




жБЛїGTC,РЯЛЦОЭжИзХФуЩеtokenСЫ
НёФъЯдШЛгжЪЧгЂЮАДяетМв33ЫъЙЋЫОгжвЛИіЙиМќЪБПЬЃЌШЫУЧЯёЦкД§Ъ§ТыВњЦЗвЛбљЦкД§ЫќЕФаОЦЌИќаТЃЌЖдГЌдЄЦкЕФВЦБЈЩѕжСЖМЬсВЛЦ№аЫШЄЃЌблПДгааЉНРЩВХОЁЕФЪБПЬЃЌЛЦШЪбЋгжДјРДСЫаТЕФЙЪЪТЁЃ
3дТ16ШеЃЌдк2026ФъгЂЮАДяGTCДѓЛсЩЯЃЌЛЦШЪбЋзіСЫЭђжкЦкД§ЕФжїжМбнНВЁЃШЫУЧПДД§гЂЮАДяЃЌЙиаФКЭЕЃаФЕФЖМЪЧЫќЕФдіГЄЁЃЖјНёФъGTCЃЌвЛИіЛЈ20вкУРН№ЪеЙКРДЕФGroqЃЌвЛИіЭЛШЛОЭИФБфСЫвЛЧаВЂПДЦ№РДНтОіСЫЁАгІгУЦеМАЮЪЬтЁБЕФOpenClawЃЌГЩСЫдіГЄЙЪЪТРяЕФОјЖджїНЧЁЃ
GroqЕФаТаОЦЌШкШыгЂЮАДяЬхЯЕКѓЃЌгЂЮАДяаћГЦЛсИјЫќЕФПЭЛЇУЧНтЫјвЛИі3000вкУРН№ЕФдіСПЪаГЁЃЛ
ЭЌЪБгЂЮАДявВЛсАбGroqИќЩюШыШкШыЯТвЛДњаОЦЌМмЙЙFeynmann РяЃЛ
ЖјдкЫћОјЖдВЛЛсГйЕНЕФЁАаЁСњЯКЁБПёШШРяЃЌЛЦШЪбЋвЊШУгЂЮАДяБфГЩOpenClawУЧЕФЕзВуЃЌдйДЮЩЯбнвЛГіCUDAЭЌбљЕФЯЗТыЁЃ
ОЁЙмЯрБШGTCзюЛдЛЭЕФФЧаЉЗЂВМЃЌНёФъЕФећИіЗЂВМЕФДѓЖрЪБМфЯдЕУгаЕуЗІЩЦПЩГТЃЌЕЋетаЉвбОзуЙЛШУЛЦШЪбЋаХаФТњТњЃЌЫћБэЪОЃК
2025ФъЕН2027ФъЃЌгЂЮАДяЕФаОЦЌЩњвтНЋЛсМЬајЩЯеЧЃЌеЧЕН1ЭђвкУРН№ЁЃ

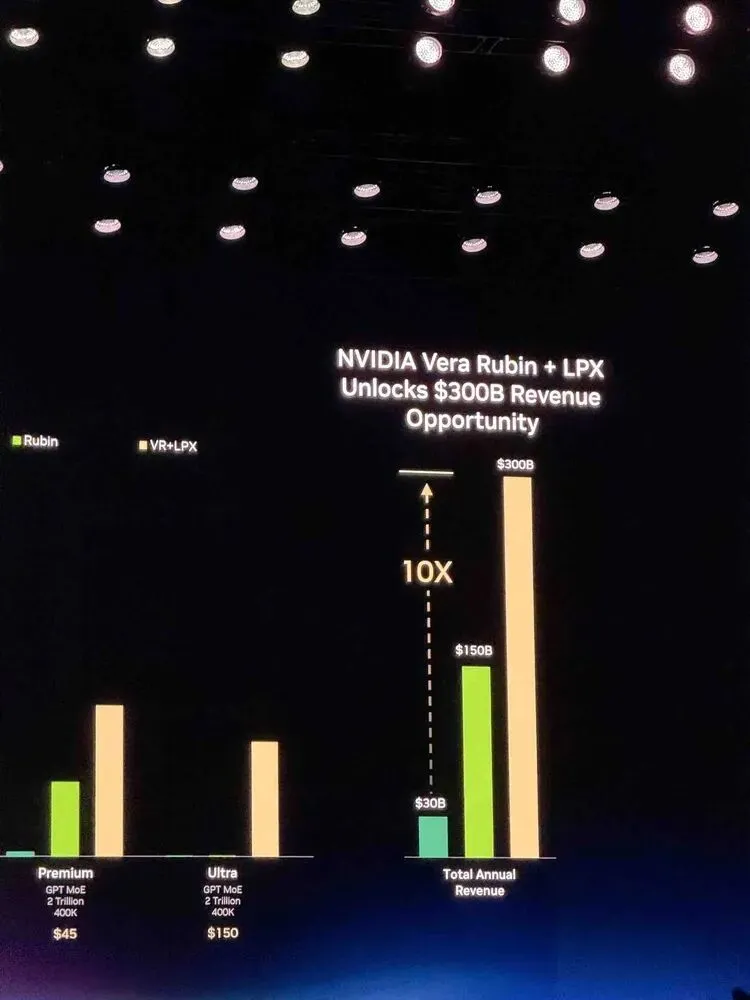
Vera Rubin + GroqЃЌЦпПХаОЦЌКЯЬх
ЛЦШЪбЋеЙЪОСЫЫћаЮШнЮЊШЋаТЕФAIЛљДЁЩшЪЉВуЕФШЋУВЁЃ
ЫћВЛдйОйзХвЛПХаОЦЌЫЕЁАthis is our new GPUЁБСЫЁЃЫћАбећИіVera RubinЛњМмАсЩЯСЫЮшЬЈЃЌЫЕетвЛДЮгЂЮАДяЯыЕФЪЧећЬзЯЕЭГЃЌДгаОЦЌЕНШэМўЕНЛЅСЌЃЌЖЫЕНЖЫДЙжБећКЯЃЌзїЮЊвЛЬЈГЌМЖМЦЫуЛњРДгХЛЏЁЃ

ЩЯвЛДњBlackwell UltraвбОЪЕЯжСЫЖдБШHopper 50БЖЕФЭЬЭТаЇТЪЬсЩ§ЃЌЖјVera Rubin + GroqдкДЫЛљДЁЩЯгжАбЧАбиЭЦЕНСЫаТЕФЧјМфЃЌетЬзЯЕЭГгЩЦпПХаОЦЌзщГЩЁЃКЫаФRubin GPUВЩгУЬЈЛ§Еч3nmЙЄвеЃЌЫЋаОЦЌЗтзАЃЌ336BОЇЬхЙмЃЌХфБИ288GB HBM4ФкДцКЭ22TB/sДјПэЃЌNVFP4ЭЦРэадФмДяЕН50 PFLOPsЃЌБШЩЯвЛДњBlackwellЬсЩ§5БЖЃЌбЕСЗадФм35 PFLOPsЃЌЬсЩ§3.5БЖЁЃХфЬзЕФVera CPUЪЧ88КЫЖЈжЦArmМмЙЙЃЈДњКХOlympusЃЉЃЌ176ЯпГЬЃЌШЋЧђЪзПюдкЪ§ОнжааФВЩгУLPDDR5ЕФCPUЃЌзЈУХЮЊAgentЭЦРэГЁОАЯТЕФИпЕЅЯпГЬадФмКЭЪ§ОнДІРэзіСЫгХЛЏЁЃЛЦШЪбЋЫЕетПХCPUЖРСЂТєЁАПЯЖЈЛсГЩЮЊЪ§ЪЎвкУРдЊЕФвЕЮёЁБЁЃ
[МгЮїЭје§еаЦИЖрУћШЋжАsales Д§гігХ]
ЮоЦРТлВЛаТЮХЃЌЗЂБэвЛЯТФњЕФвтМћАЩ
3дТ16ШеЃЌдк2026ФъгЂЮАДяGTCДѓЛсЩЯЃЌЛЦШЪбЋзіСЫЭђжкЦкД§ЕФжїжМбнНВЁЃШЫУЧПДД§гЂЮАДяЃЌЙиаФКЭЕЃаФЕФЖМЪЧЫќЕФдіГЄЁЃЖјНёФъGTCЃЌвЛИіЛЈ20вкУРН№ЪеЙКРДЕФGroqЃЌвЛИіЭЛШЛОЭИФБфСЫвЛЧаВЂПДЦ№РДНтОіСЫЁАгІгУЦеМАЮЪЬтЁБЕФOpenClawЃЌГЩСЫдіГЄЙЪЪТРяЕФОјЖджїНЧЁЃ
GroqЕФаТаОЦЌШкШыгЂЮАДяЬхЯЕКѓЃЌгЂЮАДяаћГЦЛсИјЫќЕФПЭЛЇУЧНтЫјвЛИі3000вкУРН№ЕФдіСПЪаГЁЃЛ
ЭЌЪБгЂЮАДявВЛсАбGroqИќЩюШыШкШыЯТвЛДњаОЦЌМмЙЙFeynmann РяЃЛ
ЖјдкЫћОјЖдВЛЛсГйЕНЕФЁАаЁСњЯКЁБПёШШРяЃЌЛЦШЪбЋвЊШУгЂЮАДяБфГЩOpenClawУЧЕФЕзВуЃЌдйДЮЩЯбнвЛГіCUDAЭЌбљЕФЯЗТыЁЃ
ОЁЙмЯрБШGTCзюЛдЛЭЕФФЧаЉЗЂВМЃЌНёФъЕФећИіЗЂВМЕФДѓЖрЪБМфЯдЕУгаЕуЗІЩЦПЩГТЃЌЕЋетаЉвбОзуЙЛШУЛЦШЪбЋаХаФТњТњЃЌЫћБэЪОЃК
2025ФъЕН2027ФъЃЌгЂЮАДяЕФаОЦЌЩњвтНЋЛсМЬајЩЯеЧЃЌеЧЕН1ЭђвкУРН№ЁЃ
Vera Rubin + GroqЃЌЦпПХаОЦЌКЯЬх
ЛЦШЪбЋеЙЪОСЫЫћаЮШнЮЊШЋаТЕФAIЛљДЁЩшЪЉВуЕФШЋУВЁЃ
ЫћВЛдйОйзХвЛПХаОЦЌЫЕЁАthis is our new GPUЁБСЫЁЃЫћАбећИіVera RubinЛњМмАсЩЯСЫЮшЬЈЃЌЫЕетвЛДЮгЂЮАДяЯыЕФЪЧећЬзЯЕЭГЃЌДгаОЦЌЕНШэМўЕНЛЅСЌЃЌЖЫЕНЖЫДЙжБећКЯЃЌзїЮЊвЛЬЈГЌМЖМЦЫуЛњРДгХЛЏЁЃ
ЩЯвЛДњBlackwell UltraвбОЪЕЯжСЫЖдБШHopper 50БЖЕФЭЬЭТаЇТЪЬсЩ§ЃЌЖјVera Rubin + GroqдкДЫЛљДЁЩЯгжАбЧАбиЭЦЕНСЫаТЕФЧјМфЃЌетЬзЯЕЭГгЩЦпПХаОЦЌзщГЩЁЃКЫаФRubin GPUВЩгУЬЈЛ§Еч3nmЙЄвеЃЌЫЋаОЦЌЗтзАЃЌ336BОЇЬхЙмЃЌХфБИ288GB HBM4ФкДцКЭ22TB/sДјПэЃЌNVFP4ЭЦРэадФмДяЕН50 PFLOPsЃЌБШЩЯвЛДњBlackwellЬсЩ§5БЖЃЌбЕСЗадФм35 PFLOPsЃЌЬсЩ§3.5БЖЁЃХфЬзЕФVera CPUЪЧ88КЫЖЈжЦArmМмЙЙЃЈДњКХOlympusЃЉЃЌ176ЯпГЬЃЌШЋЧђЪзПюдкЪ§ОнжааФВЩгУLPDDR5ЕФCPUЃЌзЈУХЮЊAgentЭЦРэГЁОАЯТЕФИпЕЅЯпГЬадФмКЭЪ§ОнДІРэзіСЫгХЛЏЁЃЛЦШЪбЋЫЕетПХCPUЖРСЂТєЁАПЯЖЈЛсГЩЮЊЪ§ЪЎвкУРдЊЕФвЕЮёЁБЁЃ
[МгЮїЭје§еаЦИЖрУћШЋжАsales Д§гігХ]
| ЗжЯэ: |
| зЂЃК | дкДЫвГдФЖСШЋЮФ |
ЭЦМі: