




[єюЈр] єюЈр÷Ў∞х∞lђF:AI‘\Фа’жМН≤°јэ„Љі_¬ ≥ђбt…ъ
єюЈр—–Њњµ«…ѕScience£Ї‘Џ76√ы’жМНЉ±‘\їЉ’яµƒлp√§М¶ЫQ÷–£ђOpenAI o1‘\Фа„Љі_¬ 67%ƒлЙЇ»ЋоРбt…ъµƒ50%£ђ÷ќѓЯЈљ∞Єµ√Ј÷89%М¶34%Єь «Фа—¬ љоIѕ»°™°™µЂAIяАњі≤ї“КїЉ’яµƒƒШ…ЂЇЌЌіња£ђ’ж’эµƒ„ГЄп≤ї «°ЄAIЏAЅЋ°є£ђґш «Љ±‘\ “’э‘Џ„яѕт°Єбt…ъ°ЅїЉ’я°ЅAI°є»юЈљє≤÷ќµƒ–¬Јґ љ°£ДВДВ£ђ“Љоw÷Ў∞х’®ПЧ‘“яMЅЋ»Ђ«тбtѓЯ»¶°£єюЈріуМWбtМW‘Ї¬УЇѕЎРЋє“‘…ЂЅ–≈ЃИћ ¬бtѓЯ÷––ƒ£®Beth Israel Deaconess Medical Center£©£ђ∞—“ЉнЧЅо»Ћ„шЅҐ≤ї∞≤µƒ—–ЊњљYєы∞l‘ЏЅЋ°ґScience°Ј…ѕ°£

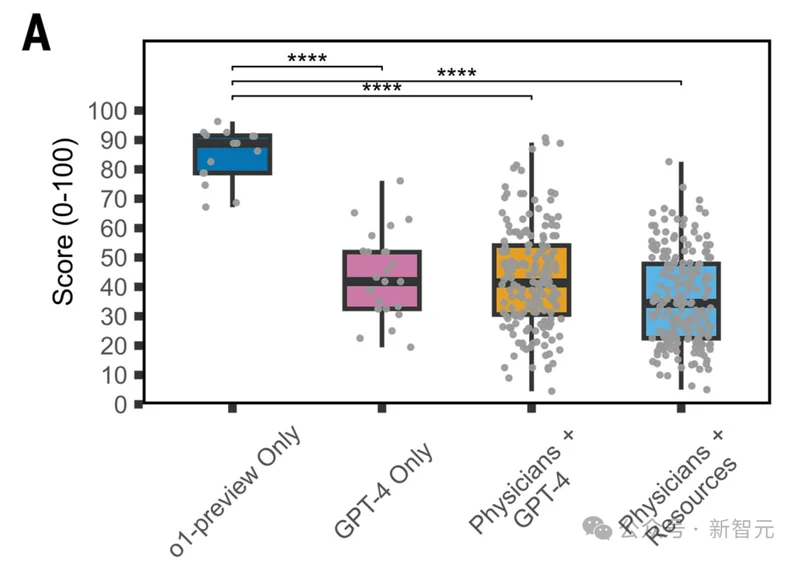
‘ЏЉ±‘\ “µƒ’жМНЈ÷‘\ИцЊ∞÷–£ђOpenAIµƒo1Ќ∆јнƒ£–Ќ‘\Фа„Љі_¬ я_µљ67%£ђґшГ…ќїљЫтЮЎSЄїµƒГ»њ∆÷ч÷ќбt…ъ£ђ“ЉВА55%£ђ“ЉВА50%°£
AIЏAЅЋ°£
≤ї «‘Џ„цо}£ђ≤ї «‘ЏњЉ‘З£ђґш «‘Џ’浴’жШМµƒЉ±‘\ “—e°£

Єь‘ъ–ƒµƒФµУюяА‘Џбб√ж°™°™‘Џ÷∆ґ®÷ќѓЯє№јнЈљ∞ЄµƒЬy‘З÷–£ђo1ƒ√ЅЋ89%£ђґш»ЋоРбt…ъ є”√ВчљyўY‘іЁo÷ъбб£ђ÷–ќїФµ÷ї”–34%°£
≤оЊа≤ї «“Љ–«∞льc£ђ «Г…±ґґа°£
я@≤ї «“ЉВАAIєЂЋЊµƒ„‘ўu„‘’F£ђя@ «єюЈрбtМW‘Ї†њо^°ҐнФЉЙМW–g∆Џњѓ±≥Хш°Ґлp√§‘uМПі_’JµƒљYєы°£
—–Њњ’УќƒµƒЌ®”Н„ч’я°ҐєюЈрбtМW‘ЇAIМНтЮ “ЎУЎЯ»ЋArjun Manrai’fЅЋ“ЉЊд“вќґ…ойLµƒ‘Т£Ї°Єќ“ВГ”√О„ЇхЋщ”–їщ„ЉЬy‘ЗЅЋя@ВАAIƒ£–Ќ£ђЋь≥ђ‘љЅЋіЋ«∞Ћщ”–ƒ£–ЌЇЌбt…ъїщЊА°£°є

“ЉВАХrіъµƒЅ—њp£ђЊЌя@ьN±їЋЇй_ЅЋ°£
76ВА’жМНїЉ’я£ђЅгоAћОјн£ђлp√§М¶ЫQ
я@нЧ—–Њњ„о”≤ЇЋµƒµЎЈљ‘Џмґ£ЇЋь≤ї «ƒ√ЊЂ–ƒ’ыјнµƒљћњ∆Хш≤°јэ»•њЉAI£ђґш «÷±љ”∞—Љ±‘\ “—e„о‘≠ Љ°Ґ„оїмБyµƒлК„”≤°Ъv»”љoЅЋЩC∆ч°£
—–ЊњИFк†ПƒЎРЋє“‘…ЂЅ–Љ±‘\њ∆лSЩCяx»°ЅЋ76√ы’жМНїЉ’я£ђ‘Џ»юВАкPжI‘\ФаєЭьcяM––М¶±»°™°™Љ±‘\Ј÷‘\£®їЉ’яДВяMйT£©°ҐЉ±‘\бt…ъ „іќљ”‘\°Ґ“‘Љ∞ ’÷ќ»л‘ЇїтяMICU°£
√њВАєЭьc£ђГ…ќїГ»њ∆÷ч÷ќбt…ъЇЌOpenAIµƒo1°Ґ4oƒ£–ЌЌђХrљo≥циbДe‘\Фа£ђ√њЈљ„оґаЅ–5ВАњ…ƒ№‘\Фа°£
кPжIЉЪєЭ «£Ї—–Њњ»ЋЖTМ¶ФµУюЅгоAћОјн°£
’Уќƒ√чі_МСµј£ђAIƒ£–Ќљ” ’µљµƒ–≈ѕҐЇЌбt…ъњіµљµƒлК„”≤°ЪvЌк»Ђ“Љ÷¬°™°™ƒ«–©ЅиБyµƒ°Ґ»± Іµƒ°Ґ≥дЭM‘л¬Хµƒ’жМН≈Rі≤ФµУю°£

»їбб£ђ”…ЅнЌвГ…√ы÷ч÷ќбt…ъяM––°Є√§‘u°є°™°™ЋыВГ≤ї÷™µјƒƒВА‘\ФаБн„‘»ЋоР°ҐƒƒВАБн„‘AI°£
√§‘uљYєып@ Њ£ђ‘uМПбt…ъО„ЇхЌк»ЂЯoЈ®Ј÷±ж‘\ФаБн‘і£Ї“Љќїбt…ъ≤¬М¶AI/»ЋоРµƒ„Љі_¬ ГH15.2%£®83.6%µƒХrЇтяxЅЋ°ЄЈ÷≤ї«е°є£©£ђЅн“ЉќїЄь’FПИ£ђ÷ї”–3.1%£®94.4%°ЄЈ÷≤ї«е°є£©°£
УQЊд‘Т’f£ђAIМСµƒ‘\Фа£ђяBўY…обt…ъґЉњі≤ї≥ц «ЩC∆ч…ъ≥…µƒ°£
‘Џя@Ш”µƒЗјњЅЧlЉюѕ¬£ђo1ƒ£–Ќ‘ЏЉ±‘\Ј÷‘\лAґќ°™°™–≈ѕҐ„о…ў°ҐХrйg„оЊo°ҐЫQ≤я„окPжIµƒ≠hєЭ°™°™љo≥цЅЋ67.1%µƒ„Љі_¬ £®∞ьЇђЊЂі_‘\ФаїтЈ«≥£љ”љьµƒ‘\Фа£©°£
Г…ќї»ЋоРбt…ъЈ÷Дe «55.3%ЇЌ50.0%°£
лS÷ш–≈ѕҐ÷рЭu‘цґа£ђЋщ”–»Ћµƒ±нђFґЉ‘Џћб…э£Їµљ»л‘ЇлAґќ£ђo1„Љі_¬ …э÷Ѕ81.6%£ђбt…ъЈ÷ДeЮй78.9%ЇЌ69.7%°£
µЂ≤оЊа ЉљKіж‘Џ£ђґш«“‘Џ–≈ѕҐ„оЕTЈ¶µƒ≥х ЉлAґќ≤оЊа„оіу°£
я@«°«° «„оњ…≈¬µƒ∞lђF°™°™Љ±‘\„о“™√ьµƒЊЌ «°Є«∞О„Ј÷жR°є£ђїЉ’яДВ±їЌ∆яMБн£ђ–≈ѕҐЋй∆ђїѓ£ђ…ъЋјЎькP£ђбt…ъ–и“™‘ЏШOґ»≤їі_ґ®÷–„ц≥ц≈–Фа°£
ґш«°«°‘Џя@ВА≠hєЭ£ђAI±нђF„оЌї≥ц°£
Љ±‘\бt…ъ≤їО÷ЅЋ£Їƒ√Г»њ∆бt…ъЄъAI±»£ђƒ№’f√ч ≤ьN£њ
’Уќƒ∞l≤Љбб£ђ“Љќї√ыљ–Kristen PanthaganiµƒЉ±‘\њ∆бt…ъ‘Џ…зљї√љуw…ѕ÷±љ”й_Сї£Їя@ «“ЉВА°Є±їя^ґ»≥і„чµƒ”–»§—–Њњ°є°£
ЋэµƒЇЋ–ƒў|“… «£Ї—–Њњ÷–ЇЌAIМ¶±»µƒ «Г»њ∆÷ч÷ќбt…ъ£ђ≤ї «Љ±‘\њ∆бt…ъ°£
°Є»зєыќ“ВГ“™ƒ√AIЇЌбt…ъµƒ≈Rі≤ƒ№Ѕ¶„ц±»Ё^£ђ÷Ѕ…ўС™‘Уƒ√Ќђ“ЉВАМ£њ∆µƒбt…ъБн±»°£ќ“≤їХюу@”†мґ“ЉВАіу’Z—‘ƒ£–Ќƒ№‘Џ…сљЫЌвњ∆µƒМ£њ∆њЉ‘З÷–ітФ°∆§ƒwњ∆бt…ъ£ђµЂя@БK≤їƒ№’f√ч ≤ьN°£°є
ЋэяА÷Є≥цЅЋЉ±‘\бtМWµƒ±Њў|яЙЁЛ£Ї°Є„чЮй“Љ√ыµЏ“ЉіќњіµљїЉ’яµƒЉ±‘\бt…ъ£ђќ“µƒ „“™ƒњШЋ≤ї «≤¬≥ц„ољK‘\Фа°£ќ“µƒ „“™ƒњШЋ «≈–Фаƒг «Јс”–“ЉЈNњ…ƒ№ХюЪҐЋјƒгµƒЉ≤≤°°£°є
я@ВАЈісg”–Ѕ¶ЅњЖб£њ
”–°£µЂ“≤–и“™„Ґ“в£ђ—–Њњ’Уќƒ±Њ…н“—љЫ≥–’JЅЋя@“ЉЊ÷ѕё–‘£ђґш«“’УќƒµƒЇЋ–ƒ’УьcПƒБн≤ї «°ЄAIњ…“‘ћжіъЉ±‘\бt…ъ°є£ђґш «°ЄAI‘Џ”–ѕё–≈ѕҐѕ¬µƒЌ∆јнƒ№Ѕ¶“—љЫя_µљ÷µµ√≈Rі≤‘ЗтЮµƒЋЃ∆љ°є°£
Љ±‘\бt…ъ‘ЏђFИц„цµƒяh≤ї÷є°Є≤¬≤°√ы°є°™°™ЋыВГ“™њіїЉ’яµƒ√ж…Ђ°Ґ¬†Їфќьµƒ¬Х“ф°ҐЄ– №ћџЌіµƒ≥ћґ»°Ґ≈–Фа…ъ√ьуw’чµƒќҐ√о„Гїѓ°£
я@–©ЉЪќҐµƒЈ«’Z—‘–≈ћЦ£ђ”–ХrЇт±»»ќЇќЩzтЮ÷ЄШЋґЉ÷Ў“™°£
“ЉВАљЫтЮЎSЄїµƒЉ±‘\бt…ъ„яяM≤°Јњ£ђТя“Љ—џїЉ’я£ђњ…ƒ№ЊЌ“—љЫ„ц≥цЅЋ80%µƒ≈–Фа°™°™я@ЈNƒ№Ѕ¶љ–°Є≈Rі≤÷±”X°є£®clinical gestalt£©£ђЋьБн„‘Фµ“‘»f”Лµƒ’жМНљ”‘\љЫтЮ£ђƒњ«∞Ы]”–»ќЇќAIƒ№ЙтПЌ÷∆°£
Manrai„‘ЉЇ“≤≥–’J£ђИFк†’э‘Џ—–ЊњAIћОјн”∞ѕсЇЌ∆дЋыЈ«ќƒ±Њ–≈ћЦµƒƒ№Ѕ¶£ђ°ЄњіµљЅЋњмЋўяM≤љµƒљYєы°є£ђµЂЊалx≈Rі≤≤њ ряА”–Ї№йLµƒ¬Ј°£
–ЅоDµƒ°ЄоA—‘°єљћ”Ц£ЇЈ≈…дњ∆бt…ъЫ]ѕ¬НП£ђЈіґшЄь√¶ЅЋ
’fµљAI»°іъбt…ъя@ВА‘То}£ђ≤їµ√≤їћб“ЉВАљЫµдµƒ°ЄітƒШ°є∞Єјэ°£
2016ƒк£ђAIљћЄЄ°Ґ÷ZЎР†Ц™Дµ√÷чGeoffrey Hinton’fЅЋ“ЉЊд’рД”бtМWљзµƒ‘Т£Ї»ЋВГђF‘ЏЊЌС™‘УЌ£÷є≈а”ЦЈ≈…дњ∆бt…ъЅЋ°£…оґ»МWЅХ‘ЏќйƒкГ»ЊЌХю±»Ј≈…дњ∆бt…ъ„цµ√ЄьЇ√£ђя@Ќк»Ђ «п@ґш“„“Кµƒ°£
я@Њд‘ТЃФХrЗШЌЋЅЋ≤ї…ў„ЉВдяxУсЈ≈…дњ∆µƒбtМW…ъ°£’ыВА2010ƒкіъбб∆Џ£ђ√љуw…ѕдБћм…wµЎґЉ «°ЄЈ≈…дњ∆ЉіМҐѕыЌц°єµƒќƒ’¬°£
∞ƒкя^»•ЅЋ°£
√ЈКW‘\ЋщµƒЈ≈…дњ∆бt…ъИFк†Пƒ2016ƒк÷Ѕљс‘цйLЅЋ55%£ђя_µљ400»Ћ°£√јЗшЈ≈…дМWХюоAЬy£ђќіБн30ƒкЈ≈…дњ∆бt…ъє©љoяАМҐ‘цйL26%°£
»Ђ«т„оіуµƒЈ≈…дњ∆бt…ъґћ»±’э‘Џ∞l…ъ°™°™≤ї «“тЮйAIУМ„яЅЋє§„ч£ђґш «“тЮйAI„М”∞ѕсЩz≤й„Гµ√Єь±гљЁ£ђЈіґшія…ъЅЋЄьґа–и«у°£
Hinton±Њ»ЋббБн“≤≥–’J„‘ЉЇ°Є’fµ√ћЂМТЈЇЅЋ°є°£
Ћы–ё’эЅЋоAЬy£ЇќіБнµƒбtМW”∞ѕсљв„xМҐ”…°ЄAIЇЌЈ≈…дњ∆бt…ъµƒљMЇѕ°єБнЌк≥…£ђAIХю„МЈ≈…дњ∆бt…ъ°Є–І¬ іуіућбЄя£ђЌђХrћб…э„Љі_¬ °є°£
я@ВАє ¬—e”–“ЉВА…оњћµƒљЫЭъМW‘≠јн°™°™В№ќƒЋєг£’У£ЇЃФ“ЉнЧЉЉ–g„Мƒ≥ЈNўY‘іµƒ є”√ЄьЄя–ІХr£ђя@ЈNўY‘іµƒњВ–и«уЈіґшњ…ƒ№іуЈщ‘цЉ”°£
”∞ѕс‘\Фа„Г±г“Ћ°Ґ„ГњмЅЋ£ђмґ «бt…ъй_ЅЋЄьґаЩz≤й£ђЈ≈…дњ∆бt…ъЈіґшЄь√¶ЅЋ°£
єюЈря@нЧ–¬—–Њњµƒ„ч’яВГп@»їќь»°ЅЋ–ЅоDµƒљћ”Ц°£
’УќƒЌ®”Н„ч’яManrai‘Џ–¬¬Д∞l≤ЉХю…ѕ√чі_’f£Ї°Єќ“ВГµƒ∞lђFБK≤ї“вќґ÷шAI»°іъбt…ъ£ђ±Mє№”––©ўuAIбtѓЯЃa∆ЈµƒєЂЋЊњ…ƒ№Хюя@ьN’f°£°є
є≤ЌђЌ®”Н„ч’я°ҐЎРЋє“‘…ЂЅ–AIнЧƒњЎУЎЯ»ЋAdam RodmanДtЄь÷±∞„£Ї°Єƒњ«∞AI‘\ФаЫ]”–»ќЇќ’э љµƒЖЦЎЯњтЉ№°£їЉ’яѕл“™µƒ «»ЋБн“эМІЋыВГґ»я^…ъЋјЎькPµƒЫQ≤я£ђ“эМІЋыВГ√жМ¶∆Dлyµƒ÷ќѓЯяxУс°£°є
≤ї «°ЄAIЏAЅЋ°єґш «бtѓЯЫQ≤яЩа‘Џ÷ЎљM
Ую√јЗшбtМWХю£®AMA£©2026ƒк’{≤й£ђ≥ђя^80%µƒ√јЗшбt…ъ“—љЫ‘Џ¬ЪШI÷– є”√AI°™°™ «2023ƒкµƒГ…±ґ°£
17%µƒбt…ъ є”√AIяM––°ЄЁo÷ъ‘\Фа°є°£
2025ƒкµƒ“ЉнЧElsevier—–Њњ∞lђF£ђ20%µƒ≈Rі≤бt…ъ“—љЫ‘Џѕтіу’Z—‘ƒ£–ЌМ§«у°ЄµЏЈ°“в“К°є°£
єюЈря@нЧ—–Њњ„C√ч£ђAI‘Џ–≈ѕҐ„оЕTЈ¶°ҐЫQ≤я„оЊo∆»µƒЉ±‘\ИцЊ∞÷–£ђЌ∆јнƒ№Ѕ¶“—љЫ≥ђя^ЅЋ»ЋоРбt…ъ°£
»юВАФµУюѓBЉ”‘Џ“Љ∆р£ђ÷Єѕт“ЉВА«еќъµƒЏЕДЁ£ЇбtѓЯЫQ≤яµƒЩаЅ¶љYШЛ’э‘Џ∞l…ъЄщ±Њ–‘µƒ÷ЎљM°£
я^»•µƒЉ±‘\ “ƒ£ љ «£ЇїЉ’яяMБн°ъбt…ъ≈–Фа°ъ„ц≥цЫQ≤я°£
ќіБнµƒƒ£ љњ…ƒ№„Г≥…£ЇїЉ’яяMБн°ъAIњмЋўТя√илК„”≤°Ъvљo≥ц≥х≤љ≈–Фа°ъбt…ъљYЇѕ≈Rі≤”^≤мЇЌAIљ®„h„ц≥цЫQ≤я°ъїЉ’яЕҐ≈c”С’У÷ќѓЯЈљ∞Є°£
—–Њњ„ч’яRodmanоAЬy£ђќіБнХю≥цђF»юЈNЈ÷їѓ£Ї“Љ≤њЈ÷»ќД’»ЋоР≥÷јm„цµ√ЄьЇ√£ђ“Љ≤њЈ÷»ќД’AI≥÷јm„цµ√ЄьЇ√£ђяА”–“Љ≤њЈ÷»ќД’–и“™»ЋЩCЕf„ч‘цПК°£
я@ЊЌ «—–Њњ’яЋщ’fµƒ°Єбt…ъ-їЉ’я-AI°є»юЈљЕf„чƒ£ љ°£
¬†∆рБнЇ№ѕс„‘Д”с{сВ°£
L2ЉЙДe°™°™AIЁo÷ъ»ЋоРЫQ≤я£їL3ЉЙДe°™°™AI÷чМІ°Ґ»ЋоР±Oґљ£їL4ЉЙДe°™°™ћЎґ®ИцЊ∞»Ђ„‘Д”°£
ƒњ«∞AI‘ЏбtѓЯоI”тіуЄ≈ћО‘ЏL2µљL3÷ЃйgµƒлAґќ£ЇЋь“—љЫƒ№‘Џ°Єќƒ„÷ јљз°є—eљo≥ц≥ђ‘љ»ЋоРµƒ≈–Фа£ђµЂ‘Џ’жМНµƒ°Ґґаƒ£СBµƒ≈Rі≤ИцЊ∞÷–£ђЋьяА–и“™»ЋоРµƒ—џЊ¶°ҐґъґдЇЌ÷±”XБн—aќї°£
AI’`‘\ЅЋ£ђ’lЎУЎЯ£њ
‘ЏЋщ”–”С’У÷–£ђ”–“ЉВАЈњйg—eµƒіуѕуЯo»ЋЄ“’э√ж”|≈ц£ЇAI≥цеeЅЋ£ђ’lБн≥–УъЎЯ»ќ£њ
Rodman‘Џљ” №°ґ–lИу°Ј≤…‘LХrћє—‘£Їƒњ«∞AI‘\ФаЫ]”–»ќЇќ’э љµƒЖЦЎЯњтЉ№°£
»зєы“Љ√ыбt…ъ’`‘\ЅЋ£ђ”–≥… мµƒбtѓЯЉmЉКћОјнуwѕµ°™°™їЉ’яњ…“‘Ќґ‘V°Ґњ…“‘‘V‘A°Ґбt…ъ√ж≈RИћ’’пLлU°£
µЂ»зєыAIљo≥цЅЋеe’`љ®„h£ђбt…ъ≤…Љ{ЅЋ£ђїЉ’я №µљЅЋВыЇ¶°™°™ «Ћгбt…ъµƒЎЯ»ќ£њAIєЂЋЊµƒЎЯ»ќ£њбt‘ЇµƒЎЯ»ќ£њяА «»юЈљє≤Уъ£њ
ЄьПЌлsµƒИцЊ∞ «£Ї»зєыAIљo≥цЅЋ’эі_љ®„h£ђµЂбt…ъЈсЫQЅЋAIµƒ≈–Фа°ҐИ‘≥÷„‘ЉЇµƒеe’`‘\Фа£ђМІ÷¬їЉ’я—”’`÷ќѓЯ°™°™іЋХrбt…ъ“™≤ї“™Юй°ЄЇц“ХAљ®„h°є≥–Уъо~ЌвЎЯ»ќ£њ
яА”–“ЉВАЄьл[±ќµƒпLлU£Їя^ґ»“јўЗ°£
ЃФбt…ъЅХСTЅЋAIљo≥цµƒЄя„Љі_¬ ≈–Фа£ђЋыВГµƒ™ЪЅҐЋЉњЉƒ№Ѕ¶Хю≤їХюЌЋїѓ£њЊЌѕсGPS„МЇ№ґа»ЋЖ ІЅЋ„‘÷чМІЇљƒ№Ѕ¶“ЉШ”£ђAIЁo÷ъ‘\Фа «ЈсХю„Мбt…ъµƒ≈Rі≤Ќ∆јн°ЄЉ°»в°є÷рЭuќЃњs£њ
я@–©ЖЦо}£ђƒњ«∞Ы]”–»ќЇќЗшЉ“”–«еќъµƒір∞Є°£
ЕҐњЉўYЅѕ£Ї
https://www.science.org/doi/10.1126/science.adz4433
https://www.harvardmagazine.com/ai/ai-outperforms-doctors-diagnosis-harvard-study
[ќпГrпwЭqµƒХrЇт я@Ш” °еXўПќпЇ№Ћђ]
яАЫ]»Ћ’f‘Т∞°£ђќ“ѕлБн’fО„Њд
‘ЏЉ±‘\ “µƒ’жМНЈ÷‘\ИцЊ∞÷–£ђOpenAIµƒo1Ќ∆јнƒ£–Ќ‘\Фа„Љі_¬ я_µљ67%£ђґшГ…ќїљЫтЮЎSЄїµƒГ»њ∆÷ч÷ќбt…ъ£ђ“ЉВА55%£ђ“ЉВА50%°£
AIЏAЅЋ°£
≤ї «‘Џ„цо}£ђ≤ї «‘ЏњЉ‘З£ђґш «‘Џ’浴’жШМµƒЉ±‘\ “—e°£
Єь‘ъ–ƒµƒФµУюяА‘Џбб√ж°™°™‘Џ÷∆ґ®÷ќѓЯє№јнЈљ∞ЄµƒЬy‘З÷–£ђo1ƒ√ЅЋ89%£ђґш»ЋоРбt…ъ є”√ВчљyўY‘іЁo÷ъбб£ђ÷–ќїФµ÷ї”–34%°£
≤оЊа≤ї «“Љ–«∞льc£ђ «Г…±ґґа°£
я@≤ї «“ЉВАAIєЂЋЊµƒ„‘ўu„‘’F£ђя@ «єюЈрбtМW‘Ї†њо^°ҐнФЉЙМW–g∆Џњѓ±≥Хш°Ґлp√§‘uМПі_’JµƒљYєы°£
—–Њњ’УќƒµƒЌ®”Н„ч’я°ҐєюЈрбtМW‘ЇAIМНтЮ “ЎУЎЯ»ЋArjun Manrai’fЅЋ“ЉЊд“вќґ…ойLµƒ‘Т£Ї°Єќ“ВГ”√О„ЇхЋщ”–їщ„ЉЬy‘ЗЅЋя@ВАAIƒ£–Ќ£ђЋь≥ђ‘љЅЋіЋ«∞Ћщ”–ƒ£–ЌЇЌбt…ъїщЊА°£°є
“ЉВАХrіъµƒЅ—њp£ђЊЌя@ьN±їЋЇй_ЅЋ°£
76ВА’жМНїЉ’я£ђЅгоAћОјн£ђлp√§М¶ЫQ
я@нЧ—–Њњ„о”≤ЇЋµƒµЎЈљ‘Џмґ£ЇЋь≤ї «ƒ√ЊЂ–ƒ’ыјнµƒљћњ∆Хш≤°јэ»•њЉAI£ђґш «÷±љ”∞—Љ±‘\ “—e„о‘≠ Љ°Ґ„оїмБyµƒлК„”≤°Ъv»”љoЅЋЩC∆ч°£
—–ЊњИFк†ПƒЎРЋє“‘…ЂЅ–Љ±‘\њ∆лSЩCяx»°ЅЋ76√ы’жМНїЉ’я£ђ‘Џ»юВАкPжI‘\ФаєЭьcяM––М¶±»°™°™Љ±‘\Ј÷‘\£®їЉ’яДВяMйT£©°ҐЉ±‘\бt…ъ „іќљ”‘\°Ґ“‘Љ∞ ’÷ќ»л‘ЇїтяMICU°£
√њВАєЭьc£ђГ…ќїГ»њ∆÷ч÷ќбt…ъЇЌOpenAIµƒo1°Ґ4oƒ£–ЌЌђХrљo≥циbДe‘\Фа£ђ√њЈљ„оґаЅ–5ВАњ…ƒ№‘\Фа°£
кPжIЉЪєЭ «£Ї—–Њњ»ЋЖTМ¶ФµУюЅгоAћОјн°£
’Уќƒ√чі_МСµј£ђAIƒ£–Ќљ” ’µљµƒ–≈ѕҐЇЌбt…ъњіµљµƒлК„”≤°ЪvЌк»Ђ“Љ÷¬°™°™ƒ«–©ЅиБyµƒ°Ґ»± Іµƒ°Ґ≥дЭM‘л¬Хµƒ’жМН≈Rі≤ФµУю°£
»їбб£ђ”…ЅнЌвГ…√ы÷ч÷ќбt…ъяM––°Є√§‘u°є°™°™ЋыВГ≤ї÷™µјƒƒВА‘\ФаБн„‘»ЋоР°ҐƒƒВАБн„‘AI°£
√§‘uљYєып@ Њ£ђ‘uМПбt…ъО„ЇхЌк»ЂЯoЈ®Ј÷±ж‘\ФаБн‘і£Ї“Љќїбt…ъ≤¬М¶AI/»ЋоРµƒ„Љі_¬ ГH15.2%£®83.6%µƒХrЇтяxЅЋ°ЄЈ÷≤ї«е°є£©£ђЅн“ЉќїЄь’FПИ£ђ÷ї”–3.1%£®94.4%°ЄЈ÷≤ї«е°є£©°£
УQЊд‘Т’f£ђAIМСµƒ‘\Фа£ђяBўY…обt…ъґЉњі≤ї≥ц «ЩC∆ч…ъ≥…µƒ°£
‘Џя@Ш”µƒЗјњЅЧlЉюѕ¬£ђo1ƒ£–Ќ‘ЏЉ±‘\Ј÷‘\лAґќ°™°™–≈ѕҐ„о…ў°ҐХrйg„оЊo°ҐЫQ≤я„окPжIµƒ≠hєЭ°™°™љo≥цЅЋ67.1%µƒ„Љі_¬ £®∞ьЇђЊЂі_‘\ФаїтЈ«≥£љ”љьµƒ‘\Фа£©°£
Г…ќї»ЋоРбt…ъЈ÷Дe «55.3%ЇЌ50.0%°£
лS÷ш–≈ѕҐ÷рЭu‘цґа£ђЋщ”–»Ћµƒ±нђFґЉ‘Џћб…э£Їµљ»л‘ЇлAґќ£ђo1„Љі_¬ …э÷Ѕ81.6%£ђбt…ъЈ÷ДeЮй78.9%ЇЌ69.7%°£
µЂ≤оЊа ЉљKіж‘Џ£ђґш«“‘Џ–≈ѕҐ„оЕTЈ¶µƒ≥х ЉлAґќ≤оЊа„оіу°£
я@«°«° «„оњ…≈¬µƒ∞lђF°™°™Љ±‘\„о“™√ьµƒЊЌ «°Є«∞О„Ј÷жR°є£ђїЉ’яДВ±їЌ∆яMБн£ђ–≈ѕҐЋй∆ђїѓ£ђ…ъЋјЎькP£ђбt…ъ–и“™‘ЏШOґ»≤їі_ґ®÷–„ц≥ц≈–Фа°£
ґш«°«°‘Џя@ВА≠hєЭ£ђAI±нђF„оЌї≥ц°£
Љ±‘\бt…ъ≤їО÷ЅЋ£Їƒ√Г»њ∆бt…ъЄъAI±»£ђƒ№’f√ч ≤ьN£њ
’Уќƒ∞l≤Љбб£ђ“Љќї√ыљ–Kristen PanthaganiµƒЉ±‘\њ∆бt…ъ‘Џ…зљї√љуw…ѕ÷±љ”й_Сї£Їя@ «“ЉВА°Є±їя^ґ»≥і„чµƒ”–»§—–Њњ°є°£
ЋэµƒЇЋ–ƒў|“… «£Ї—–Њњ÷–ЇЌAIМ¶±»µƒ «Г»њ∆÷ч÷ќбt…ъ£ђ≤ї «Љ±‘\њ∆бt…ъ°£
°Є»зєыќ“ВГ“™ƒ√AIЇЌбt…ъµƒ≈Rі≤ƒ№Ѕ¶„ц±»Ё^£ђ÷Ѕ…ўС™‘Уƒ√Ќђ“ЉВАМ£њ∆µƒбt…ъБн±»°£ќ“≤їХюу@”†мґ“ЉВАіу’Z—‘ƒ£–Ќƒ№‘Џ…сљЫЌвњ∆µƒМ£њ∆њЉ‘З÷–ітФ°∆§ƒwњ∆бt…ъ£ђµЂя@БK≤їƒ№’f√ч ≤ьN°£°є
ЋэяА÷Є≥цЅЋЉ±‘\бtМWµƒ±Њў|яЙЁЛ£Ї°Є„чЮй“Љ√ыµЏ“ЉіќњіµљїЉ’яµƒЉ±‘\бt…ъ£ђќ“µƒ „“™ƒњШЋ≤ї «≤¬≥ц„ољK‘\Фа°£ќ“µƒ „“™ƒњШЋ «≈–Фаƒг «Јс”–“ЉЈNњ…ƒ№ХюЪҐЋјƒгµƒЉ≤≤°°£°є
я@ВАЈісg”–Ѕ¶ЅњЖб£њ
”–°£µЂ“≤–и“™„Ґ“в£ђ—–Њњ’Уќƒ±Њ…н“—љЫ≥–’JЅЋя@“ЉЊ÷ѕё–‘£ђґш«“’УќƒµƒЇЋ–ƒ’УьcПƒБн≤ї «°ЄAIњ…“‘ћжіъЉ±‘\бt…ъ°є£ђґш «°ЄAI‘Џ”–ѕё–≈ѕҐѕ¬µƒЌ∆јнƒ№Ѕ¶“—љЫя_µљ÷µµ√≈Rі≤‘ЗтЮµƒЋЃ∆љ°є°£
Љ±‘\бt…ъ‘ЏђFИц„цµƒяh≤ї÷є°Є≤¬≤°√ы°є°™°™ЋыВГ“™њіїЉ’яµƒ√ж…Ђ°Ґ¬†Їфќьµƒ¬Х“ф°ҐЄ– №ћџЌіµƒ≥ћґ»°Ґ≈–Фа…ъ√ьуw’чµƒќҐ√о„Гїѓ°£
я@–©ЉЪќҐµƒЈ«’Z—‘–≈ћЦ£ђ”–ХrЇт±»»ќЇќЩzтЮ÷ЄШЋґЉ÷Ў“™°£
“ЉВАљЫтЮЎSЄїµƒЉ±‘\бt…ъ„яяM≤°Јњ£ђТя“Љ—џїЉ’я£ђњ…ƒ№ЊЌ“—љЫ„ц≥цЅЋ80%µƒ≈–Фа°™°™я@ЈNƒ№Ѕ¶љ–°Є≈Rі≤÷±”X°є£®clinical gestalt£©£ђЋьБн„‘Фµ“‘»f”Лµƒ’жМНљ”‘\љЫтЮ£ђƒњ«∞Ы]”–»ќЇќAIƒ№ЙтПЌ÷∆°£
Manrai„‘ЉЇ“≤≥–’J£ђИFк†’э‘Џ—–ЊњAIћОјн”∞ѕсЇЌ∆дЋыЈ«ќƒ±Њ–≈ћЦµƒƒ№Ѕ¶£ђ°ЄњіµљЅЋњмЋўяM≤љµƒљYєы°є£ђµЂЊалx≈Rі≤≤њ ряА”–Ї№йLµƒ¬Ј°£
–ЅоDµƒ°ЄоA—‘°єљћ”Ц£ЇЈ≈…дњ∆бt…ъЫ]ѕ¬НП£ђЈіґшЄь√¶ЅЋ
’fµљAI»°іъбt…ъя@ВА‘То}£ђ≤їµ√≤їћб“ЉВАљЫµдµƒ°ЄітƒШ°є∞Єјэ°£
2016ƒк£ђAIљћЄЄ°Ґ÷ZЎР†Ц™Дµ√÷чGeoffrey Hinton’fЅЋ“ЉЊд’рД”бtМWљзµƒ‘Т£Ї»ЋВГђF‘ЏЊЌС™‘УЌ£÷є≈а”ЦЈ≈…дњ∆бt…ъЅЋ°£…оґ»МWЅХ‘ЏќйƒкГ»ЊЌХю±»Ј≈…дњ∆бt…ъ„цµ√ЄьЇ√£ђя@Ќк»Ђ «п@ґш“„“Кµƒ°£
я@Њд‘ТЃФХrЗШЌЋЅЋ≤ї…ў„ЉВдяxУсЈ≈…дњ∆µƒбtМW…ъ°£’ыВА2010ƒкіъбб∆Џ£ђ√љуw…ѕдБћм…wµЎґЉ «°ЄЈ≈…дњ∆ЉіМҐѕыЌц°єµƒќƒ’¬°£
∞ƒкя^»•ЅЋ°£
√ЈКW‘\ЋщµƒЈ≈…дњ∆бt…ъИFк†Пƒ2016ƒк÷Ѕљс‘цйLЅЋ55%£ђя_µљ400»Ћ°£√јЗшЈ≈…дМWХюоAЬy£ђќіБн30ƒкЈ≈…дњ∆бt…ъє©љoяАМҐ‘цйL26%°£
»Ђ«т„оіуµƒЈ≈…дњ∆бt…ъґћ»±’э‘Џ∞l…ъ°™°™≤ї «“тЮйAIУМ„яЅЋє§„ч£ђґш «“тЮйAI„М”∞ѕсЩz≤й„Гµ√Єь±гљЁ£ђЈіґшія…ъЅЋЄьґа–и«у°£
Hinton±Њ»ЋббБн“≤≥–’J„‘ЉЇ°Є’fµ√ћЂМТЈЇЅЋ°є°£
Ћы–ё’эЅЋоAЬy£ЇќіБнµƒбtМW”∞ѕсљв„xМҐ”…°ЄAIЇЌЈ≈…дњ∆бt…ъµƒљMЇѕ°єБнЌк≥…£ђAIХю„МЈ≈…дњ∆бt…ъ°Є–І¬ іуіућбЄя£ђЌђХrћб…э„Љі_¬ °є°£
я@ВАє ¬—e”–“ЉВА…оњћµƒљЫЭъМW‘≠јн°™°™В№ќƒЋєг£’У£ЇЃФ“ЉнЧЉЉ–g„Мƒ≥ЈNўY‘іµƒ є”√ЄьЄя–ІХr£ђя@ЈNўY‘іµƒњВ–и«уЈіґшњ…ƒ№іуЈщ‘цЉ”°£
”∞ѕс‘\Фа„Г±г“Ћ°Ґ„ГњмЅЋ£ђмґ «бt…ъй_ЅЋЄьґаЩz≤й£ђЈ≈…дњ∆бt…ъЈіґшЄь√¶ЅЋ°£
єюЈря@нЧ–¬—–Њњµƒ„ч’яВГп@»їќь»°ЅЋ–ЅоDµƒљћ”Ц°£
’УќƒЌ®”Н„ч’яManrai‘Џ–¬¬Д∞l≤ЉХю…ѕ√чі_’f£Ї°Єќ“ВГµƒ∞lђFБK≤ї“вќґ÷шAI»°іъбt…ъ£ђ±Mє№”––©ўuAIбtѓЯЃa∆ЈµƒєЂЋЊњ…ƒ№Хюя@ьN’f°£°є
є≤ЌђЌ®”Н„ч’я°ҐЎРЋє“‘…ЂЅ–AIнЧƒњЎУЎЯ»ЋAdam RodmanДtЄь÷±∞„£Ї°Єƒњ«∞AI‘\ФаЫ]”–»ќЇќ’э љµƒЖЦЎЯњтЉ№°£їЉ’яѕл“™µƒ «»ЋБн“эМІЋыВГґ»я^…ъЋјЎькPµƒЫQ≤я£ђ“эМІЋыВГ√жМ¶∆Dлyµƒ÷ќѓЯяxУс°£°є
≤ї «°ЄAIЏAЅЋ°єґш «бtѓЯЫQ≤яЩа‘Џ÷ЎљM
Ую√јЗшбtМWХю£®AMA£©2026ƒк’{≤й£ђ≥ђя^80%µƒ√јЗшбt…ъ“—љЫ‘Џ¬ЪШI÷– є”√AI°™°™ «2023ƒкµƒГ…±ґ°£
17%µƒбt…ъ є”√AIяM––°ЄЁo÷ъ‘\Фа°є°£
2025ƒкµƒ“ЉнЧElsevier—–Њњ∞lђF£ђ20%µƒ≈Rі≤бt…ъ“—љЫ‘Џѕтіу’Z—‘ƒ£–ЌМ§«у°ЄµЏЈ°“в“К°є°£
єюЈря@нЧ—–Њњ„C√ч£ђAI‘Џ–≈ѕҐ„оЕTЈ¶°ҐЫQ≤я„оЊo∆»µƒЉ±‘\ИцЊ∞÷–£ђЌ∆јнƒ№Ѕ¶“—љЫ≥ђя^ЅЋ»ЋоРбt…ъ°£
»юВАФµУюѓBЉ”‘Џ“Љ∆р£ђ÷Єѕт“ЉВА«еќъµƒЏЕДЁ£ЇбtѓЯЫQ≤яµƒЩаЅ¶љYШЛ’э‘Џ∞l…ъЄщ±Њ–‘µƒ÷ЎљM°£
я^»•µƒЉ±‘\ “ƒ£ љ «£ЇїЉ’яяMБн°ъбt…ъ≈–Фа°ъ„ц≥цЫQ≤я°£
ќіБнµƒƒ£ љњ…ƒ№„Г≥…£ЇїЉ’яяMБн°ъAIњмЋўТя√илК„”≤°Ъvљo≥ц≥х≤љ≈–Фа°ъбt…ъљYЇѕ≈Rі≤”^≤мЇЌAIљ®„h„ц≥цЫQ≤я°ъїЉ’яЕҐ≈c”С’У÷ќѓЯЈљ∞Є°£
—–Њњ„ч’яRodmanоAЬy£ђќіБнХю≥цђF»юЈNЈ÷їѓ£Ї“Љ≤њЈ÷»ќД’»ЋоР≥÷јm„цµ√ЄьЇ√£ђ“Љ≤њЈ÷»ќД’AI≥÷јm„цµ√ЄьЇ√£ђяА”–“Љ≤њЈ÷»ќД’–и“™»ЋЩCЕf„ч‘цПК°£
я@ЊЌ «—–Њњ’яЋщ’fµƒ°Єбt…ъ-їЉ’я-AI°є»юЈљЕf„чƒ£ љ°£
¬†∆рБнЇ№ѕс„‘Д”с{сВ°£
L2ЉЙДe°™°™AIЁo÷ъ»ЋоРЫQ≤я£їL3ЉЙДe°™°™AI÷чМІ°Ґ»ЋоР±Oґљ£їL4ЉЙДe°™°™ћЎґ®ИцЊ∞»Ђ„‘Д”°£
ƒњ«∞AI‘ЏбtѓЯоI”тіуЄ≈ћО‘ЏL2µљL3÷ЃйgµƒлAґќ£ЇЋь“—љЫƒ№‘Џ°Єќƒ„÷ јљз°є—eљo≥ц≥ђ‘љ»ЋоРµƒ≈–Фа£ђµЂ‘Џ’жМНµƒ°Ґґаƒ£СBµƒ≈Rі≤ИцЊ∞÷–£ђЋьяА–и“™»ЋоРµƒ—џЊ¶°ҐґъґдЇЌ÷±”XБн—aќї°£
AI’`‘\ЅЋ£ђ’lЎУЎЯ£њ
‘ЏЋщ”–”С’У÷–£ђ”–“ЉВАЈњйg—eµƒіуѕуЯo»ЋЄ“’э√ж”|≈ц£ЇAI≥цеeЅЋ£ђ’lБн≥–УъЎЯ»ќ£њ
Rodman‘Џљ” №°ґ–lИу°Ј≤…‘LХrћє—‘£Їƒњ«∞AI‘\ФаЫ]”–»ќЇќ’э љµƒЖЦЎЯњтЉ№°£
»зєы“Љ√ыбt…ъ’`‘\ЅЋ£ђ”–≥… мµƒбtѓЯЉmЉКћОјнуwѕµ°™°™їЉ’яњ…“‘Ќґ‘V°Ґњ…“‘‘V‘A°Ґбt…ъ√ж≈RИћ’’пLлU°£
µЂ»зєыAIљo≥цЅЋеe’`љ®„h£ђбt…ъ≤…Љ{ЅЋ£ђїЉ’я №µљЅЋВыЇ¶°™°™ «Ћгбt…ъµƒЎЯ»ќ£њAIєЂЋЊµƒЎЯ»ќ£њбt‘ЇµƒЎЯ»ќ£њяА «»юЈљє≤Уъ£њ
ЄьПЌлsµƒИцЊ∞ «£Ї»зєыAIљo≥цЅЋ’эі_љ®„h£ђµЂбt…ъЈсЫQЅЋAIµƒ≈–Фа°ҐИ‘≥÷„‘ЉЇµƒеe’`‘\Фа£ђМІ÷¬їЉ’я—”’`÷ќѓЯ°™°™іЋХrбt…ъ“™≤ї“™Юй°ЄЇц“ХAљ®„h°є≥–Уъо~ЌвЎЯ»ќ£њ
яА”–“ЉВАЄьл[±ќµƒпLлU£Їя^ґ»“јўЗ°£
ЃФбt…ъЅХСTЅЋAIљo≥цµƒЄя„Љі_¬ ≈–Фа£ђЋыВГµƒ™ЪЅҐЋЉњЉƒ№Ѕ¶Хю≤їХюЌЋїѓ£њЊЌѕсGPS„МЇ№ґа»ЋЖ ІЅЋ„‘÷чМІЇљƒ№Ѕ¶“ЉШ”£ђAIЁo÷ъ‘\Фа «ЈсХю„Мбt…ъµƒ≈Rі≤Ќ∆јн°ЄЉ°»в°є÷рЭuќЃњs£њ
я@–©ЖЦо}£ђƒњ«∞Ы]”–»ќЇќЗшЉ“”–«еќъµƒір∞Є°£
ЕҐњЉўYЅѕ£Ї
https://www.science.org/doi/10.1126/science.adz4433
https://www.harvardmagazine.com/ai/ai-outperforms-doctors-diagnosis-harvard-study
[ќпГrпwЭqµƒХrЇт я@Ш” °еXўПќпЇ№Ћђ]
| Ј÷ѕн: |
| „Ґ£Ї |
| —”…мйЖ„x | Єьґа... |
Ќ∆Ћ]: