




YCеЦУХШЫПЊдДСЫЫћЕФ"ЕкЖўДѓФд"(ЭМ
ШчЙћФуНёЬьЮЪШЮКЮвЛИі AI AgentЃКЁАзђЬьФуАяЮвзіСЫЪВУДЃПЁБВЛгУЫЕЃЌЫќДѓИХТЪЛсЁАвЛСГУЃШЛЁБЃЌШЛКѓПЊЪМКњбдТвгяЁЃ
етЪЧвђЮЊОјДѓЖрЪ§Лљгк LLM ЕФжЧФмЬхЖМЪмРЇгкЁАЮозДЬЌРЇОГЁБЃЈStateless DilemmaЃЉЃКЛсЛАвЛЕЉНсЪјЃЌМЧвфМДПЬЧхСуЁЃЯТвЛДЮЖдЛАЃЌгРдЖЪЧДгСуПЊЪМЕФРфЦєЖЏЁЃФуЗДИДНтЪЭЙ§ЕФЯюФПБГОАЁЂКЯзїЛяАщЕФадИёЦЋКУЁЂФудјОБэДяЙ§ЕФЙлЕуЃЌЖд Agent ЖјбдЖМЪЧвЛЦЌащЮоЁЃетвВЪЧзшЕВ Agent ДгЁАКУгУЕФЙЄОпЁБНјЛЏЮЊЁАеце§ЕФжњЪжЁБЕФеЯАжЎвЛЁЃ
НќШеЃЌY CombinatorЃЈвдЯТМђГЦ YCЃЉзмВУМц CEO Garry Tan аћВМНЋздМКШеГЃЪЙгУЕФИіШЫжЊЪЖЯЕЭГ ЁАGBrainЁБ ПЊдДЁЃЫћдк X ЩЯаДЕРЃКЁАЮвЯЃЭћЫљгаШЫЖМФмгЕгаздМКЕФЁЎИіШЫУдФуAGIЁЏЁЃЁБНижСФПЧАЃЌИУЯюФПдк GitHub ЩЯвбЛёЕУГЌЙ§ 5,000 ПХаЧЁЃ
етВЂЗЧ Garry Tan НќЦкЕФЮЈвЛЖЏзїЁЃвЛИідТЧАЃЌЫћЗЂВМЕФЛљгк Claude Code ЕФНсЙЙЛЏЬсЪОДЪЙЄзїСї gstack дјдквЛжмФкеЖЛёГЌ 69,000 ПХ StarЁЃОЁЙмгаШЫХњЦРФЧЁАБОжЪЩЯжЛЪЧЮФМўМаРяЕФвЛЖбЬсЪОДЪЁБЃЌЕЋДЫДЮЭЦГіЕФ GBrain УщзМЕФЪЧвЛИіИќЕзВуЁЂИќКЫаФЕФЮЪЬтЃКВЛНівЊШУ Agent ИќКУЕижДааЕЅДЮШЮЮёЃЌИќвЊИГгшЦфГжајЛ§РлЁЂВЛЖЯНјЛЏЕФГЄаЇМЧвфЁЃ
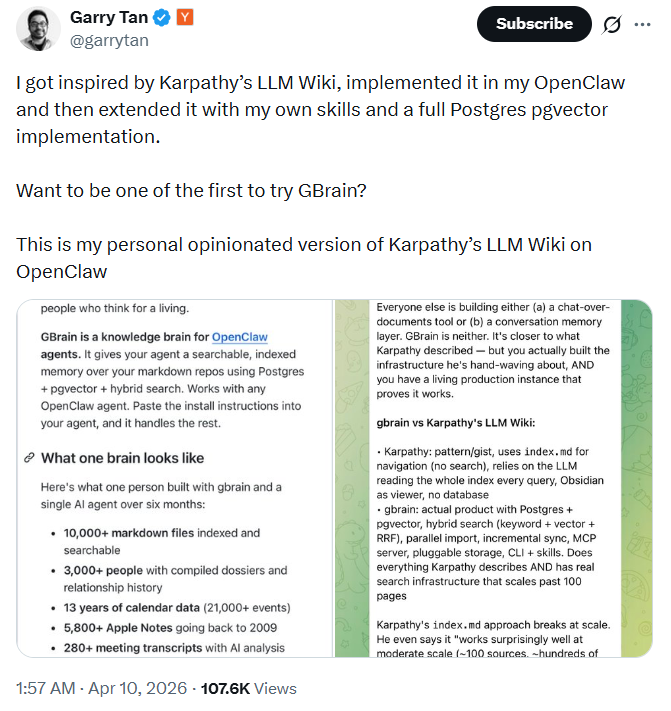
АДее GBrain ЕФ README ЮФЕЕУшЪіЃЌећИіЯЕЭГЕФКЫаФЫМТЗПЩвдгУвЛОфЛАИХРЈЃКШУ Agent ОРњЖСШЁЁЊЖдЛАЁЊаДШыЕФБеЛЗЁЃ
УПЕБгааТаХКХНјШыЯЕЭГЃКПЩФмЪЧвЛЗтгЪМўЁЂвЛЖЮЛсвщТМвєЁЂвЛЬѕЭЦЮФЃЌЩѕжСЪЧШеРњЩЯЕФФГИіааГЬБфЖЏЁЁAgent ЛсЯШВщбЏвбгажЊЪЖПтЃЈЖСШЁЃЉЃЌдкГфЗжРэНтЩЯЯТЮФжЎКѓзїГіЛигІЃЈЖдЛАЃЉЃЌШЛКѓНЋетДЮНЛЛЅВњЩњЕФаТжЊЪЖаДЛижЊЪЖПтЃЈаДШыЃЉЃЌЙЉЯТвЛДЮВщбЏЪЙгУЁЃ
Tan дкЮФЕЕжаАбетГЦзїЁАДѓФд-Agent бЛЗЁБЃЌЫћШЯЮЊетИібЛЗЕФвтвхдкгкЃКУПзпвЛШІЃЌAgent ОЭБШЩЯвЛШІИќЖЎФуЁЃ
етЬзбЛЗЕНЕзНтОіЪВУДЮЪЬтЃППЩвдЩшЯывЛИіОпЬхГЁОАЁЃзїЮЊ YC ЕФ CEOЃЌTan УПжмПЩФмвЊгыЪ§ЪЎЮЛДДЪМШЫЁЂЭЖзЪШЫКЭКЯзїЛяАщДђНЛЕРЁЃМйЩшЫћжмЖўЯТЮчКЭФГЮЛДДЪМШЫПЊСЫвЛГЁВњЦЗЦРЩѓЛсЃЌЛсвщТМвєБЛздЖЏзЊТМКѓСїШы GBrainЃЌAgent ЛсзіМИМўЪТЃКЪзЯШЪЖБ№ГіЛсвщжаЬсЕНЕФЫљгаШЫУћКЭЙЋЫОУћЃЈЪЕЬхМьВтЃЉЃЌШЛКѓШЅжЊЪЖПтВщеветаЉШЫКЭЙЋЫОЪЧЗёвбгаЖдгІвГУцЁЃ
ШчЙћвбгаЃЌБШШчетЮЛДДЪМШЫШ§ИідТЧАдкСэвЛГЁЛсвщЩЯвбОМћЙ§ЁЃAgent ОЭАбаТЕФЛсвщвЊЕузЗМгЕНФЧИіШЫЕФЪБМфЯпРяЃЌЭЌЪБИќаТвГУцЖЅВПЕФзлКЯХаЖЯЃКетИіШЫФПЧАдкзіЪВУДЁЂЙиаФЪВУДЁЂЩЯДЮКЭФуЬжТлЙ§ЪВУДЁЃШчЙћЪЧЕквЛДЮГіЯжЕФФАЩњУцПзЃЌAgent дђЛсДДНЈаТвГУцЃЌВЂЭЈЙ§ Web ЫбЫїЁЂLinkedIn Ъ§ОнЁЂЩѕжС X ЩЯЕФЙЋПЊЗЂбдРДЬюГфБГОАзЪСЯЁЃ
етбљвЛРДЃЌСНжмКѓЕБ Tan дйДЮМћЕНетЮЛДДЪМШЫЪБЃЌЫћВЛашвЊЗгЪМўЁЂВщШеРњЁЂЛивфЩЯДЮСФСЫЪВУДЁЃAgent вбОАбЫљгаЩЯЯТЮФДђАќКУСЫЁЃ
етжжФмСІдкДІРэИДдгМьЫїЪБгШЮЊЯджјЁЃР§ШчЃЌЕБФубЏЮЪЁАШЅФъ 3 дТФЧДЮЭэбчЖМгаЫВЮМгЁБЪБЃЌДЋЭГЗНЪНашвЊЪжЖЏЦДДеШеРњЁЂгЪМўКЭСФЬьМЧТМЃЛЖјдк GBrain ЬхЯЕЯТЃЌгЩгкУПДЮНЛЛЅЖМвбБЛНсЙЙЛЏВЂЙиСЊжСЖдгІШЫЮявГУцЃЌВщбЏПЩПьЫйЗЕЛиЭъећУћЕЅЁЃ
МђбджЎЃЌGBrain НтОіЕФКЫаФЭДЕуЪЧЃКШУУПвЛДЮЖдЛАЖМНЈСЂдкЙ§ЭљЫљгаЛ§РлЕФЛљЪЏжЎЩЯЃЌЖјЗЧУПДЮЖМДгСуПЊЪМЁЃ

[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
ЮоЦРТлВЛаТЮХЃЌЗЂБэвЛЯТФњЕФвтМћАЩ
етЪЧвђЮЊОјДѓЖрЪ§Лљгк LLM ЕФжЧФмЬхЖМЪмРЇгкЁАЮозДЬЌРЇОГЁБЃЈStateless DilemmaЃЉЃКЛсЛАвЛЕЉНсЪјЃЌМЧвфМДПЬЧхСуЁЃЯТвЛДЮЖдЛАЃЌгРдЖЪЧДгСуПЊЪМЕФРфЦєЖЏЁЃФуЗДИДНтЪЭЙ§ЕФЯюФПБГОАЁЂКЯзїЛяАщЕФадИёЦЋКУЁЂФудјОБэДяЙ§ЕФЙлЕуЃЌЖд Agent ЖјбдЖМЪЧвЛЦЌащЮоЁЃетвВЪЧзшЕВ Agent ДгЁАКУгУЕФЙЄОпЁБНјЛЏЮЊЁАеце§ЕФжњЪжЁБЕФеЯАжЎвЛЁЃ
НќШеЃЌY CombinatorЃЈвдЯТМђГЦ YCЃЉзмВУМц CEO Garry Tan аћВМНЋздМКШеГЃЪЙгУЕФИіШЫжЊЪЖЯЕЭГ ЁАGBrainЁБ ПЊдДЁЃЫћдк X ЩЯаДЕРЃКЁАЮвЯЃЭћЫљгаШЫЖМФмгЕгаздМКЕФЁЎИіШЫУдФуAGIЁЏЁЃЁБНижСФПЧАЃЌИУЯюФПдк GitHub ЩЯвбЛёЕУГЌЙ§ 5,000 ПХаЧЁЃ
етВЂЗЧ Garry Tan НќЦкЕФЮЈвЛЖЏзїЁЃвЛИідТЧАЃЌЫћЗЂВМЕФЛљгк Claude Code ЕФНсЙЙЛЏЬсЪОДЪЙЄзїСї gstack дјдквЛжмФкеЖЛёГЌ 69,000 ПХ StarЁЃОЁЙмгаШЫХњЦРФЧЁАБОжЪЩЯжЛЪЧЮФМўМаРяЕФвЛЖбЬсЪОДЪЁБЃЌЕЋДЫДЮЭЦГіЕФ GBrain УщзМЕФЪЧвЛИіИќЕзВуЁЂИќКЫаФЕФЮЪЬтЃКВЛНівЊШУ Agent ИќКУЕижДааЕЅДЮШЮЮёЃЌИќвЊИГгшЦфГжајЛ§РлЁЂВЛЖЯНјЛЏЕФГЄаЇМЧвфЁЃ
АДее GBrain ЕФ README ЮФЕЕУшЪіЃЌећИіЯЕЭГЕФКЫаФЫМТЗПЩвдгУвЛОфЛАИХРЈЃКШУ Agent ОРњЖСШЁЁЊЖдЛАЁЊаДШыЕФБеЛЗЁЃ
УПЕБгааТаХКХНјШыЯЕЭГЃКПЩФмЪЧвЛЗтгЪМўЁЂвЛЖЮЛсвщТМвєЁЂвЛЬѕЭЦЮФЃЌЩѕжСЪЧШеРњЩЯЕФФГИіааГЬБфЖЏЁЁAgent ЛсЯШВщбЏвбгажЊЪЖПтЃЈЖСШЁЃЉЃЌдкГфЗжРэНтЩЯЯТЮФжЎКѓзїГіЛигІЃЈЖдЛАЃЉЃЌШЛКѓНЋетДЮНЛЛЅВњЩњЕФаТжЊЪЖаДЛижЊЪЖПтЃЈаДШыЃЉЃЌЙЉЯТвЛДЮВщбЏЪЙгУЁЃ
Tan дкЮФЕЕжаАбетГЦзїЁАДѓФд-Agent бЛЗЁБЃЌЫћШЯЮЊетИібЛЗЕФвтвхдкгкЃКУПзпвЛШІЃЌAgent ОЭБШЩЯвЛШІИќЖЎФуЁЃ
етЬзбЛЗЕНЕзНтОіЪВУДЮЪЬтЃППЩвдЩшЯывЛИіОпЬхГЁОАЁЃзїЮЊ YC ЕФ CEOЃЌTan УПжмПЩФмвЊгыЪ§ЪЎЮЛДДЪМШЫЁЂЭЖзЪШЫКЭКЯзїЛяАщДђНЛЕРЁЃМйЩшЫћжмЖўЯТЮчКЭФГЮЛДДЪМШЫПЊСЫвЛГЁВњЦЗЦРЩѓЛсЃЌЛсвщТМвєБЛздЖЏзЊТМКѓСїШы GBrainЃЌAgent ЛсзіМИМўЪТЃКЪзЯШЪЖБ№ГіЛсвщжаЬсЕНЕФЫљгаШЫУћКЭЙЋЫОУћЃЈЪЕЬхМьВтЃЉЃЌШЛКѓШЅжЊЪЖПтВщеветаЉШЫКЭЙЋЫОЪЧЗёвбгаЖдгІвГУцЁЃ
ШчЙћвбгаЃЌБШШчетЮЛДДЪМШЫШ§ИідТЧАдкСэвЛГЁЛсвщЩЯвбОМћЙ§ЁЃAgent ОЭАбаТЕФЛсвщвЊЕузЗМгЕНФЧИіШЫЕФЪБМфЯпРяЃЌЭЌЪБИќаТвГУцЖЅВПЕФзлКЯХаЖЯЃКетИіШЫФПЧАдкзіЪВУДЁЂЙиаФЪВУДЁЂЩЯДЮКЭФуЬжТлЙ§ЪВУДЁЃШчЙћЪЧЕквЛДЮГіЯжЕФФАЩњУцПзЃЌAgent дђЛсДДНЈаТвГУцЃЌВЂЭЈЙ§ Web ЫбЫїЁЂLinkedIn Ъ§ОнЁЂЩѕжС X ЩЯЕФЙЋПЊЗЂбдРДЬюГфБГОАзЪСЯЁЃ
етбљвЛРДЃЌСНжмКѓЕБ Tan дйДЮМћЕНетЮЛДДЪМШЫЪБЃЌЫћВЛашвЊЗгЪМўЁЂВщШеРњЁЂЛивфЩЯДЮСФСЫЪВУДЁЃAgent вбОАбЫљгаЩЯЯТЮФДђАќКУСЫЁЃ
етжжФмСІдкДІРэИДдгМьЫїЪБгШЮЊЯджјЁЃР§ШчЃЌЕБФубЏЮЪЁАШЅФъ 3 дТФЧДЮЭэбчЖМгаЫВЮМгЁБЪБЃЌДЋЭГЗНЪНашвЊЪжЖЏЦДДеШеРњЁЂгЪМўКЭСФЬьМЧТМЃЛЖјдк GBrain ЬхЯЕЯТЃЌгЩгкУПДЮНЛЛЅЖМвбБЛНсЙЙЛЏВЂЙиСЊжСЖдгІШЫЮявГУцЃЌВщбЏПЩПьЫйЗЕЛиЭъећУћЕЅЁЃ
МђбджЎЃЌGBrain НтОіЕФКЫаФЭДЕуЪЧЃКШУУПвЛДЮЖдЛАЖМНЈСЂдкЙ§ЭљЫљгаЛ§РлЕФЛљЪЏжЎЩЯЃЌЖјЗЧУПДЮЖМДгСуПЊЪМЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
| бгЩьдФЖС |
ЭЦМі: