




OpenAIвВПЊЪМПжОхздМКбЕСЗГіЕФаТФЃаЭСЫ

ПДЕН Anthropic ФкВтжаЕФЯТвЛДњЦьНЂФЃаЭ Mythos ЧПДѓЕФЭјТчЙЅЗРФмСІДјРДЕФОоДѓгАЯьКЭЬжТлЖШЃЌАТЬиТќзјВЛзЁСЫЃЌвВМЦЛЎФкВт OpenAI ОпгаЧПДѓЕФЭјТчЙЅЗРФмСІЕФ AIЁЃ
4 дТ 9 ШеЃЌAxios БЌСЯЃКOpenAI е§дкзМБИвЛПюОпБИКмЧПЭјТчАВШЋФмСІЕФВњЦЗЃЌжЛЛсЯШИјЩйСПКЯзїЛяАщПЊЗХЁЃ
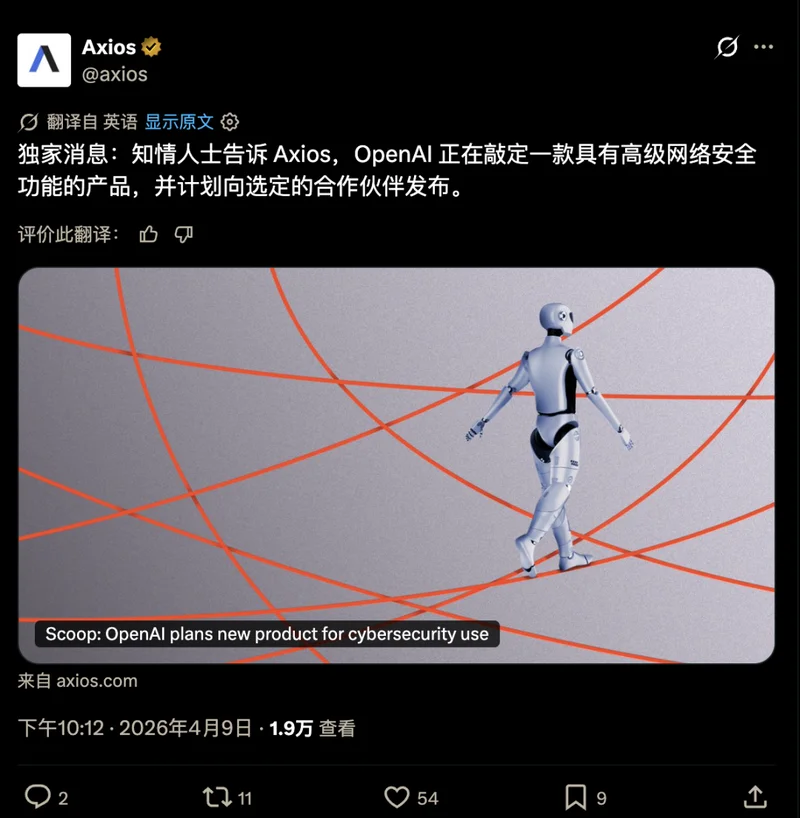
https://x.com/axios/status/2042244222292529371
етМўЪТБГКѓЃЌеце§жЕЕУСФЕФЃЌВЛЪЧ OpenAI гжвЊЗЂЪВУДаТЖЋЮїЁЃ
ЖјЪЧСэвЛМўИќЯХШЫЕФЪТЃЌAI дкЭјТчАВШЋетМўЪТЩЯЃЌПЩФмецЕФПчЙ§ФЧЬѕЯпСЫЁЃ
ШчЙћФуетМИИідТвЛжБдкЙизЂ AIЃЌФуЛсЗЂЯжвЛИіЬиБ№ЮЂУюЕФБфЛЏЁЃ
ЧАСНФъДѓМвСФФЃаЭЃЌСФЕФЪЧЛсВЛЛсаДЮФАИЃЌЛсВЛЛсзі PPTЃЌЛсВЛЛсаДДњТыЁЃ
дйКѓРДЃЌПЊЪМСФ AgentЃЌСФздЖЏжДааЃЌСФФмВЛФмздМКЕїгУЙЄОпЁЃ
ЕНСЫЯждкЃЌЬжТлвбОЭљСэвЛИіЗНЯђЛЌЙ§ШЅСЫЁЃ
ЫќФмВЛФмздМКевЕНТЉЖДЁЂИДЯжТЉЖДЁЂРћгУТЉЖДЁЃ
етМИИіЮЪЬтЃЌЬ§зХЯёАВШЋШІФкВПЛсвщЃЌВЛЯёЦеЭЈШЫЛсЙиаФЕФЪТЁЃ
ЕЋЬЙТЪЕФНВЃЌвЛЕЉД№АИПЊЪМНгНќЁИФмЁЙЃЌетОЭВЛЪЧвЛИіКкПЭШІЕФаЁаТЮХСЫЁЃ
етЪЧЛљДЁЩшЪЉМЖБ№ЕФДѓЪТЁЃ
вђЮЊТЉЖДетИіЖЋЮїЃЌВЛЪЧФуЕчФдРЖЦССЫжиЦєвЛЯТФЧУДМђЕЅЁЃ
ТЉЖДСЌзХЫЎГЇЃЌЕчЭјЃЌвНдКЃЌвјааЃЌфЏРРЦїЃЌВйзїЯЕЭГЃЌдЦЗўЮёЁЃ
Й§ШЅетаЉЖЋЮїжївЊППЖЅМЖАВШЋбаОПдБЁЂКьЖгЁЂЙњМвМЖЛњЙЙТ§Т§ЭкЁЃ
ЯждкЃЌФЃаЭПЊЪМЯТГЁСЫЁЃ
ЖјЧвВЛЪЧФЧжжАяФуВЙШЋСНааДњТыЕФЯТГЁЃЌЪЧФЧжжФуЭэЩЯАбШЮЮёНЛИјЫќЃЌЕкЖўЬьдчЩЯЦ№РДЃЌЫќАб PoCЁЂРћгУСДЁЂаоВЙНЈвщЖМИјФуАкзРЩЯЕФЯТГЁЁЃ
жЛЪЧЖд Anthropic MythosPR ВпТдЕФМђЕЅФЃЗТТ№ЃП
ОЭдкзюНќЃЌAnthropic вВзіСЫвЛИіКмЗДГЃЕФЖЏзїЁЃ
ЫћУЧУЛгаЯёЭљГЃвЛбљИпЕїЭЦаТФЃаЭЃЌЖјЪЧАбвЛИіНа Claude Mythos Preview ЕФФЃаЭЃЌШћНјСЫвЛИіНа Project Glasswing ЕФЗтБеМЦЛЎРяЃЌжЛИјЩйЪ§ПЦММЙЋЫОКЭАВШЋЙЋЫОгУЁЃ
Anthropic ЙйЗНИјГіЕФРэгЩЪЧЃКетИіФЃаЭЬЋЧПСЫЃЌЧПЕНВЛЪЪКЯСЂПЬЙЋПЊЁЃ
Anthropic ЙЋВМЕФвЛаЉВтЪдЯИНкЃЌЫЕецЕФЃЌвбОгаЕуШќВЉОЊуЄЦЌЕФИаОѕСЫЁЃ
ЫќФмдкДѓЙцФЃПЊдДЯюФПРяевЕНИпЮЃТЉЖДЃЌФмАбТЉЖДвЛТЗЭЦНјГЩПЩРћгУЕФЙЅЛїСДЃЌЩѕжСаДГіПчЖрИіТЉЖДЕФИДдгРћгУЁЃ
ИќПфеХЕФЪЧЃЌAnthropic ЕФбаОПЭХЖгЛЙЬсЕНЃЌСЌУЛгае§ЪНАВШЋбЕСЗБГОАЕФФкВПЙЄГЬЪІЃЌЖМФмШУЫќИєвЙШЅевдЖГЬДњТыжДааТЉЖДЃЌЕкЖўЬьабРДОЭПДЕНвЛЗнПЩдЫааЕФРћгУНсЙћЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
| бгЩьдФЖС |
ЭЦМі: