




[єюЈр] єюЈр÷Ў∞х∞lђF:AI‘\Фа’жМН≤°јэ„Љі_¬ ≥ђбt…ъ
єюЈр—–Њњµ«…ѕScience£Ї‘Џ76√ы’жМНЉ±‘\їЉ’яµƒлp√§М¶ЫQ÷–£ђOpenAI o1‘\Фа„Љі_¬ 67%ƒлЙЇ»ЋоРбt…ъµƒ50%£ђ÷ќѓЯЈљ∞Єµ√Ј÷89%М¶34%Єь «Фа—¬ љоIѕ»°™°™µЂAIяАњі≤ї“КїЉ’яµƒƒШ…ЂЇЌЌіња£ђ’ж’эµƒ„ГЄп≤ї «°ЄAIЏAЅЋ°є£ђґш «Љ±‘\ “’э‘Џ„яѕт°Єбt…ъ°ЅїЉ’я°ЅAI°є»юЈљє≤÷ќµƒ–¬Јґ љ°£ДВДВ£ђ“Љоw÷Ў∞х’®ПЧ‘“яMЅЋ»Ђ«тбtѓЯ»¶°£єюЈріуМWбtМW‘Ї¬УЇѕЎРЋє“‘…ЂЅ–≈ЃИћ ¬бtѓЯ÷––ƒ£®Beth Israel Deaconess Medical Center£©£ђ∞—“ЉнЧЅо»Ћ„шЅҐ≤ї∞≤µƒ—–ЊњљYєы∞l‘ЏЅЋ°ґScience°Ј…ѕ°£

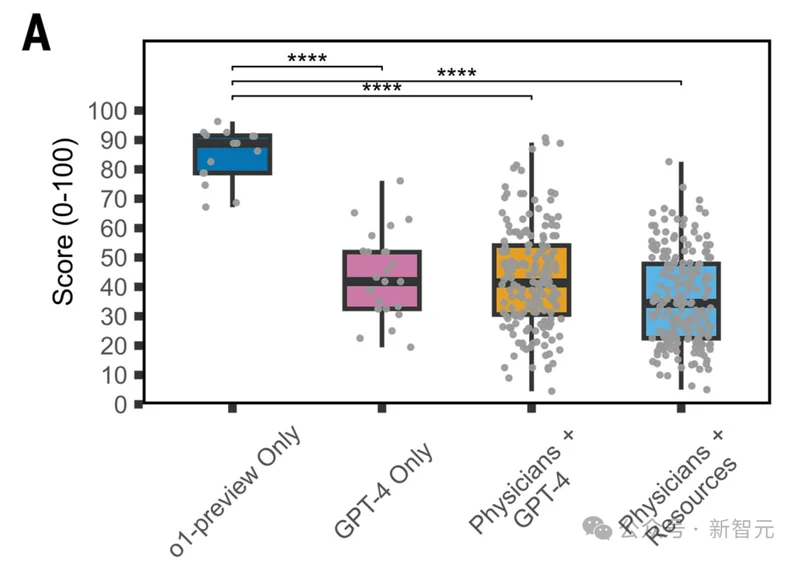
‘ЏЉ±‘\ “µƒ’жМНЈ÷‘\ИцЊ∞÷–£ђOpenAIµƒo1Ќ∆јнƒ£–Ќ‘\Фа„Љі_¬ я_µљ67%£ђґшГ…ќїљЫтЮЎSЄїµƒГ»њ∆÷ч÷ќбt…ъ£ђ“ЉВА55%£ђ“ЉВА50%°£
AIЏAЅЋ°£
≤ї «‘Џ„цо}£ђ≤ї «‘ЏњЉ‘З£ђґш «‘Џ’浴’жШМµƒЉ±‘\ “—e°£

Єь‘ъ–ƒµƒФµУюяА‘Џбб√ж°™°™‘Џ÷∆ґ®÷ќѓЯє№јнЈљ∞ЄµƒЬy‘З÷–£ђo1ƒ√ЅЋ89%£ђґш»ЋоРбt…ъ є”√ВчљyўY‘іЁo÷ъбб£ђ÷–ќїФµ÷ї”–34%°£
≤оЊа≤ї «“Љ–«∞льc£ђ «Г…±ґґа°£
я@≤ї «“ЉВАAIєЂЋЊµƒ„‘ўu„‘’F£ђя@ «єюЈрбtМW‘Ї†њо^°ҐнФЉЙМW–g∆Џњѓ±≥Хш°Ґлp√§‘uМПі_’JµƒљYєы°£
—–Њњ’УќƒµƒЌ®”Н„ч’я°ҐєюЈрбtМW‘ЇAIМНтЮ “ЎУЎЯ»ЋArjun Manrai’fЅЋ“ЉЊд“вќґ…ойLµƒ‘Т£Ї°Єќ“ВГ”√О„ЇхЋщ”–їщ„ЉЬy‘ЗЅЋя@ВАAIƒ£–Ќ£ђЋь≥ђ‘љЅЋіЋ«∞Ћщ”–ƒ£–ЌЇЌбt…ъїщЊА°£°є

[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
Яo‘u’У≤ї–¬¬Д£ђ∞l±н“Љѕ¬ƒъµƒ“в“К∞…
‘ЏЉ±‘\ “µƒ’жМНЈ÷‘\ИцЊ∞÷–£ђOpenAIµƒo1Ќ∆јнƒ£–Ќ‘\Фа„Љі_¬ я_µљ67%£ђґшГ…ќїљЫтЮЎSЄїµƒГ»њ∆÷ч÷ќбt…ъ£ђ“ЉВА55%£ђ“ЉВА50%°£
AIЏAЅЋ°£
≤ї «‘Џ„цо}£ђ≤ї «‘ЏњЉ‘З£ђґш «‘Џ’浴’жШМµƒЉ±‘\ “—e°£
Єь‘ъ–ƒµƒФµУюяА‘Џбб√ж°™°™‘Џ÷∆ґ®÷ќѓЯє№јнЈљ∞ЄµƒЬy‘З÷–£ђo1ƒ√ЅЋ89%£ђґш»ЋоРбt…ъ є”√ВчљyўY‘іЁo÷ъбб£ђ÷–ќїФµ÷ї”–34%°£
≤оЊа≤ї «“Љ–«∞льc£ђ «Г…±ґґа°£
я@≤ї «“ЉВАAIєЂЋЊµƒ„‘ўu„‘’F£ђя@ «єюЈрбtМW‘Ї†њо^°ҐнФЉЙМW–g∆Џњѓ±≥Хш°Ґлp√§‘uМПі_’JµƒљYєы°£
—–Њњ’УќƒµƒЌ®”Н„ч’я°ҐєюЈрбtМW‘ЇAIМНтЮ “ЎУЎЯ»ЋArjun Manrai’fЅЋ“ЉЊд“вќґ…ойLµƒ‘Т£Ї°Єќ“ВГ”√О„ЇхЋщ”–їщ„ЉЬy‘ЗЅЋя@ВАAIƒ£–Ќ£ђЋь≥ђ‘љЅЋіЋ«∞Ћщ”–ƒ£–ЌЇЌбt…ъїщЊА°£°є
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
| Ј÷ѕн: |
| „Ґ£Ї | ‘ЏіЋнУйЖ„x»Ђќƒ |
| —”…мйЖ„x | Єьґа... |
Ќ∆Ћ]: