




DeepSeek»ыяMћOєы±ЊГЇ Ј÷О≈≤її®МНђF"эИќr„‘”…"

‘ЏagentХrіъ„оўFµƒ « ≤ьN£њ «token°£
“Љ–©÷Ўґ»agent є”√’я£ђ“ЉВА‘¬”√µфО„Г|token£ђў~Жќ–°О„»fЙKеX“≤ «≥£”–µƒ ¬°£
»їґшђF‘Џй_ Љ£ђ”–я@ьN“ЉВАй_∞l’яЋый_‘іЅЋ“ЉВА±ЊµЎЈљ∞Є£ђ“Љћ®ћOєыєP”Ы±ЊЊЌƒ№≤њ р£ђ“≤ЊЌ «’f£ђƒгПƒіЋМНђFЅЋ°∞эИќr„‘”…°±£ђ≈№‘ўґа»ќД’£ђ“≤≤їХю‘ўЮйtokenЄґ≥ц“ЉЈ÷еXЅЋ°£„окPжIµƒ «£ђЋы”√µƒяА «DeeSeek V4 Falsh°£
О„ћм«∞£ђantirez‘ЏGitHub…ѕ∞l≤ЉЅЋ“ЉВАнЧƒњ£ђљ–ds4°£
я@ «“ЉВАМ£йTЮйDeepSeek V4 FlashМСµƒЌ∆јн“э«ж°£“Љє≤О„«І––Cіъіa£ђњ…“‘„МDeepSeek V4 Flashя@ВАƒ£–Ќ‘Џ128GГ»іжµƒћOєылКƒX…ѕ≈№∆рБн°£
й_∞l’яantirez£ђ±Њ√ыSalvatore Sanfilippo£ђ «“віујы≥ћ–тЖT£ђЌђХrЋы“≤ «й_‘іФµУюОмRedisµƒ‘≠„ч’я°£RedisббБн≥…Юй»Ђ«тї•¬УЊWїщµA‘O ©—e„о≥£”√µƒГ»іжФµУюОм÷Ѓ“Љ°£
ЌщЇ√µƒЈљ√ж»•ѕл£ђDeepSeek”∞нСЅ¶„гЙтіу£ђќь“эµљЅЋ»¶Г»нФЅчµƒ≥ћ–тЖT£ђµЂ «ЙƒµƒЈљ√ж «£ђDeepSeekя@їЎ’жµƒ√вўMЅЋ°£
»ќЇќй_∞l’яґЉњ…“‘”√ds4£ђ»•∞—DeepSeek V4 Flash—bяM„‘ЉЇµƒMacBook Pro—e£ђ±ЊµЎ≈№іъіa°Ґ±ЊµЎ„x…ѕѕ¬ќƒ°Ґ±ЊµЎ„цagent»ќД’£ђґшя@“Љ«–µƒ“Љ«–£ђ≤ї–и“™љoDeepSeekЄґ1Ј÷еX°£
лm»їDeepSeek V4 Flash±Њ…нй_‘і£ђњ…FP16ЊЂґ»µƒ‘≠ Љƒ£–Ќ“™≥‘µф284GГ»іж£ђп@іж–и«уЄь «Єяя_160G°£
“тіЋ£ђѕля\––Ћь£ђƒг÷Ѕ…ўµ√”–Г…ПИ”ҐВ•я_A100 80GB°Ґ“ЉЧl512GB DDR5 ECCГ»іж£ђ“‘Љ∞“ЉВА4TB NVMe SSD°£њВ≥…±Њ50»f»Ћ√сО≈(专题)°£
ґшђF‘Џ£ђ“Љћ®3»fЙKеXµƒMacBook ProЊЌƒ№≈№°£
ƒ«antirezЮй ≤ьN∆Ђ∆Ђяx÷–DeepSeek V4 FlashƒЎ£њ
‘≠“т «DeepSeek„ояmЇѕ±ї°∞»ыяM±ЊµЎлКƒX°±°£
Ћь”–284BњВЕҐФµ£ђ„гЙтіу£їµЂ√њіќЌ∆јн÷їЉ§їо13BЕҐФµ£ђ”÷≤їѕсВчљyіуƒ£–Ќƒ«Ш”≥Ѕ÷Ў°£
Ћь÷І≥÷100»ftoken…ѕѕ¬ќƒ£ђяmЇѕЊО≥ћ÷ъ ÷я@ЈNйL»ќД’£їЌђХrKV cacheЙЇњsµ√„гЙтЇЁ£ђљo±ЊµЎГ»іжЇЌSSDЅфѕ¬ЅЋ≤ў„чњ’йg°£
DeepSeek V4 FlashДВЇ√’Њ‘ЏЅЋя@Ш”“ЉВА…с∆жµƒ∆љЇвьc…ѕ£ђЉ»іуµљ÷µµ√’џтv£ђ”÷–°µљƒ№±ї»ыяMћOєыєP”Ы±Њ—e°£
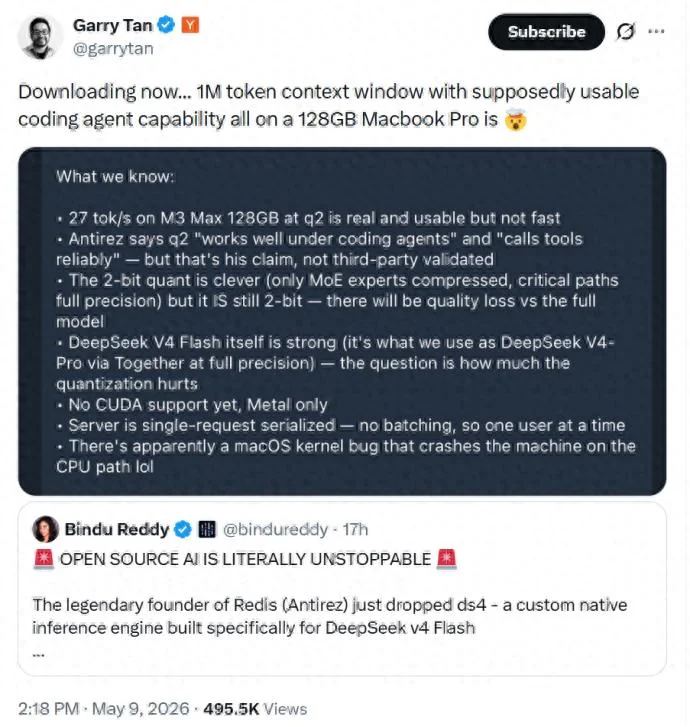
YCµƒCEO Garry Tan‘ЏX…ѕёDЅЋя@ЧlѕыѕҐ£ђ÷їітЅЋ“Љ––„÷£Ї’э‘Џѕ¬Ёd°≠°≠100»ftoken…ѕѕ¬ќƒі∞њЏ£ђњ…”√µƒЊО≥ћ÷ъ ÷ƒ№Ѕ¶£ђ»Ђ‘Џ“Љћ®128GBµƒMacBook Pro…ѕ£ђћЂѓВњсЅЋ°£
ds4ЊњЊє « ≤ьN£њ
ѕ»’fљY’У£ђds4≤ї «“ЉВАƒ£–Ќ£ђЋь «“Љћ®°∞М£”√∞lД”ЩC°±°£DeepSeek V4 Flash «№З£ђћOєылКƒX «¬Ј£ђds4ЎУЎЯ∞—я@Ёv‘≠±ЊЄьяmЇѕ≈№‘ЏлЕґЋµƒіу№З£ђЄƒµљ±ЊµЎЩC∆ч…ѕƒ№≈№°Ґƒ№љ”API°ҐяАƒ№±їcoding agent’{”√°£

я^»•іуЉ“ѕл‘Џ„‘ЉЇлКƒX…ѕ≈№іуƒ£–Ќ£ђ∆’±й”√µƒґЉ «llama.cppя@ВАє§Њя°£ЋьµƒЇ√ћО « ≤ьNƒ£–ЌґЉƒ№≈№£ђLlama°ҐQwen°ҐDeepSeek»ЂґЉ÷І≥÷°£
њ…ЖЦо}ЊЌ «£ђ ≤ьNґЉƒ№≈№£ђЊЌ“вќґ÷ш ≤ьNґЉ≈№≤їµљ„оњм°£ЮйЅЋ’’оЩЋщ”–ƒ£–Ќ£ђllama.cpp±ЎнЪ„цЇ№ґаЌ„Еf£ђ–‘ƒ№…ѕ≤їњ…ƒ№„цµљШO÷¬°£
antirezµƒѕлЈ®’эЇ√ѕаЈі£ђЋы≤≈≤їє№Дeµƒƒ£–ЌЋјїо£ђЋыЊЌМ£йTЋ≈ЇтDeepSeek V4 Flashя@“ЉВА£ђ∞—ЋьГЮїѓµљШOѕё°£
Ћы“Љє≤„цЅЋ3Љю ¬°£
µЏ“ЉЉю ¬£ђ «≤їМ¶ЈQµƒ2-bitЅњїѓ°£
DeepSeek V4 FlashµƒЉ№ШЛ «MoE£®Mixture of Experts£©£ђ284BњВЕҐФµ—e£ђ√њіќЌ∆јн÷їЉ§їо13B£ђя@13B «¬Ј”…ћф≥цБнµƒ»фО÷ВАМ£Љ“„”ЊWљj°£
ЊЌѕс“ЉВАє§Њяѕд—e”–284∞—є§Њя£ђ√њіќ÷їƒ√≥ц13∞—Бн”√°£я@284B—e√ж£ђ”–“Љіуґ—°∞ВдяxМ£Љ“°±’ЉЅЋ90%“‘…ѕµƒњ’йg£ђµЂЋьВГ≤ї «√њіќґЉ”√£ђ÷ї «Їт—a°£
antirezµƒ„цЈ® «£ђ÷їМ¶я@≈ъrouted experts„цЉ§яMµƒ2-bitЅњїѓ£ђupЇЌgateЊЎкЗ”√IQ2_XXS£ђdownЊЎкЗ”√Q2_K£ђґшƒ£–Ќ—eЋщ”–кPжI¬ЈПљ…ѕµƒљMЉю£ђ∞ьј®shared experts°Ґprojections°ҐroutingЊWљj£ђ»Ђ≤њ±£≥÷‘≠ ЉЊЂґ»≤їД”°£
“≤ЊЌ «’f£ђantirez∞—я@–©°∞Їт—aМ£Љ“°±ЇЁЇЁЙЇњs£ђЙЇµљ÷ї £‘≠Бн1/4µƒіу–°£ђµЂƒ«–©√њіќґЉ“™”√µƒЇЋ–ƒљMЉю£ђ“ЉьcґЉ≤їД”£ђ±£≥÷‘≠Ш”°£
я@ «“ЉЈN≤їМ¶ЈQµƒЙЇњs≤я¬‘£ђњ≥µфуwЈeіуо^£ђ±£„°ў|Ѕњ√ь√}°£
µЏЈ°Љю ¬£ђ «∞—KV Cache∞бµљSSD…ѕ°£
DeepSeek V4 Flash÷І≥÷100»ftokenµƒ…ѕѕ¬ќƒ£ђя@ѕаЃФмґƒгњ…“‘∞—“Љ’ы±Њ–°’f»”љoЋь£ђЋьƒ№»Ђ”Ы„°°£
µЂя@ьNйLµƒ…ѕѕ¬ќƒ£ђ“вќґ÷шAI‘Џє§„чХr“™≤їЌ£µЎїЎо^Ј≠њі«∞√жµƒГ»»Ё°£ЮйЅЋ„Мя@ВА°∞їЎо^Ј≠њі°±µƒД”„ч≤ї÷Ѕмґ¬эµљњ®Ћј£ђAI–и“™∞—я@–©Г»»ЁХЇіж‘Џ“ЉВАљ–°∞ЊПіж°±µƒµЎЈљ£ђЈљ±глSХr’{”√°£
“‘«∞µƒ„цЈ® «∞—я@ВАЊПіжЈ≈‘ЏГ»іж—e°£Г»іжЋўґ»њм£ђAI√њіќ…ъ≥…“ЉВА„÷ґЉ“™оlЈ±≤йя@ВАЊПіж£ђЋщ“‘±ЎнЪЈ≈Г»іж°£
µЂЖЦо} «£ђ»зєы„М128GBГ»іжµƒMacBook Pro≈№DeepSeek-V4 Flash£ђєвЊПіжЊЌƒ№∞—Г»іж≥‘єв£ђƒ£–Ќ±Њ…нґЉЫ]µЎЈљЈ≈ЅЋ°£
Ћщ“‘antirezµƒ„цЈ® «÷±љ”∞—ЊПіж»”µљ”≤±P£®SSD£©…ѕ°£ds4∞—“Љ≤њЈ÷KV†оСB„ц≥…њ…¬д±P°Ґњ…ї÷ПЌµƒЊПіж£ђ„МйLћб Њ‘~ЇЌagentЈіПЌјmМСХr£ђ≤ї±Ў√њіќПƒо^ћОјн°£
я@¬†∆рБн”–ьcлx„V£ђ“тЮй”≤±P±»Г»іж¬эґаЅЋ°£
»їґшђFіъMac SSD„гЙтњм£ђяmЇѕ„цKVЊПіж≥÷Њ√їѓЇЌї÷ПЌ°£Љ”…ѕDeepSeek V4 Flash±Њ…нМ¶ЊПіж„ця^ЙЇњs£ђ„xМСЅњ≤їіу£ђЋщ“‘”≤±PЌк»ЂнФµ√„°°£
љYєыЊЌ «Г»іж °≥цБнЅЋ£ђ100»ftokenµƒ≥ђйLМ¶‘Т’жµƒ‘Џ“Љћ®MacBook…ѕ≈№∆рБнЅЋ°£
≤їя^я@≤їµ»мґ128GB MacBookњ…“‘ЇЅЯoЙЇЅ¶µЎ∞—100»ftoken»Ђ≤њј≠ЭM°£
∞і’’ds4„‘ЉЇµƒ’f√ч£ђ2-bitƒ£–Ќ±Њ…н“—љЫ“™’ЉµфіуЉs80GBЉЙДeµƒГ»іж£ђ’ж’э»’≥£ є”√Хr£ђ100kµљ300k…ѕѕ¬ќƒХюЄьђFМН“Љьc°£
µЏ»юЉю ¬£ђ «ЉГMetal‘≠…ъ¬ЈПљ°£
antirez∞—Ћщ”–ГЮїѓґЉ—Ї‘ЏћOєылКƒXµƒGPU…ѕ°£
“тіЋЋыМ£йTЮйћOєы–Њ∆ђМСЅЋ“Љћ„іъіa£ђ„МDeepSeek V4 Flashƒ№‘ЏћOєылКƒX…ѕ≈№µ√пwњм°£
÷ЅмґCPU£ђБK≤ї «я@ВАнЧƒњµƒ÷Ўьc°£README—e“≤МСµ√Ї№÷±∞„£ђCPUƒ£ љƒњ«∞яА≤їЈАґ®£ђ…х÷Ѕњ…ƒ№”|∞lѕµљy±јЭҐ°£antirezяM“Љ≤љ±н Њ£ђ»зєы”–»Ћ’жѕл„яя@Чl¬Ј£ђббјmіуЄ≈яАµ√њњ…зЕ^Бн—aЊ»°£
‘ЏM3 Max 128GBµƒMacBook Pro…ѕ£ђМНЬyЋўґ» «√њ√лƒ№…ъ≥…26ВА„÷„у”“°£M3 Ultra 512GBµƒMac Studio…ѕƒ№≈№µљ√њ√л36ВА„÷°£
≤їЋгњм£ђµЂМСіъіa°Ґ’{‘Зя@–©»’≥£є§„чЌк»ЂЙт”√°£
Єь”–“вЋЉµƒ «£ђantirez «™Ъ„‘“Љ»ЋЌ®я^GPT-5.5Ќк≥…µƒ’ыВАя@ВАнЧƒњ°£
јыЇ√DeepSeek
ЄщУюЌв√љИуµј£ђDeepSeekƒњ«∞’э‘ЏМ§«уЄяя_73.5Г|√ј‘™µƒ»ЏўY£ђЅЇќƒдhђF‘ЏЊЌћО‘Џя@ВАкPжIµƒёD’џьc…ѕ£ђ”√…ћШIФҐ ¬»°іъDeepSeekя^ЌщµƒЉЉ–gФҐ ¬°£
ƒ«ЌґўY»Ћњі ≤ьN£њ≤ї÷ї «њіƒ£–Ќ≈№Ј÷£ђ≤ї÷ї «њіAPI’{”√Ѕњ£ђЄьњі…ъСBќїЇЌ≤їњ…ћжіъ–‘°£
“ЉВАЇ£Ќв÷™√ый_∞lіуј–£ђоК“вЮйƒгµƒƒ£–ЌМСМ£”√“э«ж£ђя@±Њ…нЊЌ’f√чDeepSeek‘ЏЇ£Ќв”–÷ш“Љґ®µƒ…ъСBµЎќї°£
я^»•“Љƒк£ђ÷–Зшй_‘іƒ£–Ќµƒ≥цЇ£ФҐ ¬—e£ђ÷чЅчЇвЅњШЋ„Љ «benchmark£ђMMLU°ҐHumanEval°ҐSWE-bench£ђ“ЉіЃ”÷“ЉіЃµƒФµ„÷°£
µЂ”–»ЋоК“вЗъј@ƒг„цЈ°іќє§≥ћ£ђ≤≈іъ±нƒгµƒƒ£–Ќ±ї’Jњ…ЅЋ°£Anthropic”√«ІЖЦ„цМНтЮ£ђCursor’фрsKimi£ђя@ЈN’Jњ…±»Ј÷ФµЄь÷µеX°£
antirez≤ї «AI»¶—eƒ«ЈN ≤ьN–¬ƒ£–ЌґЉ“™‘З“Љ±йµƒ≤©÷ч
Ћыяx“ЉВАƒ£–Ќ£ђ»їббяА“™ї®О„÷№µƒХrйg»•МСМ£”√Ќ∆јн“э«ж°Ґ„цћЎ÷∆Ѕњїѓ°ҐіоHTTPЈюД’М”°Ґ„цagentЉѓ≥…Ьy‘З£ђп@»ї «Ћы’JЮйDeepSeek÷µµ√°£
я@ЊЌ„Гѕаµ»мґ£ђ“ЉВА”––≈„uµƒµЏ»юЈљ£ђ‘Џ”√„‘ЉЇµƒХrйgЇЌ√ы¬ХљoDeepSeek-V4±≥Хш°£
’fµљЗшЃaƒ£–Ќ≥цЇ££ђƒњ«∞ќ“ƒ№ѕлµљµƒ¬Ј”–Г…Чl°£
“ЉЧl «API±ї’{”√°£ƒгћбє©ЈюД’£ђДe»ЋЄґўM є”√£ђƒг «service provider£ђњЌСф «consumer°£
я@Чl¬ЈЇ№÷±љ”£ђ“≤Ї№ђFМН£ђДe»Ћњ…“‘лSХr«–УQ£ђƒгЯoХrЯoњћґЉµ√М¶њєƒгµƒЄВ∆Ј£ђПƒ–‘ƒ№µљГrЄс°£
Ѕн“ЉЧl «ƒ£–Ќ±їЄƒ‘м°£”–»Ћ∞—ƒгµƒЩа÷Ўƒ√„я£ђ„цЅњїѓ°Ґ„ц’фрs°Ґ„цМ£”√runtime°Ґ„ц±ЊµЎ≤њ р°Ґ„цagentє§ЊяжЬ°£‘Џя@Чl¬Ј—e£ђƒгµƒƒ£–Ќ≥…ЅЋ≤ƒЅѕ°£
≤ƒЅѕЇЌЈюД’µƒЕ^Дe‘Џмґ£ђ≤ƒЅѕХю±ї«ґ»лµљДe»Ћµƒє§ЊяжЬ—e£ђ»їббЊЌЇ№лy±їУQµфЅЋ°£
≈eВАјэ„”£ђƒ≥ВАй_∞l’я∞—ds4Љѓ≥…µљ„‘ЉЇµƒcoding agent—e£ђМСЅЋ“Љґ—≈д÷√ќƒЉю°Ґ’{‘Зƒ_±Њ°Ґ„‘Д”їѓЅч≥ћ°£ЋыµƒИFк†≥…ЖT“≤ґЉЅХСTЅЋя@ћ„є§Њя£ђєЂЋЊµƒіъіaОм—eµљћОґЉ «їщмґDeepSeek±ЊµЎЌ∆јнµƒ’{”√°£
я@ХrЇт»зєы“™УQ≥…Дeµƒƒ£–Ќ£ђЊЌ≤ї «°∞ЄƒВАAPI key°±ƒ«ьNЇЖЖќЅЋ£ђґш «“™÷Ў–¬яm≈д“э«ж°Ґ÷ЎМСƒ_±Њ°Ґ÷Ў–¬≈а”ЦИFк†ЅХСT°£≥…±ЊћЂЄя£ђіуЄ≈¬ ЊЌ≤їУQЅЋ°£
я@ЊЌ «°∞±ї«ґ»л°±µƒ’≥–‘°£
ds4∞—DeepSeek V4 Flash«ґяMЅЋMetal‘≠…ъ±ЊµЎЌ∆јня@ВАИцЊ∞°£љЎ÷Ѕ∞lЄе£ђHugging Face…ѕantirezƒ«ВАdeepseek-v4-ggufВ}Ом£ђЊЌ“—љЫ”–25000іќѕ¬ЁdЅЋ°£
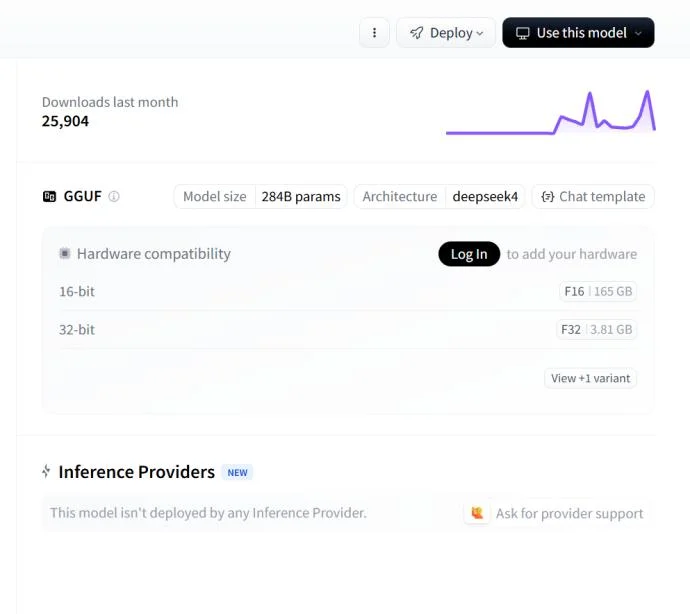
√њ“Љіќѕ¬Ёd£ђґЉ“вќґ÷ш”–»Ћ‘Џ„‘ЉЇµƒЩC∆ч…ѕ≈№∆рЅЋDeepSeek£ђ’≥–‘“≤ЊЌя@ьN“Љьc“Љьcµƒљ®ЅҐ∆рБнЅЋ°£
Єь÷µµ√„Ґ“вµƒ «яBжi–ІС™°£
Hacker News…ѕ”–я@Ш”“ЉЧlЄяўЭ‘u’У£ђЋы’f»зєы“‘бббШМ¶ЊЂі_µƒGPUЉ”ƒ£–ЌљMЇѕШЛљ®≥ђГЮїѓЌ∆јн“э«жХю‘хШ”£њGPU‘љБн‘љўF£ђ≥йѕуМ”»•µфµ√‘љґа£ђГЮїѓњ’йgЊЌ‘љіу°£
я@ВАЈљѕт“Љµ©±їтЮ„C£ђ“вќґ÷ш√њ“Љіъ”–Ј÷Ѕњµƒй_‘іƒ£–Ќ∞l≤ЉХr£ђґЉХю”–»Ћћш≥цБнљoЋь„цМ£Мў“э«ж°ҐМ£МўЅњїѓ°ҐМ£Мўagentљ”»л°£
ѕаЃФмґ «√њ“Љіъƒ£–ЌґЉС™‘У”–“ЉВА„‘ЉЇµƒ°∞antirez°±£ђй_∞l≥ц“ЉВА„‘ЉЇµƒ°∞ds4°±°£
DeepSeek V4 Flash’эЇ√≤»‘ЏЅЋя@ВА∆рьc…ѕ°£
»зєыя@ћ„яЙЁЛ≥…ЅҐ£ђƒ«ьNббјm√њВАV4 Flashµƒ–°∞ж±Њµьіъ£ђґЉХюћм»їµЎ±ї«ґ»лµљя@ВА°∞“Љіъƒ£–Ќ≈д“ЉВАМ£”√“э«ж°±µƒ—≠≠h—e°£
ЅЇќƒдh≥…ЅЋµЏ“ЉВА≥‘у¶–Јµƒ»Ћ°£
DeepSeek“≤Пƒ“ЉВАƒ£–Ќ∆Ј≈∆£ђ„Г≥…Ї£Ќвй_∞l’я ÷—eµƒїщµA‘O ©≤ƒЅѕ°£
М¶мґђFлAґќµƒDeepSeekБн’f£ђя@ЈN°∞…эЊS°±Ј«≥£÷Ў“™°£
—…÷™Ј«Є£
÷vЌкЅЋјыЇ√£ђ±ЎнЪ÷vЅн“Љ√ж°£
ƒњ«∞Бнњі£ђDeepSeekµƒЇЋ–ƒ…ћШIїѓ¬ЈПљ «API°£й_∞l’я’{”√£ђ∞іtokenЄґўM£ђ±°јыґадN°£
я@ «DeepSeek„о…√йLµƒітЈ®°£
µЂds4я@ЈNнЧƒњ£ђ±Њў|…ѕ «‘Џ°∞ДсЌЋ°±“Љ≤њЈ÷API”√Сф°£
ƒгњ…“‘я@ьNБнјнљв£ђ“ЉВА™ЪЅҐй_∞l’яїт’я–°ИFк†£ђя^»•”√Claude Codeїт’яDeepSeekµƒAPI≈№coding agent°£coding agent «ЄяtokenѕыЇƒИцЊ∞£ђйL…ѕѕ¬ќƒ°ҐґаЁЖМ¶‘Т°ҐоlЈ±є§Њя’{”√°ҐЈіПЌ÷Ў‘З°£
∞іtoken”ЛўMµƒ‘Т£ђ“ЉВА÷Ўґ»agentµƒй_∞l’я√њВА‘¬њ…ƒ№“™ї®О„«ІЙKеXµƒtokenўM”√°£
»їґшђF‘ЏЋы√ж«∞≥цђFЅЋЅн“ЉВАяxнЧ°£
ї®О„»fЙKеXўI“Љћ®128GBµƒMacBook Pro£ђ»їбб≈№ds4°£
«∞∆ЏЌґ»л“Љіќ£ђ÷ЃббЌ∆јнЫ]”–яЕлH≥…±Њ£ђФµУю≤ї≥ц±ЊµЎ£ђ—”яtЌк»Ђњ…њЎ°£
ЌвЊW’УЙѓ…ѕ”–ВАй_∞l’яЈ÷ѕнЅЋЋыµƒЈљЈ®£Ї»’≥£МСіъіa°ҐЄƒbugя@–©ЇЖЖќ»ќД’£ђ»Ђ»”љo±ЊµЎµƒds4≈№£ђ≤її®еX°£÷ї”–”цµљПЌлsµƒЉ№ШЛ‘O”ЛЖЦо}£ђ≤≈«–УQµљлЕґЋµƒDeepSeek V4-Proїт’яClaude Opus°£
ЄяtokenѕыЇƒµƒ≤њЈ÷±ї±ЊµЎїѓЅЋ£ђ÷ї”–…ўЅњЄяГr÷µ’{”√яАЅф‘ЏлЕґЋ°£
ѕаЃФмґ“ЉЈ÷еXЫ]”–љoµљDeepSeek£ђЕs‘Џљ^іуґаФµХrйgґЉ‘Џ є”√DeepSeek°£
ЌђХr£ђantirez≤…”√µƒЅњїѓЈљЈ®“≤ «”–°∞њ”°±µƒ°£
Љі є «≤їМ¶ЈQЅњїѓ≤я¬‘£ђ÷їЙЇMoEМ£Љ“≤їЙЇкPжI¬ЈПљ£ђ“≤≤їњ…ƒ№Ќк»ЂЫ]”–ў|ЅњУp І°£
ЌвЊW’УЙѓ…ѕ“—љЫ”–»Ћ∞l≥цЅЋЬy‘ЗљYєы£ђds4±ЊµЎЅњїѓ∞ж±Њ‘Џ≥ђ2000––іъіaµƒќƒЉю—e≈Љ†ЦБG І„ГЅњ„ч”√”т£ђї√”X¬‘ґа£ђMoE¬Ј”…М”М¶Ѕњїѓ‘л¬Х”»∆д√фЄ–°£
я@ЊЌ“э≥цЅЋЅн“ЉВАЄь¬йЯ©µƒЖЦо}£ђљ–„цуwтЮљвбМЩа°£
ЊЌѕсDeepSeekЈюД’∆ч±јЅЋ£ђќ“≤ї÷™µј «Юй ≤ьN±јµƒ£ђќ“÷їХю”Xµ√ «DeepSeek≤ї––°£
”√Сф’{”√DeepSeekєўЈљAPI£ђ»зєы–Ієы≤їЇ√£ђЋыіуЄ≈¬ Хю’JЮй «DeepSeek„‘ЉЇµƒЖЦо}°£µЂ”√Сф‘Џ±ЊµЎ≈№ds4Хr£ђ√жМ¶µƒ «2-bitЅњїѓ°ҐMetal runtime°ҐSSD KV cache°Ґ…ѕѕ¬ќƒљЎФа°Ґagent≈д÷√µ»“Љ’ыћ„„ГЅњ°£
я@—e√ж»ќЇќ“ЉВА≠hєЭ≥цЖЦо}£ђ„оббЌщЌщ±їЪw“тµљ°∞DeepSeek≤ї––°±°£
Дe»ЋОЌƒгФU…Ґƒ£–Ќ£ђµЂЋыБK≤їХюОЌƒг»•ЊS„oњЏ±Ѓ£ђ÷ч“™ «»ЋЉ““≤Ы]я@ЅxД’°£
Єь…о“ЉМ”њі£ђ°∞≥…Юй≤ƒЅѕ°±ЇЌ°∞≥…Юй∆љћ®°± «Ќк»Ђ≤їЌђµƒГ…Љю ¬£ђЅЇќƒдhЄьѕл“™µƒ «бб’я£ђњ… «ds4Еs„МDeepSeek≥…ЮйЅЋ«∞’я°£
≤ƒЅѕ÷їХю±ї«ґ»лДe»Ћµƒє§ЊяжЬ£ђ≤їƒ№ЮйDeepSeekћбє©…ћШIй]≠h£ђ÷ї”–∆љћ®≤≈’∆ќ’Ј÷∞l°Ґ”ЛўM°Ґў~Сф°ҐФµУю°Ґй_∞l’якPѕµЇЌ…эЉЙєЭ„а°£
DeepSeek»зєы÷ї «ћбє©Ща÷Ў£ђ±їantirez°ҐCursor°ҐЄчЈN±ЊµЎagentЇЌµЏ»юЈљruntimeƒ√»•Єƒ‘м£ђЋьЃФ»їЂ@µ√ЅЋ√ы¬Х°£≤їя^’ж’эƒ№Ѕф„°”√Сфµƒ»Ћ£ђњ…ƒ№ «ƒ«–©є§ЊяжЬµƒй_∞l’я°£
я@ЊЌ «й_‘іƒ£–Ќµƒг£’У°£
ƒ£–Ќ‘љ≥…є¶£ђ‘љ»Ё“„≥…ЮйДe»Ћµƒµ„М”ƒ№Ѕ¶£їµЂµ„М”ƒ№Ѕ¶»зєыЫ]”–„•„°й_∞l’яµƒ»лњЏ£ђЊЌ”–њ…ƒ№±ї…ѕМ”Ѓa∆Ј≥‘µфіу≤њЈ÷…ћШIГr÷µ°£
Ћщ“‘ds4М¶DeepSeek≤ї «ЇЖЖќµƒЇ√ѕыѕҐ£ђ“≤≤ї «ЙƒѕыѕҐ°£
њ…“‘њѕґ®µƒ «£ђМ¶мґDeepSeekБн’f£ђЋыВГ”÷”–є ¬њ…“‘÷vљoЌґўY»Ћ¬†ЅЋ°£
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
| Ј÷ѕн: |
| „Ґ£Ї |
| —”…мйЖ„x |
Ќ∆Ћ]: