




ЪЕВтGPT5.5:зюЧПФЃаЭВЛЪЧзьХк,ЫќецФмИЩЛюЖљ
GPT-5.5ЃЌжегкЗЂВМЁЃ
зїЮЊOpenAIЕБЯТзюЧПЕФФЃаЭЃЌетДЮИќаТЕФССЕуЪЧЁАЮЊецЪЕЙЄзїЖјЩшМЦЁБЁЃ
КЭЙ§ШЅЕФФЃаЭЯрБШЃЌGPT-5.5ФмИќПьРэНтЪЙгУепеце§ЯызіЕФЪТЧщЃЌвВФмздМКГаЕЃИќЖржДааЙ§ГЬЃЌПЩвддкЯпМьЫїаХЯЂЁЂЗжЮіЪ§ОнЁЂЩњГЩЮФЕЕКЭБэИёЁЂВйзїШэМўЃЌВЂдкВЛЭЌЙЄОпжЎМфРДЛиЧаЛЛЃЌжБЕНАбШЮЮёЭъГЩЁЃ
гУЛЇВЛдйашвЊОЋЯИЕиВ№НтУПвЛВНЃЌПЩвджБНгИјЫќвЛИіЛьТвЁЂЖрВНжшЕФЮЪЬтЃЌШУЫќздМКЙцЛЎТЗОЖЁЂЕїгУЙЄОпЁЂМьВщНсЙћЃЌдкВЛШЗЖЈжаМЬајЭЦНјЁЃ
гаЭјгбжБНгЦРМлЃЌетЪЧФПЧАЮЊжЙзюНгНќAGIЕФФЃаЭЁЃ
ФПЧАЃЌGPT-5.5вбОдкChatGPTКЭCodexжаЯђPlusЁЂProЁЂЭХЖгАцКЭЦѓвЕАцгУЛЇж№ВНПЊЗХЃЌGPT-5.5 ProдђУцЯђProМАвдЩЯгУЛЇЁЃAPIАцБОЩаЮДЩЯЯпЁЃ
ФЃаЭадФм
ЯШРДПДПДФЃаЭдкЛљзМВтЪджаЕФЕУЗжЧщПіЁЃ
ЦфжазюжЕЕУЙизЂЕФжИБъЪЧGDPvalЃЌетИіВтЪдВЛЪЧДЋЭГбЁдёЬтЃЌЖјЪЧгУ44жжецЪЕжАвЕШЮЮёРДЦРЙРФЃаЭЃЌБШШчЗжЮіЪ§ОнЁЂаДБЈИцЁЂзіХаЖЯЁЃ
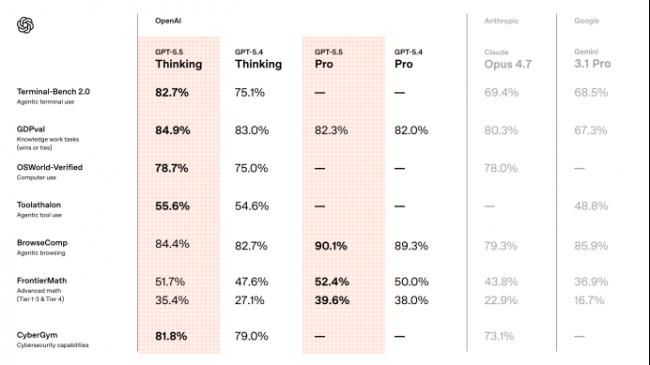
GPT-5.5ЕФГЩМЈЪЧ84.9%ЃЌЯрБШGPT-5.4ЕФ83.0%ЃЌгавЛЖЈЕФЬсЩ§ЃЌвВИпгкClaude Opus 4.7 ЕФ80.3%КЭGemini 3.1 ProЕФ67.3%ЁЃ
ЕкЖўИіЙиМќВтЪдЪЧOSWorldЃЌгУРДКтСПФЃаЭдкецЪЕЕчФдЛЗОГжаЕФВйзїФмСІЁЃGPT-5.5 ДяЕН78.7%ЃЌИпгкGPT-5.4ЕФ75.0%ЃЌЬсЩ§ЗљЖШВЛЫуПфеХЃЌЕЋвтвхКмДѓЁЃ
етЯюФмСІПМбщСЫвЛИіИќЯжЪЕЕФЮЪЬтЃКФЃаЭВЛНіФмИцЫпФудѕУДзіЃЌЛЙФмВЛФмжБНгЬцФуШЅзіЃЌАќРЈЕуЛїНчУцЁЂЧаЛЛЙЄОпЁЂжДааЖрВНжшВйзїЁЃ
ЛЙгаTau2 TelecomЃЌетЪЧвЛИіЕчаХПЭЗўСїГЬВтЪдЃЌGPT-5.5 дкЮоашЖюЭтЕїгХЕФЧщПіЯТДяЕН98.0%ЁЃетРрШЮЮёИќНгНќЦѓвЕРяЕФецЪЕЙЄзїЃЌашвЊдкИДдгЁЂЖрВНжшЁЂгаЩЯЯТЮФвРРЕЕФСїГЬжаЭъГЩЁЃ
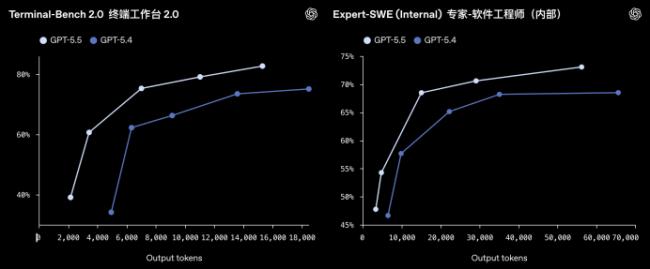
дкИќЯИЗжЕФФмСІЩЯЃЌGPT-5.5ЕФБрГЬФмСІМЬајЬсЩ§ЃЌдкTerminal-Bench 2.0ЩЯДяЕНСЫ82.7%ЃЌдкSWE-Bench ProЩЯДяЕНСЫ58.6%ЁЃ
дкЦфЫћжЊЪЖЙЄзїЛљзМВтЪджаЃЌGPT-5.5ЕФБэЯжвВКмГіЩЋЃКFinanceAgentЕУЗж60.0%ЃЌФкВПЭЖзЪвјааНЈФЃШЮЮёЕУЗж88.5%ЃЌOfficeQA ProЕУЗж54.1%ЁЃЫЕУїЫќдкНсЙЙЛЏЗжЮіКЭЪ§ОнДІРэЩЯвбОЯрЕБГЩЪьЁЃ
ПЦбаЗНУцЫфШЛЗжЪ§ЬсЩ§ЯрЖдЮТКЭЃЌЕЋвбОГіЯжФмЙЛВЮгыЭЦРэЁЂбщжЄЩѕжСИЈжњЗЂЯжаТНсЙћЕФАИР§ЃЌетвЛЕуИќЯёФмСІБпНчЕФБфЛЏЃЌЖјВЛЪЧМђЕЅЕФадФмдіГЄЁЃ
АбетаЉХмЗжЗХдквЛЦ№ПДЃЌЛсЗЂЯжетДЮФЃаЭЕФЦРМлБъзМе§дкЗЂЩњБфЛЏЃКЙ§ШЅЮвУЧГЃгУMMLUЁЂGPQAетбљЕФжИБъПДФЃаЭЕФжЊЪЖКЭЭЦРэФмСІЃЌЕЋЯждкИќВржигкGDPvalЁЂOSWorldетРрЁАШЮЮёМЖЦРЙРЁБЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
КУаТЮХУЛШЫЦРТлдѕУДааЃЌЮвРДЫЕМИОф
зїЮЊOpenAIЕБЯТзюЧПЕФФЃаЭЃЌетДЮИќаТЕФССЕуЪЧЁАЮЊецЪЕЙЄзїЖјЩшМЦЁБЁЃ
КЭЙ§ШЅЕФФЃаЭЯрБШЃЌGPT-5.5ФмИќПьРэНтЪЙгУепеце§ЯызіЕФЪТЧщЃЌвВФмздМКГаЕЃИќЖржДааЙ§ГЬЃЌПЩвддкЯпМьЫїаХЯЂЁЂЗжЮіЪ§ОнЁЂЩњГЩЮФЕЕКЭБэИёЁЂВйзїШэМўЃЌВЂдкВЛЭЌЙЄОпжЎМфРДЛиЧаЛЛЃЌжБЕНАбШЮЮёЭъГЩЁЃ
гУЛЇВЛдйашвЊОЋЯИЕиВ№НтУПвЛВНЃЌПЩвджБНгИјЫќвЛИіЛьТвЁЂЖрВНжшЕФЮЪЬтЃЌШУЫќздМКЙцЛЎТЗОЖЁЂЕїгУЙЄОпЁЂМьВщНсЙћЃЌдкВЛШЗЖЈжаМЬајЭЦНјЁЃ
гаЭјгбжБНгЦРМлЃЌетЪЧФПЧАЮЊжЙзюНгНќAGIЕФФЃаЭЁЃ
ФПЧАЃЌGPT-5.5вбОдкChatGPTКЭCodexжаЯђPlusЁЂProЁЂЭХЖгАцКЭЦѓвЕАцгУЛЇж№ВНПЊЗХЃЌGPT-5.5 ProдђУцЯђProМАвдЩЯгУЛЇЁЃAPIАцБОЩаЮДЩЯЯпЁЃ
ФЃаЭадФм
ЯШРДПДПДФЃаЭдкЛљзМВтЪджаЕФЕУЗжЧщПіЁЃ
ЦфжазюжЕЕУЙизЂЕФжИБъЪЧGDPvalЃЌетИіВтЪдВЛЪЧДЋЭГбЁдёЬтЃЌЖјЪЧгУ44жжецЪЕжАвЕШЮЮёРДЦРЙРФЃаЭЃЌБШШчЗжЮіЪ§ОнЁЂаДБЈИцЁЂзіХаЖЯЁЃ
GPT-5.5ЕФГЩМЈЪЧ84.9%ЃЌЯрБШGPT-5.4ЕФ83.0%ЃЌгавЛЖЈЕФЬсЩ§ЃЌвВИпгкClaude Opus 4.7 ЕФ80.3%КЭGemini 3.1 ProЕФ67.3%ЁЃ
ЕкЖўИіЙиМќВтЪдЪЧOSWorldЃЌгУРДКтСПФЃаЭдкецЪЕЕчФдЛЗОГжаЕФВйзїФмСІЁЃGPT-5.5 ДяЕН78.7%ЃЌИпгкGPT-5.4ЕФ75.0%ЃЌЬсЩ§ЗљЖШВЛЫуПфеХЃЌЕЋвтвхКмДѓЁЃ
етЯюФмСІПМбщСЫвЛИіИќЯжЪЕЕФЮЪЬтЃКФЃаЭВЛНіФмИцЫпФудѕУДзіЃЌЛЙФмВЛФмжБНгЬцФуШЅзіЃЌАќРЈЕуЛїНчУцЁЂЧаЛЛЙЄОпЁЂжДааЖрВНжшВйзїЁЃ
ЛЙгаTau2 TelecomЃЌетЪЧвЛИіЕчаХПЭЗўСїГЬВтЪдЃЌGPT-5.5 дкЮоашЖюЭтЕїгХЕФЧщПіЯТДяЕН98.0%ЁЃетРрШЮЮёИќНгНќЦѓвЕРяЕФецЪЕЙЄзїЃЌашвЊдкИДдгЁЂЖрВНжшЁЂгаЩЯЯТЮФвРРЕЕФСїГЬжаЭъГЩЁЃ
дкИќЯИЗжЕФФмСІЩЯЃЌGPT-5.5ЕФБрГЬФмСІМЬајЬсЩ§ЃЌдкTerminal-Bench 2.0ЩЯДяЕНСЫ82.7%ЃЌдкSWE-Bench ProЩЯДяЕНСЫ58.6%ЁЃ
дкЦфЫћжЊЪЖЙЄзїЛљзМВтЪджаЃЌGPT-5.5ЕФБэЯжвВКмГіЩЋЃКFinanceAgentЕУЗж60.0%ЃЌФкВПЭЖзЪвјааНЈФЃШЮЮёЕУЗж88.5%ЃЌOfficeQA ProЕУЗж54.1%ЁЃЫЕУїЫќдкНсЙЙЛЏЗжЮіКЭЪ§ОнДІРэЩЯвбОЯрЕБГЩЪьЁЃ
ПЦбаЗНУцЫфШЛЗжЪ§ЬсЩ§ЯрЖдЮТКЭЃЌЕЋвбОГіЯжФмЙЛВЮгыЭЦРэЁЂбщжЄЩѕжСИЈжњЗЂЯжаТНсЙћЕФАИР§ЃЌетвЛЕуИќЯёФмСІБпНчЕФБфЛЏЃЌЖјВЛЪЧМђЕЅЕФадФмдіГЄЁЃ
АбетаЉХмЗжЗХдквЛЦ№ПДЃЌЛсЗЂЯжетДЮФЃаЭЕФЦРМлБъзМе§дкЗЂЩњБфЛЏЃКЙ§ШЅЮвУЧГЃгУMMLUЁЂGPQAетбљЕФжИБъПДФЃаЭЕФжЊЪЖКЭЭЦРэФмСІЃЌЕЋЯждкИќВржигкGDPvalЁЂOSWorldетРрЁАШЮЮёМЖЦРЙРЁБЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
| бгЩьдФЖС |
ЭЦМі: