




“‘ќ“µƒ”H…нуwтЮ,’Д’Д»зЇќ’эі_јнљв"рBќr"
2026ƒк1‘¬£ђ“ЉВАљ–ClawdbotµƒВА»ЋAI÷ъјнїрЅЋ£ђ «™ЪЅҐй_∞l’яPeter Steinberger£®±Ћµ√°§ ©ћ©“т≤ЃЄс£©2025ƒк11‘¬24»’ДУљ®µƒ°£“тЮй√ы„÷≈cAnthropicµƒClaudeіуƒ£–Ќљ”љь£ђ„ч’яМҐ∆дЄƒ√ыЮйMoltbot£ђБKљ®ЅҐЅЋЈ«≥£їо№Sµƒй_∞l’я…зЕ^Moltbook°£3‘¬10»’£ђ ’ўПРџЇ√’я‘ъњЋ≤ЃЄсМҐMoltbook…зЕ^Љ{»л∆мѕ¬£ђґшSteinberger‘з‘Џ2‘¬ЊЌ±їOpenAIЌЏ„я°£
єP’яµЏ“ЉХrйgЊЌкP„ҐЅЋ ¬Љю£ђБKМСќƒ‘u’УЅЋMoltbot≈c°∞“Љ»ЋєЂЋЊ°±£®∞l‘Џ2‘¬6»’µƒ≠h«тХrИу£©£ђљйљBAI≈c÷–Зш÷∆‘мШIЈ÷ДeПƒ№Ы”≤Г…Јљ√жћбє©±гљЁЈюД’£ђМ¶мґВА»ЋДУШIЇ№”–“вЅx°£Ы]ѕлµљµƒ «£ђ3‘¬ХrґаЉ“÷–Зшї•¬УЊWЊёо^≈cіуƒ£–ЌєЂЋЊґЉЕҐ≈cяMБнЅЋ£ђ“Љ–©µЎЈљ’юЄЃґЉ≥цўYЉ§ДоВА»Ћй_∞l’я£ђЯбґ»≈c2023ƒк≥хµƒChatGPT°Ґ2025ƒк≥хµƒDeepSeekњ…“‘ѕа±»°£
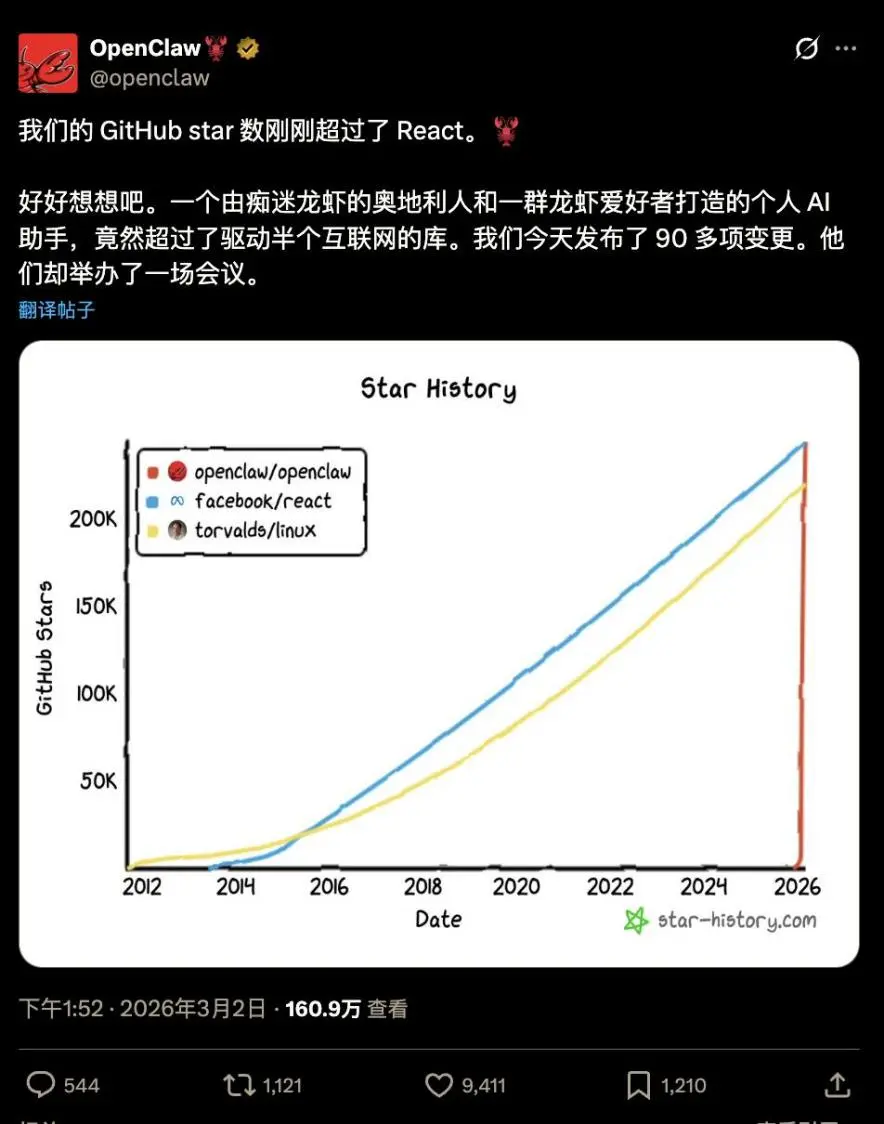
Moltbotмґ2026ƒк1‘¬30»’’э љЄь√ыЮйOpenClaw£ђБKмґ2‘¬24»’≥ђя^”–30ƒкЪv ЈµƒLINUX°Ґ3‘¬2»’≥ђя^React£ђ≥…Юйй_‘і…зЕ^GitHub Ј…ѕ–«ШЋ„оґаµƒ№ЫЉюнЧƒњ°£љьЇхіє÷±µƒ‘цйL«ъЊА≥…Юйй_‘і№ЫЉюЪv Ј…ѕµƒ∆ж”^°£
OpenClaw„чЮйй_‘інЧƒњ£ђ є”√”–“Љґ®йTЩС£ђ÷–ЗшРџЇ√’я”–ƒ№Ѕ¶„‘––ѕ¬Ёd∞≤—bµƒ≤їґа°£KimiClaw «÷–Зшіуƒ£–ЌєЂЋЊ„о‘зЌ∆≥цµƒOpenClawлЕЈюД’£ђ≤ї «—b‘ЏВА»ЋлКƒX…ѕ£ђґш «‘ЏлЕ…ѕй_LINUXћУФMЩC£ђ∞≤—bЈљ±г£ђіЇєЭ«∞Ќ∆≥цЅЋ‘Зьc°£бб√жMaxClaw°ҐDuClawµ»ЄчоРлЕClawЃa∆Ј‘љБн‘љґа£ђ∞Ґ—eлЕ°Ґтv”НлЕ°Ґ»AЮй(专题)лЕ°Ґїр…љ“э«ж°ҐЊ©Ц|лЕ°Ґ“∆Д”лЕ°Ґћм“нлЕґЉЌ∆≥цЅЋ°∞“ЉжI≤њ р°±љвЫQЈљ∞Є°£яА”–AutoClaw°ҐQClawя@–©„чЮйWindows°ҐMacOSµƒ≥ћ–т∞≤—b∞ь£ђ—b‘Џ”√СфВА»ЋлКƒX…ѕµƒ°£
я@–©°∞Claw°±ЈюД’µƒЌ∆≥ц£ђШЋ÷Њ÷ш÷–ЗшAIПS…ћ’э‘Џ†ОКZOpenClaw…ъСB÷чМІЩа£ђ≈c2025ƒк2-3‘¬ЄчПS…ћЉКЉК≤њ рљ”»лDeepSeekоРЋ∆°£
“Љ. ћљЋчOpenClawµƒґаЈNЈљ љ
KimiClawмґ2‘¬18»’’э љ…ѕЊА£ђєP’яЅҐњћљїЅЋ199‘¬ўM£ђ≈dЫ_Ы_µЎ°∞“ЉжI∞≤—b°±°£О„ћмґЉяB≤ї…ѕЈюД’∆ч£ђС™‘У «іЇєЭЫ]…ѕ∞а°£2‘¬22»’МўмґєP’яµƒKimiClawљKмґїоЅЋ£ђ∞іћ„¬Ј‘O÷√яB…ѕпwХш“‘бб£ђњ…“‘нШХ≥ є”√ЅЋ°£єP’яµƒ≈d»§ «ЅЋљвOpenClawµƒЉ№ШЛ≈c‘≠јн£ђя@Јљ√ж”–“Љ–©–ƒµ√£ђМ¶мґ∆дГЮДЁ≈c»±ѕЁµƒЄщ‘і“≤Ё^Юй«е≥ю°£
±ЊќƒМ¶OpenClawяM––‘≠јн–‘ЉЉ–gљвбМ£ђХю∆’Љ∞“Љ–©їщµAЄ≈ƒо°£Єь÷Ў“™µƒ «моч»£ђ’эі_’J„Rя@÷їЯбґ»њ’«∞µƒ°∞эИќr°±£ђ≤ї…сїѓ∆дє¶ƒ№£ђЅЋљв∆дЊёіуµƒЭУЅ¶≈c±Њў|»±ѕЁ°£
÷–Зш“—љЫљ”…ѕOpenClawµƒ”√Сф£ђ“Љ∞гЇЌЋь”–Г…ВАљїї•«юµј°£“ЉВА «пwХшµ» ÷ЩCЉіХrЌ®”НAPP£ђ…ѕ√жЉ”ЅЋClawЩC∆ч»Ћ£ђЅƒћмѕ¬я_÷ЄЅо°Ґљ” ’ќƒЉю£ђѕа–≈ќҐ–≈≤їЊ√“≤Хюіу“Оƒ£љ”»л°£∆д‘≠јн «£ђпwХшХюћбє©APIљ”»лёkЈ®£ђOpenClaw”–ЅЋAPIЩаѕё“‘бб£ђЊЌњ…“‘ЇЌпwХшЌ®–≈£ђљ” ’÷ЄЅо°ҐЈµїЎљYєы°£я@“≤ «Steinbergerй_∞lOpenClawµƒ≥х÷‘£ђѕл”√ ÷ЩCЉіХrЌ®”НAPPяBљ”„‘ЉЇµƒлКƒX£ђяh≥ћ≤йњіљYєы°Ґ÷ЄУ]О÷їо°£ƒњ«∞я@“≤ «ЇЌOpenClaw„о÷ч“™µƒЬѕЌ®Јљ љ°£
М¶мґлЕ…ѕ≤њ рµƒOpenClaw£ђЅн“ЉВА≥£”√«юµј «іуƒ£–ЌЊWнУїтіуƒ£–Ќ ÷ЩCAPP…ѕµƒЅƒћмљз√ж°£»зєP’яЊWнУ…ѕЅЋKimiіуƒ£–Ќ£ђ…ѕ√жЊЌ”–KimiClawљз√ж£ђ“≤ƒ№Ѕƒћмѕ¬я_÷ЄЅо°£“Љй_ Љ÷ї”–PCЊWнУ∞жњ…“‘£ђббБн ÷ЩCKimi APP“≤њ…“‘ЅЋ°£
єP’яуwтЮѕ¬Бн£ђ∞lђFЈ°’я”–÷ЎіуЕ^Дe°£пwХш «÷±яBKimiClaw£ђљ” ’µƒ «OpenClawµƒИћ––љYєы£ђƒ№ ’ќƒЉю°£пwХш…ѕµƒЅƒћм“≤љЫя^іуƒ£–ЌћОјн «÷«ƒ№µƒ£ђµЂ”…мґ «Ј«ЉіХrЬѕЌ®£ђ №ѕёмґпwХшAPIµƒЄс љ≈c„÷єЭѕё÷∆£ђ–≈ѕҐ∞lЋЌ“™ЙЇњs£ђ–≈ѕҐЇђЅњ”–ѕё£ђјэ»зњі≤їµљіуƒ£–ЌµƒЋЉњЉя^≥ћ°£ґш‘ЏKimiЊWнУїт’яKimi ÷ЩCAPP…ѕ£ђ «÷±љ”≈cKimiіуƒ£–ЌЅƒћм£ђ÷ч“™Г»»Ё «іуƒ£–ЌЁФ≥цµƒ£ђ”–ЋЉњЉя^≥ћ£ђ–≈ѕҐ√чп@ЄьЎSЄї£ї∆д÷–КAлsЅЋ“Љ–©OpenClawИћ––÷ЄЅоµƒљYєы£ђµЂќƒЉю ’≤їЅЋ£ђ–и“™∞lµљпwХш…ѕ°£єP’яяxУс≈cіуƒ£–Ќ÷±љ”Ѕƒћмµƒƒ£ љ£ђ“‘пwХш ’ќƒЉюЮйЁo÷ъ°£я@Ш”ƒ№МWµљЇ№ґаЦ|ќч£ђњ…“‘÷±љ”ћбЖЦ£ђ≥цЅЋЖЦо}іуƒ£–Ќƒ№љo≥цґаЈNљвЫQЈљ∞ЄяxУс£ђЗL‘Зя^≥ћњ…“К£ђ «МWЅХћљЋчOpenClaw≤їеeµƒЈљ љ°£
ВА»ЋлКƒX…ѕ∞≤—bµƒOpenClaw£ђ“≤”–я@ЈNЅƒћмљз√ж°£AutoClaw°ҐQClawЈв—b∞жµƒХю”–Ќк’ы„ј√жњЌСфґЋ£ђХюћбє©М¶‘Тњт°£я@ЈNƒ£ љ£ђ”…мґВА»ЋлКƒXя\––†оСB°Ґіуƒ£–ЌAPIґЉƒ№÷±љ”≤йњіњЎ÷∆£ђƒ№ћбє©ЄьЮйЎSЄїµƒя\––ЉЪєЭ–≈ѕҐ°£
єP’яЮйЅЋјнљвOpenClawЉ№ШЛ≈c‘≠јн£ђяА”–“ЉЈN„о÷±љ”µƒ°∞ћљЋч°±ёkЈ®£ђЊЌ «яM»лKimiClaw°∞Њ”„°°±µƒLinuxћУФMЩCљKґЋ£ђ «Ubuntu 24.04ѕµљy£ђKimiClawЊWнУ∞жћбє©ЅЋ»лњЏ°£»зєыМ¶Linux≤ў„чѕµљy≈c√ьЅоЁ^Юй мѕ§£ђЊЌњ…“‘»•„–ЉЪњіњіќƒЉюљYШЛ£ђИћ––ґаЈNµ„М”√ьЅо£ђ≤рљвOpenClawИћ––»ќД’µƒя^≥ћ°£»зМ¶мґOpenClawµƒSkills°ҐMemoryя@–©°∞ЉЉƒ№°±°Ґ°∞”ЫСЫ°±ѕакPµƒ÷Ў“™≤њЉю£ђњ…“‘÷±љ”≤йњіѕакPќƒЉюГ»»Ё£ђПƒ„̔љ“√Ў°£
µЂя@ЈNћљЋчёkЈ®–и“™ѕаЃФµƒLinux÷™„R£ђяBИD–ќ≤ў„чљз√жґЉЫ]”–£ђ уШЋЌк»ЂЯo”√£ђ–и“™ЁФ»л‘Sґа√ьЅо°£»зЯoљЫтЮХюлy“‘≤ў„ч£ђЉі єМСќƒ’¬Ѕ–≥ц≤ў„чЉЪєЭ£ђ“≤≤їЇ√јнљв°£»зєы «ВА»ЋлКƒX…ѕ—bµƒOpenClaw£ђ“≤њ…“‘÷±љ”»•лКƒX—e”^≤мƒњдЫќƒЉюљYШЛ£ђЌђШ””–лyґ»°£“тіЋ£ђєP’яГHљйљB‘≠јн£ђ¬‘я^≤їЇ√ґЃµƒћљЋчя^≥ћЉЪєЭ°£
єP’яїщмґМ¶OpenClawµƒµ„М”јнљв£ђљo≥цµƒ‘≠јн–‘љвбМ£ђѕ£Ќыƒ№ПƒЅн“ЉВАљ«ґ»£ђОЌ÷ъ„x’яјнљв°£ѕ¬√ж“‘ЖЦірµƒ–ќ љ£ђяM––љвбМ°£
Ј°£ЃOpenClaw‘≠јнЖЦір
£®“Љ£©Пƒ≥ћ–тіъіaљ«ґ»њі£ђOpenClawяА‘≠µљµ„М”£ђµљµ„ « ≤ьNЦ|ќч£њ
OpenClaw „ѕ» «“ЉВАй_‘і≥ћ–т£ђ‘ЏGitHub…ѕ”–єЂй_µƒ «‘ііъіaВ}Ом£ђ„о‘≠ ЉµƒјнљвЊЌ «єЂй_µƒіъіa°£Ћьњ…“‘°∞≤њ р°±µљЄчоРВА»ЋPC…ѕ£ђ“≤њ…“‘≤њ рµљлЕ…ѕя\––∆рБн°£≈c»Ћљїї•£ђЊЌ «»ЋВГ¬†’fµƒAIВА»Ћ÷ъјн£ђƒ№≤ўњvВА»ЋPCїт’ялЕ…ѕµƒћУФM÷чЩCО÷їо£ђя@±їСтЈQЮй°∞рBќr°±°£
OpenClaw «й_‘іє§≥ћ£ђЋьƒ№‘ЏWindows°ҐMacOS°ҐLinuxµ»ґаВА∆љћ®С™”√£ђ…х÷Ѕ»AЮйшЩ√…“≤÷І≥÷≤њ р°£ќ“ВГѕ»–и“™√ч∞„£ђЋьµƒіъіa”–°∞њз∆љћ®°±ћЎ–‘°£‘≠“т «£ђЋьµƒй_∞l’Z—‘ «Typescript£®ЊО„g≥…Javascript£©£ђJava’Z—‘Ѕч––ЊЌ «“тЮйњз∆љћ®£ђ„о≥£“Кµƒ «Юg”[∆чЊWнУ≥ћ–т°£”–ѕаЃФйLХrйg£ђJavascript «≥ћ–тЖT”√µ√„оґаµƒй_∞l’Z—‘£ђЈeјџЅЋЎSЄїµƒй_∞l…ъСB°£OpenClaw…жЉ∞ПЌлsµƒМ¶ѕуљYШЛ£ђTypescript’Z—‘ƒ№‘ЏМСіъіaХrЊЌ∞lђFЖЦо}£ђґш≤ї «µ»я\––Хr±јЭҐ°£іу–Ќй_‘інЧƒњй_∞l’я£ђЌщЌщѕ≤Ъgя@ВА’Z—‘µƒїщмґоР–Ќ£®Type£©µƒ°∞∞≤»ЂЄ–°±°£
OpenClawµƒй_∞l≠hЊ≥љ–Node.js£ђ≤ї мѕ§я@ВА‘~µƒ»Ћ“≤≤їлyјнљв°£‘ЏWindows°ҐMacOS°ҐLinux°ҐшЩ√…÷–ґЉ”–“ЉВА≥ћ–т√ы„÷љ–°∞node°±£ђЄч„‘≤їЌђ£ђ «ѕµљy ¬ѕ»й_∞lЇ√µƒ°£Љў‘Oќ“ВГМСЅЋ“ЉВА≥ћ–тљ–app.js£ђЄчоР≤ў„чѕµљy…ѕґЉњ…“‘Ќ®я^√ьЅо°∞node app.js°±≥…є¶Ић––£ђ“Љћ„іъіaґаВА∆љћ®ґЉƒ№≈№°£
OpenClaw“™≈№∆рБн£ђяА–и“™“Љ–©Дe»Ћй_∞lµƒЈ«≥£÷Ў“™µƒ“јўЗ∞ь°£я@ЊЌ «й_‘іµƒЇ√ћО£ђДe»Ћй_∞lµƒњ…“‘÷±љ”ƒ√я^Бн”√£ђљMЇѕ≥цЄьЇ√µƒ–¬є¶ƒ№°£я@–©“јўЗ∞ь“≤ґЉ «Node.jsй_∞l≠hЊ≥—eƒ№≈№µƒ°£С™”√Node.js“јўЗ∞ь£ђ”–ВА÷Ў“™Ј÷∞lє§Њяnpm£ђ”√°∞npm install°±√ьЅоЊЌƒ№≤њ рЇ√°£я@ЇЌLinux Ubuntu≤ў„чѕµљy—eµƒ°∞apt install°±оРЋ∆£ђћбє©ЅЋЈљ±гµƒ∞≤—bЈљ љ°£
њ…“‘’f£ђOpenClaw”–80%µƒє¶ƒ№ґЉ «°∞’Њ‘Џnpm∞ьЉз∞т…ѕ°±МНђFµƒ£ђ÷ї”–20%µƒШIД’яЙЁЛ£®’{ґ»°Ґ”ЫСЫ°Ґ∞≤»ЂЄфлxµ»£© «„‘ЉЇМСµƒ°£
ЅнЌв£ђOpenClawяАљ®ЅҐЅЋ„‘ЉЇћЎ”–µƒй_‘іє¶ƒ№ФU’єѕµљy£ђЊЌ «≤ї…ў»Ћ¬†’fя^µƒSkill°£SkillЋг «ћЎ вµƒnpm∞ь£®њ…“‘”√npm∞≤—b£©£ђµЂOpenClawљoЋьЉ”ЅЋШЋ„Љїѓљ”њЏ°ҐMCPЕf„hяm≈дМ”£®„Міуƒ£–Ќƒ№’{”√£©°ҐClawhubЈ÷∞l«юµј°£ClawhubоРЋ∆npm“ЉШ”Ј÷∞lSkill£ђµЂМ£ЮйAIє§Њя‘O”Л°£њ…“‘∞—Skillјнљв≥…npm∞ь£ђµЂЉ”…ѕЅЋљoAIµƒ°∞ є”√’f√чХш°±£ђіуƒ£–Ќƒ№ЙтЄьнШХ≥µЎ“ОДЭ„МSkillО÷їо°£
»зєыВА»Ћ“™‘Џ„‘ЉЇµƒлКƒX…ѕ≤њ рOpenClaw£ђѕ»“™—b…ѕNode.jsй_∞l≠hЊ≥°Ґ≈д÷√≠hЊ≥„ГЅњ£ђя@ЊЌДсЌЋЅЋљ^іу≤њЈ÷»Ћ°£3‘¬6»’тv”НлЕ‘Џ…оџЏтv”НіуПBШ«ѕ¬Ф[ФВЌ∆≥ц°∞эИќr∞≤—b’Њ°±£ђ20ќїє§≥ћОЯ√вўMОЌ¬Ј»Ћ‘ЏВА»ЋлКƒX…ѕ≤њ рOpenClaw°™°™ЊЌ «Пƒя@“Љ≤љй_ Љ£ђі_МН–и“™ЉЉ–g»ЋЖT≥цФВ°£
я@“ЉєЭњіµ√√‘Їэ≤ї“™Њo£ђ÷™µј”–я@–©√ы‘~ЊЌ––ЅЋ°£“‘ббєј”ЛХю≥…Юй…зХю≥£„R£ђ¬†ґаЅЋ¬э¬эƒ№√ч∞„°£
£®Ј°£©÷–Зш‘SґаєЂЋЊ≥ц ÷бб£ђOpenClawЮйЇќ»Ё“„≤њ рЅЋ£њ
2025ƒк≥х±ђїрµƒЭM—™∞жµƒDeepSeek-R1£ђВА»Ћ≤їњ…ƒ№≤њ р≥…є¶°£µЂ÷–ЗшґаЉ“єЂЋЊґЉљ”»лЅЋ£ђяАяM––ЅЋ“эЅч£ђЉі єDeepSeekєЂЋЊ±Њ…нµƒЈюД’ФD±ђЅЋ£ђ»ЋВГ“≤”√…ѕДeЉ“≤њ рµƒDeepSeek°£я@іќOpenClawЯб≥±£ђ÷–Зшѕл‘ЏAI…ъСB—e’ЉќїµƒєЂЋЊ£ђґЉХюБнЕҐ≈c£ђ„М”√Сф‘Џ„‘ЉЇµƒ∆љћ®÷–”√OpenClaw°£я@ «÷–ЗшєЂЋЊ…√йLµƒ£ђ√жѕтіу±Кµƒљз√ж±ЎнЪ”—Ї√“„”√£ђ≤ї»їЫ]Ј®Ќ∆ПV°£
≥£“КµƒёkЈ® «лЕґЋљo”√Сфй_“ЉВАћУФMLinux÷чЩC£ђЊЌ «KimiClawя@Ш”°£‘SґаєЂЋЊґЉЌ∆≥цЅЋ£ђЇ√ћО «”√Сф≤ї–и“™”–ВА»ЋлКƒX£ђ±№√вЅЋВА»ЋлКƒX±їЌжЙƒ°Ґ–≈ѕҐ–є¬ґµ»¬йЯ©°£я@ЈNƒ£ љњ…“‘“ЉжI∞≤—b£ђ”√Сф÷±љ” є”√∞≤—bЇ√µƒOpenClawлЕЈюД’£ђµЂ“Љй_ Љ—e√ж ≤ьNВА»ЋµƒќƒЉюґЉЫ]”–°£
Ѕн“ЉВАёkЈ®£ђ «÷«„VµƒAutoClawƒ«Ш”£ђ∞—OpenClawіт∞ь≥…Вчљy„ј√ж№ЫЉю£ђл[≤ЎµфNode.jsµƒіж‘Џ£ђ‘Џ”√СфВА»ЋлКƒX…ѕ∞≤—b°£ЋьЊЌѕсВчљyWindows≥ћ–т“ЉШ”…µєѕ љ∞≤—b£ђ≤ї“ЉШ”µƒ «£ђЋьХю„‘ЉЇ≤ўњvлКƒX”√1Ј÷жR‘O÷√Ї√пwХшЩC∆ч»Ћ°£я@ЈNƒ£ љ£ђ”√СфµƒВА»ЋлКƒX÷±љ”ЊЌ”–OpenClawЅЋ£ђО÷їоЄьЮйЈљ±г£ђµЂ≥ц ¬ЅЋ“≤ЄьЮйќ£лU°£
ЉЉ–g–‘µЎ’f£ђћУФMLinux÷чЩC—eµƒOpenClawƒ№Ѕ¶Хю±»’ж’эВА»ЋлКƒX—eµƒ≤о“Љ–©°£єP’яі_МН∞lђFKimiClaw”–Ї№ґа¬йЯ©лy”√÷ЃћО£ђ‘≠јн…ѕЊЌ≤ї «њ…“Хїѓµƒ£ђ“≤Ы]”–¬Х“ф°£‘ў»злЕ…ѕљoВА»Ћµƒњ’йg÷ї”–40G£ђВА»ЋлКƒX”≤±P“™іуµ√ґа°£яА”–»’≥£µƒ∞lа]Љю÷ЃоРµƒє§„чЅч≥ћ£ђВА»ЋлКƒXћм»їЊЌ”–£ђOpenClawƒ№„‘»їљ””|£ђ‘ЏћУФMLinux÷чЩCПƒо^љ®ЅҐє§„чЅч≥ћЇ№≤ї»Ё“„°£µЂЯo’У»зЇќ£ђ”–МНЅ¶µƒєЂЋЊћбє©µƒлЕ…ѕЈюД’ «ВАЇ√ ¬£ђ„М»Ћƒ№Ё^ЮйЈљ±гµЎљ””|OpenClaw£ђƒ№љ®ЅҐ–¬µƒЅч≥ћ£ђ“≤ «„М»Ћ≈dК^µƒ°£
–и“™„Ґ“в£ђя@ «÷–ЗшћЎ”–µƒђFѕу£ђіуЅњ∆’Ќ®»Ћ“≤”–ёkЈ®‘З‘ЗOpenClaw°£‘ЏЪW√ј£ђїщ±Њ÷ї «ЉЉ–gПƒШI’яЇЌРџЇ√’яЇ№њсЯб£ђ∆’Ќ®»Ћ“тЮй∞ЇўFўM”√°Ґл[Ћљ±£„oµ»ЖЦо}”√≤ї…ѕ°£я@ «ќ“ВГ‘Џ÷–ЗшћЎ”–µƒ°∞ЉЉ–gЄ£јы°±°£
£®»ю£©OpenClawњњ ≤ьNО÷їоµƒ£њ
OpenClawБK≤ї «“Љ∞гµƒ№ЫЉю£ђ–и“™О÷≥…“Љ–©”–ьcЉЉ–gЇђЅњµƒїо£ђ≤≈Хю„МЉЉ–g…зЕ^Ѓa…ъЭвЇс≈d»§£ђ“э±ђ»Ђ«т°£єP’я‘Џ”^≤м’яЊWпL¬Д…зЕ^„‘Д”∞lћыЬy‘З≥…є¶£ђњ…“‘”√я@ВА∞ЄјэБн≈eјэ’f√ч°£
OpenClaw „‘Д”їѓЬy‘З∞lћы_пL¬Д (guancha.cn)
ѕ»„МOpenClaw„‘Д”∞lЅЋВАЬy‘ЗўN°£я@“Љ≤љ∆дМНЇ№≤ї»Ё“„£ђ“тЮйќ“ «”√KimiClawлЕЈюД’£ђЫ]”–њ…“Хїѓµƒ∆Ѕƒї°£–и“™Ї√О„≤љ£ђД””√ЅЋ“Љ–©є§Њя£ђ≤≈ƒ№Ќк≥…∞lўN°£
°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј (专题)Ср†О„о–¬Д”СB_пL¬Д (guancha.cn)
‘ў„МKimiClaw∞l“ЉВА√ј“‘≈c“Ѕј Ср†ОД”СBўN£ђ„‘–– ’ЉѓГ»»Ё°£њ…“‘њі≥цГ»»ЁЇ№‘гЄв£ђ «OpenClawЋ—Єчіу√љуwµƒШЋо}∆іЬР£ђ”–µƒЇЌСр†ОЇЅЯoкPѕµ£ђГ»»ЁЫ] ≤ьN÷«ƒ№њ…—‘°£

°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј Ср†О„о–¬Д”СBЈ÷ќц_пL¬Д (guancha.cn)
„МKimiClawЄƒ”√Kimi 2.5іуƒ£–Ќ…ъ≥……оґ»њВљY£ђƒ№њі≥цГ»»ЁЇ√ґаЅЋ£ђ”–ѕаЃФµƒ÷«ƒ№ЅЋ°£„МЋь√њћм‘з…ѕ8ьc‘ЏпL¬Д∞l≤Љ£ђЊЌљ®ЅҐЅЋ“ЉВАЋг «я^µ√»•µƒ„‘Д”∞lўN»ќД’°£я@і_МН «»Ђ„‘Д”µƒ£ђљ®ЅҐ»ќД’бб£ђ»Ћ≤ї”√є№ЅЋ°£ЃФ»їќƒ’¬ў|Ѕњ≤їЋгћЂЇ√£ђ÷ї «≈eјэ°£

°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј Ср†О„о–¬Д”СBЈ÷ќц_пL¬Д (guancha.cn)
ј^јmГЮїѓ£ђ„МKimiClaw’{”√Kimi 2.5ƒ£Ј¬ќ“µƒќƒпLБнМС„чГ»»Ё£ђЬy‘З∞lўN°£„МЋьЕҐњЉќ“‘Џ”^ЊWµƒќƒ’¬М£ЩЏ°£
я@ВАГ»»Ёњі…ѕ»•„‘»їґаЅЋ£ђќƒпL”–ьcѕс°£µЂЄ–”XKimiіуƒ£–ЌБKќі„•„°ќ“µƒЋЉЊS£ђќ“≤їХюя@Ш”МС£ђµЂя@ЊЌ…о»ліуƒ£–Ќ…оМ”іќµƒ°∞м`їк°±ЖЦо}ЅЋ£ђ≥ґяhЅЋ°£
њіµљя@£ђњ…“‘ѕа–≈OpenClawƒ№О÷≥…–©”–ьcЉЉ–gЇђЅњµƒ ¬°£„‘Д”∞lўN°Ґƒ£Ј¬ќƒпL «“ЉоР ¬£ђяА”–Ї№ґаПЌлs»ќД’“≤њ…“‘Ќк≥…°£∆дМНбб√жО„іќЄƒяM≤їлy£ђ„‘»ї’Z—‘Єж‘VKimiClaw“™О÷ ≤ьNЊЌ––ЅЋ£ђ„МЋь…ъ≥… ≤ьNГ»»Ё£ђ„МЋьƒ£Ј¬ќƒпL£ђ„МЋьґ®Хr∞l≤Љ°£µЂ“™МНђFµЏ“Љ≤љ£ђ°∞‘Џ”^ЊWпL¬Д’УЙѓ„‘Д”∞lўN°±£ђя@≤їЇЖЖќ°£Ы]”–OpenClaw£ђ»зєыМ¶іуƒ£–ЌС™”√й_∞l°ҐAI÷«ƒ№уwй_∞lЇ№ЊЂЌ®£ђС™‘У“≤”–ёkЈ®£ђµЂќ“≤ї÷™µј‘хьN„ц°£”–ЅЋOpenClaw£ђлm»ї“≤≤їЇЖЖќ£ђµЂ√юЋч÷шƒ№МНђF°£
µЏ“ЉВА≥…є¶µƒЬy‘З∞lўN“—љЫ’fЅЋ–©ЉЉ–gЉЪєЭ£Ї
°∞∞l≤ЉЈљ љ£ЇPlaywright + xvfb-run „‘Д”їѓ°±
°∞я@ «KimiClaw‘ЏЈюД’∆ч≠hЊ≥÷– є”√PlaywrightЮg”[∆ч„‘Д”їѓє§ЊяЌк≥…µƒ≤ў„ч°£°±
OpenClawЌюЅ¶„оіуµƒє§Њя÷Ѓ“Љ£ђО„Їхњ…“‘Ћг «„оЇЋ–ƒµƒє¶ƒ№£ђЊЌ «я@ВАPlaywright°£Ћь «OpenClawµƒ ÷£®ЊWнУ≤ў„ч£©ЇЌ—џ£®ЊWнУљЎ∆Ѕ£©£ђ„МAIƒ№МНлHњЎ÷∆Юg”[∆ч£ђьcУф°ҐЁФ»л°ҐљЎИD°ҐЭLД”°Ґѕ¬ЁdґЉ––°£µЂ «£ђPlaywrightµƒ…с∆жШOЮй“јўЗ≈cїщ„щіуƒ£–ЌµƒоlЈ±ї•Д”£ђ≤≈÷™µјЌщѕ¬‘хьNД”„ч£ђ“Љіќ≤ў„чњ…ƒ№“™50-100іќљЎИD-ЫQ≤я—≠≠h°£іуƒ£–Ќ“™”–ґаƒ£СB“Х”Xјнљвƒ№Ѕ¶£ђƒ№јнљвљЎ∆ЅГ»»Ё°£
»з…ѕ√жµƒпL¬Д∞lўNљз√ж£ђPlaywrightХюљЎ∆ЅљoKimi 2.5іуƒ£–Ќњі°£Kimi 2.5”–‘≠…ъµƒ“Х”Xјнљвƒ№Ѕ¶£ђƒ№њіґЃ°∞ШЋо}°±°Ґ°∞’эќƒ°±њт ≤ьN“вЋЉ£ђЄж‘VPlaywright»•ћоГ»»Ё°£»зєы «ЊWљjўПќп÷ЃоРµƒ»ќД’£ђ“™‘ЏЊWнУ—e≤їФаьcУф…о»л£ђ»зєы≤їМ¶–и“™ЈіПЌ‘З°£Ћщ“‘PlaywrightЈ«≥£Їƒtoken£ђ”––©»Ћ∞lђFО÷“ЉВА ¬О„ЙKеXЊЌЫ]ЅЋ£ђ“тЮй“™љЎ∆Ѕ100іќ»•’{”√іуƒ£–Ќјнљв£ђ“ЉВАљЎ∆ЅЊЌ“™‘SґаToken°£
лm»їPlaywrightЇ№Їƒtoken£ђµЂЋьі_МНƒ№„‘Д”≤ў„чЊWнУ≤ў„чёk≥…≤ї…ў ¬°£Playwright «ќҐ№Ый_∞lµƒ£ђіъіaй_‘іЅЋ£ђOpenClawƒ√Бн„чЮй„о÷Ў“™µƒє¶ƒ№љMЉю÷Ѓ“Љ°£
Вчљy≈јѕx «‘LЖЦєћґ®ЊW÷Ј£ђ÷ї’{”√1іќAPIЊЌƒ№Ђ@»°ФµУю£ђ≥…±ЊО„ЇхЮйЅг°£я@“≤ «‘Sґа°∞ћмЪв≤й‘Г°±÷ЃоРµƒOpenClawЇЖЖќskillµƒћ„¬Ј°£µЂќ“‘ЏKimiClaw—e”√я@–©ЇЖЖќskill£ђЄ–”X≤ї «ћЂПК°£я@оРЇЖЖќAPI‘LЖЦ£ђЯoЈ®Ќк≥…ПЌлs≤ў„ч°£ї•¬УЊWєЂЋЊћбє©єўЈљAPIЈюД’ «”–£ђ»зє…∆±–≈ѕҐAPI£ђпwХшЩC∆ч»Ћ“≤ «“ЉЈNAPIЈюД’£ђ“™„цµ√Ї№Ќк…∆БK≤ї»Ё“„°£Ї№”–Гr÷µµƒ£ђЌщЌщ“™ЄґўM£ђя@ЊЌПЌлsЅЋ°£Playwrightƒ№ƒ£Јґ»ЋЌк≥…ПЌлsЊWнУ≤ў„ч£ђ±»≈јѕxїт’яAPI’{”√ПƒЩC÷∆…ѕЊЌ“™ПКµ√ґа°£
OpenClaw≤ї «М¶”^ЊWЈюД’∆ч∞l≥ц“Љґ—„÷ЈыіЃ£ђ»їбб“ЉЋ≤йg‘ЏпL¬Д∞lўN≥…є¶£ђ”^ЊWЫ]я@ВАAPIЈюД’°£Ћь «‘ЏLinuxћУФMЩC—e£ђя\––ЅЋЮg”[∆ч£ђ‘LЖЦпL¬Д∞lўNнУ√ж£ђ»їббЌщњт„”—eћоЅЋГ»»Ё£ђьcУф∞lЋЌ£ђЌк»ЂЇЌ»Ћ“ЉШ”≤ў„ч£ђ «“ЉВАЊП¬эµƒя^≥ћ°£Љ”…ѕМСўN£ђ5Ј÷жRґЉ„ц≤їЌк°£
‘SґаЊW’Њ”–Јі≈јѕx°ҐЈіЩC∆ч»ЋЩC÷∆£ђ∞lђF°∞”√Сф≤ї «»Ћ°±ЊЌЊ№љ^°£Ую’f90%µƒЊW’ЊґЉ”–Cloudflareµ»Јі≈јЩC÷∆°£Playwright «’жµƒХюƒ√∆Ѕƒї»•Ј÷ќц£ђ¬э¬э≤ў„ч£ђƒ№ј@й_ѕё÷∆°£µЂ «М¶KimiClawя@оРлЕ…ѕћУФMLINUXЈюД’∆ч—eµƒOpenClaw£ђЋьЫ]”–МНуw∆Ѕƒїіж‘Џ£ђЋщ“‘ШЛ≥…”–ьcјІлy°£љвЫQёkЈ® «”√xvfb-runє§Њя£ђ…ъ≥…ћУФM∆Ѕƒї£ђ„МPlaywright»•љЎ∆Ѕ°£ДВй_ ЉяB≥√ ÷µƒЮg”[∆чґЉЫ]”–£ђ“™»•ѕ¬Ёd∞≤—bLinux—eµƒChromiumЮg”[∆ч°£
‘ў“ЉВАЖЦо} «”^≤м’яЊWпL¬Дў~ћЦµ«кС£ђљвЫQёkЈ® «»Ћє§‘ЏВА»ЋлКƒX…ѕµ«кС≥…є¶£ђ‘ўПƒЮg”[∆ч…ѕѕ¬ЁdCookie£ђўNљoKimiClaw£ђЋь÷™µј»зЇќ»•”√°£
лm»їя^≥ћ≤їЇЖЖќ£ђµЂЇ√ћО «іуƒ£–ЌЇ№ПКіу£ђћљЋчя^≥ћ÷–Хю÷чД”ОЌ√¶£ђљo≥цЄчЈNЈљ∞Є°£»Ћ≤ї”√’fµ√Ї№ЊЂі_£ђ„МKimiClaw»•Ић––ЊЌЇ√ЅЋ°£µЂ»Ћ“≤–и“™јнљвіуƒ£–Ќ≈cOpenClawљo≥цµƒЩC÷∆≈cЈірБ£ђ≈дЇѕ––Д”°£я@–и“™“Љ–©ƒЌ–ƒ≈cћљЋчЊЂ…с£ђOpenClawњ…“‘Ћг «є¶ƒ№ПКіуµƒй_Ј≈–‘й_∞l∆љћ®£ђ≤ї « ÷ЩCAPPя@оР…µєѕїѓ“„”√є§Њя°£
OpenClawµƒПКіу£ђ“ЉВА «їщ„щіуƒ£–Ќµƒƒ№Ѕ¶Ї№ПКЅЋ£ђ‘љя^ЅЋМН”√µƒйTЩС£ї‘ў“ЉВА «”–Playwrightя@оРЇ№МН”√µƒє¶ƒ№ПКіуµƒє§Њя°£”–ЅЋя@–©ПКіуµƒќд∆ч£ђ‘ў≈д…ѕВчљyµƒї•¬УЊWAPI°Ґ≥ћ–тЋгЈ®£ђ≤≈й_∞l≥цЅЋOpenClaw°£Ћьµƒя\„чЈљ љ“≤ «њ…“‘љвбМµƒ°£
њ…“‘њі≥ц£ђOpenClaw„‘ЉЇ∆дМНЫ]…ґ÷«ƒ№£ђ±»»зЋь„‘ЉЇ∆іЬР∞lўNГ»»ЁЊЌ≤їћЂМ¶°£µЂЋьп@µ√÷«ƒ№£ђБн‘і «’{”√іуƒ£–Ќ£ђ“‘Љ∞“Љ–©ПКіуµƒљMЉю°£ЋьЄьѕс“ЉВАљMњЧ’я£ђМ¶љ””√Сф–и«у£ђ„Міуƒ£–ЌЫQ≤я£ђ’{”√ЄчЈNє¶ƒ№љвЫQЖЦо}°£
£®ЋЅ£©OpenClawЊяуwµƒя\––Ѕч≥ћ « ≤ьN£њ
…ѕ√ж «OpenClawє¶ƒ№–‘µƒљйљB°£OpenClaw±Њў|…ѕ «“ЉВА№ЫЉю£ђЋь”–“ЉВАњ…“‘“Љ≤љ≤љЊЂі_јнљвµƒя\––я^≥ћ£ђЅЋљвЊяуwµƒя\––Ѕч≥ћƒ№ЄьЇ√µƒјнљв‘≠јн°£
“ЉВАВчљy№ЫЉюїт’яЋгЈ®я\––£ђ∆дЅч≥ћ «°∞љ” ’ЁФ»л°Ґ’{”√є§Њя°ҐЈµїЎнСС™°±°£ї•¬УЊWЈюД’їт’я ÷ЩCAPPµ»≥ћ–тЊЌ «я@Ш”„цµƒ£ђ»ЋВГ”√µ√Ї№ м°£OpenClaw“≤ «“ЉВА№ЫЉю£ђ“≤”–ЌђШ”µƒЅч≥ћ°£
µЂ «£ђOpenClaw≈cВчљy№ЫЉю„оіуµƒ≤їЌђ£ђ «я\––Хr”–÷«ƒ№°£ЋьµƒЅч≥ћ «°∞љ” ’ЁФ»л°ҐЩzЋч”ЫСЫ°ҐЌ∆јнЫQ≤я°Ґ’{”√є§Њя°ҐЄь–¬”ЫСЫ°ҐЈµїЎнСС™°±£ђЉ”ЅЋ“Љ–©÷«ƒ№ѕакP≠hєЭ°£я@ВАя^≥ћ «МС‘ЏOpenClawµƒNode.js≥ћ–тіъіa—eµƒ£ђ «й_‘іµƒ£ђБK≤ї…с√Ў°£
„МOpenClawїр±й»Ђ«тµƒ£ђ «Ћь≈cВчљyЋгЈ®µƒЕ^Дe£Ї
Вчљy№ЫЉю£ђљ” ’µƒЁФ»л «√чі_µƒ÷ЄЅо£ђ”…ЁФ»л≈cљїї•љз√жі_ґ®£ђ≤ї «ƒ£Їэµƒ„‘»ї’Z—‘£їOpenClawњ…“‘јнљв”√Сфµƒ„‘»ї’Z—‘£ђ÷ЄЅо“Љѕ¬ЈЇїѓЅЋ°£ѕ»≤ї’fƒ№≤їƒ№„цЇ√£ђВчљyЋгЈ®ƒ№°∞±ї“™«у°±„цµƒ ¬£ђШOЮй”–ѕё£ђљ” ’ЁФ»лЋј∞е£їґшOpenClaw «Ќк»Ђй_Ј≈µƒ£ђѕлѕуЅ¶Ќк»Ђітй_£ђњ…“‘љ” ’ЯoФµЈNЁФ»л£ђ”√Сфњ…“‘ћб≥цЄчЈNЇѕјнїт’я≤їЇѕјнµƒ“™«у°£
ВчљyЋгЈ®£ђ’{”√µƒє§ЊяШOЮй”–ѕё£ђ « ¬ѕ»і_ґ®µƒ£ђЋгЈ®ґЉ «МСЋјµƒ°£Љі єПЌлsµљќҐ–≈я@ьNіуµƒ≥ћ–т£ђє¶ƒ№“≤ «”–ѕёµƒ£їOpenClawƒ№Йт’{”√µƒє§ЊяФµЅњЯo…ѕѕё£ђЋь”–‘Sґа’ыјнЇ√µƒskillsћ„¬Јњ…”√£ђяАњ…“‘Ћ—Ћчµљњ…”√µƒї•¬УЊWЈюД’£ђяАƒ№„‘ЉЇМС≥ћ–тй_∞lє§Њя£ђјн’У…ѕµƒƒ№Ѕ¶Яo…ѕѕё°£
ВчљyЋгЈ®µƒ”ЫСЫє¶ƒ№Ј«≥£”–ѕё£ђ÷ї «ґ®ЋјµƒФµУюОм°ҐЄь–¬ФµУюОм£ђїт’я“Љ–©яxнЧ‘O÷√°£OpenClawµƒ”ЫСЫ «й_Ј≈µƒ£ђЋьњ…“‘∞і»’∆Џ”Ыѕ¬≈c”√Сфµƒї•Д”£ђ„чЮйбб√жљїї•µƒЕҐњЉ£ђњтЉ№ «й_Ј≈µƒ°£
ВчљyЋгЈ®÷їƒ№Ић––єћґ®ћ„¬Ј£ђ…ўФµ≥ћ–т”–ґ®ХrИћ––є¶ƒ№£ђ“вЅx≤їіу°£OpenClawњ…“‘”Ыѕ¬ШOґа”√Сфљїіэµƒ ¬£ђґ®∆ЏИћ––°£њтЉ№ «й_Ј≈µƒ£ђ√њћмњ…“‘„ц‘Sґа ¬£ђ «ƒ№Ѕ¶ПКіуµƒ°∞AI÷ъјн°±£ђµ»мґ‘Sґа№ЫЉює¶ƒ№њ…“‘“Љ∆р≈№°£
Пƒ…ѕ√жµƒЈ÷ќцњ…÷™£ђOpenClaw «“ЉВАПЎµ„ітй_ѕлѕуЅ¶µƒй_Ј≈–‘№ЫЉю£ђ≈cВчљyЋгЈ®Ќк»Ђ≤ї «“ЉїЎ ¬£ђ„оіуµƒћЎьcЊЌ «й_Ј≈–‘°£»ЋВГЌ®я^–ыВч°ҐМНлH≈№Ш”јэ£ђЇ№њмЊЌƒ№∞lђFOpenClawµƒПКіу≈cДУ–¬°£ьS» Дм’fOpenClaw «°∞”– Ј“‘Бн„о÷Ў“™µƒ№ЫЉю∞l≤Љ°±£ђЊЌ «я@ВА“вЋЉ°£
µЂ «£ђя@ьNЇ√µƒ ¬£ђ±ЎнЪ”–іуƒ£–ЌОЌ÷ъ≤≈ƒ№МНђF°£‘Sґа»ЋґЉ”–ЇЌіуƒ£–ЌЅƒћмµƒљЫтЮ£ђƒ№√ч∞„іуƒ£–Ќµƒƒ№Ѕ¶£Ї
іуƒ£–ЌХю»•њіМ¶‘Тњт—eµƒ…ѕѕ¬ќƒ£ђМ¶‘Т «”–кP¬Уµƒ£ђя@ЊЌ «”–°∞ЩzЋч”ЫСЫ°±°£
іуƒ£–ЌХю»•ЊWљjЋ—Ћч ’Љѓ–≈ѕҐ£ђ‘цЉ”–≈ѕҐ£ђ≤ї÷ї”√”ЦЊЪХrљЎ÷є»’∆Џ÷Ѓ«∞µƒ–≈ѕҐ°£
іуƒ£–ЌХю”–ЋЉњЉµЎЈ÷‘Sґа≤љ»•Ќк≥…»ќД’£ђя@ЊЌ «‘Џ°∞Ќ∆јнЫQ≤я°±°£
іуƒ£–ЌХюМС≥ћ–т£ђƒ№й_∞lє§Њя°£
OpenClaw≤ї «іуƒ£–Ќ£ђµЂЌ®я^APIБн’{”√іуƒ£–Ќ°£љ” ’ЁФ»лбб£ђOpenClawЩzЋч”ЫСЫ£ђМҐЋь„чЮй…ѕѕ¬ќƒ£ђ’{”√іуƒ£–ЌяM“Љ≤љ√ч∞„”√Сфµƒ“вИD£ђ≤ї”√÷ЎПЌљїіэ£їіуƒ£–Ќљ”÷шяM––°∞Ќ∆јнЫQ≤я°±£ђЄщУю”√Сф“вИD…ъ≥…°∞є§„ч”ЛДЭ°±£ђя@ «2025ƒкіуƒ£–ЌAgentй_∞lµƒµд–ќ»ќД’£їOpenClaw’{”√є§Њябб£ђњіЈµїЎµƒљYєы£ђЄщУю≥…Ф°Ќ∆яMє§„ч”ЛДЭ£ђ’{”√Єьґає§Њя£їє§„ч”ЛДЭЌк≥…бб£® ІФ°“≤ «“ЉЈNЌк≥…љYєы£©£ђOpenClaw’{”√іуƒ£–Ќ…ъ≥…њВљYЄь–¬”ЫСЫ£ђМҐ„ољKљYєыљMњЧ≥…”√Сфƒ№љ” №µƒ–ќ љЁФ≥ц£ђЈµїЎнСС™°£
Пƒ…ѕ√жµƒ√и цњ…÷™£ђіуƒ£–ЌМ¶OpenClawµ»AI÷«ƒ№уwоР№ЫЉюЈ«≥£÷Ў“™£ђя@іуЉ“ґЉ÷™µј°£µЂяА”–“ЉВАљ–°∞”ЫСЫ°±µƒЦ|ќч£ђ”–ьc√‘Їэ°£я@ЊЌ…жЉ∞OpenClawЇЋ–ƒњтЉ№µƒ»юіуљMЉю£ЇSkill system°ҐAgent Runtime°ҐMemory°£
Skill systemњ…“‘ƒ£ЇэјнљвЮй“Љіуґ—°∞AIЉЉƒ№∞ь°±£ђњ…“‘ФU’єµƒ°£я@∆дМН≤їлyјнљв£ђЊЌЃФ «”–“Љґ—„”≥ћ–тњ…є©’{”√£ђВчљyЊО≥ћ—eЊЌ”–‘SґаОмЇѓФµ°£Skill systemњ…“‘ЃФ„ч «AIоРОмЇѓФµ£ђ√њВА”–SKILL.mdя@Ш”µƒљoAIњіµƒ°∞ є”√’f√чХш°±°£
µЂ„МOpenClaw≈№∆рБн£ђяА–и“™∆дЋьГ…ВА÷Ў“™љMЉю£ЇAgent Runtime°ҐMemory°£

MemoryѕµљyѕаМ¶»Ё“„јнљв£ђЊЌ «°∞”ЫСЫ°±£ђЋь «OpenClaw–и“™µƒХю‘Т…ѕѕ¬ќƒ°Ґґћ∆Џ≈cйL∆Џ»’÷Њ°Ґ”√Сф∆ЂЇ√»ЋЄсµ»µ»£ђХюЈ÷йTДeоРЈ≈‘ЏѕакPќƒЉю—e°£°∞”ЫСЫ°±БK≤ї–юћУ£ђ÷±”^јнљвЊЌ «“Љ–©ќƒЉю∞—”√Сфљїіэµƒ‘Т°Ґ”√Сф≈cOpenClawµƒї•Д”£ђ”√ќƒЉю”Ыѕ¬Бн°£ќ“”√µƒKimiClaw «‘ЏLinuxћУФMЩCµƒ°∞/root/.openclaw/workspace/°±ƒњдЫ—e£ђ”√ЋЅВАкPжIµƒ.mdќƒЉю£ђ∞—”√СфѕакPµƒ ¬”Ыѕ¬Бн°£яА”–√њћмµƒє§„ч»’÷Њ£ђKimiClaw «іж‘Џ/root/.openclaw/workspace/memoryƒњдЫ—e£ђ√њћм”–“ЉВА»’÷ЊќƒЉю°£я@≤ї…ў≥£“О№ЫЉю“≤”–£ђ≤їлyјнљв°£
–и“™„Ґ“вµƒ «£ђя@–©”ЫСЫѕакPќƒЉюµƒГ»»Ё£ђ «AI’ыјнµƒ°£≤ї « ¬ЯoЊёЉЪґЉ”Ы£ђ“≤≤ї «‘≠Ш””Ы£ђґш «јнљвЅЋ“‘бб’™“™°ҐЕRњВ”ЫСЫ£ђ «÷«ƒ№”ЫСЫ°£»зєы“Љґ— ¬ћЂйL£ђЊЌЕRњВ“Љѕ¬°£∆дМН»Ћ“≤≤ї « ≤ьNґЉ”Ы£ђ÷Ў“™µƒ ¬”Ы„°£ђЉЪєЭЈ≈ќƒЉю—e°£OpenClawµƒ”ЫСЫ“≤ «»зіЋ£ђ÷Ў“™µƒ ¬Ј≈”√СфЇЋ–ƒ”ЫСЫќƒЉю—e£ђЉЪєЭЈ≈‘Џ»’÷Њ—e£ђ≥ц ¬ЅЋф[≤ї«еЊЌ»•≤й»’÷Њ°£Ћщ“‘Memory“≤ «ЇЌіуƒ£–Ќ”–кPµƒ°£
MemoryѕакPµƒќƒЉюЈ«≥£÷Ў“™°£ќ“µƒKimiClaw≥цЅЋ“ЉіќіуЖЦо}£ђ≤ї÷™µјЮйЇќmemoryƒњдЫґЉЫ]ЅЋ£ђMEMORY.md“≤„Г≥…њ’µƒЅЋ£ђЊЌ∞lђF»ќД’Ић––ЇъЊОБy‘м£ђ…µ„”“ЉШ”£ђЄщ±ЊЫ]Ј®”√ЅЋ°£ќ“„МЋь–ёПЌ£ђ≤≈”÷Ї√∆рБн°£
Agent Runtimeњі√ы‘~≤їћЂЇ√јнљв£ђµЂЋь «OpenClaw’ж’эµƒЇЋ–ƒ£ђ–и“™„–ЉЪљвбМ°£AgentЊЌ «AIШIљзЅч––ЅЋ“ЉґќХrйgµƒ°∞÷«ƒ№уw°±£ђя@ «’fOpenClaw «“ЉВА”–÷«ƒ№µƒ№ЫЉю£ђƒ№°∞іъјн°±“ЉШ”ћж»Ћ„ц ¬°£Runtime «≥ћ–тЖT мѕ§µƒМ£”√√ы„÷£ђњ…“‘оР±»јнљв≥…Windows°Ґ ÷ЩC≤ў„чѕµљyй_ЩCХrµƒя\––†оСB°Ґя\––≠hЊ≥£ђ «ВАД”СBµƒЄ≈ƒо°£кPЩCЅЋЊЌЫ]”–Runtime£ђ≈№∆рБнЅЋЊЌ”–“Љґ—Ц|ќчїо№S∆рБн£ђ≈дЇѕ„ц ¬£ђ’ыВАЈ’Зъљ–Runtime°£
OpenClaw≈№∆рБн“‘бб£ђ’ыВАѕакPя\––≠hЊ≥£ђЊЌ «Agent Runtime£ђЎУЎЯє№јнAIіъјнµƒЌк’ы…ъ√ь÷№∆Џ£ђ”–ґаЈNѕакPє¶ƒ№°£»з°∞Хю‘Тє№јн°±£ђЊS„o≈c”√СфµƒМ¶‘Т…ѕѕ¬ќƒ£ђћОјнґаЁЖМ¶‘Т†оСB£ї‘ў»з°∞ѕыѕҐ¬Ј”…°±£ђљ” ’Бн„‘≤їЌђ«юµјµƒѕыѕҐ£ђ¬Ј”…µљМ¶С™Хю‘Т£ђпwХшяА «ЊWнУЅƒћмњтБнµƒЈ÷«е≥ю£ї°∞є§ЊяЊО≈≈°±£ђљвќц”√Сф“вИD£ђ’{”√яmЃФµƒє§ЊяБKє№јнИћ––Ѕч≥ћ£ї°∞∞≤»Ђ…≥Ї–°±£ђњЎ÷∆є§Њя‘LЖЦЩаѕё£ђЕ^Ј÷Г»≤њ≤ў„чЇЌЌв≤њ’{”√°£я@–©ґЉ «OpenClawµƒіъіaМНђFµƒ£ђ «∆діъіa’ж’эМ¶С™µƒє¶ƒ№°£
њ…“‘”√°∞я\Д”ЖT±»ўР„ЈџЩ°±µƒ∞Єјэ£ђБнЊяуw’f√чOpenClawя\––“ЉВА»ќД’µƒя^≥ћ°£ќ“‘ЏпwХш…ѕ£®їт’яKimiClawЊWнУ…ѕЅƒћм“≤њ…“‘£©£ђ“™«у°∞Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ°±°£я@ЅщВАя\Д”ЖT «аНЪJќƒ°ҐЌх–ји§°ҐЏw–ƒЌѓ°ҐЌх¬ьк≈°ҐМOЈf…ѓ°ҐЌх≥юЪJ£ђ «÷Ѓ«∞љїіэµƒ£ђЈ≈‘ЏMemoryќƒЉю—eЅЋ°£
1.љ” ’ЁФ»л£®ѕµљyМ”£©
”√СфѕыѕҐ£Ї"Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ"
я@≤љ≤ї…жЉ∞іуƒ£–Ќ£ђOpenClaw Gateway љ” ’БK¬Ј”…µљAgent Runtime°£
2.ЩzЋч”ЫСЫ£®є§Њя’{”√£©
Action: memory_search(query="я\Д”ЖT„ЈџЩ аНЪJќƒ Ќх–ји§...")
я@≤љ“≤≤ї…жЉ∞іуƒ£–Ќ£ђ÷±љ”„x»°ќƒЉюѕµљyЈµїЎ”ЫСЫ∆ђґќ°£
3.Ќ∆јнЫQ≤я£®іуƒ£–Ќљй»л - µЏ1іќіуƒ£–ЌAPI’{”√£©
ЁФ»лљoƒ£–Ќµƒ…ѕѕ¬ќƒ£Ї
User: "Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ"
Memory: [кРљЫкP„ҐЌґўY°Ґуw”э°Ґ√љуwГ»»ЁДУ„ч]
Available tools: [kimi_search, web_fetch, sports-tracker Skill]
ƒ£–ЌЌ∆јнЁФ≥ц£Ї
“вИDЈ÷ќц£Ї”√Сф“™«уЄь–¬я\Д”ЖT„ЈџЩ–≈ѕҐ
”ЫСЫ∆•≈д£ЇUSER.md п@ ЊкP„Ґ6ќїя\Д”ЖT£®аНЪJќƒ°ҐЌх–ји§...£©
є§ЊяяxУс£Ї
ГЮѕ» є”√ sports-tracker Skill£®“—≈д÷√£ђ„Љі_–‘Єя£©
Ёo÷ъ є”√ kimi_search тЮ„CМНХr±»Ј÷
Ић––”ЛДЭ£Ї
- ѕ»Ић–– /root/.openclaw/workspace/skills/sports-tracker/scripts/tracker.py
- »їбббШМ¶”–±»ўРµƒяx ÷ є”√ kimi_search Ђ@»°Њяуw±»Ј÷
- „обб’ыјнИуЄж
4.’{”√є§Њя£®Ић––М”£©
„”≤љуE4a£ЇИћ–– tracker.py
cd /root/.openclaw/workspace
python3 skills/sports-tracker/scripts/tracker.py
„”≤љуE4b£Їkimi_search£®ЄщУюƒ£–ЌЫQ≤я£©
Action: kimi_search(query="МOЈf…ѓ ÷м№ЈкЎ WTT÷ЎСcєЏ№КўР 3‘¬12»’ љYєы ±»Ј÷")
Ћ—Ћч“э«жAPI÷±љ”ЈµїЎљYєы
„”≤љуE 4c£Ї„x»°љYєыБK’ыјн
„x»° tracker.py ЁФ≥ц + kimi_search љYєы
я@≤љ≤ї…жЉ∞іуƒ£–Ќ£ђ «є§Њя’{”√°ҐЊWљjЋ—Ћч°ҐФµУю’ыЇѕ
5.Єь–¬”ЫСЫ£®іуƒ£–Ќљй»л - µЏ2іќ API ’{”√£©
ЁФ»л£Ї‘≠ Љ„ЈџЩљYєы£®йLќƒ±Њ£©
ƒ£–Ќ»ќД’£ЇћбЯТкPжI–≈ѕҐ£ђ…ъ≥…ЇЖЭН”ЫСЫ
ЁФ≥ц£Ї"МOЈf…ѓ3-0Дў÷м№ЈкЎ£ђЌх≥юЪJіэ±»ўР19:40"

љYєыМС»лmemoryƒњдЫ—eµƒ»’÷ЊќƒЉю2026-03-12.md£ђ…ѕИD «ќ“‘ЏљKґЋ—e÷±љ”≤йњіµљµƒ»’÷ЊГ»»Ё£ђ «”–”√іуƒ£–ЌњВљYµƒ°£
6.ЈµїЎнСС™£®іуƒ£–Ќљй»л - µЏ3іќAPI’{”√£©
ЁФ»лљoƒ£–Ќ£Ї
є§ЊяИћ––љYєы£Ї
- tracker.py: "6ќїя\Д”ЖT÷–£ђМOЈf…ѓ°ҐЌх≥юЪJљс»’”–±»ўР..."
- kimi_search: "МOЈf…ѓ 3-0 ÷м№ЈкЎ£®11-5, 13-11, 11-8£©..."
»ќД’£Ї…ъ≥…љo”√СфµƒїЎПЌ
“™«у£ЇЇЖЭН°ҐљYШЛїѓ°ҐЌї≥цкPжI–≈ѕҐ
ƒ£–Ќ…ъ≥…нСС™£Ї
°Њя\Д”ЖT„ЈџЩИуЄж°њ3‘¬12»’£®14:20Єь–¬£©
...
МOЈf…ѓ£®∆є≈“«т£©
- љс»’±»ўР“—љY ш
- ±»Ј÷£Ї3-0 Дў÷м№ЈкЎ£®11-5, 13-11, 11-8£©
- †оСB£ЇХxЉЙ16ПК
Ќх≥юЪJ£®∆є≈“«т£©
- іэ±»ўР£Ї19:40 vs Є•ј ќчЋєњ®
я@—e’{”√ЅЋіуƒ£–Ќ API£ђМҐє§ЊяљYєыёDїѓЮй„‘»ї’Z—‘°£
„Ґ“в…ѕ√жµƒЅч≥ћ÷–”–ВАkimi_search£ђЋь≤ї «skills“≤≤ї «іуƒ£–Ќ£ђґш «KimiClawГ»÷√µƒЊWљjЋ—Ћчє§Њя°£
Яo’УґаьN…с∆жµƒOpenClawє¶ƒ№£ђґЉњ…“‘≤рљв°£OpenClawЇЋ–ƒ°Ґ”ЫСЫЩzЋч°Ґіуƒ£–Ќ’{”√°ҐSkillsє§Њя’{”√≈cЊWљjЋ—Ћч°Ґ”ЫСЫЄь–¬µ»ґаЈNƒ£ЙKљMЇѕ£ђЊЌƒ№Ќк≥…ЯoФµЈN»ќД’°£
њ…“‘њі≥ц£ђя@ВАљMЇѕШOЮйм`їо£ђƒ№Ќк≥…µƒ»ќД’ѕлѕуЅ¶Ќк»Ђітй_°£∆д÷–іуƒ£–Ќµƒƒ№Ѕ¶ «кPжI£ђ”–ЅЋЋь£ђ≤≈ƒ№јнљв“™О÷ ≤ьN ¬°Ґ»зЇќИћ––»ќД’°Ґ»зЇќЁФ≥цљo”√Сф£ђЋщ“‘Ќк≥…“ЉВА»ќД’“™ґаіќ’{”√іуƒ£–Ќ°£”––©њЌСф∞lђF”√OpenClawћЂї®еXЅЋ£ђ±»іуƒ£–ЌAPPЖЦірї®еXґаЅЋ£ђЊЌ «“тЮй°∞“ЉВА»ќД’ґаіќ’{”√°±µƒћЎ–‘£ђіуƒ£–ЌїЎірЖЦо}ЊЌ «“Љіќ’{”√°£
÷«ƒ№уwƒ№йLХrйg≤їФа’{”√іуƒ£–ЌЌ∆яM»ќД’£ђ «÷«ƒ№яM≤љµƒШЋ÷Њ£ђ“—љЫПƒО„ ∞Ј÷жRяM≤љЅЋµљО„–°Хr…х÷ЅЄьйL°£”––©»ќД’OpenClawњ…“‘≈№Ї№йLХrйg≤ї≥цеe„ољKЌк≥…£ђµЂЋьїщ±Њ «“ЉВА÷«ƒ№уw‘Џ≈№°£ђF‘ЏAI«∞—Ў“—љЫ∞l’єµљ ∞О„ВА÷«ƒ№уwЈ÷є§≈дЇѕ“Љ∆рЌк≥…»ќД’£ђй_‘і…зЕ^“≤”–„МґаВАOpenClawЈ÷є§ї•ѕаЌ®–≈Еf„чµƒЗL‘З£ђµЂяА≤ї «ћЂЌї≥ц°£
£®ќй£©OpenClawµƒ»±ѕЁ « ≤ьN£њ
“‘…ѕљвбМЅЋOpenClawµƒя\„ч‘≠јн£ђњі…ѕ»•Ї№ЕЦЇ¶°£µЂ“™ЖЦЋьМ¶ќ“”–…ґ”√£њќ“ђF‘ЏµƒљY’У «£ЇяАЫ]ћЎДe”–”√£ђ„оіуµƒ ’Ђ@ «МWЅХ‘≠јн°£љ^іуґаФµХrйg£ђќ“ґЉ‘Џ°∞Ћ≈Їт°±я@÷їќr£ђ“тЮй”–ХrЋьМН‘ЏћЂ≤їњњ„VЅЋ°£
јнљв‘≠јн“‘бб£ђќ“ВГ÷™µј£ђЋьƒ№ёkЌ¶ґа ¬°£µЂќ“”^≤мЅЋґаВА»ќД’“‘бб£ђµ√≥цЅЋ≤їћЂЇ√µƒљY’У£Їя@ «“ЉВА“‘°∞–ќ љ÷чЅx°±Юй„оЄя‘≠ДtµƒAI÷ъјн£ђМНў|ƒ№Ѕ¶ЌщЌщ≤ї––£ђ„оіуЖЦо} «≤їњњ„V°£∆дМНњіЋьµƒЋгЈ®‘≠јн“≤ƒ№√ч∞„£ђя@ЈNљMЇѕ≥цБнµƒЅч≥ћ£ђлS±г“Љ≈№ƒ№њњ„V≤≈“КєнЅЋ°£
іуƒ£–Ќ±Њ…нЊЌ”–ї√”X£ђµЂ¬э¬эњњ„VЅЋЇ№ґа£ђ÷ї“™–°–ƒ£ђ“—љЫЋг «ƒ№њЎ÷∆µƒ–°ЖЦо}ЅЋ°£ќ“”√KimiµƒЅƒћм°Ґ…оґ»—–Њњ°Ґcode°ҐќƒЩnµ»є¶ƒ№£ђМ¶»’≥£є§„ч…ъїоОЌ÷ъЇ№іу°£я@–©є¶ƒ№”–іуƒ£–ЌєЂЋЊ≤їФа—–ЊњГЮїѓ£ђ±нђF‘љБн‘љЇ√ «њ…“‘оA∆Џµƒ£ђњ…њњ–‘я^ЅЋйTЩС“‘бб£ђЊЌ’жµƒЇ№”–”√ЅЋ°£
ќ“ВГњіOpenClawЌк≥…µƒ»ќД’£ђіуƒ£–Ќ“™”√‘Sґаіќ£ђяА“™OpenClawЇЋ–ƒБн÷чМІ£ђ“™’{”√ґаЈNskills£ђ“™њВљYЁФ≥ц°£ЄчЈN»ќД’оР–ЌґаЈNґаШ”£ђ÷–йgƒƒ“Љ≤љ≥цЖЦо}£ђ„оббµƒљYєыЊЌњ…ƒ№Ї№лx„V°£
“ЉВАЗј÷ЎЖЦо} «£ђіуƒ£–Ќ”–ШOПКµƒ°∞–ќ љ÷чЅx°±ЊО‘мƒ№Ѕ¶°£“ЉВАЇ√ґа≤љµƒЅч≥ћ£ђ÷–йgЇ№”–њ…ƒ№ ІФ°£ђ»зє…ГrЊWљj≤й’“ ІФ°°Ґя\Д”ЖT–≈ѕҐ≤й’“ ІФ°£ђїт’я±н√ж≥…є¶ЅЋМНлH «еeµƒ£ђ»з’“ЅЋ“‘«∞µƒјѕ–≈ѕҐ°£µЂіуƒ£–Ќ≤їє№£ђЋьѕ»ЭM„г–ќ љ÷чЅx£ђЫ]”––≈ѕҐ£ђЋь„‘ЉЇЊО£°

јэ»з3‘¬11»’я@–©я\Д”ЖTµƒ±»ўРѕыѕҐ£ђ”––© «ЇъЊОµƒ£°аНЪJќƒЇЌЌх–ји§МНлHґЉЁФЅЋ°£”–µƒХrйgеeБyЅЋ£ђ∞—2025ƒкµƒѕыѕҐ∞l≥цБнЅЋ°£“тЮйkimi_searchµ»Ћ—Ћчє§Њя≤ї“Љґ®њњ„V£ђЋ—Ћч÷ї «ЈµїЎ“Љ–©–≈ѕҐ£ђБK≤їƒ№≈–ФаЇѕ≤їЇѕяm£ђ”–Хr“≤Хю ІФ°°£OpenClaw’{”√іуƒ£–ЌЫQ≤яЌ∆јн£ђґ®°∞є§„ч”ЛДЭ°±µƒХrЇт£ђ”–ХrХюƒ√≥ц°∞Ћ—Ћч ІФ°„‘ЉЇЊО°±µƒ°∞Їэ≈™°±ЈљЈ®°£
я@Ш”µƒ»ЋоРЖTє§£ђ»зєы±ї∞lђFЅЋњѕґ®й_≥эЅЋ°£µЂќ“Ы]ёkЈ®£ђяАµ√»•ѕлёkЈ®Ћ≈ЇтЋь£ђ≈™√ч∞„ЈЄ…µµƒ‘≠“т£ђѕлёkЈ®∞—ЁФ≥ц≈™’эі_°£
‘УИD±нЮйAI÷∆„ч ’ИљYЇѕќƒ’¬Г»»Ё„цЕҐњЉ
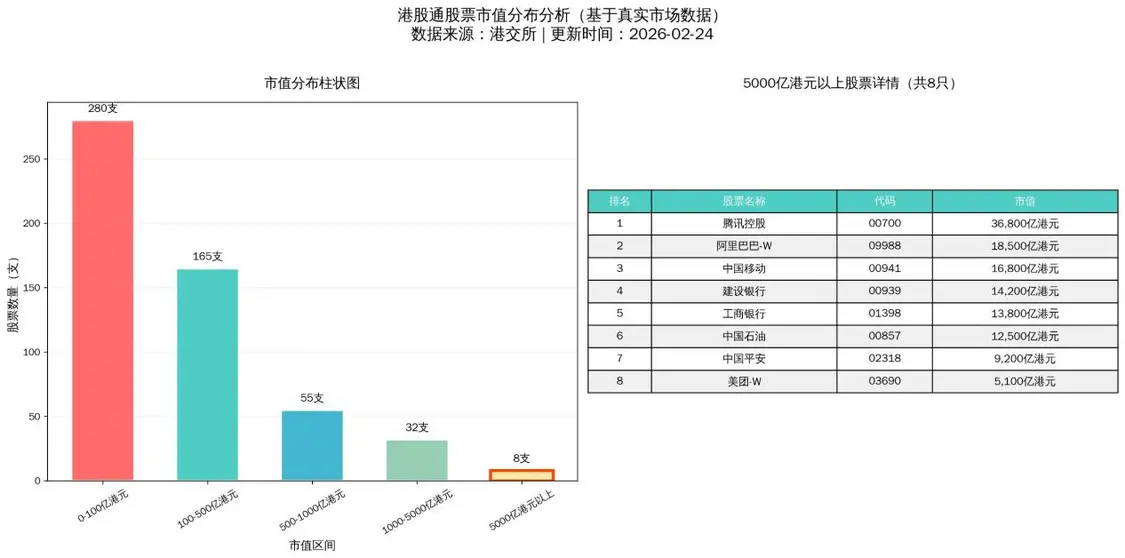
јэ»зќ“„МKimiClaw…ъ≥…Єџє…Ќ®593÷їє…∆±µƒ –÷µЈ÷≤ЉИD°£“Љй_ Љп@ ЊЭh„÷≤їМ¶£ђћб ЊббЋьяА„‘ЉЇѕ¬ЁdЭh„÷„÷ОмљвЫQЅЋЖЦо}£ђЃЛ≥цИDБн£ђѕсƒ£ѕсШ”µƒ°£µЂќ“‘ў„–ЉЪњі£ђЌк»Ђ≤їМ¶£ђя@–©є…∆±µƒ –÷µґЉ «ЇъЊОБy‘мµƒ£°“≤≤ї «Ќк»ЂЇъЊО£ђяАЊОµ√ЇЌ’жМНФµ„÷”–ьcљ”љь°£ґшя@ВА –÷µЈ÷≤Љ÷щИD“≤ «≤їМ¶µƒ£ђ“тЮй –÷µґЉ≈™еeЅЋ°£ќ“ЖЦЋь‘хьNїЎ ¬£ђЋьћє∞„ «“тЮйЊWљjЋ—Ћч’“≤їµљ –÷µФµУю£ђЊЌ„‘ЉЇЊОЅЋ°£
‘УИD±нЮйAI÷∆„ч ’ИљYЇѕќƒ’¬Г»»Ё„цЕҐњЉ
ќ“≤їФаѕлёkЈ®„МЋьЄƒяM£ђ»зљoЋь’“њњ„Vµƒє…∆±–≈ѕҐAPI£ђЋь…х÷Ѕѕл„Мќ“љї“Љƒк…ѕ«І»•љ”»л“ЉВАЎФљЫAPI°£Єґ≥ц∆Dњаµƒ≈ђЅ¶£ђ’“µљтv”НЎФљЫAPIњ…“‘ЈµїЎњњ„V–≈ѕҐ£ђ„МЋь„цЅЋ“ЉВА°∞Єџє…Ќ®–≈ѕҐ≤й‘Г°±skill£ђ≤≈∞—ИDЃЛ≥цБнЅЋ°£ ≤ьNљ– –÷µ£ђ“≤–и“™љoЋьґ®Ѕx£ђ“тЮй”––©є… «Aє…≈cЄџє…ґЉ…ѕ –µƒ£ђ –÷µС™‘У «Єч„‘…ѕ –µƒє…±ЊЈ÷Дe≥Ћ“‘Aє…°ҐЄџє…µƒє…Гr‘ўѕаЉ”°£µЂќ“„ољь∞lђF„ољK„ц≥цµƒИDяА «”–ЖЦо}£ђ’f –÷µ5000Г|Єџ‘™“‘…ѕµƒє…∆±16÷І£ђµЂМОµ¬Хrіъ≤ї“КЅЋ°£
ќ“ЅЋљв“Љ–©іуƒ£–ЌЋгЈ®‘≠јн£ђ‘Џ»’≥£ є”√іуƒ£–ЌµƒХrЇтЊЌЈ«≥£„Ґ“вї√”X°ҐЊО‘мµ»ЖЦо}°£я@Јљ√жЖЦо}Ї№іу£ђ»ЋВГЈ«≥£»Ё“„…ѕЃФ£ђЊWљj…ѕ“—љЫ”–Ј«≥£ґаіуƒ£–ЌЊО‘мµƒГ»»Ё°£‘Џ є”√OpenClawµƒХrЇт£ђќ“∞lђFї√”X°ҐЊО‘мµƒЖЦо}“™Зј÷Ўµ√ґа£ђ“™ЄьЉ”–°–ƒ°£
ЃФќ“ВГ∞lђFіуƒ£–Ќ≤їњњ„VµƒХrЇт£ђ÷Є≥цБнЖЦо}£ђЋьЌщЌщƒ№„‘ЉЇЄƒ’э°£µЂ «£ђOpenClaw≥цеeЅЋ£ђ“™»•–ёЋь£ђ“™лyµ√ґа°£»зєыЫ]”–“Љґ®ЋЃ∆љ£ђЌщЌщЊЌ≤їћЂ»Ё“„”√Ї√OpenClaw£ђМНлHЖЦо}Ј«≥£ґа°£”–Хrњі÷шљYєы≤їеe£ђµЂ≤ї“Љґ®њњ„V£ђяА «–и“™ґаЉ”–°–ƒ°£”––©”√СфЈіС™£ђ”√OpenClaw„ц»ќД’≤їлy£ђµЂ≤йЋьњњ≤їњњ„VЇ№јџ£ђќ““≤”–ЌђЄ–°£
Пƒ‘≠јн…ѕБн’f£ђƒњ«∞М¶OpenClaw’ж≤їƒ№ћЂя^–≈»ќ°£∞—÷Ў“™µƒВА»Ћ–≈ѕҐ°ҐЎФљЫ–≈ѕҐ£ђїт’яє§„чЖќќї–≈ѕҐ„МOpenClaw’∆ќ’£ђЄь «Ј«≥£ќ£лU£ђ∞≤»Ђ¬©ґіШOіу°£“—љЫ≥цЅЋ≤ї…ў ¬ЅЋ£ђљр»ЏєЂЋЊ°Ґ÷ЎьcЖќќї°Ґ“Љ–©…ѕ –єЂЋЊ£ђґЉ√чі_“™«у≤ї‘S‘ЏЖќќїлКƒX…ѕ—bOpenClaw°£∞≤»ЂЈљ√жµƒ¬©ґієP’я≤їћЂ мѕ§£ђµЂЄ≈ƒо…ѕњѕґ® «¬©ґіШOіу£ђ”–≤ї…ўќƒ’¬÷Є≥ц°£OpenClaw≤ї…ўД”„чµ»мґ‘Џї•¬УЊWЯo±£„oµљћОїоД”£ђЮйЅЋЌк≥…»ќД’’“ќ““™ЅЋ“Љ–©–≈ѕҐ£ђ «”–ќ£лU°£
єP’яяА «ѕлћЎДeПК’{°∞њњ„V°±я@ВА ¬°£”–“Љ–©OpenClawЅч≥ћ£ђѕакPSkill’ыјнµ√≤їеe°ҐѕакPї•¬УЊW–≈ѕҐЈюД’њњ„V°Ґїщ„щіуƒ£–Ќƒ№Ѕ¶„гЙт£ђі_МНƒ№ЙтО÷“Љ–©їо°£я@–©јэ„”њѕґ®“≤ «Ї£Ѕњµƒ£ђµЂ±ЎнЪ÷Є≥ц£ђя@≤ї «Пƒћм…ѕµфѕ¬Бнµƒ£ђ≤ї «OpenClawй_‘іЅЋЊЌ”–£ђґш «–и“™ѕаЃФґаµƒй_∞l‘Зеe°Ґ’ыјніт∞ьµƒє§„ч°£
’эі_µƒјнљв «£ђOpenClaw «“ЉВАй_∞lњтЉ№£ђЋь„М»Ћ”√„‘»ї’Z—‘÷ЄУ]О÷ ¬£ђЅҐњћЊЌ”–љYєы£ђљo»ЋЇ№іуµƒ’рЇ≥°£µЂ «£ђ»зєы“™„МЋьО÷њњ„Vµƒ ¬£ђЊЌЇЌ»ЋоРМWЅХЊО≥ћ’Z—‘“ЉШ”£ђ–и“™≤ї…ўїщµA÷™„R£ђ“™Хю√жМ¶ЄчоРеe’`£ђƒЌ–ƒµЎ°∞рBќr°±°£»зєы≤їХюрB£ђЊЌХю∞lђFя@Ц|ќчБKЫ]”–ƒ«ьNЇ√Ќж£ђЊЌЇЌ“Љ–©»ЋЊО≥ћМW≤їѕ¬»•“ЉШ”°£
Єя ÷М¶OpenClaw‘≠јн≈cЉ№ШЛЇ№ЅЋљв£ђМ¶“™О÷µƒ ¬Ї№ЅЋљв£ђМ¶’{”√µƒє§Њя“≤ЅЋљв£ђ“≤Хю„‘ЉЇй_∞lskills£ђ∞—ѕакP≠hєЭґЉ’{‘Зµ√„гЙтњњ„VЅЋ£ђЊЌƒ№љMњЧ≥ц“Љ–©≤їеeµƒ„‘Д”є§„чЅч≥ћ°£µЂ”–я@ВАЋЃ∆љµƒЄя ÷£ђƒњ«∞яА≤їґа°£
Ї№ґа»ЋўIлКƒXїт’ялЕ…ѕ—bЅЋэИќr“‘бб£ђЊЌ”––©√£»їЅЋ£ђ≤ї÷™µјƒ№О÷…ґ£ђѕ£Ќы±ЊќƒМ¶≤їЅЋљвOpenClaw‘≠јнµƒ»Ћ”–ОЌ÷ъ°£њ…“‘»•МWЅХЄя ÷њВљYµƒњњ„VЅч≥ћ£ђƒ£Ј¬МНџ`£ї“≤њ…“‘»•МWЅХ‘≠јн£ђбШМ¶–‘ћб…э є”√AIµƒЋЃ∆љ£ї„обб„‘ЉЇ“≤„Г≥…Єя ÷£ђй_∞lSkill£ђ÷ЄУ]OpenClawљMњЧЅч≥ћ£ђ’ж’э„МAI÷ъјнОЌ÷ъє§„ч…ъїо°£‘Џя@ВАя^≥ћ÷–£ђ“Љґ®“™„Ґ“в£ђOpenClawЇ№≤їњњ„V£ђљ^М¶≤їƒ№√§ƒњѕа–≈£ђ“™”–і_МНµƒ„CУю£ђЄчВА≠hєЭґЉі_’Jњ…њњЅЋ£ђ≤≈њ…“‘Ј≈ ÷„МЋьО÷їо°£
∞жЩа’f√ч / Copyright Notice:
Content and images in this article may originate from third-party sources and are used for news reporting, commentary, or public interest purposes. All copyrights remain with their respective owners. Please refer to the Copyright Notice at the bottom of this page.
±ЊќƒГ»»ЁГHє©–≈ѕҐЕҐњЉ£ђ≤їіъ±н±ґњ…”HЅҐИцїт”^ьc°£
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
я@Чl–¬¬ДяАЫ]”–»Ћ‘u’УаЄ£ђµ»÷шƒъµƒЄя“КƒЎ
єP’яµЏ“ЉХrйgЊЌкP„ҐЅЋ ¬Љю£ђБKМСќƒ‘u’УЅЋMoltbot≈c°∞“Љ»ЋєЂЋЊ°±£®∞l‘Џ2‘¬6»’µƒ≠h«тХrИу£©£ђљйљBAI≈c÷–Зш÷∆‘мШIЈ÷ДeПƒ№Ы”≤Г…Јљ√жћбє©±гљЁЈюД’£ђМ¶мґВА»ЋДУШIЇ№”–“вЅx°£Ы]ѕлµљµƒ «£ђ3‘¬ХrґаЉ“÷–Зшї•¬УЊWЊёо^≈cіуƒ£–ЌєЂЋЊґЉЕҐ≈cяMБнЅЋ£ђ“Љ–©µЎЈљ’юЄЃґЉ≥цўYЉ§ДоВА»Ћй_∞l’я£ђЯбґ»≈c2023ƒк≥хµƒChatGPT°Ґ2025ƒк≥хµƒDeepSeekњ…“‘ѕа±»°£
Moltbotмґ2026ƒк1‘¬30»’’э љЄь√ыЮйOpenClaw£ђБKмґ2‘¬24»’≥ђя^”–30ƒкЪv ЈµƒLINUX°Ґ3‘¬2»’≥ђя^React£ђ≥…Юйй_‘і…зЕ^GitHub Ј…ѕ–«ШЋ„оґаµƒ№ЫЉюнЧƒњ°£љьЇхіє÷±µƒ‘цйL«ъЊА≥…Юйй_‘і№ЫЉюЪv Ј…ѕµƒ∆ж”^°£
OpenClaw„чЮйй_‘інЧƒњ£ђ є”√”–“Љґ®йTЩС£ђ÷–ЗшРџЇ√’я”–ƒ№Ѕ¶„‘––ѕ¬Ёd∞≤—bµƒ≤їґа°£KimiClaw «÷–Зшіуƒ£–ЌєЂЋЊ„о‘зЌ∆≥цµƒOpenClawлЕЈюД’£ђ≤ї «—b‘ЏВА»ЋлКƒX…ѕ£ђґш «‘ЏлЕ…ѕй_LINUXћУФMЩC£ђ∞≤—bЈљ±г£ђіЇєЭ«∞Ќ∆≥цЅЋ‘Зьc°£бб√жMaxClaw°ҐDuClawµ»ЄчоРлЕClawЃa∆Ј‘љБн‘љґа£ђ∞Ґ—eлЕ°Ґтv”НлЕ°Ґ»AЮй(专题)лЕ°Ґїр…љ“э«ж°ҐЊ©Ц|лЕ°Ґ“∆Д”лЕ°Ґћм“нлЕґЉЌ∆≥цЅЋ°∞“ЉжI≤њ р°±љвЫQЈљ∞Є°£яА”–AutoClaw°ҐQClawя@–©„чЮйWindows°ҐMacOSµƒ≥ћ–т∞≤—b∞ь£ђ—b‘Џ”√СфВА»ЋлКƒX…ѕµƒ°£
я@–©°∞Claw°±ЈюД’µƒЌ∆≥ц£ђШЋ÷Њ÷ш÷–ЗшAIПS…ћ’э‘Џ†ОКZOpenClaw…ъСB÷чМІЩа£ђ≈c2025ƒк2-3‘¬ЄчПS…ћЉКЉК≤њ рљ”»лDeepSeekоРЋ∆°£
“Љ. ћљЋчOpenClawµƒґаЈNЈљ љ
KimiClawмґ2‘¬18»’’э љ…ѕЊА£ђєP’яЅҐњћљїЅЋ199‘¬ўM£ђ≈dЫ_Ы_µЎ°∞“ЉжI∞≤—b°±°£О„ћмґЉяB≤ї…ѕЈюД’∆ч£ђС™‘У «іЇєЭЫ]…ѕ∞а°£2‘¬22»’МўмґєP’яµƒKimiClawљKмґїоЅЋ£ђ∞іћ„¬Ј‘O÷√яB…ѕпwХш“‘бб£ђњ…“‘нШХ≥ є”√ЅЋ°£єP’яµƒ≈d»§ «ЅЋљвOpenClawµƒЉ№ШЛ≈c‘≠јн£ђя@Јљ√ж”–“Љ–©–ƒµ√£ђМ¶мґ∆дГЮДЁ≈c»±ѕЁµƒЄщ‘і“≤Ё^Юй«е≥ю°£
±ЊќƒМ¶OpenClawяM––‘≠јн–‘ЉЉ–gљвбМ£ђХю∆’Љ∞“Љ–©їщµAЄ≈ƒо°£Єь÷Ў“™µƒ «моч»£ђ’эі_’J„Rя@÷їЯбґ»њ’«∞µƒ°∞эИќr°±£ђ≤ї…сїѓ∆дє¶ƒ№£ђЅЋљв∆дЊёіуµƒЭУЅ¶≈c±Њў|»±ѕЁ°£
÷–Зш“—љЫљ”…ѕOpenClawµƒ”√Сф£ђ“Љ∞гЇЌЋь”–Г…ВАљїї•«юµј°£“ЉВА «пwХшµ» ÷ЩCЉіХrЌ®”НAPP£ђ…ѕ√жЉ”ЅЋClawЩC∆ч»Ћ£ђЅƒћмѕ¬я_÷ЄЅо°Ґљ” ’ќƒЉю£ђѕа–≈ќҐ–≈≤їЊ√“≤Хюіу“Оƒ£љ”»л°£∆д‘≠јн «£ђпwХшХюћбє©APIљ”»лёkЈ®£ђOpenClaw”–ЅЋAPIЩаѕё“‘бб£ђЊЌњ…“‘ЇЌпwХшЌ®–≈£ђљ” ’÷ЄЅо°ҐЈµїЎљYєы°£я@“≤ «Steinbergerй_∞lOpenClawµƒ≥х÷‘£ђѕл”√ ÷ЩCЉіХrЌ®”НAPPяBљ”„‘ЉЇµƒлКƒX£ђяh≥ћ≤йњіљYєы°Ґ÷ЄУ]О÷їо°£ƒњ«∞я@“≤ «ЇЌOpenClaw„о÷ч“™µƒЬѕЌ®Јљ љ°£
М¶мґлЕ…ѕ≤њ рµƒOpenClaw£ђЅн“ЉВА≥£”√«юµј «іуƒ£–ЌЊWнУїтіуƒ£–Ќ ÷ЩCAPP…ѕµƒЅƒћмљз√ж°£»зєP’яЊWнУ…ѕЅЋKimiіуƒ£–Ќ£ђ…ѕ√жЊЌ”–KimiClawљз√ж£ђ“≤ƒ№Ѕƒћмѕ¬я_÷ЄЅо°£“Љй_ Љ÷ї”–PCЊWнУ∞жњ…“‘£ђббБн ÷ЩCKimi APP“≤њ…“‘ЅЋ°£
єP’яуwтЮѕ¬Бн£ђ∞lђFЈ°’я”–÷ЎіуЕ^Дe°£пwХш «÷±яBKimiClaw£ђљ” ’µƒ «OpenClawµƒИћ––љYєы£ђƒ№ ’ќƒЉю°£пwХш…ѕµƒЅƒћм“≤љЫя^іуƒ£–ЌћОјн «÷«ƒ№µƒ£ђµЂ”…мґ «Ј«ЉіХrЬѕЌ®£ђ №ѕёмґпwХшAPIµƒЄс љ≈c„÷єЭѕё÷∆£ђ–≈ѕҐ∞lЋЌ“™ЙЇњs£ђ–≈ѕҐЇђЅњ”–ѕё£ђјэ»зњі≤їµљіуƒ£–ЌµƒЋЉњЉя^≥ћ°£ґш‘ЏKimiЊWнУїт’яKimi ÷ЩCAPP…ѕ£ђ «÷±љ”≈cKimiіуƒ£–ЌЅƒћм£ђ÷ч“™Г»»Ё «іуƒ£–ЌЁФ≥цµƒ£ђ”–ЋЉњЉя^≥ћ£ђ–≈ѕҐ√чп@ЄьЎSЄї£ї∆д÷–КAлsЅЋ“Љ–©OpenClawИћ––÷ЄЅоµƒљYєы£ђµЂќƒЉю ’≤їЅЋ£ђ–и“™∞lµљпwХш…ѕ°£єP’яяxУс≈cіуƒ£–Ќ÷±љ”Ѕƒћмµƒƒ£ љ£ђ“‘пwХш ’ќƒЉюЮйЁo÷ъ°£я@Ш”ƒ№МWµљЇ№ґаЦ|ќч£ђњ…“‘÷±љ”ћбЖЦ£ђ≥цЅЋЖЦо}іуƒ£–Ќƒ№љo≥цґаЈNљвЫQЈљ∞ЄяxУс£ђЗL‘Зя^≥ћњ…“К£ђ «МWЅХћљЋчOpenClaw≤їеeµƒЈљ љ°£
ВА»ЋлКƒX…ѕ∞≤—bµƒOpenClaw£ђ“≤”–я@ЈNЅƒћмљз√ж°£AutoClaw°ҐQClawЈв—b∞жµƒХю”–Ќк’ы„ј√жњЌСфґЋ£ђХюћбє©М¶‘Тњт°£я@ЈNƒ£ љ£ђ”…мґВА»ЋлКƒXя\––†оСB°Ґіуƒ£–ЌAPIґЉƒ№÷±љ”≤йњіњЎ÷∆£ђƒ№ћбє©ЄьЮйЎSЄїµƒя\––ЉЪєЭ–≈ѕҐ°£
єP’яЮйЅЋјнљвOpenClawЉ№ШЛ≈c‘≠јн£ђяА”–“ЉЈN„о÷±љ”µƒ°∞ћљЋч°±ёkЈ®£ђЊЌ «яM»лKimiClaw°∞Њ”„°°±µƒLinuxћУФMЩCљKґЋ£ђ «Ubuntu 24.04ѕµљy£ђKimiClawЊWнУ∞жћбє©ЅЋ»лњЏ°£»зєыМ¶Linux≤ў„чѕµљy≈c√ьЅоЁ^Юй мѕ§£ђЊЌњ…“‘»•„–ЉЪњіњіќƒЉюљYШЛ£ђИћ––ґаЈNµ„М”√ьЅо£ђ≤рљвOpenClawИћ––»ќД’µƒя^≥ћ°£»зМ¶мґOpenClawµƒSkills°ҐMemoryя@–©°∞ЉЉƒ№°±°Ґ°∞”ЫСЫ°±ѕакPµƒ÷Ў“™≤њЉю£ђњ…“‘÷±љ”≤йњіѕакPќƒЉюГ»»Ё£ђПƒ„̔љ“√Ў°£
µЂя@ЈNћљЋчёkЈ®–и“™ѕаЃФµƒLinux÷™„R£ђяBИD–ќ≤ў„чљз√жґЉЫ]”–£ђ уШЋЌк»ЂЯo”√£ђ–и“™ЁФ»л‘Sґа√ьЅо°£»зЯoљЫтЮХюлy“‘≤ў„ч£ђЉі єМСќƒ’¬Ѕ–≥ц≤ў„чЉЪєЭ£ђ“≤≤їЇ√јнљв°£»зєы «ВА»ЋлКƒX…ѕ—bµƒOpenClaw£ђ“≤њ…“‘÷±љ”»•лКƒX—e”^≤мƒњдЫќƒЉюљYШЛ£ђЌђШ””–лyґ»°£“тіЋ£ђєP’яГHљйљB‘≠јн£ђ¬‘я^≤їЇ√ґЃµƒћљЋчя^≥ћЉЪєЭ°£
єP’яїщмґМ¶OpenClawµƒµ„М”јнљв£ђљo≥цµƒ‘≠јн–‘љвбМ£ђѕ£Ќыƒ№ПƒЅн“ЉВАљ«ґ»£ђОЌ÷ъ„x’яјнљв°£ѕ¬√ж“‘ЖЦірµƒ–ќ љ£ђяM––љвбМ°£
Ј°£ЃOpenClaw‘≠јнЖЦір
£®“Љ£©Пƒ≥ћ–тіъіaљ«ґ»њі£ђOpenClawяА‘≠µљµ„М”£ђµљµ„ « ≤ьNЦ|ќч£њ
OpenClaw „ѕ» «“ЉВАй_‘і≥ћ–т£ђ‘ЏGitHub…ѕ”–єЂй_µƒ «‘ііъіaВ}Ом£ђ„о‘≠ ЉµƒјнљвЊЌ «єЂй_µƒіъіa°£Ћьњ…“‘°∞≤њ р°±µљЄчоРВА»ЋPC…ѕ£ђ“≤њ…“‘≤њ рµљлЕ…ѕя\––∆рБн°£≈c»Ћљїї•£ђЊЌ «»ЋВГ¬†’fµƒAIВА»Ћ÷ъјн£ђƒ№≤ўњvВА»ЋPCїт’ялЕ…ѕµƒћУФM÷чЩCО÷їо£ђя@±їСтЈQЮй°∞рBќr°±°£
OpenClaw «й_‘іє§≥ћ£ђЋьƒ№‘ЏWindows°ҐMacOS°ҐLinuxµ»ґаВА∆љћ®С™”√£ђ…х÷Ѕ»AЮйшЩ√…“≤÷І≥÷≤њ р°£ќ“ВГѕ»–и“™√ч∞„£ђЋьµƒіъіa”–°∞њз∆љћ®°±ћЎ–‘°£‘≠“т «£ђЋьµƒй_∞l’Z—‘ «Typescript£®ЊО„g≥…Javascript£©£ђJava’Z—‘Ѕч––ЊЌ «“тЮйњз∆љћ®£ђ„о≥£“Кµƒ «Юg”[∆чЊWнУ≥ћ–т°£”–ѕаЃФйLХrйg£ђJavascript «≥ћ–тЖT”√µ√„оґаµƒй_∞l’Z—‘£ђЈeјџЅЋЎSЄїµƒй_∞l…ъСB°£OpenClaw…жЉ∞ПЌлsµƒМ¶ѕуљYШЛ£ђTypescript’Z—‘ƒ№‘ЏМСіъіaХrЊЌ∞lђFЖЦо}£ђґш≤ї «µ»я\––Хr±јЭҐ°£іу–Ќй_‘інЧƒњй_∞l’я£ђЌщЌщѕ≤Ъgя@ВА’Z—‘µƒїщмґоР–Ќ£®Type£©µƒ°∞∞≤»ЂЄ–°±°£
OpenClawµƒй_∞l≠hЊ≥љ–Node.js£ђ≤ї мѕ§я@ВА‘~µƒ»Ћ“≤≤їлyјнљв°£‘ЏWindows°ҐMacOS°ҐLinux°ҐшЩ√…÷–ґЉ”–“ЉВА≥ћ–т√ы„÷љ–°∞node°±£ђЄч„‘≤їЌђ£ђ «ѕµљy ¬ѕ»й_∞lЇ√µƒ°£Љў‘Oќ“ВГМСЅЋ“ЉВА≥ћ–тљ–app.js£ђЄчоР≤ў„чѕµљy…ѕґЉњ…“‘Ќ®я^√ьЅо°∞node app.js°±≥…є¶Ић––£ђ“Љћ„іъіaґаВА∆љћ®ґЉƒ№≈№°£
OpenClaw“™≈№∆рБн£ђяА–и“™“Љ–©Дe»Ћй_∞lµƒЈ«≥£÷Ў“™µƒ“јўЗ∞ь°£я@ЊЌ «й_‘іµƒЇ√ћО£ђДe»Ћй_∞lµƒњ…“‘÷±љ”ƒ√я^Бн”√£ђљMЇѕ≥цЄьЇ√µƒ–¬є¶ƒ№°£я@–©“јўЗ∞ь“≤ґЉ «Node.jsй_∞l≠hЊ≥—eƒ№≈№µƒ°£С™”√Node.js“јўЗ∞ь£ђ”–ВА÷Ў“™Ј÷∞lє§Њяnpm£ђ”√°∞npm install°±√ьЅоЊЌƒ№≤њ рЇ√°£я@ЇЌLinux Ubuntu≤ў„чѕµљy—eµƒ°∞apt install°±оРЋ∆£ђћбє©ЅЋЈљ±гµƒ∞≤—bЈљ љ°£
њ…“‘’f£ђOpenClaw”–80%µƒє¶ƒ№ґЉ «°∞’Њ‘Џnpm∞ьЉз∞т…ѕ°±МНђFµƒ£ђ÷ї”–20%µƒШIД’яЙЁЛ£®’{ґ»°Ґ”ЫСЫ°Ґ∞≤»ЂЄфлxµ»£© «„‘ЉЇМСµƒ°£
ЅнЌв£ђOpenClawяАљ®ЅҐЅЋ„‘ЉЇћЎ”–µƒй_‘іє¶ƒ№ФU’єѕµљy£ђЊЌ «≤ї…ў»Ћ¬†’fя^µƒSkill°£SkillЋг «ћЎ вµƒnpm∞ь£®њ…“‘”√npm∞≤—b£©£ђµЂOpenClawљoЋьЉ”ЅЋШЋ„Љїѓљ”њЏ°ҐMCPЕf„hяm≈дМ”£®„Міуƒ£–Ќƒ№’{”√£©°ҐClawhubЈ÷∞l«юµј°£ClawhubоРЋ∆npm“ЉШ”Ј÷∞lSkill£ђµЂМ£ЮйAIє§Њя‘O”Л°£њ…“‘∞—Skillјнљв≥…npm∞ь£ђµЂЉ”…ѕЅЋљoAIµƒ°∞ є”√’f√чХш°±£ђіуƒ£–Ќƒ№ЙтЄьнШХ≥µЎ“ОДЭ„МSkillО÷їо°£
»зєыВА»Ћ“™‘Џ„‘ЉЇµƒлКƒX…ѕ≤њ рOpenClaw£ђѕ»“™—b…ѕNode.jsй_∞l≠hЊ≥°Ґ≈д÷√≠hЊ≥„ГЅњ£ђя@ЊЌДсЌЋЅЋљ^іу≤њЈ÷»Ћ°£3‘¬6»’тv”НлЕ‘Џ…оџЏтv”НіуПBШ«ѕ¬Ф[ФВЌ∆≥ц°∞эИќr∞≤—b’Њ°±£ђ20ќїє§≥ћОЯ√вўMОЌ¬Ј»Ћ‘ЏВА»ЋлКƒX…ѕ≤њ рOpenClaw°™°™ЊЌ «Пƒя@“Љ≤љй_ Љ£ђі_МН–и“™ЉЉ–g»ЋЖT≥цФВ°£
я@“ЉєЭњіµ√√‘Їэ≤ї“™Њo£ђ÷™µј”–я@–©√ы‘~ЊЌ––ЅЋ°£“‘ббєј”ЛХю≥…Юй…зХю≥£„R£ђ¬†ґаЅЋ¬э¬эƒ№√ч∞„°£
£®Ј°£©÷–Зш‘SґаєЂЋЊ≥ц ÷бб£ђOpenClawЮйЇќ»Ё“„≤њ рЅЋ£њ
2025ƒк≥х±ђїрµƒЭM—™∞жµƒDeepSeek-R1£ђВА»Ћ≤їњ…ƒ№≤њ р≥…є¶°£µЂ÷–ЗшґаЉ“єЂЋЊґЉљ”»лЅЋ£ђяАяM––ЅЋ“эЅч£ђЉі єDeepSeekєЂЋЊ±Њ…нµƒЈюД’ФD±ђЅЋ£ђ»ЋВГ“≤”√…ѕДeЉ“≤њ рµƒDeepSeek°£я@іќOpenClawЯб≥±£ђ÷–Зшѕл‘ЏAI…ъСB—e’ЉќїµƒєЂЋЊ£ђґЉХюБнЕҐ≈c£ђ„М”√Сф‘Џ„‘ЉЇµƒ∆љћ®÷–”√OpenClaw°£я@ «÷–ЗшєЂЋЊ…√йLµƒ£ђ√жѕтіу±Кµƒљз√ж±ЎнЪ”—Ї√“„”√£ђ≤ї»їЫ]Ј®Ќ∆ПV°£
≥£“КµƒёkЈ® «лЕґЋљo”√Сфй_“ЉВАћУФMLinux÷чЩC£ђЊЌ «KimiClawя@Ш”°£‘SґаєЂЋЊґЉЌ∆≥цЅЋ£ђЇ√ћО «”√Сф≤ї–и“™”–ВА»ЋлКƒX£ђ±№√вЅЋВА»ЋлКƒX±їЌжЙƒ°Ґ–≈ѕҐ–є¬ґµ»¬йЯ©°£я@ЈNƒ£ љњ…“‘“ЉжI∞≤—b£ђ”√Сф÷±љ” є”√∞≤—bЇ√µƒOpenClawлЕЈюД’£ђµЂ“Љй_ Љ—e√ж ≤ьNВА»ЋµƒќƒЉюґЉЫ]”–°£
Ѕн“ЉВАёkЈ®£ђ «÷«„VµƒAutoClawƒ«Ш”£ђ∞—OpenClawіт∞ь≥…Вчљy„ј√ж№ЫЉю£ђл[≤ЎµфNode.jsµƒіж‘Џ£ђ‘Џ”√СфВА»ЋлКƒX…ѕ∞≤—b°£ЋьЊЌѕсВчљyWindows≥ћ–т“ЉШ”…µєѕ љ∞≤—b£ђ≤ї“ЉШ”µƒ «£ђЋьХю„‘ЉЇ≤ўњvлКƒX”√1Ј÷жR‘O÷√Ї√пwХшЩC∆ч»Ћ°£я@ЈNƒ£ љ£ђ”√СфµƒВА»ЋлКƒX÷±љ”ЊЌ”–OpenClawЅЋ£ђО÷їоЄьЮйЈљ±г£ђµЂ≥ц ¬ЅЋ“≤ЄьЮйќ£лU°£
ЉЉ–g–‘µЎ’f£ђћУФMLinux÷чЩC—eµƒOpenClawƒ№Ѕ¶Хю±»’ж’эВА»ЋлКƒX—eµƒ≤о“Љ–©°£єP’яі_МН∞lђFKimiClaw”–Ї№ґа¬йЯ©лy”√÷ЃћО£ђ‘≠јн…ѕЊЌ≤ї «њ…“Хїѓµƒ£ђ“≤Ы]”–¬Х“ф°£‘ў»злЕ…ѕљoВА»Ћµƒњ’йg÷ї”–40G£ђВА»ЋлКƒX”≤±P“™іуµ√ґа°£яА”–»’≥£µƒ∞lа]Љю÷ЃоРµƒє§„чЅч≥ћ£ђВА»ЋлКƒXћм»їЊЌ”–£ђOpenClawƒ№„‘»їљ””|£ђ‘ЏћУФMLinux÷чЩCПƒо^љ®ЅҐє§„чЅч≥ћЇ№≤ї»Ё“„°£µЂЯo’У»зЇќ£ђ”–МНЅ¶µƒєЂЋЊћбє©µƒлЕ…ѕЈюД’ «ВАЇ√ ¬£ђ„М»Ћƒ№Ё^ЮйЈљ±гµЎљ””|OpenClaw£ђƒ№љ®ЅҐ–¬µƒЅч≥ћ£ђ“≤ «„М»Ћ≈dК^µƒ°£
–и“™„Ґ“в£ђя@ «÷–ЗшћЎ”–µƒђFѕу£ђіуЅњ∆’Ќ®»Ћ“≤”–ёkЈ®‘З‘ЗOpenClaw°£‘ЏЪW√ј£ђїщ±Њ÷ї «ЉЉ–gПƒШI’яЇЌРџЇ√’яЇ№њсЯб£ђ∆’Ќ®»Ћ“тЮй∞ЇўFўM”√°Ґл[Ћљ±£„oµ»ЖЦо}”√≤ї…ѕ°£я@ «ќ“ВГ‘Џ÷–ЗшћЎ”–µƒ°∞ЉЉ–gЄ£јы°±°£
£®»ю£©OpenClawњњ ≤ьNО÷їоµƒ£њ
OpenClawБK≤ї «“Љ∞гµƒ№ЫЉю£ђ–и“™О÷≥…“Љ–©”–ьcЉЉ–gЇђЅњµƒїо£ђ≤≈Хю„МЉЉ–g…зЕ^Ѓa…ъЭвЇс≈d»§£ђ“э±ђ»Ђ«т°£єP’я‘Џ”^≤м’яЊWпL¬Д…зЕ^„‘Д”∞lћыЬy‘З≥…є¶£ђњ…“‘”√я@ВА∞ЄјэБн≈eјэ’f√ч°£
OpenClaw „‘Д”їѓЬy‘З∞lћы_пL¬Д (guancha.cn)
ѕ»„МOpenClaw„‘Д”∞lЅЋВАЬy‘ЗўN°£я@“Љ≤љ∆дМНЇ№≤ї»Ё“„£ђ“тЮйќ“ «”√KimiClawлЕЈюД’£ђЫ]”–њ…“Хїѓµƒ∆Ѕƒї°£–и“™Ї√О„≤љ£ђД””√ЅЋ“Љ–©є§Њя£ђ≤≈ƒ№Ќк≥…∞lўN°£
°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј (专题)Ср†О„о–¬Д”СB_пL¬Д (guancha.cn)
‘ў„МKimiClaw∞l“ЉВА√ј“‘≈c“Ѕј Ср†ОД”СBўN£ђ„‘–– ’ЉѓГ»»Ё°£њ…“‘њі≥цГ»»ЁЇ№‘гЄв£ђ «OpenClawЋ—Єчіу√љуwµƒШЋо}∆іЬР£ђ”–µƒЇЌСр†ОЇЅЯoкPѕµ£ђГ»»ЁЫ] ≤ьN÷«ƒ№њ…—‘°£
°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј Ср†О„о–¬Д”СBЈ÷ќц_пL¬Д (guancha.cn)
„МKimiClawЄƒ”√Kimi 2.5іуƒ£–Ќ…ъ≥……оґ»њВљY£ђƒ№њі≥цГ»»ЁЇ√ґаЅЋ£ђ”–ѕаЃФµƒ÷«ƒ№ЅЋ°£„МЋь√њћм‘з…ѕ8ьc‘ЏпL¬Д∞l≤Љ£ђЊЌљ®ЅҐЅЋ“ЉВАЋг «я^µ√»•µƒ„‘Д”∞lўN»ќД’°£я@і_МН «»Ђ„‘Д”µƒ£ђљ®ЅҐ»ќД’бб£ђ»Ћ≤ї”√є№ЅЋ°£ЃФ»їќƒ’¬ў|Ѕњ≤їЋгћЂЇ√£ђ÷ї «≈eјэ°£
°Њ2026ƒк3‘¬13»’–«∆Џќй°њ√ј“‘≈c“Ѕј Ср†О„о–¬Д”СBЈ÷ќц_пL¬Д (guancha.cn)
ј^јmГЮїѓ£ђ„МKimiClaw’{”√Kimi 2.5ƒ£Ј¬ќ“µƒќƒпLБнМС„чГ»»Ё£ђЬy‘З∞lўN°£„МЋьЕҐњЉќ“‘Џ”^ЊWµƒќƒ’¬М£ЩЏ°£
я@ВАГ»»Ёњі…ѕ»•„‘»їґаЅЋ£ђќƒпL”–ьcѕс°£µЂЄ–”XKimiіуƒ£–ЌБKќі„•„°ќ“µƒЋЉЊS£ђќ“≤їХюя@Ш”МС£ђµЂя@ЊЌ…о»ліуƒ£–Ќ…оМ”іќµƒ°∞м`їк°±ЖЦо}ЅЋ£ђ≥ґяhЅЋ°£
њіµљя@£ђњ…“‘ѕа–≈OpenClawƒ№О÷≥…–©”–ьcЉЉ–gЇђЅњµƒ ¬°£„‘Д”∞lўN°Ґƒ£Ј¬ќƒпL «“ЉоР ¬£ђяА”–Ї№ґаПЌлs»ќД’“≤њ…“‘Ќк≥…°£∆дМНбб√жО„іќЄƒяM≤їлy£ђ„‘»ї’Z—‘Єж‘VKimiClaw“™О÷ ≤ьNЊЌ––ЅЋ£ђ„МЋь…ъ≥… ≤ьNГ»»Ё£ђ„МЋьƒ£Ј¬ќƒпL£ђ„МЋьґ®Хr∞l≤Љ°£µЂ“™МНђFµЏ“Љ≤љ£ђ°∞‘Џ”^ЊWпL¬Д’УЙѓ„‘Д”∞lўN°±£ђя@≤їЇЖЖќ°£Ы]”–OpenClaw£ђ»зєыМ¶іуƒ£–ЌС™”√й_∞l°ҐAI÷«ƒ№уwй_∞lЇ№ЊЂЌ®£ђС™‘У“≤”–ёkЈ®£ђµЂќ“≤ї÷™µј‘хьN„ц°£”–ЅЋOpenClaw£ђлm»ї“≤≤їЇЖЖќ£ђµЂ√юЋч÷шƒ№МНђF°£
µЏ“ЉВА≥…є¶µƒЬy‘З∞lўN“—љЫ’fЅЋ–©ЉЉ–gЉЪєЭ£Ї
°∞∞l≤ЉЈљ љ£ЇPlaywright + xvfb-run „‘Д”їѓ°±
°∞я@ «KimiClaw‘ЏЈюД’∆ч≠hЊ≥÷– є”√PlaywrightЮg”[∆ч„‘Д”їѓє§ЊяЌк≥…µƒ≤ў„ч°£°±
OpenClawЌюЅ¶„оіуµƒє§Њя÷Ѓ“Љ£ђО„Їхњ…“‘Ћг «„оЇЋ–ƒµƒє¶ƒ№£ђЊЌ «я@ВАPlaywright°£Ћь «OpenClawµƒ ÷£®ЊWнУ≤ў„ч£©ЇЌ—џ£®ЊWнУљЎ∆Ѕ£©£ђ„МAIƒ№МНлHњЎ÷∆Юg”[∆ч£ђьcУф°ҐЁФ»л°ҐљЎИD°ҐЭLД”°Ґѕ¬ЁdґЉ––°£µЂ «£ђPlaywrightµƒ…с∆жШOЮй“јўЗ≈cїщ„щіуƒ£–ЌµƒоlЈ±ї•Д”£ђ≤≈÷™µјЌщѕ¬‘хьNД”„ч£ђ“Љіќ≤ў„чњ…ƒ№“™50-100іќљЎИD-ЫQ≤я—≠≠h°£іуƒ£–Ќ“™”–ґаƒ£СB“Х”Xјнљвƒ№Ѕ¶£ђƒ№јнљвљЎ∆ЅГ»»Ё°£
»з…ѕ√жµƒпL¬Д∞lўNљз√ж£ђPlaywrightХюљЎ∆ЅљoKimi 2.5іуƒ£–Ќњі°£Kimi 2.5”–‘≠…ъµƒ“Х”Xјнљвƒ№Ѕ¶£ђƒ№њіґЃ°∞ШЋо}°±°Ґ°∞’эќƒ°±њт ≤ьN“вЋЉ£ђЄж‘VPlaywright»•ћоГ»»Ё°£»зєы «ЊWљjўПќп÷ЃоРµƒ»ќД’£ђ“™‘ЏЊWнУ—e≤їФаьcУф…о»л£ђ»зєы≤їМ¶–и“™ЈіПЌ‘З°£Ћщ“‘PlaywrightЈ«≥£Їƒtoken£ђ”––©»Ћ∞lђFО÷“ЉВА ¬О„ЙKеXЊЌЫ]ЅЋ£ђ“тЮй“™љЎ∆Ѕ100іќ»•’{”√іуƒ£–Ќјнљв£ђ“ЉВАљЎ∆ЅЊЌ“™‘SґаToken°£
лm»їPlaywrightЇ№Їƒtoken£ђµЂЋьі_МНƒ№„‘Д”≤ў„чЊWнУ≤ў„чёk≥…≤ї…ў ¬°£Playwright «ќҐ№Ый_∞lµƒ£ђіъіaй_‘іЅЋ£ђOpenClawƒ√Бн„чЮй„о÷Ў“™µƒє¶ƒ№љMЉю÷Ѓ“Љ°£
Вчљy≈јѕx «‘LЖЦєћґ®ЊW÷Ј£ђ÷ї’{”√1іќAPIЊЌƒ№Ђ@»°ФµУю£ђ≥…±ЊО„ЇхЮйЅг°£я@“≤ «‘Sґа°∞ћмЪв≤й‘Г°±÷ЃоРµƒOpenClawЇЖЖќskillµƒћ„¬Ј°£µЂќ“‘ЏKimiClaw—e”√я@–©ЇЖЖќskill£ђЄ–”X≤ї «ћЂПК°£я@оРЇЖЖќAPI‘LЖЦ£ђЯoЈ®Ќк≥…ПЌлs≤ў„ч°£ї•¬УЊWєЂЋЊћбє©єўЈљAPIЈюД’ «”–£ђ»зє…∆±–≈ѕҐAPI£ђпwХшЩC∆ч»Ћ“≤ «“ЉЈNAPIЈюД’£ђ“™„цµ√Ї№Ќк…∆БK≤ї»Ё“„°£Ї№”–Гr÷µµƒ£ђЌщЌщ“™ЄґўM£ђя@ЊЌПЌлsЅЋ°£Playwrightƒ№ƒ£Јґ»ЋЌк≥…ПЌлsЊWнУ≤ў„ч£ђ±»≈јѕxїт’яAPI’{”√ПƒЩC÷∆…ѕЊЌ“™ПКµ√ґа°£
OpenClaw≤ї «М¶”^ЊWЈюД’∆ч∞l≥ц“Љґ—„÷ЈыіЃ£ђ»їбб“ЉЋ≤йg‘ЏпL¬Д∞lўN≥…є¶£ђ”^ЊWЫ]я@ВАAPIЈюД’°£Ћь «‘ЏLinuxћУФMЩC—e£ђя\––ЅЋЮg”[∆ч£ђ‘LЖЦпL¬Д∞lўNнУ√ж£ђ»їббЌщњт„”—eћоЅЋГ»»Ё£ђьcУф∞lЋЌ£ђЌк»ЂЇЌ»Ћ“ЉШ”≤ў„ч£ђ «“ЉВАЊП¬эµƒя^≥ћ°£Љ”…ѕМСўN£ђ5Ј÷жRґЉ„ц≤їЌк°£
‘SґаЊW’Њ”–Јі≈јѕx°ҐЈіЩC∆ч»ЋЩC÷∆£ђ∞lђF°∞”√Сф≤ї «»Ћ°±ЊЌЊ№љ^°£Ую’f90%µƒЊW’ЊґЉ”–Cloudflareµ»Јі≈јЩC÷∆°£Playwright «’жµƒХюƒ√∆Ѕƒї»•Ј÷ќц£ђ¬э¬э≤ў„ч£ђƒ№ј@й_ѕё÷∆°£µЂ «М¶KimiClawя@оРлЕ…ѕћУФMLINUXЈюД’∆ч—eµƒOpenClaw£ђЋьЫ]”–МНуw∆Ѕƒїіж‘Џ£ђЋщ“‘ШЛ≥…”–ьcјІлy°£љвЫQёkЈ® «”√xvfb-runє§Њя£ђ…ъ≥…ћУФM∆Ѕƒї£ђ„МPlaywright»•љЎ∆Ѕ°£ДВй_ ЉяB≥√ ÷µƒЮg”[∆чґЉЫ]”–£ђ“™»•ѕ¬Ёd∞≤—bLinux—eµƒChromiumЮg”[∆ч°£
‘ў“ЉВАЖЦо} «”^≤м’яЊWпL¬Дў~ћЦµ«кС£ђљвЫQёkЈ® «»Ћє§‘ЏВА»ЋлКƒX…ѕµ«кС≥…є¶£ђ‘ўПƒЮg”[∆ч…ѕѕ¬ЁdCookie£ђўNљoKimiClaw£ђЋь÷™µј»зЇќ»•”√°£
лm»їя^≥ћ≤їЇЖЖќ£ђµЂЇ√ћО «іуƒ£–ЌЇ№ПКіу£ђћљЋчя^≥ћ÷–Хю÷чД”ОЌ√¶£ђљo≥цЄчЈNЈљ∞Є°£»Ћ≤ї”√’fµ√Ї№ЊЂі_£ђ„МKimiClaw»•Ић––ЊЌЇ√ЅЋ°£µЂ»Ћ“≤–и“™јнљвіуƒ£–Ќ≈cOpenClawљo≥цµƒЩC÷∆≈cЈірБ£ђ≈дЇѕ––Д”°£я@–и“™“Љ–©ƒЌ–ƒ≈cћљЋчЊЂ…с£ђOpenClawњ…“‘Ћг «є¶ƒ№ПКіуµƒй_Ј≈–‘й_∞l∆љћ®£ђ≤ї « ÷ЩCAPPя@оР…µєѕїѓ“„”√є§Њя°£
OpenClawµƒПКіу£ђ“ЉВА «їщ„щіуƒ£–Ќµƒƒ№Ѕ¶Ї№ПКЅЋ£ђ‘љя^ЅЋМН”√µƒйTЩС£ї‘ў“ЉВА «”–Playwrightя@оРЇ№МН”√µƒє¶ƒ№ПКіуµƒє§Њя°£”–ЅЋя@–©ПКіуµƒќд∆ч£ђ‘ў≈д…ѕВчљyµƒї•¬УЊWAPI°Ґ≥ћ–тЋгЈ®£ђ≤≈й_∞l≥цЅЋOpenClaw°£Ћьµƒя\„чЈљ љ“≤ «њ…“‘љвбМµƒ°£
њ…“‘њі≥ц£ђOpenClaw„‘ЉЇ∆дМНЫ]…ґ÷«ƒ№£ђ±»»зЋь„‘ЉЇ∆іЬР∞lўNГ»»ЁЊЌ≤їћЂМ¶°£µЂЋьп@µ√÷«ƒ№£ђБн‘і «’{”√іуƒ£–Ќ£ђ“‘Љ∞“Љ–©ПКіуµƒљMЉю°£ЋьЄьѕс“ЉВАљMњЧ’я£ђМ¶љ””√Сф–и«у£ђ„Міуƒ£–ЌЫQ≤я£ђ’{”√ЄчЈNє¶ƒ№љвЫQЖЦо}°£
£®ЋЅ£©OpenClawЊяуwµƒя\––Ѕч≥ћ « ≤ьN£њ
…ѕ√ж «OpenClawє¶ƒ№–‘µƒљйљB°£OpenClaw±Њў|…ѕ «“ЉВА№ЫЉю£ђЋь”–“ЉВАњ…“‘“Љ≤љ≤љЊЂі_јнљвµƒя\––я^≥ћ£ђЅЋљвЊяуwµƒя\––Ѕч≥ћƒ№ЄьЇ√µƒјнљв‘≠јн°£
“ЉВАВчљy№ЫЉюїт’яЋгЈ®я\––£ђ∆дЅч≥ћ «°∞љ” ’ЁФ»л°Ґ’{”√є§Њя°ҐЈµїЎнСС™°±°£ї•¬УЊWЈюД’їт’я ÷ЩCAPPµ»≥ћ–тЊЌ «я@Ш”„цµƒ£ђ»ЋВГ”√µ√Ї№ м°£OpenClaw“≤ «“ЉВА№ЫЉю£ђ“≤”–ЌђШ”µƒЅч≥ћ°£
µЂ «£ђOpenClaw≈cВчљy№ЫЉю„оіуµƒ≤їЌђ£ђ «я\––Хr”–÷«ƒ№°£ЋьµƒЅч≥ћ «°∞љ” ’ЁФ»л°ҐЩzЋч”ЫСЫ°ҐЌ∆јнЫQ≤я°Ґ’{”√є§Њя°ҐЄь–¬”ЫСЫ°ҐЈµїЎнСС™°±£ђЉ”ЅЋ“Љ–©÷«ƒ№ѕакP≠hєЭ°£я@ВАя^≥ћ «МС‘ЏOpenClawµƒNode.js≥ћ–тіъіa—eµƒ£ђ «й_‘іµƒ£ђБK≤ї…с√Ў°£
„МOpenClawїр±й»Ђ«тµƒ£ђ «Ћь≈cВчљyЋгЈ®µƒЕ^Дe£Ї
Вчљy№ЫЉю£ђљ” ’µƒЁФ»л «√чі_µƒ÷ЄЅо£ђ”…ЁФ»л≈cљїї•љз√жі_ґ®£ђ≤ї «ƒ£Їэµƒ„‘»ї’Z—‘£їOpenClawњ…“‘јнљв”√Сфµƒ„‘»ї’Z—‘£ђ÷ЄЅо“Љѕ¬ЈЇїѓЅЋ°£ѕ»≤ї’fƒ№≤їƒ№„цЇ√£ђВчљyЋгЈ®ƒ№°∞±ї“™«у°±„цµƒ ¬£ђШOЮй”–ѕё£ђљ” ’ЁФ»лЋј∞е£їґшOpenClaw «Ќк»Ђй_Ј≈µƒ£ђѕлѕуЅ¶Ќк»Ђітй_£ђњ…“‘љ” ’ЯoФµЈNЁФ»л£ђ”√Сфњ…“‘ћб≥цЄчЈNЇѕјнїт’я≤їЇѕјнµƒ“™«у°£
ВчљyЋгЈ®£ђ’{”√µƒє§ЊяШOЮй”–ѕё£ђ « ¬ѕ»і_ґ®µƒ£ђЋгЈ®ґЉ «МСЋјµƒ°£Љі єПЌлsµљќҐ–≈я@ьNіуµƒ≥ћ–т£ђє¶ƒ№“≤ «”–ѕёµƒ£їOpenClawƒ№Йт’{”√µƒє§ЊяФµЅњЯo…ѕѕё£ђЋь”–‘Sґа’ыјнЇ√µƒskillsћ„¬Јњ…”√£ђяАњ…“‘Ћ—Ћчµљњ…”√µƒї•¬УЊWЈюД’£ђяАƒ№„‘ЉЇМС≥ћ–тй_∞lє§Њя£ђјн’У…ѕµƒƒ№Ѕ¶Яo…ѕѕё°£
ВчљyЋгЈ®µƒ”ЫСЫє¶ƒ№Ј«≥£”–ѕё£ђ÷ї «ґ®ЋјµƒФµУюОм°ҐЄь–¬ФµУюОм£ђїт’я“Љ–©яxнЧ‘O÷√°£OpenClawµƒ”ЫСЫ «й_Ј≈µƒ£ђЋьњ…“‘∞і»’∆Џ”Ыѕ¬≈c”√Сфµƒї•Д”£ђ„чЮйбб√жљїї•µƒЕҐњЉ£ђњтЉ№ «й_Ј≈µƒ°£
ВчљyЋгЈ®÷їƒ№Ић––єћґ®ћ„¬Ј£ђ…ўФµ≥ћ–т”–ґ®ХrИћ––є¶ƒ№£ђ“вЅx≤їіу°£OpenClawњ…“‘”Ыѕ¬ШOґа”√Сфљїіэµƒ ¬£ђґ®∆ЏИћ––°£њтЉ№ «й_Ј≈µƒ£ђ√њћмњ…“‘„ц‘Sґа ¬£ђ «ƒ№Ѕ¶ПКіуµƒ°∞AI÷ъјн°±£ђµ»мґ‘Sґа№ЫЉює¶ƒ№њ…“‘“Љ∆р≈№°£
Пƒ…ѕ√жµƒЈ÷ќцњ…÷™£ђOpenClaw «“ЉВАПЎµ„ітй_ѕлѕуЅ¶µƒй_Ј≈–‘№ЫЉю£ђ≈cВчљyЋгЈ®Ќк»Ђ≤ї «“ЉїЎ ¬£ђ„оіуµƒћЎьcЊЌ «й_Ј≈–‘°£»ЋВГЌ®я^–ыВч°ҐМНлH≈№Ш”јэ£ђЇ№њмЊЌƒ№∞lђFOpenClawµƒПКіу≈cДУ–¬°£ьS» Дм’fOpenClaw «°∞”– Ј“‘Бн„о÷Ў“™µƒ№ЫЉю∞l≤Љ°±£ђЊЌ «я@ВА“вЋЉ°£
µЂ «£ђя@ьNЇ√µƒ ¬£ђ±ЎнЪ”–іуƒ£–ЌОЌ÷ъ≤≈ƒ№МНђF°£‘Sґа»ЋґЉ”–ЇЌіуƒ£–ЌЅƒћмµƒљЫтЮ£ђƒ№√ч∞„іуƒ£–Ќµƒƒ№Ѕ¶£Ї
іуƒ£–ЌХю»•њіМ¶‘Тњт—eµƒ…ѕѕ¬ќƒ£ђМ¶‘Т «”–кP¬Уµƒ£ђя@ЊЌ «”–°∞ЩzЋч”ЫСЫ°±°£
іуƒ£–ЌХю»•ЊWљjЋ—Ћч ’Љѓ–≈ѕҐ£ђ‘цЉ”–≈ѕҐ£ђ≤ї÷ї”√”ЦЊЪХrљЎ÷є»’∆Џ÷Ѓ«∞µƒ–≈ѕҐ°£
іуƒ£–ЌХю”–ЋЉњЉµЎЈ÷‘Sґа≤љ»•Ќк≥…»ќД’£ђя@ЊЌ «‘Џ°∞Ќ∆јнЫQ≤я°±°£
іуƒ£–ЌХюМС≥ћ–т£ђƒ№й_∞lє§Њя°£
OpenClaw≤ї «іуƒ£–Ќ£ђµЂЌ®я^APIБн’{”√іуƒ£–Ќ°£љ” ’ЁФ»лбб£ђOpenClawЩzЋч”ЫСЫ£ђМҐЋь„чЮй…ѕѕ¬ќƒ£ђ’{”√іуƒ£–ЌяM“Љ≤љ√ч∞„”√Сфµƒ“вИD£ђ≤ї”√÷ЎПЌљїіэ£їіуƒ£–Ќљ”÷шяM––°∞Ќ∆јнЫQ≤я°±£ђЄщУю”√Сф“вИD…ъ≥…°∞є§„ч”ЛДЭ°±£ђя@ «2025ƒкіуƒ£–ЌAgentй_∞lµƒµд–ќ»ќД’£їOpenClaw’{”√є§Њябб£ђњіЈµїЎµƒљYєы£ђЄщУю≥…Ф°Ќ∆яMє§„ч”ЛДЭ£ђ’{”√Єьґає§Њя£їє§„ч”ЛДЭЌк≥…бб£® ІФ°“≤ «“ЉЈNЌк≥…љYєы£©£ђOpenClaw’{”√іуƒ£–Ќ…ъ≥…њВљYЄь–¬”ЫСЫ£ђМҐ„ољKљYєыљMњЧ≥…”√Сфƒ№љ” №µƒ–ќ љЁФ≥ц£ђЈµїЎнСС™°£
Пƒ…ѕ√жµƒ√и цњ…÷™£ђіуƒ£–ЌМ¶OpenClawµ»AI÷«ƒ№уwоР№ЫЉюЈ«≥£÷Ў“™£ђя@іуЉ“ґЉ÷™µј°£µЂяА”–“ЉВАљ–°∞”ЫСЫ°±µƒЦ|ќч£ђ”–ьc√‘Їэ°£я@ЊЌ…жЉ∞OpenClawЇЋ–ƒњтЉ№µƒ»юіуљMЉю£ЇSkill system°ҐAgent Runtime°ҐMemory°£
Skill systemњ…“‘ƒ£ЇэјнљвЮй“Љіуґ—°∞AIЉЉƒ№∞ь°±£ђњ…“‘ФU’єµƒ°£я@∆дМН≤їлyјнљв£ђЊЌЃФ «”–“Љґ—„”≥ћ–тњ…є©’{”√£ђВчљyЊО≥ћ—eЊЌ”–‘SґаОмЇѓФµ°£Skill systemњ…“‘ЃФ„ч «AIоРОмЇѓФµ£ђ√њВА”–SKILL.mdя@Ш”µƒљoAIњіµƒ°∞ є”√’f√чХш°±°£
µЂ„МOpenClaw≈№∆рБн£ђяА–и“™∆дЋьГ…ВА÷Ў“™љMЉю£ЇAgent Runtime°ҐMemory°£
MemoryѕµљyѕаМ¶»Ё“„јнљв£ђЊЌ «°∞”ЫСЫ°±£ђЋь «OpenClaw–и“™µƒХю‘Т…ѕѕ¬ќƒ°Ґґћ∆Џ≈cйL∆Џ»’÷Њ°Ґ”√Сф∆ЂЇ√»ЋЄсµ»µ»£ђХюЈ÷йTДeоРЈ≈‘ЏѕакPќƒЉю—e°£°∞”ЫСЫ°±БK≤ї–юћУ£ђ÷±”^јнљвЊЌ «“Љ–©ќƒЉю∞—”√Сфљїіэµƒ‘Т°Ґ”√Сф≈cOpenClawµƒї•Д”£ђ”√ќƒЉю”Ыѕ¬Бн°£ќ“”√µƒKimiClaw «‘ЏLinuxћУФMЩCµƒ°∞/root/.openclaw/workspace/°±ƒњдЫ—e£ђ”√ЋЅВАкPжIµƒ.mdќƒЉю£ђ∞—”√СфѕакPµƒ ¬”Ыѕ¬Бн°£яА”–√њћмµƒє§„ч»’÷Њ£ђKimiClaw «іж‘Џ/root/.openclaw/workspace/memoryƒњдЫ—e£ђ√њћм”–“ЉВА»’÷ЊќƒЉю°£я@≤ї…ў≥£“О№ЫЉю“≤”–£ђ≤їлyјнљв°£
–и“™„Ґ“вµƒ «£ђя@–©”ЫСЫѕакPќƒЉюµƒГ»»Ё£ђ «AI’ыјнµƒ°£≤ї « ¬ЯoЊёЉЪґЉ”Ы£ђ“≤≤ї «‘≠Ш””Ы£ђґш «јнљвЅЋ“‘бб’™“™°ҐЕRњВ”ЫСЫ£ђ «÷«ƒ№”ЫСЫ°£»зєы“Љґ— ¬ћЂйL£ђЊЌЕRњВ“Љѕ¬°£∆дМН»Ћ“≤≤ї « ≤ьNґЉ”Ы£ђ÷Ў“™µƒ ¬”Ы„°£ђЉЪєЭЈ≈ќƒЉю—e°£OpenClawµƒ”ЫСЫ“≤ «»зіЋ£ђ÷Ў“™µƒ ¬Ј≈”√СфЇЋ–ƒ”ЫСЫќƒЉю—e£ђЉЪєЭЈ≈‘Џ»’÷Њ—e£ђ≥ц ¬ЅЋф[≤ї«еЊЌ»•≤й»’÷Њ°£Ћщ“‘Memory“≤ «ЇЌіуƒ£–Ќ”–кPµƒ°£
MemoryѕакPµƒќƒЉюЈ«≥£÷Ў“™°£ќ“µƒKimiClaw≥цЅЋ“ЉіќіуЖЦо}£ђ≤ї÷™µјЮйЇќmemoryƒњдЫґЉЫ]ЅЋ£ђMEMORY.md“≤„Г≥…њ’µƒЅЋ£ђЊЌ∞lђF»ќД’Ић––ЇъЊОБy‘м£ђ…µ„”“ЉШ”£ђЄщ±ЊЫ]Ј®”√ЅЋ°£ќ“„МЋь–ёПЌ£ђ≤≈”÷Ї√∆рБн°£
Agent Runtimeњі√ы‘~≤їћЂЇ√јнљв£ђµЂЋь «OpenClaw’ж’эµƒЇЋ–ƒ£ђ–и“™„–ЉЪљвбМ°£AgentЊЌ «AIШIљзЅч––ЅЋ“ЉґќХrйgµƒ°∞÷«ƒ№уw°±£ђя@ «’fOpenClaw «“ЉВА”–÷«ƒ№µƒ№ЫЉю£ђƒ№°∞іъјн°±“ЉШ”ћж»Ћ„ц ¬°£Runtime «≥ћ–тЖT мѕ§µƒМ£”√√ы„÷£ђњ…“‘оР±»јнљв≥…Windows°Ґ ÷ЩC≤ў„чѕµљyй_ЩCХrµƒя\––†оСB°Ґя\––≠hЊ≥£ђ «ВАД”СBµƒЄ≈ƒо°£кPЩCЅЋЊЌЫ]”–Runtime£ђ≈№∆рБнЅЋЊЌ”–“Љґ—Ц|ќчїо№S∆рБн£ђ≈дЇѕ„ц ¬£ђ’ыВАЈ’Зъљ–Runtime°£
OpenClaw≈№∆рБн“‘бб£ђ’ыВАѕакPя\––≠hЊ≥£ђЊЌ «Agent Runtime£ђЎУЎЯє№јнAIіъјнµƒЌк’ы…ъ√ь÷№∆Џ£ђ”–ґаЈNѕакPє¶ƒ№°£»з°∞Хю‘Тє№јн°±£ђЊS„o≈c”√СфµƒМ¶‘Т…ѕѕ¬ќƒ£ђћОјнґаЁЖМ¶‘Т†оСB£ї‘ў»з°∞ѕыѕҐ¬Ј”…°±£ђљ” ’Бн„‘≤їЌђ«юµјµƒѕыѕҐ£ђ¬Ј”…µљМ¶С™Хю‘Т£ђпwХшяА «ЊWнУЅƒћмњтБнµƒЈ÷«е≥ю£ї°∞є§ЊяЊО≈≈°±£ђљвќц”√Сф“вИD£ђ’{”√яmЃФµƒє§ЊяБKє№јнИћ––Ѕч≥ћ£ї°∞∞≤»Ђ…≥Ї–°±£ђњЎ÷∆є§Њя‘LЖЦЩаѕё£ђЕ^Ј÷Г»≤њ≤ў„чЇЌЌв≤њ’{”√°£я@–©ґЉ «OpenClawµƒіъіaМНђFµƒ£ђ «∆діъіa’ж’эМ¶С™µƒє¶ƒ№°£
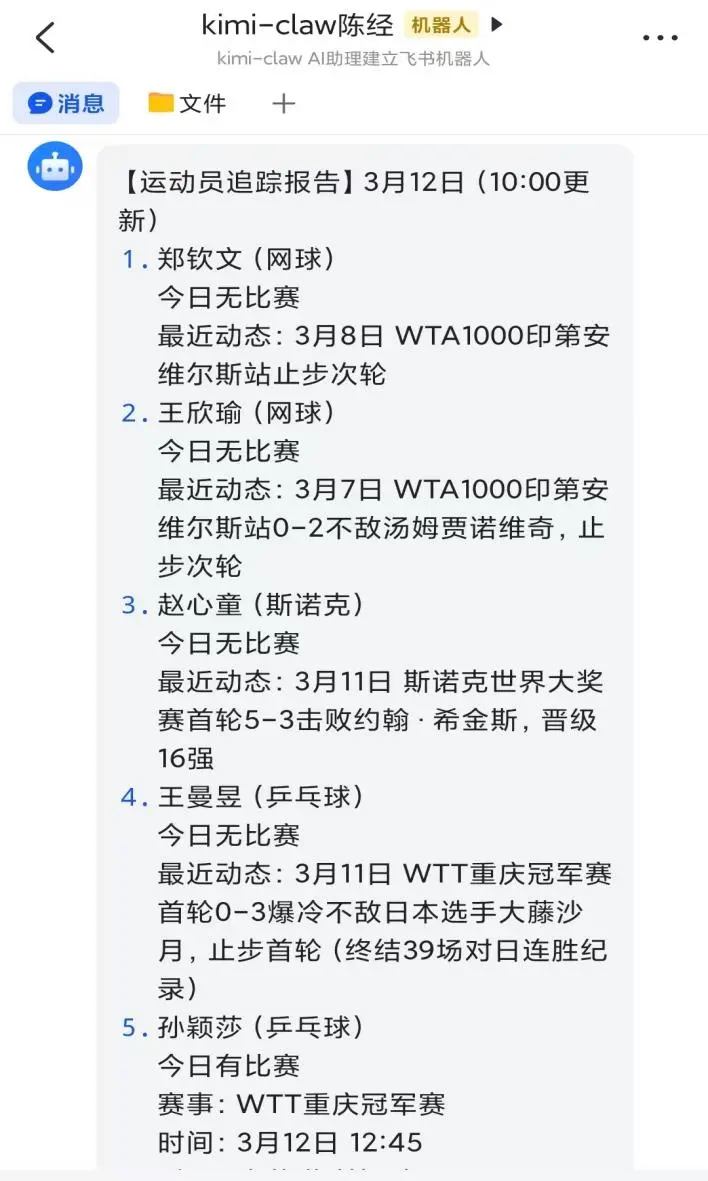
њ…“‘”√°∞я\Д”ЖT±»ўР„ЈџЩ°±µƒ∞Єјэ£ђБнЊяуw’f√чOpenClawя\––“ЉВА»ќД’µƒя^≥ћ°£ќ“‘ЏпwХш…ѕ£®їт’яKimiClawЊWнУ…ѕЅƒћм“≤њ…“‘£©£ђ“™«у°∞Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ°±°£я@ЅщВАя\Д”ЖT «аНЪJќƒ°ҐЌх–ји§°ҐЏw–ƒЌѓ°ҐЌх¬ьк≈°ҐМOЈf…ѓ°ҐЌх≥юЪJ£ђ «÷Ѓ«∞љїіэµƒ£ђЈ≈‘ЏMemoryќƒЉю—eЅЋ°£
1.љ” ’ЁФ»л£®ѕµљyМ”£©
”√СфѕыѕҐ£Ї"Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ"
я@≤љ≤ї…жЉ∞іуƒ£–Ќ£ђOpenClaw Gateway љ” ’БK¬Ј”…µљAgent Runtime°£
2.ЩzЋч”ЫСЫ£®є§Њя’{”√£©
Action: memory_search(query="я\Д”ЖT„ЈџЩ аНЪJќƒ Ќх–ји§...")
я@≤љ“≤≤ї…жЉ∞іуƒ£–Ќ£ђ÷±љ”„x»°ќƒЉюѕµљyЈµїЎ”ЫСЫ∆ђґќ°£
3.Ќ∆јнЫQ≤я£®іуƒ£–Ќљй»л - µЏ1іќіуƒ£–ЌAPI’{”√£©
ЁФ»лљoƒ£–Ќµƒ…ѕѕ¬ќƒ£Ї
User: "Єь–¬ѕ¬ЅщВАя\Д”ЖTµƒЄъџЩ–≈ѕҐ"
Memory: [кРљЫкP„ҐЌґўY°Ґуw”э°Ґ√љуwГ»»ЁДУ„ч]
Available tools: [kimi_search, web_fetch, sports-tracker Skill]
ƒ£–ЌЌ∆јнЁФ≥ц£Ї
“вИDЈ÷ќц£Ї”√Сф“™«уЄь–¬я\Д”ЖT„ЈџЩ–≈ѕҐ
”ЫСЫ∆•≈д£ЇUSER.md п@ ЊкP„Ґ6ќїя\Д”ЖT£®аНЪJќƒ°ҐЌх–ји§...£©
є§ЊяяxУс£Ї
ГЮѕ» є”√ sports-tracker Skill£®“—≈д÷√£ђ„Љі_–‘Єя£©
Ёo÷ъ є”√ kimi_search тЮ„CМНХr±»Ј÷
Ић––”ЛДЭ£Ї
- ѕ»Ић–– /root/.openclaw/workspace/skills/sports-tracker/scripts/tracker.py
- »їбббШМ¶”–±»ўРµƒяx ÷ є”√ kimi_search Ђ@»°Њяуw±»Ј÷
- „обб’ыјнИуЄж
4.’{”√є§Њя£®Ић––М”£©
„”≤љуE4a£ЇИћ–– tracker.py
cd /root/.openclaw/workspace
python3 skills/sports-tracker/scripts/tracker.py
„”≤љуE4b£Їkimi_search£®ЄщУюƒ£–ЌЫQ≤я£©
Action: kimi_search(query="МOЈf…ѓ ÷м№ЈкЎ WTT÷ЎСcєЏ№КўР 3‘¬12»’ љYєы ±»Ј÷")
Ћ—Ћч“э«жAPI÷±љ”ЈµїЎљYєы
„”≤љуE 4c£Ї„x»°љYєыБK’ыјн
„x»° tracker.py ЁФ≥ц + kimi_search љYєы
я@≤љ≤ї…жЉ∞іуƒ£–Ќ£ђ «є§Њя’{”√°ҐЊWљjЋ—Ћч°ҐФµУю’ыЇѕ
5.Єь–¬”ЫСЫ£®іуƒ£–Ќљй»л - µЏ2іќ API ’{”√£©
ЁФ»л£Ї‘≠ Љ„ЈџЩљYєы£®йLќƒ±Њ£©
ƒ£–Ќ»ќД’£ЇћбЯТкPжI–≈ѕҐ£ђ…ъ≥…ЇЖЭН”ЫСЫ
ЁФ≥ц£Ї"МOЈf…ѓ3-0Дў÷м№ЈкЎ£ђЌх≥юЪJіэ±»ўР19:40"
љYєыМС»лmemoryƒњдЫ—eµƒ»’÷ЊќƒЉю2026-03-12.md£ђ…ѕИD «ќ“‘ЏљKґЋ—e÷±љ”≤йњіµљµƒ»’÷ЊГ»»Ё£ђ «”–”√іуƒ£–ЌњВљYµƒ°£
6.ЈµїЎнСС™£®іуƒ£–Ќљй»л - µЏ3іќAPI’{”√£©
ЁФ»лљoƒ£–Ќ£Ї
є§ЊяИћ––љYєы£Ї
- tracker.py: "6ќїя\Д”ЖT÷–£ђМOЈf…ѓ°ҐЌх≥юЪJљс»’”–±»ўР..."
- kimi_search: "МOЈf…ѓ 3-0 ÷м№ЈкЎ£®11-5, 13-11, 11-8£©..."
»ќД’£Ї…ъ≥…љo”√СфµƒїЎПЌ
“™«у£ЇЇЖЭН°ҐљYШЛїѓ°ҐЌї≥цкPжI–≈ѕҐ
ƒ£–Ќ…ъ≥…нСС™£Ї
°Њя\Д”ЖT„ЈџЩИуЄж°њ3‘¬12»’£®14:20Єь–¬£©
...
МOЈf…ѓ£®∆є≈“«т£©
- љс»’±»ўР“—љY ш
- ±»Ј÷£Ї3-0 Дў÷м№ЈкЎ£®11-5, 13-11, 11-8£©
- †оСB£ЇХxЉЙ16ПК
Ќх≥юЪJ£®∆є≈“«т£©
- іэ±»ўР£Ї19:40 vs Є•ј ќчЋєњ®
я@—e’{”√ЅЋіуƒ£–Ќ API£ђМҐє§ЊяљYєыёDїѓЮй„‘»ї’Z—‘°£
„Ґ“в…ѕ√жµƒЅч≥ћ÷–”–ВАkimi_search£ђЋь≤ї «skills“≤≤ї «іуƒ£–Ќ£ђґш «KimiClawГ»÷√µƒЊWљjЋ—Ћчє§Њя°£
Яo’УґаьN…с∆жµƒOpenClawє¶ƒ№£ђґЉњ…“‘≤рљв°£OpenClawЇЋ–ƒ°Ґ”ЫСЫЩzЋч°Ґіуƒ£–Ќ’{”√°ҐSkillsє§Њя’{”√≈cЊWљjЋ—Ћч°Ґ”ЫСЫЄь–¬µ»ґаЈNƒ£ЙKљMЇѕ£ђЊЌƒ№Ќк≥…ЯoФµЈN»ќД’°£
њ…“‘њі≥ц£ђя@ВАљMЇѕШOЮйм`їо£ђƒ№Ќк≥…µƒ»ќД’ѕлѕуЅ¶Ќк»Ђітй_°£∆д÷–іуƒ£–Ќµƒƒ№Ѕ¶ «кPжI£ђ”–ЅЋЋь£ђ≤≈ƒ№јнљв“™О÷ ≤ьN ¬°Ґ»зЇќИћ––»ќД’°Ґ»зЇќЁФ≥цљo”√Сф£ђЋщ“‘Ќк≥…“ЉВА»ќД’“™ґаіќ’{”√іуƒ£–Ќ°£”––©њЌСф∞lђF”√OpenClawћЂї®еXЅЋ£ђ±»іуƒ£–ЌAPPЖЦірї®еXґаЅЋ£ђЊЌ «“тЮй°∞“ЉВА»ќД’ґаіќ’{”√°±µƒћЎ–‘£ђіуƒ£–ЌїЎірЖЦо}ЊЌ «“Љіќ’{”√°£
÷«ƒ№уwƒ№йLХrйg≤їФа’{”√іуƒ£–ЌЌ∆яM»ќД’£ђ «÷«ƒ№яM≤љµƒШЋ÷Њ£ђ“—љЫПƒО„ ∞Ј÷жRяM≤љЅЋµљО„–°Хr…х÷ЅЄьйL°£”––©»ќД’OpenClawњ…“‘≈№Ї№йLХrйg≤ї≥цеe„ољKЌк≥…£ђµЂЋьїщ±Њ «“ЉВА÷«ƒ№уw‘Џ≈№°£ђF‘ЏAI«∞—Ў“—љЫ∞l’єµљ ∞О„ВА÷«ƒ№уwЈ÷є§≈дЇѕ“Љ∆рЌк≥…»ќД’£ђй_‘і…зЕ^“≤”–„МґаВАOpenClawЈ÷є§ї•ѕаЌ®–≈Еf„чµƒЗL‘З£ђµЂяА≤ї «ћЂЌї≥ц°£
£®ќй£©OpenClawµƒ»±ѕЁ « ≤ьN£њ
“‘…ѕљвбМЅЋOpenClawµƒя\„ч‘≠јн£ђњі…ѕ»•Ї№ЕЦЇ¶°£µЂ“™ЖЦЋьМ¶ќ“”–…ґ”√£њќ“ђF‘ЏµƒљY’У «£ЇяАЫ]ћЎДe”–”√£ђ„оіуµƒ ’Ђ@ «МWЅХ‘≠јн°£љ^іуґаФµХrйg£ђќ“ґЉ‘Џ°∞Ћ≈Їт°±я@÷їќr£ђ“тЮй”–ХrЋьМН‘ЏћЂ≤їњњ„VЅЋ°£
јнљв‘≠јн“‘бб£ђќ“ВГ÷™µј£ђЋьƒ№ёkЌ¶ґа ¬°£µЂќ“”^≤мЅЋґаВА»ќД’“‘бб£ђµ√≥цЅЋ≤їћЂЇ√µƒљY’У£Їя@ «“ЉВА“‘°∞–ќ љ÷чЅx°±Юй„оЄя‘≠ДtµƒAI÷ъјн£ђМНў|ƒ№Ѕ¶ЌщЌщ≤ї––£ђ„оіуЖЦо} «≤їњњ„V°£∆дМНњіЋьµƒЋгЈ®‘≠јн“≤ƒ№√ч∞„£ђя@ЈNљMЇѕ≥цБнµƒЅч≥ћ£ђлS±г“Љ≈№ƒ№њњ„V≤≈“КєнЅЋ°£
іуƒ£–Ќ±Њ…нЊЌ”–ї√”X£ђµЂ¬э¬эњњ„VЅЋЇ№ґа£ђ÷ї“™–°–ƒ£ђ“—љЫЋг «ƒ№њЎ÷∆µƒ–°ЖЦо}ЅЋ°£ќ“”√KimiµƒЅƒћм°Ґ…оґ»—–Њњ°Ґcode°ҐќƒЩnµ»є¶ƒ№£ђМ¶»’≥£є§„ч…ъїоОЌ÷ъЇ№іу°£я@–©є¶ƒ№”–іуƒ£–ЌєЂЋЊ≤їФа—–ЊњГЮїѓ£ђ±нђF‘љБн‘љЇ√ «њ…“‘оA∆Џµƒ£ђњ…њњ–‘я^ЅЋйTЩС“‘бб£ђЊЌ’жµƒЇ№”–”√ЅЋ°£
ќ“ВГњіOpenClawЌк≥…µƒ»ќД’£ђіуƒ£–Ќ“™”√‘Sґаіќ£ђяА“™OpenClawЇЋ–ƒБн÷чМІ£ђ“™’{”√ґаЈNskills£ђ“™њВљYЁФ≥ц°£ЄчЈN»ќД’оР–ЌґаЈNґаШ”£ђ÷–йgƒƒ“Љ≤љ≥цЖЦо}£ђ„оббµƒљYєыЊЌњ…ƒ№Ї№лx„V°£
“ЉВАЗј÷ЎЖЦо} «£ђіуƒ£–Ќ”–ШOПКµƒ°∞–ќ љ÷чЅx°±ЊО‘мƒ№Ѕ¶°£“ЉВАЇ√ґа≤љµƒЅч≥ћ£ђ÷–йgЇ№”–њ…ƒ№ ІФ°£ђ»зє…ГrЊWљj≤й’“ ІФ°°Ґя\Д”ЖT–≈ѕҐ≤й’“ ІФ°£ђїт’я±н√ж≥…є¶ЅЋМНлH «еeµƒ£ђ»з’“ЅЋ“‘«∞µƒјѕ–≈ѕҐ°£µЂіуƒ£–Ќ≤їє№£ђЋьѕ»ЭM„г–ќ љ÷чЅx£ђЫ]”––≈ѕҐ£ђЋь„‘ЉЇЊО£°
јэ»з3‘¬11»’я@–©я\Д”ЖTµƒ±»ўРѕыѕҐ£ђ”––© «ЇъЊОµƒ£°аНЪJќƒЇЌЌх–ји§МНлHґЉЁФЅЋ°£”–µƒХrйgеeБyЅЋ£ђ∞—2025ƒкµƒѕыѕҐ∞l≥цБнЅЋ°£“тЮйkimi_searchµ»Ћ—Ћчє§Њя≤ї“Љґ®њњ„V£ђЋ—Ћч÷ї «ЈµїЎ“Љ–©–≈ѕҐ£ђБK≤їƒ№≈–ФаЇѕ≤їЇѕяm£ђ”–Хr“≤Хю ІФ°°£OpenClaw’{”√іуƒ£–ЌЫQ≤яЌ∆јн£ђґ®°∞є§„ч”ЛДЭ°±µƒХrЇт£ђ”–ХrХюƒ√≥ц°∞Ћ—Ћч ІФ°„‘ЉЇЊО°±µƒ°∞Їэ≈™°±ЈљЈ®°£
я@Ш”µƒ»ЋоРЖTє§£ђ»зєы±ї∞lђFЅЋњѕґ®й_≥эЅЋ°£µЂќ“Ы]ёkЈ®£ђяАµ√»•ѕлёkЈ®Ћ≈ЇтЋь£ђ≈™√ч∞„ЈЄ…µµƒ‘≠“т£ђѕлёkЈ®∞—ЁФ≥ц≈™’эі_°£
‘УИD±нЮйAI÷∆„ч ’ИљYЇѕќƒ’¬Г»»Ё„цЕҐњЉ
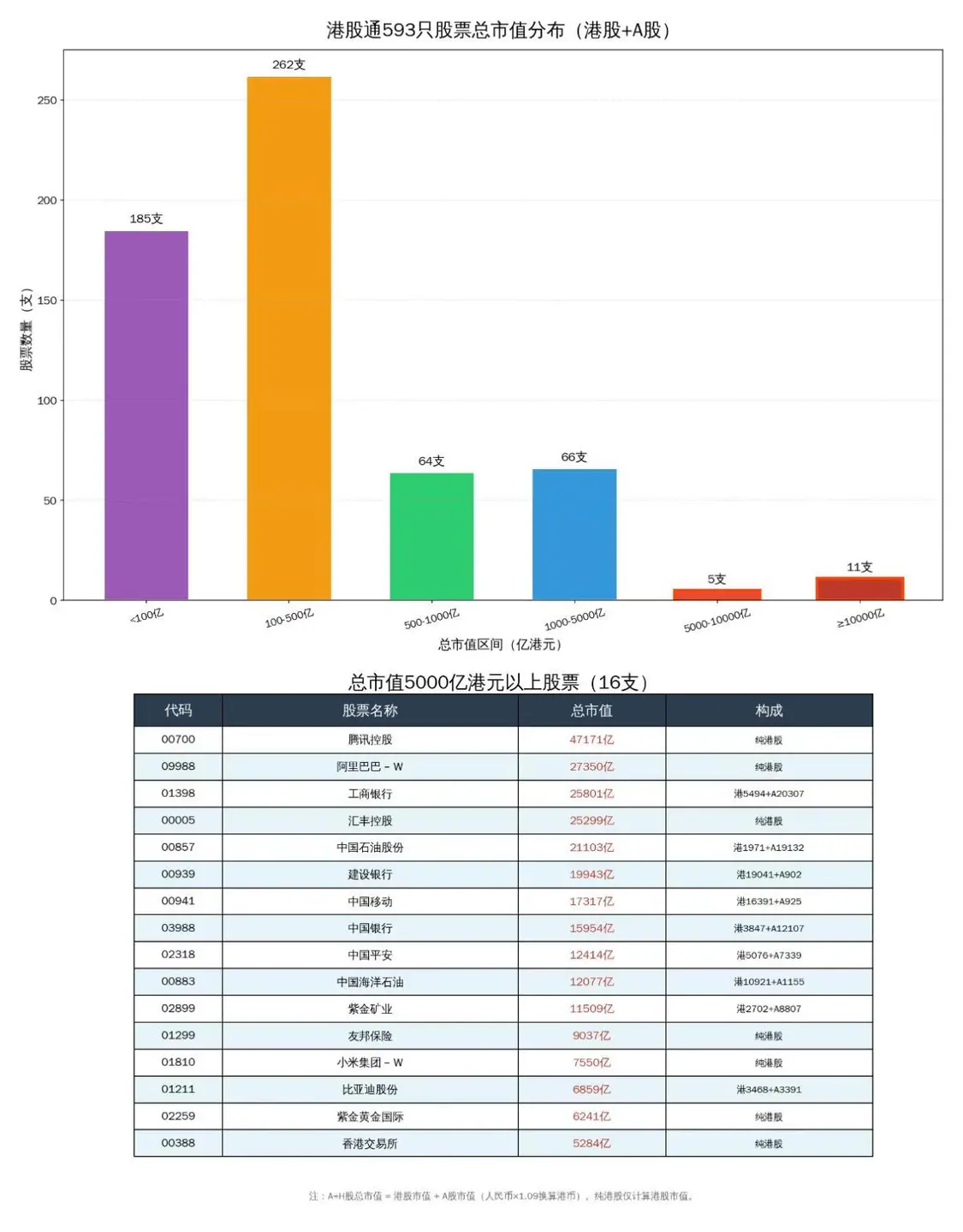
јэ»зќ“„МKimiClaw…ъ≥…Єџє…Ќ®593÷їє…∆±µƒ –÷µЈ÷≤ЉИD°£“Љй_ Љп@ ЊЭh„÷≤їМ¶£ђћб ЊббЋьяА„‘ЉЇѕ¬ЁdЭh„÷„÷ОмљвЫQЅЋЖЦо}£ђЃЛ≥цИDБн£ђѕсƒ£ѕсШ”µƒ°£µЂќ“‘ў„–ЉЪњі£ђЌк»Ђ≤їМ¶£ђя@–©є…∆±µƒ –÷µґЉ «ЇъЊОБy‘мµƒ£°“≤≤ї «Ќк»ЂЇъЊО£ђяАЊОµ√ЇЌ’жМНФµ„÷”–ьcљ”љь°£ґшя@ВА –÷µЈ÷≤Љ÷щИD“≤ «≤їМ¶µƒ£ђ“тЮй –÷µґЉ≈™еeЅЋ°£ќ“ЖЦЋь‘хьNїЎ ¬£ђЋьћє∞„ «“тЮйЊWљjЋ—Ћч’“≤їµљ –÷µФµУю£ђЊЌ„‘ЉЇЊОЅЋ°£
‘УИD±нЮйAI÷∆„ч ’ИљYЇѕќƒ’¬Г»»Ё„цЕҐњЉ
ќ“≤їФаѕлёkЈ®„МЋьЄƒяM£ђ»зљoЋь’“њњ„Vµƒє…∆±–≈ѕҐAPI£ђЋь…х÷Ѕѕл„Мќ“љї“Љƒк…ѕ«І»•љ”»л“ЉВАЎФљЫAPI°£Єґ≥ц∆Dњаµƒ≈ђЅ¶£ђ’“µљтv”НЎФљЫAPIњ…“‘ЈµїЎњњ„V–≈ѕҐ£ђ„МЋь„цЅЋ“ЉВА°∞Єџє…Ќ®–≈ѕҐ≤й‘Г°±skill£ђ≤≈∞—ИDЃЛ≥цБнЅЋ°£ ≤ьNљ– –÷µ£ђ“≤–и“™љoЋьґ®Ѕx£ђ“тЮй”––©є… «Aє…≈cЄџє…ґЉ…ѕ –µƒ£ђ –÷µС™‘У «Єч„‘…ѕ –µƒє…±ЊЈ÷Дe≥Ћ“‘Aє…°ҐЄџє…µƒє…Гr‘ўѕаЉ”°£µЂќ“„ољь∞lђF„ољK„ц≥цµƒИDяА «”–ЖЦо}£ђ’f –÷µ5000Г|Єџ‘™“‘…ѕµƒє…∆±16÷І£ђµЂМОµ¬Хrіъ≤ї“КЅЋ°£
ќ“ЅЋљв“Љ–©іуƒ£–ЌЋгЈ®‘≠јн£ђ‘Џ»’≥£ є”√іуƒ£–ЌµƒХrЇтЊЌЈ«≥£„Ґ“вї√”X°ҐЊО‘мµ»ЖЦо}°£я@Јљ√жЖЦо}Ї№іу£ђ»ЋВГЈ«≥£»Ё“„…ѕЃФ£ђЊWљj…ѕ“—љЫ”–Ј«≥£ґаіуƒ£–ЌЊО‘мµƒГ»»Ё°£‘Џ є”√OpenClawµƒХrЇт£ђќ“∞lђFї√”X°ҐЊО‘мµƒЖЦо}“™Зј÷Ўµ√ґа£ђ“™ЄьЉ”–°–ƒ°£
ЃФќ“ВГ∞lђFіуƒ£–Ќ≤їњњ„VµƒХrЇт£ђ÷Є≥цБнЖЦо}£ђЋьЌщЌщƒ№„‘ЉЇЄƒ’э°£µЂ «£ђOpenClaw≥цеeЅЋ£ђ“™»•–ёЋь£ђ“™лyµ√ґа°£»зєыЫ]”–“Љґ®ЋЃ∆љ£ђЌщЌщЊЌ≤їћЂ»Ё“„”√Ї√OpenClaw£ђМНлHЖЦо}Ј«≥£ґа°£”–Хrњі÷шљYєы≤їеe£ђµЂ≤ї“Љґ®њњ„V£ђяА «–и“™ґаЉ”–°–ƒ°£”––©”√СфЈіС™£ђ”√OpenClaw„ц»ќД’≤їлy£ђµЂ≤йЋьњњ≤їњњ„VЇ№јџ£ђќ““≤”–ЌђЄ–°£
Пƒ‘≠јн…ѕБн’f£ђƒњ«∞М¶OpenClaw’ж≤їƒ№ћЂя^–≈»ќ°£∞—÷Ў“™µƒВА»Ћ–≈ѕҐ°ҐЎФљЫ–≈ѕҐ£ђїт’яє§„чЖќќї–≈ѕҐ„МOpenClaw’∆ќ’£ђЄь «Ј«≥£ќ£лU£ђ∞≤»Ђ¬©ґіШOіу°£“—љЫ≥цЅЋ≤ї…ў ¬ЅЋ£ђљр»ЏєЂЋЊ°Ґ÷ЎьcЖќќї°Ґ“Љ–©…ѕ –єЂЋЊ£ђґЉ√чі_“™«у≤ї‘S‘ЏЖќќїлКƒX…ѕ—bOpenClaw°£∞≤»ЂЈљ√жµƒ¬©ґієP’я≤їћЂ мѕ§£ђµЂЄ≈ƒо…ѕњѕґ® «¬©ґіШOіу£ђ”–≤ї…ўќƒ’¬÷Є≥ц°£OpenClaw≤ї…ўД”„чµ»мґ‘Џї•¬УЊWЯo±£„oµљћОїоД”£ђЮйЅЋЌк≥…»ќД’’“ќ““™ЅЋ“Љ–©–≈ѕҐ£ђ «”–ќ£лU°£
єP’яяА «ѕлћЎДeПК’{°∞њњ„V°±я@ВА ¬°£”–“Љ–©OpenClawЅч≥ћ£ђѕакPSkill’ыјнµ√≤їеe°ҐѕакPї•¬УЊW–≈ѕҐЈюД’њњ„V°Ґїщ„щіуƒ£–Ќƒ№Ѕ¶„гЙт£ђі_МНƒ№ЙтО÷“Љ–©їо°£я@–©јэ„”њѕґ®“≤ «Ї£Ѕњµƒ£ђµЂ±ЎнЪ÷Є≥ц£ђя@≤ї «Пƒћм…ѕµфѕ¬Бнµƒ£ђ≤ї «OpenClawй_‘іЅЋЊЌ”–£ђґш «–и“™ѕаЃФґаµƒй_∞l‘Зеe°Ґ’ыјніт∞ьµƒє§„ч°£
’эі_µƒјнљв «£ђOpenClaw «“ЉВАй_∞lњтЉ№£ђЋь„М»Ћ”√„‘»ї’Z—‘÷ЄУ]О÷ ¬£ђЅҐњћЊЌ”–љYєы£ђљo»ЋЇ№іуµƒ’рЇ≥°£µЂ «£ђ»зєы“™„МЋьО÷њњ„Vµƒ ¬£ђЊЌЇЌ»ЋоРМWЅХЊО≥ћ’Z—‘“ЉШ”£ђ–и“™≤ї…ўїщµA÷™„R£ђ“™Хю√жМ¶ЄчоРеe’`£ђƒЌ–ƒµЎ°∞рBќr°±°£»зєы≤їХюрB£ђЊЌХю∞lђFя@Ц|ќчБKЫ]”–ƒ«ьNЇ√Ќж£ђЊЌЇЌ“Љ–©»ЋЊО≥ћМW≤їѕ¬»•“ЉШ”°£
Єя ÷М¶OpenClaw‘≠јн≈cЉ№ШЛЇ№ЅЋљв£ђМ¶“™О÷µƒ ¬Ї№ЅЋљв£ђМ¶’{”√µƒє§Њя“≤ЅЋљв£ђ“≤Хю„‘ЉЇй_∞lskills£ђ∞—ѕакP≠hєЭґЉ’{‘Зµ√„гЙтњњ„VЅЋ£ђЊЌƒ№љMњЧ≥ц“Љ–©≤їеeµƒ„‘Д”є§„чЅч≥ћ°£µЂ”–я@ВАЋЃ∆љµƒЄя ÷£ђƒњ«∞яА≤їґа°£
Ї№ґа»ЋўIлКƒXїт’ялЕ…ѕ—bЅЋэИќr“‘бб£ђЊЌ”––©√£»їЅЋ£ђ≤ї÷™µјƒ№О÷…ґ£ђѕ£Ќы±ЊќƒМ¶≤їЅЋљвOpenClaw‘≠јнµƒ»Ћ”–ОЌ÷ъ°£њ…“‘»•МWЅХЄя ÷њВљYµƒњњ„VЅч≥ћ£ђƒ£Ј¬МНџ`£ї“≤њ…“‘»•МWЅХ‘≠јн£ђбШМ¶–‘ћб…э є”√AIµƒЋЃ∆љ£ї„обб„‘ЉЇ“≤„Г≥…Єя ÷£ђй_∞lSkill£ђ÷ЄУ]OpenClawљMњЧЅч≥ћ£ђ’ж’э„МAI÷ъјнОЌ÷ъє§„ч…ъїо°£‘Џя@ВАя^≥ћ÷–£ђ“Љґ®“™„Ґ“в£ђOpenClawЇ№≤їњњ„V£ђљ^М¶≤їƒ№√§ƒњѕа–≈£ђ“™”–і_МНµƒ„CУю£ђЄчВА≠hєЭґЉі_’Jњ…њњЅЋ£ђ≤≈њ…“‘Ј≈ ÷„МЋьО÷їо°£
∞жЩа’f√ч / Copyright Notice:
Content and images in this article may originate from third-party sources and are used for news reporting, commentary, or public interest purposes. All copyrights remain with their respective owners. Please refer to the Copyright Notice at the bottom of this page.
±ЊќƒГ»»ЁГHє©–≈ѕҐЕҐњЉ£ђ≤їіъ±н±ґњ…”HЅҐИцїт”^ьc°£
[Љ”ќчЊW’э’–∆Єґа√ы»Ђ¬Ъsales іэ”цГЮ]
| Ј÷ѕн: |
| „Ґ£Ї |
Ќ∆Ћ]: