒґ®Ѕx∞l…ъЅЋ…оњћµƒќї“∆°£Вчљy»юіуЇЋ–ƒ“™ЋЎ°™°™ЋгЅ¶°Ґ—–Њњ°Ґ”ЦЊЪФµУю£ђлm»ї‘ЏњВЅњ…ѕ≥÷јm‘цйL£ђµЂ‘ЏљYШЛ…ѕ“—љЫ≥цђFЅЋЗј÷Ўµƒ ІЇв°£
љсћмµƒЄчіу AI Њёо^п@÷шћбЄяЅЋ‘ЏЋгЅ¶…ѕµƒўY±Њ÷І≥ц (CapEx)£ђ„МЋгЅ¶їщљ®≥…ЮйЅЋЃФ«∞ЁЫ’Уµƒ÷ч–э¬…°£µЂМНлH…ѕ£ђћЎДe «‘ЏЊО≥ћЈґЃ†Г»£ђлS÷ш GitHub В}Ом°ҐStackOverflow µ»ї•¬УЊWєЂй_іъіaФµУю±їїщƒ£ПS…ћ°ЄљяЭ…ґшЭO°є љµЎјы”√£ђƒ£–Ќ‘Џіъіa…ъ≥…≈cяЙЁЛЌ∆јн…ѕµƒяЕљзй_ Љ÷рЭuп@ђF°£
я@“≤ «Юй ≤ьN£ђ––ШIє≤„R’э‘Џ÷рЭuёDѕт“ЉВА»љ»љ…э∆рµƒ–¬С𬑪яµЎ£ЇМ¶мґ»ќЇќѕ£Ќы’∆ќ’нФЉЙіъіaƒ№Ѕ¶µƒƒ£–ЌПS…ћґш—‘£ђљ®ЅҐ„‘”–µƒ coding agent Ѓa∆Ј‘з“—≤ї‘ў «њ…яxµƒ…ћШI¬ЈЊА£ђґш «і_±£µ„М”ƒ£–Ќњ…“‘≥÷јmяMїѓµƒЇЋ–ƒ…ъ√ьЊА°£
’э»з«∞√ж APPSO ’У„Cµƒƒ«Ш”£ђЖќЉГМWЅХєЂй_ФµУюµ»мґ÷їМWЅХ≥…є¶’яµƒљYЊ÷£ђЕsЯoЈ®ЅЋљв≥…є¶µƒ¬ЈПљ£ђя@љ^М¶≤ї «’эі_µƒ≥…є¶МWС™‘У”–µƒШ”„”°£‘Џ’жМНµƒЊО≥ћ≠hЊ≥÷–£ђ÷™µј∞l…ъЅЋ ≤ьNеe’`°Ґ‘хШ”∞l…ъµƒ°Ґ»зЇќ’эі_µЎјнљвЇЌЄя–ІµЎМНџ`–и«уµ»µ»°™°™ЅЋљв’эі_я^≥ћµƒГr÷µ£ђяh≥ђмґµ√µљ’эі_љYєы±Њ…н°£

÷ї”–Ун”–„‘ЉЇµƒЊОіaЃa∆Ј£ђƒ£–ЌПS…ћ≤≈ƒ№Ђ@»°Єяў|Ѕњµƒ°Єя^≥ћ±Oґљ°є–≈ћЦ£ђПƒґш‘ЏЊОіa/Ќ∆јнƒ№Ѕ¶µƒѕ¬“ЉлAґќЄВ†О÷–£ђі_±£„‘ЉЇ»‘”–ЉЉ–g„o≥«Ї”°™°™
ЈсДtЊЌ≤їµ√≤їѕс SpaceXAI ƒ«Ш”£ђї®еX»•Єъ coding agent Ѓa∆ЈєЂЋЊ»•Їѕ„ч°£»їґшБK≤ї «Ћщ”–ƒ£–ЌПS…ћґЉЄъсRЋєњЋ“ЉШ””–еX£ђ“‘Љ∞ 2026 ƒкй_ ЉµƒЊёо^ДЁЅ¶ДЭЈ÷°ҐљY√Ћ≈cоIµЎµƒ†ОґЈХю„Гµ√ЄьЉ”Љ§Ѕ“£ђЃФ“ЉЉ“»±Ј¶„‘÷ч coding Ѓa∆Јµƒƒ£–ЌПS…ћљKмґїЎя^ќґБнµƒХrЇт£ђњ÷≈¬“—љЫЫ]”–„гЙтµƒЇѕ„чїп∞йњ…“‘ћфяx£ђЇѕ„чµƒГrЄс“≤МҐЋЃЭqіђЄя°£
√јЗшƒ£–ЌЊёо^µƒ«йЫrіуЉ“∆’±й±»Ё^ мѕ§ЅЋ£ђ‘ЏіЋ≤їўШ ц°£APPSO “≤„Ґ“вµљ£ђЗшГ»µƒ÷чЅчƒ£–ЌПS…ћЇЌ AI Њёо^ЃФ÷–£ђљ^іу≤њЈ÷ґЉ“—љЫ‘Џ coding agent Ѓa∆Ј…ѕ”–Ћщ≤ЉЊ÷°£
ЗшГ»Њёо^єЂЋЊ÷ч“™“‘‘≠…ъ AI IDE їт IDE ≤еЉюµƒЋЉ¬Ј‘Џ„ц£Ї„÷єЭћшД”»•ƒкЇ№‘зЊЌ≤ЉЊ÷ЅЋ TRAE°Ґ∞Ґ—e∞Ќ∞Ќµƒ Qoder°Ґтv”Нµƒ CodeBuddy°Ґ∞ўґ»µƒќƒ–ƒњміa Comate µ»°£
AI –°эИєЂЋЊ÷–£ђ‘¬÷Ѓ∞µ√ж «„о‘зй_∞l™ЪЅҐ coding agent Ѓa∆ЈµƒєЂЋЊ£ђ÷ч“™“‘ CLI љз√жµƒ Kimi Code Юй÷ч°™°™≤їя^ Kimi іЋ«∞”–ЌЄ¬ґя^£ђ‘Џ‘≠…ъЊО≥ћЃa∆Јя@Љю ¬…ѕ£ђCLI ≤їХю «љKЊ÷°£

Ѕн“ЉЈNМНђFЋЉ¬Ј «ƒ£–ЌПS…ћ„‘––ћбє© API ЈюД’°ҐCoding Plan°£я@Ш”£ђ≤ї’У”√Сф є”√ЇќЈN AI й_∞l≠hЊ≥£ђƒ£–ЌПS…ћґЉњ…“‘Ќ®я^ЈюД’∆чґЋµƒ API ”ЫдЫБнЂ@»°„оіу≥ћґ»љ”љьмґ‘≠…ъ coding Ѓa∆Јµƒя^≥ћФµУю°£
µЂя@“≤÷ї «љ”љь£ђБKЈ«Ќк»ЂѕаЌђ°£ЇЋ–ƒ‘Џмґ£ђЈюД’∆чґЋ API µƒ’И«у-нСС™»’÷Њ£ђ≈c…оґ»«ґ»лµƒЃa∆Јљїї•№ЙџEѕа±»»‘”–Ї№іу≤оЊа°£
„‘љ®Ѓa∆ЈµƒПS…ћ£®јэ»з Cursor°ҐClaude „ј√жґЋ°ҐCodex£©Ун”–„о÷±љ”µƒп@ љЈірБ–≈ћЦ£ђґш API В» «ѕаМ¶ƒ£Їэµƒл[ љЌ∆Фа°£ЇЖЖќБн’f£ђAPI В»ƒ№њіµљ”√Сф’И«уЇЌнСС™£ђµЂ”√Сф„обб «Јс≤…Љ{ЅЋя@ґќіъіa°Ґіъіaƒ№Јс≈№Ќ®°Ґ“э∞lЅЋ ≤ьNШ”µƒ bug£ђAPI В»М¶іЋ «“ЉЯoЋщ÷™µƒ°£ЋыВГЯoЈ®ЅЋљвµљ”√Сф„ољK––Юйя@“ЉкPжIµƒШЋЇЮ£ђПƒґшЯoЈ®МНђF„оЄяў|ЅњµƒПКїѓМWЅХ°£
–ќґш…ѕБн÷v£ђ’Z—‘Љі јљз£ђіъіaЉіЈљ∞Є°£іъіaњ…“‘±ня_я@ВА јљз…ѕљ^іуґаФµµƒ»ќД’£ђіъіa“≤Хю≥…Юйо^≤њµƒЈ≈іу∆ч£ђ„М„онФЉвµƒ»Ћ≤≈Ј≈іуФµ±ґµƒ…ъЃaЅ¶°£
÷ї”–„онФЉвµƒ coding ƒ£–Ќ≤≈≈дµ√…ѕ„онФЉвµƒ»Ћ≤≈°£»зєыоIѕ»µƒƒ£–ЌПS…ћ≤ї÷Ў“Х coding£ђДЁ±ЎМҐХюµф≥цµЏ“ЉћЁк†°£
ЃФ»ї£ђ ¬МН…ѕ√њЉ“ƒ£–ЌПS…ћґЉ≤їХю≤ї÷Ў“Х coding°™°™ґш «’f£ђ‘Џ–¬µƒЈґ љѕ¬£ђƒ«–©Ы]”–„‘÷чњ…њЎµƒ‘≠…ъ coding agent Ѓa∆Ј£ђШO”–њ…ƒ№÷рЭu¬дббмґ”–Ѓa∆ЈµƒПS…ћ°£
ЊЌ‘Џ«∞О„ћм£ђMiniMax “≤∞l≤ЉЅЋ„ј√жњЌСфґЋЃa∆Јµƒ÷ЎіуЄь–¬£ЇОІ”–»Ђ–¬ґа agent ЊО≈≈Љ№ШЛµƒ Mavis є¶ƒ№£ђБK«““≤„МњЌСфґЋп@÷шЄƒ…∆ЅЋМ¶ coding »ќД’µƒ÷І≥÷°£
іЋ«∞ MiniMax ÷ї «Ќ∆≥цЅЋ„ј√жґЋ£ђµЂЫ]”–Љ”»л‘≠…ъ coding ЇЌ agent є¶ƒ№°£


Њoљ”÷ш£ђ‘Џ 5 ‘¬ 15 »’£ђ∞Ґ—e∞Ќ∞Ќ’э љ∞l≤ЉЅЋ Qoder 1.0°™°™я@ВАЃa∆ЈПƒ IDE µƒ–ќСB’э љ…эЉЙЮй“ЉВАЌк’ыµƒ Agent Ѓa∆Ј£®∞Ґ—eµƒєўЈљљ–Ј® «÷«ƒ№уw„‘÷чй_∞lє§„чћ®£©°£

≈cіЋЌђХr£ђxAI µƒ Grok Build CLI£ђ“≤љKмґ’э љЌ∆≥цЅЋ°£
Ы]еe£ђЊЌ « xAI ƒк≥х±ї Anthropic ЇЌ Cursor ЈвћЦ÷Ѓбб£ђЋыВГ„‘ЉЇУvєƒ≥цБнµƒƒ«ВА coding agent.

я@≤ї£ђ”÷ґаЅЋЇ√О„ВАђF≥…µƒ∞Єјэ°£
њіБн£ђіуЉ“ґЉ’JЮй Cursor°ҐCodex ЇЌ Claude „ј√жґЋ„я‘Џ’эі_µƒµј¬Ј…ѕ°£
6.
∞—‘То}Пƒ coding ФU’єµљ agent ±Њ…н£ђ«йЫr“≤ «“ЉШ”µƒ°£
ЊОіa»ќД’µƒ№ЙџEФµУю£ђ‘ЏєЂй_’ZЅѕ÷–і_МНяА «ƒ№’“µљ“Љ–©µƒ£®±»»з GitHub µƒћбљї”ЫдЫ/PR£ђ±Mє№ў|ЅњБK≤їЄя£©°£µЂ « agent »ќД’µƒ№ЙџEФµУю£ђ∞ьј®µЂ≤їѕёмґ“∆Д”ЇЌьcУф уШЋ°Ґ≤ўњЎ”|∆Ѕ°ҐћоМСЁФ»лњтµ»£ђЕsЯoЈ®‘ЏєЂй_’ZЅѕ÷–’“µљ°£
Ћщ“‘ќ“ВГХюњіµљ£ђЉі є‘Џ agent ≤ў„чµƒ„о–°МНђF¬ЈПљ°™°™Юg”[∆ч≤еЉю…ѕ£ђЉі±г «я@ьNВАњі∆рБн“ЉьcґЉ≤їЄяґЋµƒЦ|ќч£ђО„Їх√њЉ“ƒ£–ЌПS…ћґЉХю„ц„‘ЉЇµƒ°£
OpenAI ‘з‘Џ 2025 ƒк 1 ‘¬ЊЌ„цЅЋ Operator°™°™≈c∆д’fЋь «“ЉВА°ЄAI „‘Д”≤ў„чЮg”[∆ч°єµƒЃa∆Ј£ђ≤ї»з’f±Њў|…ѕЊЌ «“ЉВАіу“Оƒ£µƒФµУю ’Љѓ—b÷√°£√њ“Љќї‘З”√ Operator µƒ”√Сф£ђґЉ‘Џ√вўMЮй OpenAI ћбє© on-policy ФµУю°£
ббјm OpenAI яА—№…ъ≥ц ChatGPT Agent “‘Љ∞–¬∞ж Codex „ј√жґЋ£їAnthropic “≤ «Ќђјн£ї„ољь Kimi ≤ї¬Х≤їнСµЎ“≤„цЅЋ“ЉВАљ–„ц WebBridge µƒнЧƒњ£ђ∆дМНЊЌ «“ЉВАЮg”[∆ч≤еЉю°£

Љі±г «‘Џя^»•Г…ƒк—eД”„ч„оњЋ÷∆µƒ÷–Зшƒ£–ЌЊёо^…оґ»«уЋч£ђ“≤‘Џ„ољьй_ Љ’є¬ґ≥цМ¶ Agent µƒ≈d»§°£
CEO ЅЇќƒдhіЋ«∞љ” №≤…‘LХr‘шљЫћбµљя@Ш”µƒ”^ьc£ЇФµМWЇЌіъіa «AGIћм»їµƒ‘ЗтЮИц£ђ”–ьcѕсЗъ∆е£ђ «“ЉВАЈвй]µƒ°Ґњ…тЮ„Cµƒѕµљy£ђ”–њ…ƒ№Ќ®я^„‘ќ“МWЅХЊЌƒ№МНђFЇ№Єяµƒ÷«ƒ№°£
я@Њд‘ТµƒЭУћ®‘~£ђ « DeepSeek “Љ÷±∞— coding°ҐAgent ЃФ—–Њњ‘ЗтЮИц£ђґшЈ«…ћШIїѓЈљѕт°£
µЂ «‘Џљсƒк 3 ‘¬£ђDeepSeek “Љіќ–‘Ј≈≥цЅЋ ∞О„ВА Agent ѕакPНПќї£ђ∞ьј® „іќ≥цђFµƒƒ£–Ќ≤я¬‘Ѓa∆ЈљЫјн£®Agent Јљѕт£©µ»°£ЃФХrµƒ JD ¬ЪЎЯЇ≠…w°Є÷чМІ Agent ‘uЬyуwѕµ“‘Љ∞”ЦЊЪФµУюЈљ∞Єµƒ‘O”Л°є£ђ“™«у÷–∞ьј®°Є…оґ» є”√ Claude Code°ҐManus°єµ»Ѓa∆Ј°£
APPSO „Ґ“вµљ£ђљь∆Џ…оґ»«уЋч∞l≤ЉЅЋ Agent Ѓa∆ЈљЫјн°ҐHarness Ѓa∆ЈљЫјнµ»¬Ъќї’–∆Є–≈ѕҐ°™°™Ї№п@»ї£ђDeepSeek “™„ц™ЪЅҐ°Ґ‘≠…ъµƒ Coding/Agent Ѓa∆ЈЅЋ°£

іЋ«∞ўYЅѕп@ Њ£ђDeepSeek V3.2 µƒ”ЦЊЪя^≥ћ÷–“э»лЅЋљьГ…«ІВАЇѕ≥…µƒ Agent ”ЦЊЪ≠hЊ≥ЇЌ∞Ћ»fґаЧlПЌлs÷ЄЅо°£µЂ «њі∆рБн£ђњњЇѕ≥…µƒ”ЦЊЪФµУю÷їƒ№ОІ DeepSeek „яµљя@—eЅЋ£ђ £ѕ¬µƒ «Їѕ≥…≤ї≥цБнµƒ≤њЈ÷£Ї’жМН”√Сф‘Џ’жМН≠hЊ≥—eµƒ’жМН≥…є¶ЇЌ ІФ°£ђ±ЎнЪњњ„‘Љ“µƒ agent Ѓa∆Ј≤≈ƒ№ƒ√µљ°£
DeepSeek “‘“ЉЈNШOґ»њЋ÷∆µƒЈљ љ„цЅЋ»юƒкƒ£–Ќ“‘Љ∞ƒ£–ЌЃa∆Ј£®÷±µљ…ѕВА‘¬≤≈љKмґ‘ЏєўЊWЉ”»лЅЋґаƒ£СBƒ№Ѕ¶£©°£µЂ «‘ЏљсћмБнњі£ђ‘ЏЊОіaоР»ќД’…ѕ£ђDeepSeek ƒ√ SOTA ‘љБн‘љлyЅЋ£ђЉі±гіЋ«∞ƒ√µљ“≤Хю‘Џ≤їЊ√бб±ї≥ђ‘љ°£
ЃФ÷ъјн“јњњ—–Њњµƒ¬ЈПљ÷ІУќ≤ї„°пwЁЖµƒХrЇт£ђDeepSeek љKмґ––Д”ЅЋ°£
7.
„обб£ђќ“ВГїЎµљй_∆™µƒє ¬°£
ЄщУю The Information Иуµј‘Ѓ“э÷™«й»Ћ њИуµј£ђ‘Џљ” №сRЋєњЋ 600 Г| ’ўП/100 Г|√ј‘™Їѕ„чµƒЌђХr£ђCursor ±н Њ≤їХю≈c xAI Їѕ„чй_∞l–¬µƒƒ£–Ќ£ђґш «»‘МҐЊџљємґГЮїѓ„‘ЉЇµƒ Composer ƒ£–Ќ°£
я@“вќґ÷ш£ђЉі±г±їсRЋєњЋўIЌ®…х÷Ѕ ’ўП£ђCursor »‘»ї“™±£Ѕф„‘ЉЇФµУюпwЁЖµƒ÷чуw–‘°£
ФµУюЪwМўµƒ±Њ…н£ђ «„окPжIµƒл[≤Ў≤©ёƒьc°£
ЃФЋщ”–нФЉЙƒ£–ЌПS…ћґЉ„цЅЋ„‘ЉЇµƒЃa∆Ј£ђЋщ”–нФЉЙЃa∆Ј“≤ґЉй_ Љ”ЦЊЪ„‘ЉЇµƒƒ£–Ќ£ђ°Єƒ£–ЌєЂЋЊ°єЇЌ°ЄЃa∆ЈєЂЋЊ°єµƒ±ЊЊЌ≤їћЂ«е≥юµƒљзѕё£ђЋ∆Їх‘љБн‘љ≤їіж‘ЏЅЋ°≠°≠
я@Иц≤©ёƒ“≤≤≈ДВДВй_ Љ°£
ќƒ£ьґ≈≥њ
ЕҐњЉўYЅѕ£Ї
Theo - t3.gg: www.youtube.com/watch?v=3pkz-Ie_k_c
Composer 2 ЉЉ–gИуЄж£Їcursor.com/cn/blog/composer-2-technical-report
Anthropic ’Уќƒ£Їarxiv.org/abs/2511.18397
љYєы±Oґљ vs я^≥ћ±Oґљ£Ї www.emergentmind.com/topics/process-vs-outcome-supervision
ПКїѓМWЅХµƒ–≈ћЦ’`≤о£Їhttps://openreview.net/pdf?id=TDfrN1TbGH
кPмґ„‘љ® or ўПўIя^≥ћФµУюµƒ”С’У£Їhttps://www.reddit.com/r/AI_Agents/comments/1snc116/the_overlooked_trend_of_building_custom_ai_agents/
≤њЈ÷ИD∆ђЮй AI …ъ≥…
[ќпГrпwЭqµƒХrЇт я@Ш” °еXўПќпЇ№Ћђ]
Яo‘u’У≤ї–¬¬Д£ђ∞l±н“Љѕ¬ƒъµƒ“в“К∞…
OpenAI µƒГ…іуЋёФ≥ Anthropic ЇЌсRЋєњЋ£ђЈ≈ѕ¬–ƒ÷–≥…“К÷ЃббљKмґ‘Џ‘¬≥хљY√ЋЅЋ°£
‘ЏіЋ÷Ѓ«∞£ђAnthropic ЇЌсRЋєњЋµƒкPѕµБK≤ї»Џ«Ґ£Їљсƒк 2 ‘¬£ђсRЋєњЋяА‘Џ„‘ЉЇµƒ X ў~ћЦ÷ЄЎЯ A …з°Єwoke°є°Є–∞РЇ°є°ЄЈі»ЋоР°є£®misanthropic£©£ђ’fя@Љ“єЂЋЊ°Є≥р“Хќƒ√ч°є°£
¬ббБнњі£ђя@іќє•УфБKЈ«сRЋєњЋ«е–¬√УЋ„µƒ–‘Єс є»ї£ђґш « Anthropic Ћщ„цµƒƒ≥–© ¬«й”|≈цµљЋыµƒ…сљЫ£ђ ¬≥ц”–“т°£
‘ЏіЋ÷Ѓ«∞£ђxAI Г»≤њ є”√ Cursor є§„ч£ђµЂ «љсƒкƒк≥хЖTє§∞lђF£ђClaude ƒ£–ЌЌї»ї‘Џ xAI µƒ Cursor єЂЋЊў~ћЦ—e≤їƒ№ є”√ЅЋ°£
ЃФХrяА‘Џ xAI …ѕ∞аµƒ¬УЇѕДУ Љ»ЋЕ«”оС—£ђ‘Џ»ЂЖT–≈—e «я@ьN’fµƒ£Ї°ЄAnthropic Єь–¬ЅЋ’ю≤я£ђ“™«у Cursor ≤їµ√ѕт∆д÷ч“™ЄВ†ОМ¶ ÷ћбє© Claude ƒ£–Ќ’{”√ƒ№Ѕ¶°£°є
ббБн£ђxAI ’ыВА¬УДУИFꆴЉ…ҐїпЅЋ£ђМНуw“≤Єъ SpaceX ЇѕБK£ђ≥…Юй°ЄSpaceXAI°є°£µЂЃФХr£ђЕ«”оС—‘Џ–≈÷–МСЅЋ“ЉЊд‘Т£ђоHЮй”–»§£Ї
°Єя@ «ЙƒѕыѕҐ“≤ «Ї√ѕыѕҐ°£ќ“ВГµƒ…ъЃaЅ¶Хю±ї”∞нС£ђµЂя@“≤ґЎіўќ“ВГй_∞l„‘ЉЇµƒЊОіaЃa∆ЈЇЌƒ£–Ќ°£°є
Юй ≤ьNЃФХr xAI µƒЄяМ”’JЮй£ђй_∞l„‘ЉЇµƒЊОіaЃa∆Ј «кPжI£њ
ббБн∞l…ъµƒ ¬«й£ђіуЉ“ґЉ÷™µјЅЋ°£xAI µƒ¬УДУИFк†ѕ§Фµ≈№¬Ј£ђсRЋєњЋ“ЉЪв÷Ѓѕ¬М¶ Cursor є”√ЅЋвnƒ№Ѕ¶±ЎЪҐ£Ї
…ѕВА‘¬µ„£ђSpaceX ЇЌ Cursor є≤Ќђ–ы≤Љ£ђМҐ‘ЏЊО≥ћЇЌ÷™„RоРє§„ч AI ƒ£–Ќµƒ”ЦЊЪ…ѕ£ђ’єй_«∞Ћщќі”–µƒС𬑯ѕ„ч£їБK«“£ђSpaceX яАЂ@µ√ЅЋ“‘ 600 Г|√ј‘™ ’ўП Cursor µƒЩајы£ђїтѕтбб’я÷ІЄґ 100 Г|√ј‘™Їѕ„чўM”√°£
„Ґ“вЊО≥ћя@ВАкPжIґ®’Z£ђбб√жяАХю call back.
2.
„ољь£ђќ“њіЅЋ“ЉЧl Cursor ‘з∆ЏЌґўY»Ћ°ҐAnthropic іуЗК„”°ҐT3 ДУ Љ»Ћ Theo Browne µƒ“Хоl°£
±ЊБньcяM»• «њіЋыЗК A …зЇЌ SpaceX ‘хьNѕЙ†IєЈєґ£ђљYєыЫ]ѕлµљ£ђЕsњіµљЅЋкPмґ SpaceX + Cursor Їѕ„чµƒ£ђ“ЉВАЉ»ЅноРЕs”÷ШOґ»ЇѕјнµƒЈ÷ќц£Ї
≤ї’f 600 Г|µƒ ’ўП£ђЊЌ÷ї’f 100 Г|µƒЇѕ„чўM°™°™Theo ‘Џ“Хоl—e±н Њ£ђ„‘ЉЇ’JЮй°Єƒƒ≈¬÷ї «љїУQµљ Cursor µƒ”√СфФµУю£ђя@ 100 Г|“≤÷µїЎ∆±ГrЅЋ°£°є
Ћщ“‘ « ≤ьNФµУю£њ»зєыƒг“≤»•њі Theo я@Чl“Хоl£ђЋыХю÷vµ√Ј«≥£«е≥ю°£µЂЮйЅЋєЭЉsХrйg£ђќ“ВГ‘Џя@—eЇЖЖќЄ≈ј®“Љѕ¬£Ї
ќ“ВГЇЌ AI µƒМ¶‘Т «“ЉБн“ЉїЎµƒ£ђƒгћб≥цЖЦо}/–и«у£ђЋьљoƒгљвір£їcoding agent Ќђјн£ђ÷ї≤їя^ЈµїЎµƒ «іъіa°£
“ЉіќЄяў|ЅњµƒМ¶‘Т£ђ’ыВАя^≥ћ£ђ∞ьј®”√Сфћб Њ°Ґƒ£–ЌЋЉњЉ°Ґagent “ОДЭ°ҐЁФ≥ціъіa°ҐтЮ„C°™°™Ћщ”–я@–©Ц|ќчЇѕ∆рБн£ђњ…“‘ЈQЮй“ЉВАЌк’ыµƒ Agentic Loop°™°™ЊЌ≥…ЮйЅЋЄяГr÷µµƒ”ЦЊЪФµУю£ђ‘ўќєљoƒ£–Ќ»•яM––ПКїѓМWЅХ£ђЊЌƒ№яM“Љ≤љћбЄяƒ£–Ќ‘ЏМНСрИцЊ∞ѕ¬µƒ±нђFЋЃ„Љ°£
Cursor ”–µƒ£ђSpaceX ѕл“™µƒ£ђЊЌ «я@–©ФµУю°£
њ…я@–©ФµУюПƒƒƒ—eБнƒЎ£њ
ір∞ЄЇ№ЇЖЖќ£Ї„чЮйƒ£–ЌПS…ћ£ђя@ЈNЄяў|ЅњФµУюµƒ„о÷±љ”Бн‘і£ђ÷їƒ№ «ƒг„‘ЉЇй_∞lµƒ coding agent Ѓa∆Ј°™°™“≤Љі Anthropic µƒ Claude Code°ҐOpenAI µƒ Codex°ҐKimi µƒ Kimi Code°£
ђF‘ЏƒгС™‘У√ч∞„ЅЋ£ђЮй ≤ьN±ї Anthropic°ЄЈвћЦ°є÷Ѓбб£ђЕ«”оС—Хю‘Џ»ЂЖT–≈—eћб≥цй_∞l xAI „‘ЉЇµƒ coding Ѓa∆ЈЇЌƒ£–Ќя@Љю ¬ЅЋ°£я@Љю ¬ xAI ‘ЏЃФХr“—љЫњі«е≥юЅЋ£Ї
Ы]”–„‘ЉЇµƒЊОіaЃa∆Ј£ђЊЌЫ]”–Єяў|ЅњµƒПКїѓМWЅХФµУю£їЫ]”–Єяў|ЅњµƒФµУю£ђЊЌ”ЦЊЪ≤ї≥ц’ж’эМНСрƒ№Ѕ¶ПКµƒ coding ƒ£–Ќ°£
лm»ї”–ьc±©’У£ђµЂђF‘Џќ“ВГњ…“‘ьcо}ЅЋ£Їƒ£–ЌПS…ћѕл„ц≥цБн’ж’эƒ№ітµƒЊО≥ћƒ£–Ќ£ђ„ц„‘ЉЇµƒ coding agent Ѓa∆Ј «ќ®“Љµƒ¬ЈПљ°£
3.
іу’Z—‘ƒ£–ЌѕсВАЋЃЊІ«т£ђ”√»ЂЊWµƒ’ZЅѕ”ЦЊЪ≥цБн£ђЋ∆Їхƒ№Йтљвір»fќп£ђµЂБK≤їіъ±нЋь‘ЏЋщ”–ЖЦо}…ѕґЉƒ№љo≥цЄяў|Ѕњµƒір∞Є°£
”√ GitHub …ѕФµ“‘Г|”ЛµƒіъіaЧlƒњ”ЦЊЪ£ђЃФ»ї“≤ƒ№”ЦЊЪ≥ц coding ƒ£–Ќ°£я@ «°ЄМWЅХљYєы°єµƒяЙЁЛ£ђ“≤ «Ы]ЖЦо}µƒ°£ЃЕЊєЊОіa»ќД’µƒљYєы «њ…“‘тЮ„Cµƒ£Їіъіaƒ№≤їƒ№я\––£ђЬy‘Зƒ№ЈсЌ®я^£ђљYєыФ[‘Џƒ«—e°£
µЂ «£ђЌ®ЌщљYєыµƒя^≥ћ£ђ «“ЉВА…жЉ∞ґа≤љуEЫQ≤я°Ґеe’`Љm’э°Ґ“вИDМ¶эRµƒПЌлsжЬЧl°£√њ“Љіќ”√Сфµƒљ” №°ҐЊ№љ^°Ґ—a»Ђ°Ґ≥ЈдN°Ґ„ЈЖЦ°Ґ…х÷ЅЃФƒ£–ЌЇ√О„іќґЉЄг≤їґ®їт’яЌк»ЂЄгеeХrµƒ»иЅR°™°™ґЉ «я@“ЉжЬЧl…ѕµƒя^≥ћ–≈ћЦ°£
ПКїѓМWЅХ”–Г…ЈN±OґљЈљ љ£ђ“ЉЈNљ–„цљYєы±Oґљ£ђ÷їњі„обб «Јс≈№Ќ®°£µЂ «љYєы±OґљХюія…ъ°Є™ДДоЇЏњЌ°єµƒђFѕу£Їƒ£–ЌЮйЅЋƒ№≈№Ќ®њ…ƒ№МС≥ц»я”а°Ґіа»х°ҐОІяЙЁЛ¬©ґіµƒіъіa£ђµЂ“тЮйЬy‘Зя^ЅЋ£ђƒ£–Ќ“‘Юй„‘ЉЇМWМ¶ЅЋ°£
ґшЅн“ЉЈNљ–„ця^≥ћ±Oґљ£ђМ¶Ќ∆јн¬ЈПљ…ѕµƒ√њ“Љ≤љяM––ітЈ÷°£…ѕ ця@–©я^≥ћ–≈ћЦ£ђ÷ї”–‘Џ coding agent я\––≠hЊ≥—e≤≈ƒ№’Q…ъ°£GitHub В}Ом—e÷ї”–љYєы£ђƒƒ≈¬ «»•њіЖќ™ЪµƒћбљїЪv Ј£ђњі PR£ђґЉ’“≤їµљ”––Іµƒя^≥ћ–≈ћЦ°£
‘Џ»±Ј¶”––І°Ґ„‘÷чњ…Ђ@µ√µƒя^≥ћ–≈ћЦµƒХrЇт£ђ“Љ–©ƒ£–ЌПS…ћХю≤…”√°Є’фрs°єµƒЈљ љ£ђя@ВА ¬«йіуЉ“С™‘У“—љЫ÷™µјЅЋ°£
’фрsµƒяЙЁЛЇ№ЇЖЖќ£ђљoЌђШ”µƒЁФ»л£ђјѕОЯƒ£–ЌЁФ≥ц ≤ьN£ђМW…ъƒ£–ЌЊЌМW÷шЁФ≥ц ≤ьN°£µЂ «Ќ®я^’фрs£ђЉі±гњ…“‘Ђ@»°µљЋЉЊSжЬ£ђµ√µљµƒ»‘»їЄьѕс «љYєы£ђґшЈ«±ї’фрsµƒјѕОЯƒ£–ЌГ»≤њµƒЄ≈¬ Ј÷≤Љ°£
“Љµ©МW…ъ‘ЏЌ∆јн÷–∆ЂлxЅЋјѕОЯµƒ№ЙџE£ђƒƒ≈¬“ЉВА token ≤їЈыЇѕ£ђґЉ”–њ…ƒ№∞l…ъ∆Ђлx°£
я@±≥бб «ПКїѓМWЅХµƒїщµAѕё÷∆£Ї≤я¬‘ћЁґ»ґ®јн“™«у£ђГЮїѓШ”±Њ„оЇ√”…ЃФ«∞’э‘ЏГЮїѓµƒƒ£–Ќ„‘ЉЇ»•Ѓa…ъ°£я@ЈNФµУюљ–„ц on-policy ФµУю°£ґшЌ®я^’фрsДeЉ“ƒ£–Ќ£ђ‘ЏДe»ЋµƒЃa∆Ј—eЃa…ъµƒФµУю£ђБн”ЦЊЪ„‘ЉЇƒ£–Ќ£ђґЉМўмґ off-policy ФµУю°£ƒ£–ЌЃФ»їњ…“‘Пƒ÷–МWµљЦ|ќч£ђµЂМW≤їµљјѕОЯƒ£–ЌГ»≤њµƒЄ≈¬ Ј÷≤Љ–≈ѕҐ°£
ґшѕс Cursor я@Ш”„‘ЉЇЊЌ « coding agent Ѓa∆ЈµƒєЂЋЊ£ђ’∆ќ’÷ш„о’жМН°Ґ”––І°ҐЄяў|Ѕњµƒ”ЦЊЪФµУю°£Cursor Ѓa∆Ј±Њ…н£ђЊЌ « coding ƒ£–Ќ‘ЏМНСр≠hЊ≥÷–µƒ„оЉ—”ЦЊЪИц°£
ќ“ВГњ…“‘Ќ®я^ Cursor ƒк≥хµƒ°ЄЈ≠№З°є£ђБн„C√чя@ВАяЙЁЛ°£
4.
APPSO „x’яС™‘У”Ыµ√£ђƒк≥х Cursor ∞l≤ЉЅЋ Composer 2£ђћЦЈQ°Єѕ¬“ЉіъМ£”√ЊО≥ћƒ£–Ќ°є£ђЉЉ–gИуµјМСµƒѕаМ¶±£ Ў£ђ„‘ИуЉ“йT «–¬ƒ£–Ќ£ђ“≤Ы]”–ћбє©Њяуwµƒƒ£–Ќµ„„щ–≈ѕҐ°£
љYєыЇ№њм£ђЊW”—ЊЌ‘ЏєЂй_іъіa∆ђґќ—e∞lђFЅЋ Kimi µƒƒ£–Ќ ID£ђљЎИDВч±йЅЋй_∞l’я…з»Ї£ђ±∆µ√ Cursor Є±њВ≤√ Lee Robinson ≥ц√ж≥ќ«е£Ї°ЄComposer 2 і_МН «Пƒй_‘іµ„„щ≥ц∞lµƒ°£„ољKƒ£–ЌіуЉs÷ї”– 1/4 µƒЋгЅ¶Бн„‘µ„„щ£ђ £ѕ¬ 3/4 «ќ“ВГ„‘ЉЇ”Ц≥цБнµƒ°£°єО„–°Хrбб£ђCursor ¬УДУ Aman Sanger “≤Єъ÷ш∞lЅЋ“ЉЧlµј«Є£Ї°Є“Љй_ ЉЫ]ћб Kimi µ„„щ «ВА І’`°£°є
ќйћмбб£ђCursor Ј≈≥цЅЋЌк’ыµƒ Composer 2 ЉЉ–gИуЄж£ђп@ Њµ„„щµƒі_ « Kimi K2.5£ђ ЏЩаЈљДt « Firworks AI£ђіу÷¬Ѕч≥ћ «‘Џ K2.5 …ѕ„ц”ЦЊЪ£ђ‘ўј^јm„ціу“Оƒ£ПКїѓМWЅХ£®RL£©°£
µЂкPжI÷ЃћО‘Џмґ£ђComposer 2 µƒ RL «я\––‘Џ’жМНµƒ Cursor Хю‘ТЃФ÷–£ђ є”√≈c…ъЃa≤њ рЌк»ЂѕаЌђµƒє§ЊяЇЌ harness°£
Cursor МҐя@ћ„Ѕч≥ћљ–„ц°ЄМНХrПКїѓМWЅХ°є(real-time RL)£ђ“≤ЉіМҐƒ£–Ќµƒ checkpoint ÷±љ”≤њ рµљ Cursor …ъЃa≠hЊ≥÷–£ђ”^≤м”√СфµƒнСС™£ђ ’ЉѓФµУю£ђЊџЇѕ≥…™ДДо–≈ћЦ£ђ„оњмњ…“‘√њ 5 ВА–°Хrµьіъ“Љіќƒ£–Ќ∞ж±Њ£ђ»їббј^јm≤њ рµљ Cursor —e£ђ—≠≠hЌщПЌ°£
„оШO÷¬µƒ∞Єјэ « Cursor µƒ„‘Д”їѓіъіa—a»Ђє¶ƒ№ Tab£ђ√њћмћОјн≥ђя^ 4 Г|іќ’И«у£ђ√њЃФ”√СфЁФ»л„÷Јы°Ґ“∆Д”євШЋХr£ђƒ£–ЌґЉХюоAЬyѕ¬“Љ≤љД”„ч£ђ»зєыоAЬy÷√–≈ґ»Єя£ђДtп@ Њљ®„h£ђ”√Сф∞іѕ¬ tab Љіљ” №„‘Д”—a»Ђ°£
‘Ує¶ƒ№≤…”√µƒ «‘ЏЊАПКїѓМWЅХ£ђ‘Џ––ШIГ»ШOЊяћЎ…Ђ°£Cursor њ…“‘“‘ШOЄяµƒоl¬ £®„оњмњ…я_√њ“ЉВА∞л–°ХrµљГ…–°Хr£©Єь–¬ Tab µƒƒ£–Ќƒ№Ѕ¶љo”√Сф£ђ÷±љ”‘ЏЃa∆ЈГ» ’Љѓ on-policy ФµУюяM––”ЦЊЪ°£
я@ЈNЄяоl°Ґљ”љьМНХrµƒЈірБїЎ¬Ј£ђ„М Tab њ…“‘МWЅХµљШO∆䝥√оµƒ”√Сф“вИD°£Cursor Јљ√жЌЄ¬ґ£ђя@ЈNЈљЈ®„М Tab љ®„hµƒЊ№љ^¬ љµµЌ 21%£ђљ” №¬ ћбЄяЅЋ 28%°£
їЎµљ Composer ƒ£–Ќ±Њ…н°£‘Џ ¬«йЄг«е≥юЅЋ÷Ѓбб£ђ“Љ–© Kimi ЖTє§“≤ДhµфЅЋ÷Ѓ«∞Ќ¬≤џµƒЌ∆ќƒ£ђKimi єўЈљў~ћЦ∞l±нЅЋ„£ўR°£
“ЉЉ“єј÷µ 600 Г|√ј‘™£®їщмґсRЋєњЋљoµƒФµ„÷£©£ђ≤ї„ц„‘ЉЇµƒƒ£–Ќїщ„щµƒ coding agent С™”√М”єЂЋЊ£ђ»‘»їњ…“‘Ќ®я^Ѓa∆Ј„‘…нµƒФµУюпwЁЖ£ђRL ≥ц≥ђ‘љїщ„щƒ£–ЌµƒМ£”–ЊО≥ћƒ£–Ќ°£
Ћщ“‘≈c∆д’f Cursor Ј≠ЅЋ№З£ђ≤ї»з’fя@Јіґш « coding agent Ѓa∆Ј÷Ў“™–‘µƒљ^Љ—јэ„C°£
Cursor ‘ЏЅн“Љ∆™кPмґМНХr RL µƒќƒ’¬—eМСµљ£Ї°Є£®”ЦЊЪЊО≥ћƒ£–Ќ£©„оіуµƒјІлy‘Џмґљ®ƒ£”√Сф°£Composer µƒ…ъЃa≠hЊ≥—e≤ї÷ї”–Ић––√ьЅоµƒ”ЛЋгЩC£ђяА”–±OґљЇЌ÷ЄМІЋьµƒ»Ћ°£ƒ£ФM”ЛЋгЩC»Ё“„£ђƒ£ФM є”√Ћьµƒ»ЋЕsЇ№лy°£°є
я@Њд‘Т£ђђF’э‘Џ÷рЭu≥…ЮйЅЋ‘ЏЊО≥ћƒ£–ЌЈљ√ж„я‘Џ«∞—Ўµƒƒ£–ЌПS…ћ÷Ѓйgµƒє≤„R°£»зєыƒг»•њі benchmark ∞сЖќЇЌ”√Сф∆’±й‘uГr£ђХю∞lђFƒ«–©о^≤њµƒПS…ћґЉ‘Џ∞lЅ¶„ц„‘ЉЇµƒ coding agent/ЊО≥ћЃa∆Ј°£Е^Дe÷ї‘Џмґ’lлx”√СфЄьљь°£
ќ“ВГ“‘ SWE-bench°ҐLLM-Stats µ»ѕаМ¶ЩаЌюµƒ∞сЖќЮйјэ£ђClaude°ҐGPT°ҐGemini°ҐKimi µ»ƒ£–Ќїщ±Њ∞‘∞с«∞ ∞£ђ«е“Љ…ЂґЉ «”–„‘ЉЇй_∞l coding agent Ѓa∆Ј£®∞ьј® CLI°ҐIDE°ҐЉѓ≥… coding agent µƒ„ј√жњЌСфґЋ£©µƒƒ£–ЌПS…ћ°£
‘Џ≤њЈ÷∞сЖќ…ѕХю≥цђF…ўФµЈіјэ£ђ»з Meta (Muse Spark)°ҐMinimax°ҐDeepSeek µ»£ђЫ]”–й_∞l„‘ЉЇµƒ coding agent°£
≤їя^ƒгХю∞lђF£ђя@–©Јіјэƒ£–Ќ£ђ‘ЏЄьЉ”љ”љь’жМНИцЊ∞°Ґ±№√вќџ»ЊµƒЄьЩаЌю benchmark …ѕЊЌЇ№лy…ѕ∞сЅЋ°£“‘ DeepSeek Юйјэ£ђЋь‘Џ SWE-bench bash only …ѕЈ÷Фµ « 70%£ђ≈≈√ыµЏЊ≈£ђ‘Џ SWE-bench Pro …ѕЈ÷ФµЕsµфµљЅЋ 15% „у”“°£
OpenRouter µƒ’жМНЅчЅњФµУюњ…“‘љвбМя@ЈNЈі≤о£Ї‘У∆љћ® 2025 ƒкИуЄжп@ Њ£ђClaude token ѕыўM 80% “‘…ѕ”√мґЊО≥ћЇЌЉЉ–g»ќД’£ђґш DeepSeek token ѕыўM÷ч“™Љѓ÷–мґйfЅƒЇЌљ«…Ђ∞з—Ё°£
Ы]”–„‘Љ“ coding Ѓa∆ЈµƒПS…ћ£ђ‘Џ“Љ–© coding »ќД’ benchmark …ѕƒ№ФDяMо^≤њ£ђµЂ‘ЏЄьлyµƒ’жМНє§≥ћ benchmark …ѕ£ђ‘Џ”√Сф”√ token ѕыўMЌґ∆±µƒ’жМНЅчЅњ÷–£ђґЉХю‘≠–ќЃЕ¬ґ°£
≤їГH « Cursor£ђAnthropic ‘Џ 2025 ƒк 11 ‘¬∞lµƒ“Љ∆™’Уќƒ—e£ђ“≤√чі_ЌЄ¬ґ„‘ЉЇ‘Џ„ц“Љƒ£“ЉШ”µƒ ¬«й£Ї°Єќ“ВГ‘Џ Anthropic „‘Љ“µƒ’жМН…ъЃaЊО≥ћ≠hЊ≥…ѕ„ц”ЦЊЪ°£°є“≤Љі Anthropic ∞—„‘ЉЇЖTє§ є”√ Claude Code µƒљїї•ФµУю£ђЈі≤Єљo Claude ƒ£–Ќ”√Бн”ЦЊЪ°£
5.
‘Џ AI µƒ—ЁяMЪv≥ћ÷–£ђ…ъЃa“™ЋЎµƒґ®Ѕx∞l…ъЅЋ…оњћµƒќї“∆°£Вчљy»юіуЇЋ–ƒ“™ЋЎ°™°™ЋгЅ¶°Ґ—–Њњ°Ґ”ЦЊЪФµУю£ђлm»ї‘ЏњВЅњ…ѕ≥÷јm‘цйL£ђµЂ‘ЏљYШЛ…ѕ“—љЫ≥цђFЅЋЗј÷Ўµƒ ІЇв°£
љсћмµƒЄчіу AI Њёо^п@÷шћбЄяЅЋ‘ЏЋгЅ¶…ѕµƒўY±Њ÷І≥ц (CapEx)£ђ„МЋгЅ¶їщљ®≥…ЮйЅЋЃФ«∞ЁЫ’Уµƒ÷ч–э¬…°£µЂМНлH…ѕ£ђћЎДe «‘ЏЊО≥ћЈґЃ†Г»£ђлS÷ш GitHub В}Ом°ҐStackOverflow µ»ї•¬УЊWєЂй_іъіaФµУю±їїщƒ£ПS…ћ°ЄљяЭ…ґшЭO°є љµЎјы”√£ђƒ£–Ќ‘Џіъіa…ъ≥…≈cяЙЁЛЌ∆јн…ѕµƒяЕљзй_ Љ÷рЭuп@ђF°£
я@“≤ «Юй ≤ьN£ђ––ШIє≤„R’э‘Џ÷рЭuёDѕт“ЉВА»љ»љ…э∆рµƒ–¬С𬑪яµЎ£ЇМ¶мґ»ќЇќѕ£Ќы’∆ќ’нФЉЙіъіaƒ№Ѕ¶µƒƒ£–ЌПS…ћґш—‘£ђљ®ЅҐ„‘”–µƒ coding agent Ѓa∆Ј‘з“—≤ї‘ў «њ…яxµƒ…ћШI¬ЈЊА£ђґш «і_±£µ„М”ƒ£–Ќњ…“‘≥÷јmяMїѓµƒЇЋ–ƒ…ъ√ьЊА°£
’э»з«∞√ж APPSO ’У„Cµƒƒ«Ш”£ђЖќЉГМWЅХєЂй_ФµУюµ»мґ÷їМWЅХ≥…є¶’яµƒљYЊ÷£ђЕsЯoЈ®ЅЋљв≥…є¶µƒ¬ЈПљ£ђя@љ^М¶≤ї «’эі_µƒ≥…є¶МWС™‘У”–µƒШ”„”°£‘Џ’жМНµƒЊО≥ћ≠hЊ≥÷–£ђ÷™µј∞l…ъЅЋ ≤ьNеe’`°Ґ‘хШ”∞l…ъµƒ°Ґ»зЇќ’эі_µЎјнљвЇЌЄя–ІµЎМНџ`–и«уµ»µ»°™°™ЅЋљв’эі_я^≥ћµƒГr÷µ£ђяh≥ђмґµ√µљ’эі_љYєы±Њ…н°£
÷ї”–Ун”–„‘ЉЇµƒЊОіaЃa∆Ј£ђƒ£–ЌПS…ћ≤≈ƒ№Ђ@»°Єяў|Ѕњµƒ°Єя^≥ћ±Oґљ°є–≈ћЦ£ђПƒґш‘ЏЊОіa/Ќ∆јнƒ№Ѕ¶µƒѕ¬“ЉлAґќЄВ†О÷–£ђі_±£„‘ЉЇ»‘”–ЉЉ–g„o≥«Ї”°™°™
ЈсДtЊЌ≤їµ√≤їѕс SpaceXAI ƒ«Ш”£ђї®еX»•Єъ coding agent Ѓa∆ЈєЂЋЊ»•Їѕ„ч°£»їґшБK≤ї «Ћщ”–ƒ£–ЌПS…ћґЉЄъсRЋєњЋ“ЉШ””–еX£ђ“‘Љ∞ 2026 ƒкй_ ЉµƒЊёо^ДЁЅ¶ДЭЈ÷°ҐљY√Ћ≈cоIµЎµƒ†ОґЈХю„Гµ√ЄьЉ”Љ§Ѕ“£ђЃФ“ЉЉ“»±Ј¶„‘÷ч coding Ѓa∆Јµƒƒ£–ЌПS…ћљKмґїЎя^ќґБнµƒХrЇт£ђњ÷≈¬“—љЫЫ]”–„гЙтµƒЇѕ„чїп∞йњ…“‘ћфяx£ђЇѕ„чµƒГrЄс“≤МҐЋЃЭqіђЄя°£
√јЗшƒ£–ЌЊёо^µƒ«йЫrіуЉ“∆’±й±»Ё^ мѕ§ЅЋ£ђ‘ЏіЋ≤їўШ ц°£APPSO “≤„Ґ“вµљ£ђЗшГ»µƒ÷чЅчƒ£–ЌПS…ћЇЌ AI Њёо^ЃФ÷–£ђљ^іу≤њЈ÷ґЉ“—љЫ‘Џ coding agent Ѓa∆Ј…ѕ”–Ћщ≤ЉЊ÷°£
ЗшГ»Њёо^єЂЋЊ÷ч“™“‘‘≠…ъ AI IDE їт IDE ≤еЉюµƒЋЉ¬Ј‘Џ„ц£Ї„÷єЭћшД”»•ƒкЇ№‘зЊЌ≤ЉЊ÷ЅЋ TRAE°Ґ∞Ґ—e∞Ќ∞Ќµƒ Qoder°Ґтv”Нµƒ CodeBuddy°Ґ∞ўґ»µƒќƒ–ƒњміa Comate µ»°£
AI –°эИєЂЋЊ÷–£ђ‘¬÷Ѓ∞µ√ж «„о‘зй_∞l™ЪЅҐ coding agent Ѓa∆ЈµƒєЂЋЊ£ђ÷ч“™“‘ CLI љз√жµƒ Kimi Code Юй÷ч°™°™≤їя^ Kimi іЋ«∞”–ЌЄ¬ґя^£ђ‘Џ‘≠…ъЊО≥ћЃa∆Јя@Љю ¬…ѕ£ђCLI ≤їХю «љKЊ÷°£
Ѕн“ЉЈNМНђFЋЉ¬Ј «ƒ£–ЌПS…ћ„‘––ћбє© API ЈюД’°ҐCoding Plan°£я@Ш”£ђ≤ї’У”√Сф є”√ЇќЈN AI й_∞l≠hЊ≥£ђƒ£–ЌПS…ћґЉњ…“‘Ќ®я^ЈюД’∆чґЋµƒ API ”ЫдЫБнЂ@»°„оіу≥ћґ»љ”љьмґ‘≠…ъ coding Ѓa∆Јµƒя^≥ћФµУю°£
µЂя@“≤÷ї «љ”љь£ђБKЈ«Ќк»ЂѕаЌђ°£ЇЋ–ƒ‘Џмґ£ђЈюД’∆чґЋ API µƒ’И«у-нСС™»’÷Њ£ђ≈c…оґ»«ґ»лµƒЃa∆Јљїї•№ЙџEѕа±»»‘”–Ї№іу≤оЊа°£
„‘љ®Ѓa∆ЈµƒПS…ћ£®јэ»з Cursor°ҐClaude „ј√жґЋ°ҐCodex£©Ун”–„о÷±љ”µƒп@ љЈірБ–≈ћЦ£ђґш API В» «ѕаМ¶ƒ£Їэµƒл[ љЌ∆Фа°£ЇЖЖќБн’f£ђAPI В»ƒ№њіµљ”√Сф’И«уЇЌнСС™£ђµЂ”√Сф„обб «Јс≤…Љ{ЅЋя@ґќіъіa°Ґіъіaƒ№Јс≈№Ќ®°Ґ“э∞lЅЋ ≤ьNШ”µƒ bug£ђAPI В»М¶іЋ «“ЉЯoЋщ÷™µƒ°£ЋыВГЯoЈ®ЅЋљвµљ”√Сф„ољK––Юйя@“ЉкPжIµƒШЋЇЮ£ђПƒґшЯoЈ®МНђF„оЄяў|ЅњµƒПКїѓМWЅХ°£
–ќґш…ѕБн÷v£ђ’Z—‘Љі јљз£ђіъіaЉіЈљ∞Є°£іъіaњ…“‘±ня_я@ВА јљз…ѕљ^іуґаФµµƒ»ќД’£ђіъіa“≤Хю≥…Юйо^≤њµƒЈ≈іу∆ч£ђ„М„онФЉвµƒ»Ћ≤≈Ј≈іуФµ±ґµƒ…ъЃaЅ¶°£
÷ї”–„онФЉвµƒ coding ƒ£–Ќ≤≈≈дµ√…ѕ„онФЉвµƒ»Ћ≤≈°£»зєыоIѕ»µƒƒ£–ЌПS…ћ≤ї÷Ў“Х coding£ђДЁ±ЎМҐХюµф≥цµЏ“ЉћЁк†°£
ЃФ»ї£ђ ¬МН…ѕ√њЉ“ƒ£–ЌПS…ћґЉ≤їХю≤ї÷Ў“Х coding°™°™ґш «’f£ђ‘Џ–¬µƒЈґ љѕ¬£ђƒ«–©Ы]”–„‘÷чњ…њЎµƒ‘≠…ъ coding agent Ѓa∆Ј£ђШO”–њ…ƒ№÷рЭu¬дббмґ”–Ѓa∆ЈµƒПS…ћ°£
ЊЌ‘Џ«∞О„ћм£ђMiniMax “≤∞l≤ЉЅЋ„ј√жњЌСфґЋЃa∆Јµƒ÷ЎіуЄь–¬£ЇОІ”–»Ђ–¬ґа agent ЊО≈≈Љ№ШЛµƒ Mavis є¶ƒ№£ђБK«““≤„МњЌСфґЋп@÷шЄƒ…∆ЅЋМ¶ coding »ќД’µƒ÷І≥÷°£
іЋ«∞ MiniMax ÷ї «Ќ∆≥цЅЋ„ј√жґЋ£ђµЂЫ]”–Љ”»л‘≠…ъ coding ЇЌ agent є¶ƒ№°£
Њoљ”÷ш£ђ‘Џ 5 ‘¬ 15 »’£ђ∞Ґ—e∞Ќ∞Ќ’э љ∞l≤ЉЅЋ Qoder 1.0°™°™я@ВАЃa∆ЈПƒ IDE µƒ–ќСB’э љ…эЉЙЮй“ЉВАЌк’ыµƒ Agent Ѓa∆Ј£®∞Ґ—eµƒєўЈљљ–Ј® «÷«ƒ№уw„‘÷чй_∞lє§„чћ®£©°£
≈cіЋЌђХr£ђxAI µƒ Grok Build CLI£ђ“≤љKмґ’э љЌ∆≥цЅЋ°£
Ы]еe£ђЊЌ « xAI ƒк≥х±ї Anthropic ЇЌ Cursor ЈвћЦ÷Ѓбб£ђЋыВГ„‘ЉЇУvєƒ≥цБнµƒƒ«ВА coding agent.
я@≤ї£ђ”÷ґаЅЋЇ√О„ВАђF≥…µƒ∞Єјэ°£
њіБн£ђіуЉ“ґЉ’JЮй Cursor°ҐCodex ЇЌ Claude „ј√жґЋ„я‘Џ’эі_µƒµј¬Ј…ѕ°£
6.
∞—‘То}Пƒ coding ФU’єµљ agent ±Њ…н£ђ«йЫr“≤ «“ЉШ”µƒ°£
ЊОіa»ќД’µƒ№ЙџEФµУю£ђ‘ЏєЂй_’ZЅѕ÷–і_МНяА «ƒ№’“µљ“Љ–©µƒ£®±»»з GitHub µƒћбљї”ЫдЫ/PR£ђ±Mє№ў|ЅњБK≤їЄя£©°£µЂ « agent »ќД’µƒ№ЙџEФµУю£ђ∞ьј®µЂ≤їѕёмґ“∆Д”ЇЌьcУф уШЋ°Ґ≤ўњЎ”|∆Ѕ°ҐћоМСЁФ»лњтµ»£ђЕsЯoЈ®‘ЏєЂй_’ZЅѕ÷–’“µљ°£
Ћщ“‘ќ“ВГХюњіµљ£ђЉі є‘Џ agent ≤ў„чµƒ„о–°МНђF¬ЈПљ°™°™Юg”[∆ч≤еЉю…ѕ£ђЉі±г «я@ьNВАњі∆рБн“ЉьcґЉ≤їЄяґЋµƒЦ|ќч£ђО„Їх√њЉ“ƒ£–ЌПS…ћґЉХю„ц„‘ЉЇµƒ°£
OpenAI ‘з‘Џ 2025 ƒк 1 ‘¬ЊЌ„цЅЋ Operator°™°™≈c∆д’fЋь «“ЉВА°ЄAI „‘Д”≤ў„чЮg”[∆ч°єµƒЃa∆Ј£ђ≤ї»з’f±Њў|…ѕЊЌ «“ЉВАіу“Оƒ£µƒФµУю ’Љѓ—b÷√°£√њ“Љќї‘З”√ Operator µƒ”√Сф£ђґЉ‘Џ√вўMЮй OpenAI ћбє© on-policy ФµУю°£
ббјm OpenAI яА—№…ъ≥ц ChatGPT Agent “‘Љ∞–¬∞ж Codex „ј√жґЋ£їAnthropic “≤ «Ќђјн£ї„ољь Kimi ≤ї¬Х≤їнСµЎ“≤„цЅЋ“ЉВАљ–„ц WebBridge µƒнЧƒњ£ђ∆дМНЊЌ «“ЉВАЮg”[∆ч≤еЉю°£
Љі±г «‘Џя^»•Г…ƒк—eД”„ч„оњЋ÷∆µƒ÷–Зшƒ£–ЌЊёо^…оґ»«уЋч£ђ“≤‘Џ„ољьй_ Љ’є¬ґ≥цМ¶ Agent µƒ≈d»§°£
CEO ЅЇќƒдhіЋ«∞љ” №≤…‘LХr‘шљЫћбµљя@Ш”µƒ”^ьc£ЇФµМWЇЌіъіa «AGIћм»їµƒ‘ЗтЮИц£ђ”–ьcѕсЗъ∆е£ђ «“ЉВАЈвй]µƒ°Ґњ…тЮ„Cµƒѕµљy£ђ”–њ…ƒ№Ќ®я^„‘ќ“МWЅХЊЌƒ№МНђFЇ№Єяµƒ÷«ƒ№°£
я@Њд‘ТµƒЭУћ®‘~£ђ « DeepSeek “Љ÷±∞— coding°ҐAgent ЃФ—–Њњ‘ЗтЮИц£ђґшЈ«…ћШIїѓЈљѕт°£
µЂ «‘Џљсƒк 3 ‘¬£ђDeepSeek “Љіќ–‘Ј≈≥цЅЋ ∞О„ВА Agent ѕакPНПќї£ђ∞ьј® „іќ≥цђFµƒƒ£–Ќ≤я¬‘Ѓa∆ЈљЫјн£®Agent Јљѕт£©µ»°£ЃФХrµƒ JD ¬ЪЎЯЇ≠…w°Є÷чМІ Agent ‘uЬyуwѕµ“‘Љ∞”ЦЊЪФµУюЈљ∞Єµƒ‘O”Л°є£ђ“™«у÷–∞ьј®°Є…оґ» є”√ Claude Code°ҐManus°єµ»Ѓa∆Ј°£
APPSO „Ґ“вµљ£ђљь∆Џ…оґ»«уЋч∞l≤ЉЅЋ Agent Ѓa∆ЈљЫјн°ҐHarness Ѓa∆ЈљЫјнµ»¬Ъќї’–∆Є–≈ѕҐ°™°™Ї№п@»ї£ђDeepSeek “™„ц™ЪЅҐ°Ґ‘≠…ъµƒ Coding/Agent Ѓa∆ЈЅЋ°£
іЋ«∞ўYЅѕп@ Њ£ђDeepSeek V3.2 µƒ”ЦЊЪя^≥ћ÷–“э»лЅЋљьГ…«ІВАЇѕ≥…µƒ Agent ”ЦЊЪ≠hЊ≥ЇЌ∞Ћ»fґаЧlПЌлs÷ЄЅо°£µЂ «њі∆рБн£ђњњЇѕ≥…µƒ”ЦЊЪФµУю÷їƒ№ОІ DeepSeek „яµљя@—eЅЋ£ђ £ѕ¬µƒ «Їѕ≥…≤ї≥цБнµƒ≤њЈ÷£Ї’жМН”√Сф‘Џ’жМН≠hЊ≥—eµƒ’жМН≥…є¶ЇЌ ІФ°£ђ±ЎнЪњњ„‘Љ“µƒ agent Ѓa∆Ј≤≈ƒ№ƒ√µљ°£
DeepSeek “‘“ЉЈNШOґ»њЋ÷∆µƒЈљ љ„цЅЋ»юƒкƒ£–Ќ“‘Љ∞ƒ£–ЌЃa∆Ј£®÷±µљ…ѕВА‘¬≤≈љKмґ‘ЏєўЊWЉ”»лЅЋґаƒ£СBƒ№Ѕ¶£©°£µЂ «‘ЏљсћмБнњі£ђ‘ЏЊОіaоР»ќД’…ѕ£ђDeepSeek ƒ√ SOTA ‘љБн‘љлyЅЋ£ђЉі±гіЋ«∞ƒ√µљ“≤Хю‘Џ≤їЊ√бб±ї≥ђ‘љ°£
ЃФ÷ъјн“јњњ—–Њњµƒ¬ЈПљ÷ІУќ≤ї„°пwЁЖµƒХrЇт£ђDeepSeek љKмґ––Д”ЅЋ°£
7.
„обб£ђќ“ВГїЎµљй_∆™µƒє ¬°£
ЄщУю The Information Иуµј‘Ѓ“э÷™«й»Ћ њИуµј£ђ‘Џљ” №сRЋєњЋ 600 Г| ’ўП/100 Г|√ј‘™Їѕ„чµƒЌђХr£ђCursor ±н Њ≤їХю≈c xAI Їѕ„чй_∞l–¬µƒƒ£–Ќ£ђґш «»‘МҐЊџљємґГЮїѓ„‘ЉЇµƒ Composer ƒ£–Ќ°£
я@“вќґ÷ш£ђЉі±г±їсRЋєњЋўIЌ®…х÷Ѕ ’ўП£ђCursor »‘»ї“™±£Ѕф„‘ЉЇФµУюпwЁЖµƒ÷чуw–‘°£
ФµУюЪwМўµƒ±Њ…н£ђ «„окPжIµƒл[≤Ў≤©ёƒьc°£
ЃФЋщ”–нФЉЙƒ£–ЌПS…ћґЉ„цЅЋ„‘ЉЇµƒЃa∆Ј£ђЋщ”–нФЉЙЃa∆Ј“≤ґЉй_ Љ”ЦЊЪ„‘ЉЇµƒƒ£–Ќ£ђ°Єƒ£–ЌєЂЋЊ°єЇЌ°ЄЃa∆ЈєЂЋЊ°єµƒ±ЊЊЌ≤їћЂ«е≥юµƒљзѕё£ђЋ∆Їх‘љБн‘љ≤їіж‘ЏЅЋ°≠°≠
я@Иц≤©ёƒ“≤≤≈ДВДВй_ Љ°£
ќƒ£ьґ≈≥њ
ЕҐњЉўYЅѕ£Ї
Theo - t3.gg: www.youtube.com/watch?v=3pkz-Ie_k_c
Composer 2 ЉЉ–gИуЄж£Їcursor.com/cn/blog/composer-2-technical-report
Anthropic ’Уќƒ£Їarxiv.org/abs/2511.18397
љYєы±Oґљ vs я^≥ћ±Oґљ£Ї www.emergentmind.com/topics/process-vs-outcome-supervision
ПКїѓМWЅХµƒ–≈ћЦ’`≤о£Їhttps://openreview.net/pdf?id=TDfrN1TbGH
кPмґ„‘љ® or ўПўIя^≥ћФµУюµƒ”С’У£Їhttps://www.reddit.com/r/AI_Agents/comments/1snc116/the_overlooked_trend_of_building_custom_ai_agents/
≤њЈ÷ИD∆ђЮй AI …ъ≥…
[ќпГrпwЭqµƒХrЇт я@Ш” °еXўПќпЇ№Ћђ]
| Ј÷ѕн: |
| „Ґ£Ї |
| —”…мйЖ„x | Єьґа... |
Ќ∆Ћ]: