




[ЮЂШэ] ФуЕФOfficeБЛСНИіAIНгЙмСЫ ЮЂШэФЌШЯПЊЦє

DRACOЛљзМВтЪдзлКЯЕУЗжЖдБШЭМЃКИїЩюЖШбаОПЯЕЭГЃЈКЌResearcher with CritiqueЁЂPerplexity Deep ResearchЕШЃЉКсЯђЕУЗжЖдБШЁЃЦфжаГ§Researcher with CritiqueЭтЃЌЦфгрЖдБШНсЙћв§здZhong et al., arXiv:2602.11685ЁЃ
В№ПЊЫФИіЮЌЖШПДЃК
ЗжЮіЙуЖШКЭЩюЖШЬсЩ§зюУїЯдЃЌ+3.33ЁЃЦфДЮЪЧБэДяжЪСП+3.04ЃЌЪТЪЕзМШЗад+2.58ЁЃв§гУжЪСПЭЌбљгаЬсЩ§ЁЃ
ЫљгаЮЌЖШОљДяЕНЭГМЦбЇЯджјЃЈХфЖдtМьбщЃЌp
еце§жЕЕУзЂвтЕФЪЧФЧИі+3.33ЁЃЗжЮіЩюЖШЕФьЩ§ЫЕУїCritiqueзюДѓЕФМлжЕВЛЪЧОРДэЃЌЖјЪЧПЩвдБЦГіИќШЋУцЕФЗжЮіЪгНЧЁЃ
дкСьгђВуУцЃЌ10ИіСьгђжага8ИіЙлВьЕНЯджјЬсЩ§ЃЌИВИЧвНбЇЁЂММЪѕЁЂЗЈТЩЕШКЫаФГЁОАЁЃ
НігаЕФСНИіР§ЭтЪЧЁАбЇЪѕЁБКЭЁАДѓКЃРЬеыЁБЃЌетСНИіСьгђВтЪдНсЙћВЈЖЏНЯДѓЁЃ
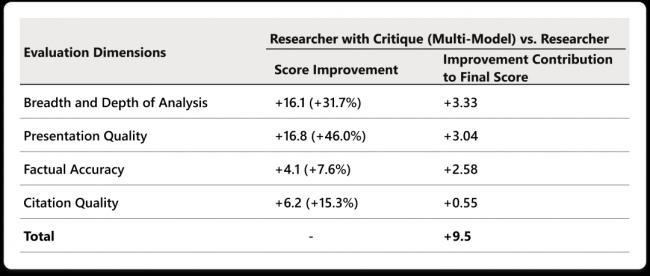
DRACOЛљзМЫФЯюЦРВтЮЌЖШЬсЩ§БэЃКResearcher with CritiqueЃЈЖрФЃаЭЃЉЯрНЯЕЅФЃаЭ ResearcherЃЌдкЗжЮіЙуЖШгыЩюЖШЁЂГЪЯжжЪСПЁЂЪТЪЕзМШЗадКЭв§гУжЪСПЩЯЕФЬсЩ§ЃЌвдМАИїЯюЖдзюжезмЗжЕФЙБЯзЁЃ
13.8%Ь§Ц№РДЪЧвЛИіЪ§зжЁЃ
дкЩюЖШбаОПетИіШќЕРЩЯЃЌДЫЧАИїМвДђЕУФбЗжФбНтЃЌPerplexityДюдиClaude Opus 4.6КУВЛШнвзХРЕНЕФЬьЛЈАхЃЌЯждкБЛCritiqueвЛИіМмЙЙДДаТжБНгЛїДЉСЫЁЃ
ЕБФуашвЊЕФВЛЪЧвЛИіД№АИЃЌЖјЪЧвЛГЁБчТл
CritiqueНтОіЕФЪЧЁАдѕУДШУвЛЗнБЈИцИќзМЁБЕФЮЪЬтЁЃ
ЕЋгааЉГЁОАЃЌФувЊЕФИљБОВЛЪЧвЛЗнОЋаоИхЃЌЖјЪЧСНИізЈМвГГвЛМмЁЃ
ЖјетЃЌОЭЪЧCouncilЕФЖЈЮЛЁЃ
дкФЃаЭбЁдёЦїжабЁЁАModel CouncilЁБЃЌGPTКЭClaudeЛсИїздЖРСЂЩњГЩвЛЗнЭъећБЈИцЃЌВЂХХеЙЪОЁЃ
ШЛКѓЃЌвЛИізЈУХЕФЦРЮЏФЃаЭЛсЖдСНЗнБЈИцНјааЦРЙРЃЌЩњГЩвЛЗнзлЪіЃЈCover LetterЃЉЃЌЩюШыЗжЮіЫЋЗНдкФФаЉЙлЕуЩЯДяГЩвЛжТЁЂдкКЮДІДцдкЗжЦчЃЌвдМАИїздДјРДЕФЖРЬиМћНтЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
| бгЩьдФЖС | ИќЖр... |
ЭЦМі: