




[ЙШИш] ЙШИшФУГібЙЯфЕзММЪѕ,жаЙњПЊдДФЃаЭМДНЋгеН?
Gemma 4ФУГіСЫЙШИшбЙЯфЕзЕФММЪѕЁЃ
4дТ2ШеСшГПЃЌЙШИшDeepMind CEO Demis HassabisдкЩчНЛЦНЬЈXЩЯЗЂСЫЫФПХзъЪЏЕФemojiЃЌМИИіаЁЪБКѓЃЌУеЕзНвЯўЃЌЙШИше§ЪНЗЂВМСЫЦьЯТзюаТПЊдДДѓФЃаЭМвзхGemma 4ЃЌетЪЧЙШИшШыОжПЊдДAIШќЕРСНФъЖрРДЃЌФУГіЕФзюгаГЯвтЁЂвВзюОпЩБЩЫСІЕФзїЦЗЁЃ
Gemma 4ВЛЪЧЕЅвЛФЃаЭЃЌЖјЪЧвЛЬзИВИЧЪжЛњЕНЙЄзїеОШЋГЁОАЕФЭъећВњЦЗОиеѓЃЌЫФИіАцБОИїгаУїШЗЕФЖЈЮЛЃЌГЙЕзДђЦЦСЫЁАадФмЧПОЭБиаыЬхЛ§ДѓЁЂУХМїИпЁБЕФаавЕЙпадЁЃ
зюаЁЕФE2BКЭE4BСНПюЖЫВрФЃаЭЃЌУћзжРяЕФЁАEЁБДњБэЁАгааЇВЮЪ§ЁБЃЌЭЈЙ§ЙШИшздбаЕФУПВуЧЖШыЃЈPLEЃЉММЪѕЃЌАбФЃаЭЁАИЩЛюЕФКЫаФЫуСІЁБКЭЁАИЈжњЕФМЧвфДцДЂЁБФЃПщзіСЫВ№ЗжЃЌШУЫќдкдЫааЪБжЛЕїгУзюЩйЕФзЪдДЁЃ
ЦфжаE2BзмВЮЪ§51вкЃЌдЫааЪБгааЇВЮЪ§Ні23вкЃЌМЋЖЫЧщПіЯТФкДцеМгУФмбЙЕН1.5GBвдЯТЃЌЦеЭЈАВзПЪжЛњОЭФмЭъШЋРыЯпдЫааЃЌВЛгУСЊЭјЁЂВЛгУЩЯДЋЪ§ОнЃЌЛЙдЩњжЇГжЭМЦЌЁЂгявєЪфШыЃЌЯрЕБгкАбвЛИіОпБИЛљДЁЭЦРэФмСІЕФAIжњЪжЃЌЭъећШћНјСЫгУЛЇЕФПкДќРяЁЃ
E4BдђдкадФмКЭЙІКФжЎМфзіСЫЦНКтЃЌ45вкгааЇВЮЪ§ОЭФмХмГіНгНќЩЯвЛДњGemma 3 27BЦьНЂФЃаЭЕФаЇЙћЃЌЪЧЖЫВрЩшБИЕФжїСІАцБОЁЃ

жаМфЕФ 26B MoE АцБОдђОЋзМВШжаСЫПЊЗЂепзюЭДЕФ ЁАЫйЖШгыадФмЦНКтЁБ ашЧѓЃЌЫќВЩгУЛьКЯзЈМвМмЙЙЃЌЭЈЫзРДЫЕОЭЪЧФЃаЭФкжУСЫ 128 ИіВЛЭЌЗНЯђЕФ ЁАзЈвЕВПУХЁБЃЌУПДЮДІРэЮЪЬтЪБЃЌНіМЄЛюзюЖдПкЕФ 8 ИіВПУХМг 1 ИіЙВЯэаЕїВПУХЁЃ252 вкзмВЮЪ§РяЃЌЕЅДЮЭЦРэНіМЄЛю 38 вкВЮЪ§ЃЌзюжеЪЕЯжСЫ ЕЅ token ЩњГЩЫйЖШЖдБъ 4B МЖФЃаЭЃЌаЇЙћШДНгНќ 31B ЦьНЂФЃаЭЕФБэЯжЁЃ
ЖјзїЮЊЦьНЂЕФ31B DenseАцБОЃЌИќЪЧжБНгЫЂаТСЫПЊдДФЃаЭЕФВЮЪ§аЇТЪЩЯЯоЃЌ310вкШЋМЄЛюВЮЪ§ЃЌЮДСПЛЏЕФдАцШЈживЛеХ80GB H100ОЭФмзАЯТЃЌСПЛЏКѓЦеЭЈЯћЗбМЖЯдПЈвВФмСїГЉдЫааЃЌШДдквЕНчЙЋШЯЕФArena AIПЊдДФЃаЭХХааАёЩЯГхЕНСЫШЋЧђЕкШ§ЃЌгУВЛЕНЪЎЗжжЎвЛЕФВЮЪ§СПЃЌОЭФмКЭВЮЪ§СП400вкМЖБ№ЕФОоЮоАдФЃаЭъўЪжЭѓЁЃ
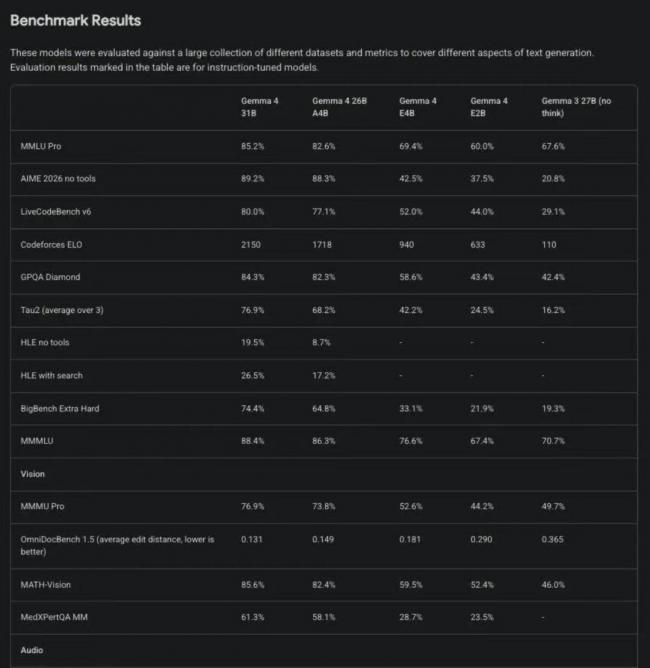
КЭЩЯвЛДњВњЦЗЯрБШЃЌЫќЕФЬсЩ§ЪЧДњМЪМЖБ№ЕФЃКAIME 2026Ъ§бЇОКШќВтЪдзМШЗТЪДг20.8%БЉеЧЕН89.2%ЃЌЗСЫЫФБЖЖрЃЛLiveCodeBenchДњТыВтЪдЕУЗжДг29.1%еЧЕН80%ЃЌЭЌЪБЛЙВЙЩЯСЫжЎЧАЕФЖЬАхЃЌГЄЩЯЯТЮФДАПкРЕН256KЃЌФмвЛДЮадДІРэМИЪЎЭђзжЕФЭъећЮФЕЕЃЌдЩњжЇГж140ЖржжгябдЃЌЖрФЃЬЌРэНтФмСІвВЪЕЯжСЫЗБЖЬсЩ§ЁЃ
ЖјзюШУШЋЧђПЊЗЂепОЊЯВЕФЃЌДгРДЖМВЛжЛЪЧадФмЃЌЖјЪЧЙШИшжегкЗХЯТСЫзЫЬЌЃЌАбGemma 4ЕФПЊдДавщЛЛГЩСЫаавЕзюПэЫЩЁЂзюЪмШЯПЩЕФApache 2.0ЁЃдкДЫжЎЧАЃЌGemmaЧАШ§ДњВњЦЗгУЕФЖМЪЧЙШИшздЖЈвхЕФПЊдДавщЃЌВЛНігажюЖрЩЬгУЯожЦЃЌЙШИшЛЙФмЕЅЗНУцаоИФЙцдђЃЌЩѕжСгаЬѕПюБЛНтЖСЮЊЁАгУGemmaЩњГЩЕФЪ§ОнбЕСЗаТФЃаЭЃЌаТФЃаЭвВвЊЪмИУавщдМЪјЁБЃЌШУКмЖрПЊЗЂепКЭЦѓвЕВЛИвЗХаФЩЬгУЃЌХТТёЯТЗЈТЩЗчЯеЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
КУаТЮХУЛШЫЦРТлдѕУДааЃЌЮвРДЫЕМИОф
4дТ2ШеСшГПЃЌЙШИшDeepMind CEO Demis HassabisдкЩчНЛЦНЬЈXЩЯЗЂСЫЫФПХзъЪЏЕФemojiЃЌМИИіаЁЪБКѓЃЌУеЕзНвЯўЃЌЙШИше§ЪНЗЂВМСЫЦьЯТзюаТПЊдДДѓФЃаЭМвзхGemma 4ЃЌетЪЧЙШИшШыОжПЊдДAIШќЕРСНФъЖрРДЃЌФУГіЕФзюгаГЯвтЁЂвВзюОпЩБЩЫСІЕФзїЦЗЁЃ
Gemma 4ВЛЪЧЕЅвЛФЃаЭЃЌЖјЪЧвЛЬзИВИЧЪжЛњЕНЙЄзїеОШЋГЁОАЕФЭъећВњЦЗОиеѓЃЌЫФИіАцБОИїгаУїШЗЕФЖЈЮЛЃЌГЙЕзДђЦЦСЫЁАадФмЧПОЭБиаыЬхЛ§ДѓЁЂУХМїИпЁБЕФаавЕЙпадЁЃ
зюаЁЕФE2BКЭE4BСНПюЖЫВрФЃаЭЃЌУћзжРяЕФЁАEЁБДњБэЁАгааЇВЮЪ§ЁБЃЌЭЈЙ§ЙШИшздбаЕФУПВуЧЖШыЃЈPLEЃЉММЪѕЃЌАбФЃаЭЁАИЩЛюЕФКЫаФЫуСІЁБКЭЁАИЈжњЕФМЧвфДцДЂЁБФЃПщзіСЫВ№ЗжЃЌШУЫќдкдЫааЪБжЛЕїгУзюЩйЕФзЪдДЁЃ
ЦфжаE2BзмВЮЪ§51вкЃЌдЫааЪБгааЇВЮЪ§Ні23вкЃЌМЋЖЫЧщПіЯТФкДцеМгУФмбЙЕН1.5GBвдЯТЃЌЦеЭЈАВзПЪжЛњОЭФмЭъШЋРыЯпдЫааЃЌВЛгУСЊЭјЁЂВЛгУЩЯДЋЪ§ОнЃЌЛЙдЩњжЇГжЭМЦЌЁЂгявєЪфШыЃЌЯрЕБгкАбвЛИіОпБИЛљДЁЭЦРэФмСІЕФAIжњЪжЃЌЭъећШћНјСЫгУЛЇЕФПкДќРяЁЃ
E4BдђдкадФмКЭЙІКФжЎМфзіСЫЦНКтЃЌ45вкгааЇВЮЪ§ОЭФмХмГіНгНќЩЯвЛДњGemma 3 27BЦьНЂФЃаЭЕФаЇЙћЃЌЪЧЖЫВрЩшБИЕФжїСІАцБОЁЃ
жаМфЕФ 26B MoE АцБОдђОЋзМВШжаСЫПЊЗЂепзюЭДЕФ ЁАЫйЖШгыадФмЦНКтЁБ ашЧѓЃЌЫќВЩгУЛьКЯзЈМвМмЙЙЃЌЭЈЫзРДЫЕОЭЪЧФЃаЭФкжУСЫ 128 ИіВЛЭЌЗНЯђЕФ ЁАзЈвЕВПУХЁБЃЌУПДЮДІРэЮЪЬтЪБЃЌНіМЄЛюзюЖдПкЕФ 8 ИіВПУХМг 1 ИіЙВЯэаЕїВПУХЁЃ252 вкзмВЮЪ§РяЃЌЕЅДЮЭЦРэНіМЄЛю 38 вкВЮЪ§ЃЌзюжеЪЕЯжСЫ ЕЅ token ЩњГЩЫйЖШЖдБъ 4B МЖФЃаЭЃЌаЇЙћШДНгНќ 31B ЦьНЂФЃаЭЕФБэЯжЁЃ
ЖјзїЮЊЦьНЂЕФ31B DenseАцБОЃЌИќЪЧжБНгЫЂаТСЫПЊдДФЃаЭЕФВЮЪ§аЇТЪЩЯЯоЃЌ310вкШЋМЄЛюВЮЪ§ЃЌЮДСПЛЏЕФдАцШЈживЛеХ80GB H100ОЭФмзАЯТЃЌСПЛЏКѓЦеЭЈЯћЗбМЖЯдПЈвВФмСїГЉдЫааЃЌШДдквЕНчЙЋШЯЕФArena AIПЊдДФЃаЭХХааАёЩЯГхЕНСЫШЋЧђЕкШ§ЃЌгУВЛЕНЪЎЗжжЎвЛЕФВЮЪ§СПЃЌОЭФмКЭВЮЪ§СП400вкМЖБ№ЕФОоЮоАдФЃаЭъўЪжЭѓЁЃ
КЭЩЯвЛДњВњЦЗЯрБШЃЌЫќЕФЬсЩ§ЪЧДњМЪМЖБ№ЕФЃКAIME 2026Ъ§бЇОКШќВтЪдзМШЗТЪДг20.8%БЉеЧЕН89.2%ЃЌЗСЫЫФБЖЖрЃЛLiveCodeBenchДњТыВтЪдЕУЗжДг29.1%еЧЕН80%ЃЌЭЌЪБЛЙВЙЩЯСЫжЎЧАЕФЖЬАхЃЌГЄЩЯЯТЮФДАПкРЕН256KЃЌФмвЛДЮадДІРэМИЪЎЭђзжЕФЭъећЮФЕЕЃЌдЩњжЇГж140ЖржжгябдЃЌЖрФЃЬЌРэНтФмСІвВЪЕЯжСЫЗБЖЬсЩ§ЁЃ
ЖјзюШУШЋЧђПЊЗЂепОЊЯВЕФЃЌДгРДЖМВЛжЛЪЧадФмЃЌЖјЪЧЙШИшжегкЗХЯТСЫзЫЬЌЃЌАбGemma 4ЕФПЊдДавщЛЛГЩСЫаавЕзюПэЫЩЁЂзюЪмШЯПЩЕФApache 2.0ЁЃдкДЫжЎЧАЃЌGemmaЧАШ§ДњВњЦЗгУЕФЖМЪЧЙШИшздЖЈвхЕФПЊдДавщЃЌВЛНігажюЖрЩЬгУЯожЦЃЌЙШИшЛЙФмЕЅЗНУцаоИФЙцдђЃЌЩѕжСгаЬѕПюБЛНтЖСЮЊЁАгУGemmaЩњГЩЕФЪ§ОнбЕСЗаТФЃаЭЃЌаТФЃаЭвВвЊЪмИУавщдМЪјЁБЃЌШУКмЖрПЊЗЂепКЭЦѓвЕВЛИвЗХаФЩЬгУЃЌХТТёЯТЗЈТЩЗчЯеЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
| бгЩьдФЖС | ИќЖр... |
ЭЦМі: