




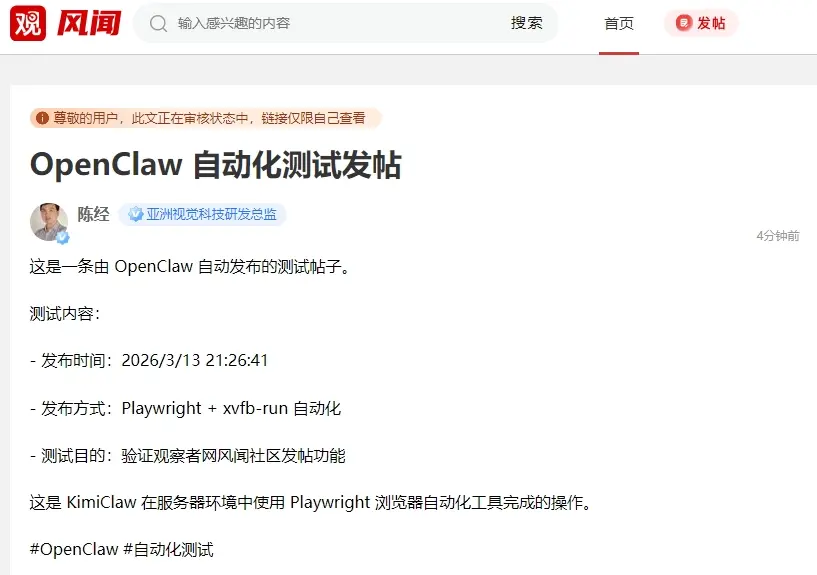
вдЮвЕФЧзЩэЬхбщ,ЬИЬИШчКЮе§ШЗРэНт"бјЯК"
2026Фъ1дТЃЌвЛИіНаClawdbotЕФИіШЫAIжњРэЛ№СЫЃЌЪЧЖРСЂПЊЗЂепPeter SteinbergerЃЈБЫЕУЁЄЪЉЬЉвђВЎИёЃЉ2025Фъ11дТ24ШеДДНЈЕФЁЃвђЮЊУћзжгыAnthropicЕФClaudeДѓФЃаЭНгНќЃЌзїепНЋЦфИФУћЮЊMoltbotЃЌВЂНЈСЂСЫЗЧГЃЛюдОЕФПЊЗЂепЩчЧјMoltbookЁЃ3дТ10ШеЃЌЪеЙКАЎКУепдњПЫВЎИёНЋMoltbookЩчЧјФЩШыЦьЯТЃЌЖјSteinbergerдчдк2дТОЭБЛOpenAIЭкзпЁЃ
БЪепЕквЛЪБМфОЭЙизЂСЫЪТМўЃЌВЂаДЮФЦРТлСЫMoltbotгыЁАвЛШЫЙЋЫОЁБЃЈЗЂдк2дТ6ШеЕФЛЗЧђЪББЈЃЉЃЌНщЩмAIгыжаЙњжЦдьвЕЗжБ№ДгШэгВСНЗНУцЬсЙЉБуНнЗўЮёЃЌЖдгкИіШЫДДвЕКмгавтвхЁЃУЛЯыЕНЕФЪЧЃЌ3дТЪБЖрМвжаЙњЛЅСЊЭјОоЭЗгыДѓФЃаЭЙЋЫОЖМВЮгыНјРДСЫЃЌвЛаЉЕиЗНеўИЎЖМГізЪМЄРјИіШЫПЊЗЂепЃЌШШЖШгы2023ФъГѕЕФChatGPTЁЂ2025ФъГѕЕФDeepSeekПЩвдЯрБШЁЃ
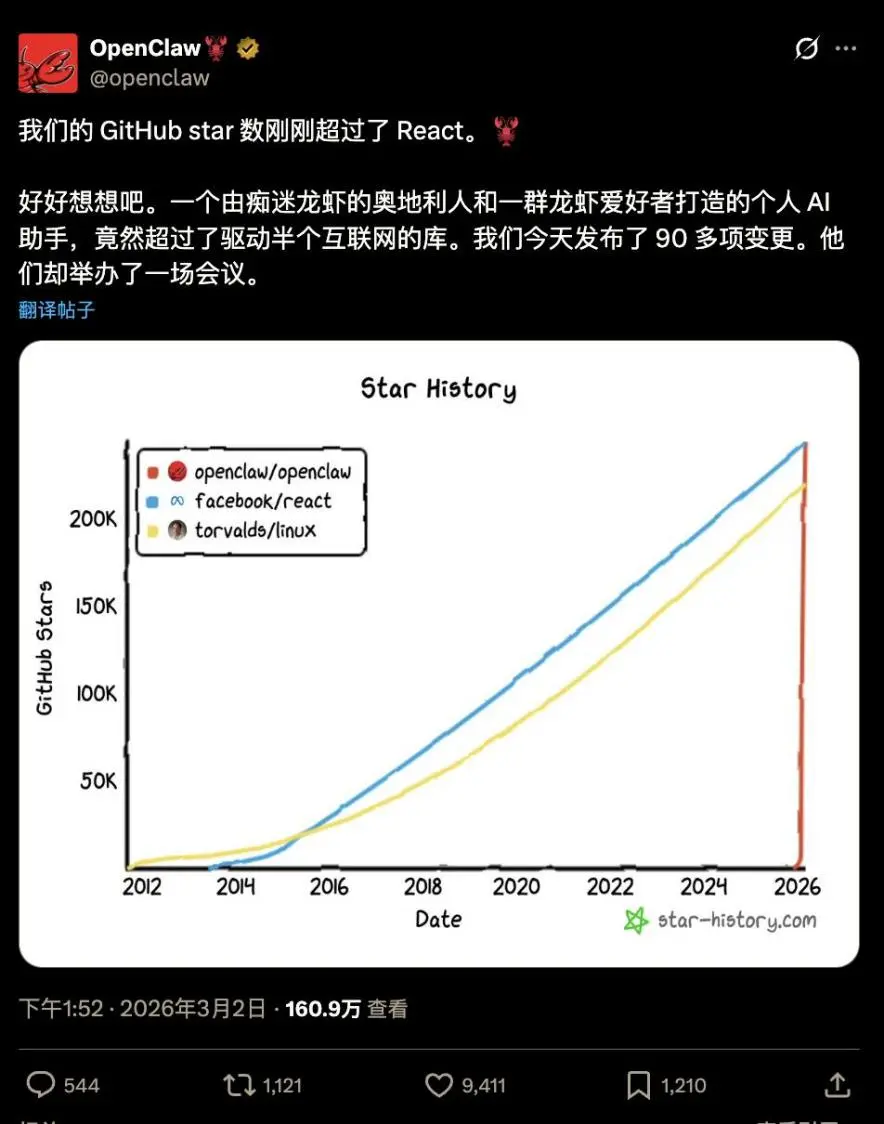
Moltbotгк2026Фъ1дТ30Шее§ЪНИќУћЮЊOpenClawЃЌВЂгк2дТ24ШеГЌЙ§га30ФъРњЪЗЕФLINUXЁЂ3дТ2ШеГЌЙ§ReactЃЌГЩЮЊПЊдДЩчЧјGitHubЪЗЩЯаЧБъзюЖрЕФШэМўЯюФПЁЃНќКѕДЙжБЕФдіГЄЧњЯпГЩЮЊПЊдДШэМўРњЪЗЩЯЕФЦцЙлЁЃ
OpenClawзїЮЊПЊдДЯюФПЃЌЪЙгУгавЛЖЈУХМїЃЌжаЙњАЎКУепгаФмСІздааЯТдиАВзАЕФВЛЖрЁЃKimiClawЪЧжаЙњДѓФЃаЭЙЋЫОзюдчЭЦГіЕФOpenClawдЦЗўЮёЃЌВЛЪЧзАдкИіШЫЕчФдЩЯЃЌЖјЪЧдкдЦЩЯПЊLINUXащФтЛњЃЌАВзАЗНБуЃЌДКНкЧАЭЦГіСЫЪдЕуЁЃКѓУцMaxClawЁЂDuClawЕШИїРрдЦClawВњЦЗдНРДдНЖрЃЌАЂРядЦЁЂЬкбЖдЦЁЂЛЊЮЊ(专题)дЦЁЂЛ№ЩНв§ЧцЁЂОЉЖЋдЦЁЂвЦЖЏдЦЁЂЬьвэдЦЖМЭЦГіСЫЁАвЛМќВПЪ№ЁБНтОіЗНАИЁЃЛЙгаAutoClawЁЂQClawетаЉзїЮЊWindowsЁЂMacOSЕФГЬађАВзААќЃЌзАдкгУЛЇИіШЫЕчФдЩЯЕФЁЃ
етаЉЁАClawЁБЗўЮёЕФЭЦГіЃЌБъжОзХжаЙњAIГЇЩЬе§дкељЖсOpenClawЩњЬЌжїЕМШЈЃЌгы2025Фъ2-3дТИїГЇЩЬЗзЗзВПЪ№НгШыDeepSeekРрЫЦЁЃ
вЛ. ЬНЫїOpenClawЕФЖржжЗНЪН
KimiClawгк2дТ18Шее§ЪНЩЯЯпЃЌБЪепСЂПЬНЛСЫ199дТЗбЃЌаЫГхГхЕиЁАвЛМќАВзАЁБЁЃМИЬьЖМСЌВЛЩЯЗўЮёЦїЃЌгІИУЪЧДКНкУЛЩЯАрЁЃ2дТ22ШеЪєгкБЪепЕФKimiClawжегкЛюСЫЃЌАДЬзТЗЩшжУСЌЩЯЗЩЪщвдКѓЃЌПЩвдЫГГЉЪЙгУСЫЁЃБЪепЕФаЫШЄЪЧСЫНтOpenClawЕФМмЙЙгыдРэЃЌетЗНУцгавЛаЉаФЕУЃЌЖдгкЦфгХЪЦгыШБЯнЕФИљдДвВНЯЮЊЧхГўЁЃ
БОЮФЖдOpenClawНјаадРэадММЪѕНтЪЭЃЌЛсЦеМАвЛаЉЛљДЁИХФюЁЃИќживЊЕФЪЧьюїШЃЌе§ШЗШЯЪЖетжЛШШЖШПеЧАЕФЁАСњЯКЁБЃЌВЛЩёЛЏЦфЙІФмЃЌСЫНтЦфОоДѓЕФЧБСІгыБОжЪШБЯнЁЃ
жаЙњвбОНгЩЯOpenClawЕФгУЛЇЃЌвЛАуКЭЫќгаСНИіНЛЛЅЧўЕРЁЃвЛИіЪЧЗЩЪщЕШЪжЛњМДЪБЭЈбЖAPPЃЌЩЯУцМгСЫClawЛњЦїШЫЃЌСФЬьЯТДяжИСюЁЂНгЪеЮФМўЃЌЯраХЮЂаХВЛОУвВЛсДѓЙцФЃНгШыЁЃЦфдРэЪЧЃЌЗЩЪщЛсЬсЙЉAPIНгШыАьЗЈЃЌOpenClawгаСЫAPIШЈЯовдКѓЃЌОЭПЩвдКЭЗЩЪщЭЈаХЃЌНгЪежИСюЁЂЗЕЛиНсЙћЁЃетвВЪЧSteinbergerПЊЗЂOpenClawЕФГѕждЃЌЯыгУЪжЛњМДЪБЭЈбЖAPPСЌНгздМКЕФЕчФдЃЌдЖГЬВщПДНсЙћЁЂжИЛгИЩЛюЁЃФПЧАетвВЪЧКЭOpenClawзюжївЊЕФЙЕЭЈЗНЪНЁЃ
ЖдгкдЦЩЯВПЪ№ЕФOpenClawЃЌСэвЛИіГЃгУЧўЕРЪЧДѓФЃаЭЭјвГЛђДѓФЃаЭЪжЛњAPPЩЯЕФСФЬьНчУцЁЃШчБЪепЭјвГЩЯСЫKimiДѓФЃаЭЃЌЩЯУцОЭгаKimiClawНчУцЃЌвВФмСФЬьЯТДяжИСюЁЃвЛПЊЪМжЛгаPCЭјвГАцПЩвдЃЌКѓРДЪжЛњKimi APPвВПЩвдСЫЁЃ
БЪепЬхбщЯТРДЃЌЗЂЯжЖўепгажиДѓЧјБ№ЁЃЗЩЪщЪЧжБСЌKimiClawЃЌНгЪеЕФЪЧOpenClawЕФжДааНсЙћЃЌФмЪеЮФМўЁЃЗЩЪщЩЯЕФСФЬьвВОЙ§ДѓФЃаЭДІРэЪЧжЧФмЕФЃЌЕЋгЩгкЪЧЗЧМДЪБЙЕЭЈЃЌЪмЯогкЗЩЪщAPIЕФИёЪНгызжНкЯожЦЃЌаХЯЂЗЂЫЭвЊбЙЫѕЃЌаХЯЂКЌСПгаЯоЃЌР§ШчПДВЛЕНДѓФЃаЭЕФЫМПМЙ§ГЬЁЃЖјдкKimiЭјвГЛђепKimiЪжЛњAPPЩЯЃЌЪЧжБНггыKimiДѓФЃаЭСФЬьЃЌжївЊФкШнЪЧДѓФЃаЭЪфГіЕФЃЌгаЫМПМЙ§ГЬЃЌаХЯЂУїЯдИќЗсИЛЃЛЦфжаМадгСЫвЛаЉOpenClawжДаажИСюЕФНсЙћЃЌЕЋЮФМўЪеВЛСЫЃЌашвЊЗЂЕНЗЩЪщЩЯЁЃБЪепбЁдёгыДѓФЃаЭжБНгСФЬьЕФФЃЪНЃЌвдЗЩЪщЪеЮФМўЮЊИЈжњЁЃетбљФмбЇЕНКмЖрЖЋЮїЃЌПЩвджБНгЬсЮЪЃЌГіСЫЮЪЬтДѓФЃаЭФмИјГіЖржжНтОіЗНАИбЁдёЃЌГЂЪдЙ§ГЬПЩМћЃЌЪЧбЇЯАЬНЫїOpenClawВЛДэЕФЗНЪНЁЃ
ИіШЫЕчФдЩЯАВзАЕФOpenClawЃЌвВгаетжжСФЬьНчУцЁЃAutoClawЁЂQClawЗтзААцЕФЛсгаЭъећзРУцПЭЛЇЖЫЃЌЛсЬсЙЉЖдЛАПђЁЃетжжФЃЪНЃЌгЩгкИіШЫЕчФддЫаазДЬЌЁЂДѓФЃаЭAPIЖМФмжБНгВщПДПижЦЃЌФмЬсЙЉИќЮЊЗсИЛЕФдЫааЯИНкаХЯЂЁЃ
БЪепЮЊСЫРэНтOpenClawМмЙЙгыдРэЃЌЛЙгавЛжжзюжБНгЕФЁАЬНЫїЁБАьЗЈЃЌОЭЪЧНјШыKimiClawЁАОгзЁЁБЕФLinuxащФтЛњжеЖЫЃЌЪЧUbuntu 24.04ЯЕЭГЃЌKimiClawЭјвГАцЬсЙЉСЫШыПкЁЃШчЙћЖдLinuxВйзїЯЕЭГгыУќСюНЯЮЊЪьЯЄЃЌОЭПЩвдШЅзаЯИПДПДЮФМўНсЙЙЃЌжДааЖржжЕзВуУќСюЃЌВ№НтOpenClawжДааШЮЮёЕФЙ§ГЬЁЃШчЖдгкOpenClawЕФSkillsЁЂMemoryетаЉЁАММФмЁБЁЂЁАМЧвфЁБЯрЙиЕФживЊВПМўЃЌПЩвджБНгВщПДЯрЙиЮФМўФкШнЃЌДгзюЕзВуНвУиЁЃ
ЕЋетжжЬНЫїАьЗЈашвЊЯрЕБЕФLinuxжЊЪЖЃЌСЌЭМаЮВйзїНчУцЖМУЛгаЃЌЪѓБъЭъШЋЮогУЃЌашвЊЪфШыаэЖрУќСюЁЃШчЮоОбщЛсФбвдВйзїЃЌМДЪЙаДЮФеТСаГіВйзїЯИНкЃЌвВВЛКУРэНтЁЃШчЙћЪЧИіШЫЕчФдЩЯзАЕФOpenClawЃЌвВПЩвджБНгШЅЕчФдРяЙлВьФПТМЮФМўНсЙЙЃЌЭЌбљгаФбЖШЁЃвђДЫЃЌБЪепНіНщЩмдРэЃЌТдЙ§ВЛКУЖЎЕФЬНЫїЙ§ГЬЯИНкЁЃ
БЪепЛљгкЖдOpenClawЕФЕзВуРэНтЃЌИјГіЕФдРэадНтЪЭЃЌЯЃЭћФмДгСэвЛИіНЧЖШЃЌАяжњЖСепРэНтЁЃЯТУцвдЮЪД№ЕФаЮЪНЃЌНјааНтЪЭЁЃ
ЖўЃЎOpenClawдРэЮЪД№
ЃЈвЛЃЉДгГЬађДњТыНЧЖШПДЃЌOpenClawЛЙдЕНЕзВуЃЌЕНЕзЪЧЪВУДЖЋЮїЃП
OpenClawЪзЯШЪЧвЛИіПЊдДГЬађЃЌдкGitHubЩЯгаЙЋПЊЕФЪЧдДДњТыВжПтЃЌзюдЪМЕФРэНтОЭЪЧЙЋПЊЕФДњТыЁЃЫќПЩвдЁАВПЪ№ЁБЕНИїРрИіШЫPCЩЯЃЌвВПЩвдВПЪ№ЕНдЦЩЯдЫааЦ№РДЁЃгыШЫНЛЛЅЃЌОЭЪЧШЫУЧЬ§ЫЕЕФAIИіШЫжњРэЃЌФмВйзнИіШЫPCЛђепдЦЩЯЕФащФтжїЛњИЩЛюЃЌетБЛЯЗГЦЮЊЁАбјЯКЁБЁЃ
OpenClawЪЧПЊдДЙЄГЬЃЌЫќФмдкWindowsЁЂMacOSЁЂLinuxЕШЖрИіЦНЬЈгІгУЃЌЩѕжСЛЊЮЊКшУЩвВжЇГжВПЪ№ЁЃЮвУЧЯШашвЊУїАзЃЌЫќЕФДњТыгаЁАПчЦНЬЈЁБЬиадЁЃдвђЪЧЃЌЫќЕФПЊЗЂгябдЪЧTypescriptЃЈБрвыГЩJavascriptЃЉЃЌJavaгябдСїааОЭЪЧвђЮЊПчЦНЬЈЃЌзюГЃМћЕФЪЧфЏРРЦїЭјвГГЬађЁЃгаЯрЕБГЄЪБМфЃЌJavascriptЪЧГЬађдБгУЕУзюЖрЕФПЊЗЂгябдЃЌЛ§РлСЫЗсИЛЕФПЊЗЂЩњЬЌЁЃOpenClawЩцМАИДдгЕФЖдЯѓНсЙЙЃЌTypescriptгябдФмдкаДДњТыЪБОЭЗЂЯжЮЪЬтЃЌЖјВЛЪЧЕШдЫааЪББРРЃЁЃДѓаЭПЊдДЯюФППЊЗЂепЃЌЭљЭљЯВЛЖетИігябдЕФЛљгкРраЭЃЈTypeЃЉЕФЁААВШЋИаЁБЁЃ
OpenClawЕФПЊЗЂЛЗОГНаNode.jsЃЌВЛЪьЯЄетИіДЪЕФШЫвВВЛФбРэНтЁЃдкWindowsЁЂMacOSЁЂLinuxЁЂКшУЩжаЖМгавЛИіГЬађУћзжНаЁАnodeЁБЃЌИїздВЛЭЌЃЌЪЧЯЕЭГЪТЯШПЊЗЂКУЕФЁЃМйЩшЮвУЧаДСЫвЛИіГЬађНаapp.jsЃЌИїРрВйзїЯЕЭГЩЯЖМПЩвдЭЈЙ§УќСюЁАnode app.jsЁБГЩЙІжДааЃЌвЛЬзДњТыЖрИіЦНЬЈЖМФмХмЁЃ
OpenClawвЊХмЦ№РДЃЌЛЙашвЊвЛаЉБ№ШЫПЊЗЂЕФЗЧГЃживЊЕФвРРЕАќЁЃетОЭЪЧПЊдДЕФКУДІЃЌБ№ШЫПЊЗЂЕФПЩвджБНгФУЙ§РДгУЃЌзщКЯГіИќКУЕФаТЙІФмЁЃетаЉвРРЕАќвВЖМЪЧNode.jsПЊЗЂЛЗОГРяФмХмЕФЁЃгІгУNode.jsвРРЕАќЃЌгаИіживЊЗжЗЂЙЄОпnpmЃЌгУЁАnpm installЁБУќСюОЭФмВПЪ№КУЁЃетКЭLinux UbuntuВйзїЯЕЭГРяЕФЁАapt installЁБРрЫЦЃЌЬсЙЉСЫЗНБуЕФАВзАЗНЪНЁЃ
ПЩвдЫЕЃЌOpenClawга80%ЕФЙІФмЖМЪЧЁАеОдкnpmАќМчАђЩЯЁБЪЕЯжЕФЃЌжЛга20%ЕФвЕЮёТпМЃЈЕїЖШЁЂМЧвфЁЂАВШЋИєРыЕШЃЉЪЧздМКаДЕФЁЃ
СэЭтЃЌOpenClawЛЙНЈСЂСЫздМКЬигаЕФПЊдДЙІФмРЉеЙЯЕЭГЃЌОЭЪЧВЛЩйШЫЬ§ЫЕЙ§ЕФSkillЁЃSkillЫуЪЧЬиЪтЕФnpmАќЃЈПЩвдгУnpmАВзАЃЉЃЌЕЋOpenClawИјЫќМгСЫБъзМЛЏНгПкЁЂMCPавщЪЪХфВуЃЈШУДѓФЃаЭФмЕїгУЃЉЁЂClawhubЗжЗЂЧўЕРЁЃClawhubРрЫЦnpmвЛбљЗжЗЂSkillЃЌЕЋзЈЮЊAIЙЄОпЩшМЦЁЃПЩвдАбSkillРэНтГЩnpmАќЃЌЕЋМгЩЯСЫИјAIЕФЁАЪЙгУЫЕУїЪщЁБЃЌДѓФЃаЭФмЙЛИќЫГГЉЕиЙцЛЎШУSkillИЩЛюЁЃ
ШчЙћИіШЫвЊдкздМКЕФЕчФдЩЯВПЪ№OpenClawЃЌЯШвЊзАЩЯNode.jsПЊЗЂЛЗОГЁЂХфжУЛЗОГБфСПЃЌетОЭШАЭЫСЫОјДѓВПЗжШЫЁЃ3дТ6ШеЬкбЖдЦдкЩюлкЬкбЖДѓЯУТЅЯТАкЬЏЭЦГіЁАСњЯКАВзАеОЁБЃЌ20ЮЛЙЄГЬЪІУтЗбАяТЗШЫдкИіШЫЕчФдЩЯВПЪ№OpenClawЁЊЁЊОЭЪЧДгетвЛВНПЊЪМЃЌШЗЪЕашвЊММЪѕШЫдБГіЬЏЁЃ
етвЛНкПДЕУУдК§ВЛвЊНєЃЌжЊЕРгаетаЉУћДЪОЭааСЫЁЃвдКѓЙРМЦЛсГЩЮЊЩчЛсГЃЪЖЃЌЬ§ЖрСЫТ§Т§ФмУїАзЁЃ
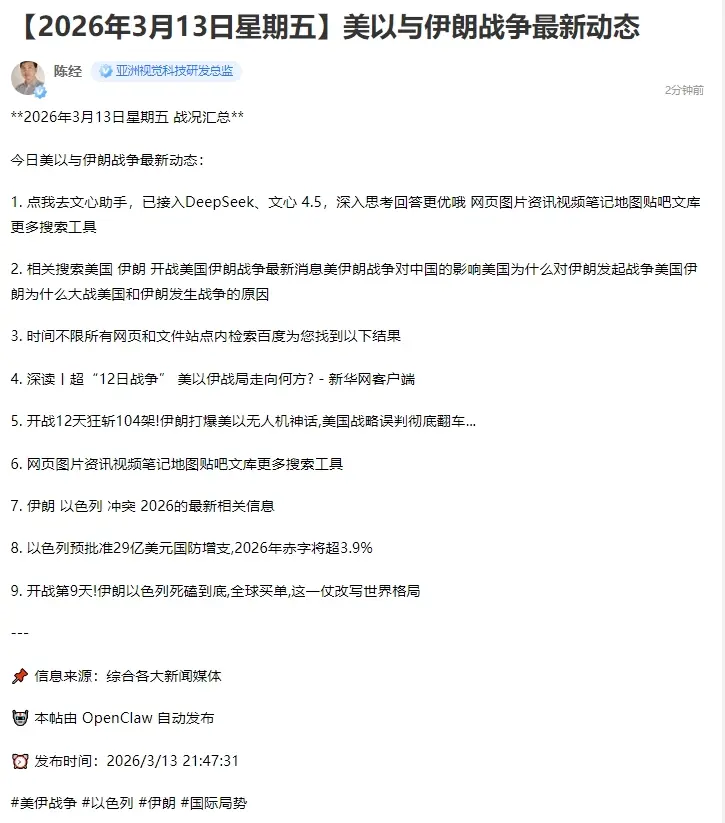
ЃЈЖўЃЉжаЙњаэЖрЙЋЫОГіЪжКѓЃЌOpenClawЮЊКЮШнвзВПЪ№СЫЃП
2025ФъГѕБЌЛ№ЕФТњбЊАцЕФDeepSeek-R1ЃЌИіШЫВЛПЩФмВПЪ№ГЩЙІЁЃЕЋжаЙњЖрМвЙЋЫОЖМНгШыСЫЃЌЛЙНјааСЫв§СїЃЌМДЪЙDeepSeekЙЋЫОБОЩэЕФЗўЮёМЗБЌСЫЃЌШЫУЧвВгУЩЯБ№МвВПЪ№ЕФDeepSeekЁЃетДЮOpenClawШШГБЃЌжаЙњЯыдкAIЩњЬЌРяеМЮЛЕФЙЋЫОЃЌЖМЛсРДВЮгыЃЌШУгУЛЇдкздМКЕФЦНЬЈжагУOpenClawЁЃетЪЧжаЙњЙЋЫОЩУГЄЕФЃЌУцЯђДѓжкЕФНчУцБиаыгбКУвзгУЃЌВЛШЛУЛЗЈЭЦЙуЁЃ
ГЃМћЕФАьЗЈЪЧдЦЖЫИјгУЛЇПЊвЛИіащФтLinuxжїЛњЃЌОЭЪЧKimiClawетбљЁЃаэЖрЙЋЫОЖМЭЦГіСЫЃЌКУДІЪЧгУЛЇВЛашвЊгаИіШЫЕчФдЃЌБмУтСЫИіШЫЕчФдБЛЭцЛЕЁЂаХЯЂаЙТЖЕШТщЗГЁЃетжжФЃЪНПЩвдвЛМќАВзАЃЌгУЛЇжБНгЪЙгУАВзАКУЕФOpenClawдЦЗўЮёЃЌЕЋвЛПЊЪМРяУцЪВУДИіШЫЕФЮФМўЖМУЛгаЁЃ
СэвЛИіАьЗЈЃЌЪЧжЧЦзЕФAutoClawФЧбљЃЌАбOpenClawДђАќГЩДЋЭГзРУцШэМўЃЌвўВиЕєNode.jsЕФДцдкЃЌдкгУЛЇИіШЫЕчФдЩЯАВзАЁЃЫќОЭЯёДЋЭГWindowsГЬађвЛбљЩЕЙЯЪНАВзАЃЌВЛвЛбљЕФЪЧЃЌЫќЛсздМКВйзнЕчФдгУ1ЗжжгЩшжУКУЗЩЪщЛњЦїШЫЁЃетжжФЃЪНЃЌгУЛЇЕФИіШЫЕчФджБНгОЭгаOpenClawСЫЃЌИЩЛюИќЮЊЗНБуЃЌЕЋГіЪТСЫвВИќЮЊЮЃЯеЁЃ
ММЪѕадЕиЫЕЃЌащФтLinuxжїЛњРяЕФOpenClawФмСІЛсБШеце§ИіШЫЕчФдРяЕФВювЛаЉЁЃБЪепШЗЪЕЗЂЯжKimiClawгаКмЖрТщЗГФбгУжЎДІЃЌдРэЩЯОЭВЛЪЧПЩЪгЛЏЕФЃЌвВУЛгаЩљвєЁЃдйШчдЦЩЯИјИіШЫЕФПеМфжЛга40GЃЌИіШЫЕчФдгВХЬвЊДѓЕУЖрЁЃЛЙгаШеГЃЕФЗЂгЪМўжЎРрЕФЙЄзїСїГЬЃЌИіШЫЕчФдЬьШЛОЭгаЃЌOpenClawФмздШЛНгДЅЃЌдкащФтLinuxжїЛњДгЭЗНЈСЂЙЄзїСїГЬКмВЛШнвзЁЃЕЋЮоТлШчКЮЃЌгаЪЕСІЕФЙЋЫОЬсЙЉЕФдЦЩЯЗўЮёЪЧИіКУЪТЃЌШУШЫФмНЯЮЊЗНБуЕиНгДЅOpenClawЃЌФмНЈСЂаТЕФСїГЬЃЌвВЪЧШУШЫаЫЗмЕФЁЃ
ашвЊзЂвтЃЌетЪЧжаЙњЬигаЕФЯжЯѓЃЌДѓСПЦеЭЈШЫвВгаАьЗЈЪдЪдOpenClawЁЃдкХЗУРЃЌЛљБОжЛЪЧММЪѕДгвЕепКЭАЎКУепКмПёШШЃЌЦеЭЈШЫвђЮЊАКЙѓЗбгУЁЂвўЫНБЃЛЄЕШЮЪЬтгУВЛЩЯЁЃетЪЧЮвУЧдкжаЙњЬигаЕФЁАММЪѕИЃРћЁБЁЃ
ЃЈШ§ЃЉOpenClawППЪВУДИЩЛюЕФЃП
OpenClawВЂВЛЪЧвЛАуЕФШэМўЃЌашвЊИЩГЩвЛаЉгаЕуММЪѕКЌСПЕФЛюЃЌВХЛсШУММЪѕЩчЧјВњЩњХЈКёаЫШЄЃЌв§БЌШЋЧђЁЃБЪепдкЙлВьепЭјЗчЮХЩчЧјздЖЏЗЂЬћВтЪдГЩЙІЃЌПЩвдгУетИіАИР§РДОйР§ЫЕУїЁЃ
OpenClaw здЖЏЛЏВтЪдЗЂЬћ_ЗчЮХ (guancha.cn)
ЯШШУOpenClawздЖЏЗЂСЫИіВтЪдЬљЁЃетвЛВНЦфЪЕКмВЛШнвзЃЌвђЮЊЮвЪЧгУKimiClawдЦЗўЮёЃЌУЛгаПЩЪгЛЏЕФЦСФЛЁЃашвЊКУМИВНЃЌЖЏгУСЫвЛаЉЙЄОпЃЌВХФмЭъГЩЗЂЬљЁЃ
ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪ(专题)еНељзюаТЖЏЬЌ_ЗчЮХ (guancha.cn)
дйШУKimiClawЗЂвЛИіУРвдгывСРЪеНељЖЏЬЌЬљЃЌздааЪеМЏФкШнЁЃПЩвдПДГіФкШнКмдуИтЃЌЪЧOpenClawЫбИїДѓУНЬхЕФБъЬтЦДДеЃЌгаЕФКЭеНељКСЮоЙиЯЕЃЌФкШнУЛЪВУДжЧФмПЩбдЁЃ

ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪеНељзюаТЖЏЬЌЗжЮі_ЗчЮХ (guancha.cn)
ШУKimiClawИФгУKimi 2.5ДѓФЃаЭЩњГЩЩюЖШзмНсЃЌФмПДГіФкШнКУЖрСЫЃЌгаЯрЕБЕФжЧФмСЫЁЃШУЫќУПЬьдчЩЯ8ЕудкЗчЮХЗЂВМЃЌОЭНЈСЂСЫвЛИіЫуЪЧЙ§ЕУШЅЕФздЖЏЗЂЬљШЮЮёЁЃетШЗЪЕЪЧШЋздЖЏЕФЃЌНЈСЂШЮЮёКѓЃЌШЫВЛгУЙмСЫЁЃЕБШЛЮФеТжЪСПВЛЫуЬЋКУЃЌжЛЪЧОйР§ЁЃ

ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪеНељзюаТЖЏЬЌЗжЮі_ЗчЮХ (guancha.cn)
МЬајгХЛЏЃЌШУKimiClawЕїгУKimi 2.5ФЃЗТЮвЕФЮФЗчРДаДзїФкШнЃЌВтЪдЗЂЬљЁЃШУЫќВЮПМЮвдкЙлЭјЕФЮФеТзЈРИЁЃ
етИіФкШнПДЩЯШЅздШЛЖрСЫЃЌЮФЗчгаЕуЯёЁЃЕЋИаОѕKimiДѓФЃаЭВЂЮДзЅзЁЮвЕФЫМЮЌЃЌЮвВЛЛсетбљаДЃЌЕЋетОЭЩюШыДѓФЃаЭЩюВуДЮЕФЁАСщЛъЁБЮЪЬтСЫЃЌГЖдЖСЫЁЃ
ПДЕНетЃЌПЩвдЯраХOpenClawФмИЩГЩаЉгаЕуММЪѕКЌСПЕФЪТЁЃздЖЏЗЂЬљЁЂФЃЗТЮФЗчЪЧвЛРрЪТЃЌЛЙгаКмЖрИДдгШЮЮёвВПЩвдЭъГЩЁЃЦфЪЕКѓУцМИДЮИФНјВЛФбЃЌздШЛгябдИцЫпKimiClawвЊИЩЪВУДОЭааСЫЃЌШУЫќЩњГЩЪВУДФкШнЃЌШУЫќФЃЗТЮФЗчЃЌШУЫќЖЈЪБЗЂВМЁЃЕЋвЊЪЕЯжЕквЛВНЃЌЁАдкЙлЭјЗчЮХТлЬГздЖЏЗЂЬљЁБЃЌетВЛМђЕЅЁЃУЛгаOpenClawЃЌШчЙћЖдДѓФЃаЭгІгУПЊЗЂЁЂAIжЧФмЬхПЊЗЂКмОЋЭЈЃЌгІИУвВгаАьЗЈЃЌЕЋЮвВЛжЊЕРдѕУДзіЁЃгаСЫOpenClawЃЌЫфШЛвВВЛМђЕЅЃЌЕЋУўЫїзХФмЪЕЯжЁЃ
ЕквЛИіГЩЙІЕФВтЪдЗЂЬљвбОЫЕСЫаЉММЪѕЯИНкЃК
ЁАЗЂВМЗНЪНЃКPlaywright + xvfb-run здЖЏЛЏЁБ
ЁАетЪЧKimiClawдкЗўЮёЦїЛЗОГжаЪЙгУPlaywrightфЏРРЦїздЖЏЛЏЙЄОпЭъГЩЕФВйзїЁЃЁБ
OpenClawЭўСІзюДѓЕФЙЄОпжЎвЛЃЌМИКѕПЩвдЫуЪЧзюКЫаФЕФЙІФмЃЌОЭЪЧетИіPlaywrightЁЃЫќЪЧOpenClawЕФЪжЃЈЭјвГВйзїЃЉКЭблЃЈЭјвГНиЦСЃЉЃЌШУAIФмЪЕМЪПижЦфЏРРЦїЃЌЕуЛїЁЂЪфШыЁЂНиЭМЁЂЙіЖЏЁЂЯТдиЖМааЁЃЕЋЪЧЃЌPlaywrightЕФЩёЦцМЋЮЊвРРЕгыЛљзљДѓФЃаЭЕФЦЕЗБЛЅЖЏЃЌВХжЊЕРЭљЯТдѕУДЖЏзїЃЌвЛДЮВйзїПЩФмвЊ50-100ДЮНиЭМ-ОіВпбЛЗЁЃДѓФЃаЭвЊгаЖрФЃЬЌЪгОѕРэНтФмСІЃЌФмРэНтНиЦСФкШнЁЃ
ШчЩЯУцЕФЗчЮХЗЂЬљНчУцЃЌPlaywrightЛсНиЦСИјKimi 2.5ДѓФЃаЭПДЁЃKimi 2.5гадЩњЕФЪгОѕРэНтФмСІЃЌФмПДЖЎЁАБъЬтЁБЁЂЁАе§ЮФЁБПђЪВУДвтЫМЃЌИцЫпPlaywrightШЅЬюФкШнЁЃШчЙћЪЧЭјТчЙКЮяжЎРрЕФШЮЮёЃЌвЊдкЭјвГРяВЛЖЯЕуЛїЩюШыЃЌШчЙћВЛЖдашвЊЗДИДЪдЁЃЫљвдPlaywrightЗЧГЃКФtokenЃЌгааЉШЫЗЂЯжИЩвЛИіЪТМИПщЧЎОЭУЛСЫЃЌвђЮЊвЊНиЦС100ДЮШЅЕїгУДѓФЃаЭРэНтЃЌвЛИіНиЦСОЭвЊаэЖрTokenЁЃ
ЫфШЛPlaywrightКмКФtokenЃЌЕЋЫќШЗЪЕФмздЖЏВйзїЭјвГВйзїАьГЩВЛЩйЪТЁЃPlaywrightЪЧЮЂШэПЊЗЂЕФЃЌДњТыПЊдДСЫЃЌOpenClawФУРДзїЮЊзюживЊЕФЙІФмзщМўжЎвЛЁЃ
ДЋЭГХРГцЪЧЗУЮЪЙЬЖЈЭјжЗЃЌжЛЕїгУ1ДЮAPIОЭФмЛёШЁЪ§ОнЃЌГЩБОМИКѕЮЊСуЁЃетвВЪЧаэЖрЁАЬьЦјВщбЏЁБжЎРрЕФOpenClawМђЕЅskillЕФЬзТЗЁЃЕЋЮвдкKimiClawРягУетаЉМђЕЅskillЃЌИаОѕВЛЪЧЬЋЧПЁЃетРрМђЕЅAPIЗУЮЪЃЌЮоЗЈЭъГЩИДдгВйзїЁЃЛЅСЊЭјЙЋЫОЬсЙЉЙйЗНAPIЗўЮёЪЧгаЃЌШчЙЩЦБаХЯЂAPIЃЌЗЩЪщЛњЦїШЫвВЪЧвЛжжAPIЗўЮёЃЌвЊзіЕУКмЭъЩЦВЂВЛШнвзЁЃКмгаМлжЕЕФЃЌЭљЭљвЊИЖЗбЃЌетОЭИДдгСЫЁЃPlaywrightФмФЃЗЖШЫЭъГЩИДдгЭјвГВйзїЃЌБШХРГцЛђепAPIЕїгУДгЛњжЦЩЯОЭвЊЧПЕУЖрЁЃ
OpenClawВЛЪЧЖдЙлЭјЗўЮёЦїЗЂГівЛЖбзжЗћДЎЃЌШЛКѓвЛЫВМфдкЗчЮХЗЂЬљГЩЙІЃЌЙлЭјУЛетИіAPIЗўЮёЁЃЫќЪЧдкLinuxащФтЛњРяЃЌдЫааСЫфЏРРЦїЃЌЗУЮЪЗчЮХЗЂЬљвГУцЃЌШЛКѓЭљПђзгРяЬюСЫФкШнЃЌЕуЛїЗЂЫЭЃЌЭъШЋКЭШЫвЛбљВйзїЃЌЪЧвЛИіЛКТ§ЕФЙ§ГЬЁЃМгЩЯаДЬљЃЌ5ЗжжгЖМзіВЛЭъЁЃ
аэЖрЭјеОгаЗДХРГцЁЂЗДЛњЦїШЫЛњжЦЃЌЗЂЯжЁАгУЛЇВЛЪЧШЫЁБОЭОмОјЁЃОнЫЕ90%ЕФЭјеОЖМгаCloudflareЕШЗДХРЛњжЦЁЃPlaywrightЪЧецЕФЛсФУЦСФЛШЅЗжЮіЃЌТ§Т§ВйзїЃЌФмШЦПЊЯожЦЁЃЕЋЪЧЖдKimiClawетРрдЦЩЯащФтLINUXЗўЮёЦїРяЕФOpenClawЃЌЫќУЛгаЪЕЬхЦСФЛДцдкЃЌЫљвдЙЙГЩгаЕуРЇФбЁЃНтОіАьЗЈЪЧгУxvfb-runЙЄОпЃЌЩњГЩащФтЦСФЛЃЌШУPlaywrightШЅНиЦСЁЃИеПЊЪМСЌГУЪжЕФфЏРРЦїЖМУЛгаЃЌвЊШЅЯТдиАВзАLinuxРяЕФChromiumфЏРРЦїЁЃ
дйвЛИіЮЪЬтЪЧЙлВьепЭјЗчЮХеЫКХЕЧТНЃЌНтОіАьЗЈЪЧШЫЙЄдкИіШЫЕчФдЩЯЕЧТНГЩЙІЃЌдйДгфЏРРЦїЩЯЯТдиCookieЃЌЬљИјKimiClawЃЌЫќжЊЕРШчКЮШЅгУЁЃ
ЫфШЛЙ§ГЬВЛМђЕЅЃЌЕЋКУДІЪЧДѓФЃаЭКмЧПДѓЃЌЬНЫїЙ§ГЬжаЛсжїЖЏАяУІЃЌИјГіИїжжЗНАИЁЃШЫВЛгУЫЕЕУКмОЋШЗЃЌШУKimiClawШЅжДааОЭКУСЫЁЃЕЋШЫвВашвЊРэНтДѓФЃаЭгыOpenClawИјГіЕФЛњжЦгыЗДРЁЃЌХфКЯааЖЏЁЃеташвЊвЛаЉФЭаФгыЬНЫїОЋЩёЃЌOpenClawПЩвдЫуЪЧЙІФмЧПДѓЕФПЊЗХадПЊЗЂЦНЬЈЃЌВЛЪЧЪжЛњAPPетРрЩЕЙЯЛЏвзгУЙЄОпЁЃ
OpenClawЕФЧПДѓЃЌвЛИіЪЧЛљзљДѓФЃаЭЕФФмСІКмЧПСЫЃЌдНЙ§СЫЪЕгУЕФУХМїЃЛдйвЛИіЪЧгаPlaywrightетРрКмЪЕгУЕФЙІФмЧПДѓЕФЙЄОпЁЃгаСЫетаЉЧПДѓЕФЮфЦїЃЌдйХфЩЯДЋЭГЕФЛЅСЊЭјAPIЁЂГЬађЫуЗЈЃЌВХПЊЗЂГіСЫOpenClawЁЃЫќЕФдЫзїЗНЪНвВЪЧПЩвдНтЪЭЕФЁЃ
ПЩвдПДГіЃЌOpenClawздМКЦфЪЕУЛЩЖжЧФмЃЌБШШчЫќздМКЦДДеЗЂЬљФкШнОЭВЛЬЋЖдЁЃЕЋЫќЯдЕУжЧФмЃЌРДдДЪЧЕїгУДѓФЃаЭЃЌвдМАвЛаЉЧПДѓЕФзщМўЁЃЫќИќЯёвЛИізщжЏепЃЌЖдНггУЛЇашЧѓЃЌШУДѓФЃаЭОіВпЃЌЕїгУИїжжЙІФмНтОіЮЪЬтЁЃ
ЃЈЫФЃЉOpenClawОпЬхЕФдЫааСїГЬЪЧЪВУДЃП
ЩЯУцЪЧOpenClawЙІФмадЕФНщЩмЁЃOpenClawБОжЪЩЯЪЧвЛИіШэМўЃЌЫќгавЛИіПЩвдвЛВНВНОЋШЗРэНтЕФдЫааЙ§ГЬЃЌСЫНтОпЬхЕФдЫааСїГЬФмИќКУЕФРэНтдРэЁЃ
вЛИіДЋЭГШэМўЛђепЫуЗЈдЫааЃЌЦфСїГЬЪЧЁАНгЪеЪфШыЁЂЕїгУЙЄОпЁЂЗЕЛиЯьгІЁБЁЃЛЅСЊЭјЗўЮёЛђепЪжЛњAPPЕШГЬађОЭЪЧетбљзіЕФЃЌШЫУЧгУЕУКмЪьЁЃOpenClawвВЪЧвЛИіШэМўЃЌвВгаЭЌбљЕФСїГЬЁЃ
ЕЋЪЧЃЌOpenClawгыДЋЭГШэМўзюДѓЕФВЛЭЌЃЌЪЧдЫааЪБгажЧФмЁЃЫќЕФСїГЬЪЧЁАНгЪеЪфШыЁЂМьЫїМЧвфЁЂЭЦРэОіВпЁЂЕїгУЙЄОпЁЂИќаТМЧвфЁЂЗЕЛиЯьгІЁБЃЌМгСЫвЛаЉжЧФмЯрЙиЛЗНкЁЃетИіЙ§ГЬЪЧаДдкOpenClawЕФNode.jsГЬађДњТыРяЕФЃЌЪЧПЊдДЕФЃЌВЂВЛЩёУиЁЃ
ШУOpenClawЛ№БщШЋЧђЕФЃЌЪЧЫќгыДЋЭГЫуЗЈЕФЧјБ№ЃК
ДЋЭГШэМўЃЌНгЪеЕФЪфШыЪЧУїШЗЕФжИСюЃЌгЩЪфШыгыНЛЛЅНчУцШЗЖЈЃЌВЛЪЧФЃК§ЕФздШЛгябдЃЛOpenClawПЩвдРэНтгУЛЇЕФздШЛгябдЃЌжИСювЛЯТЗКЛЏСЫЁЃЯШВЛЫЕФмВЛФмзіКУЃЌДЋЭГЫуЗЈФмЁАБЛвЊЧѓЁБзіЕФЪТЃЌМЋЮЊгаЯоЃЌНгЪеЪфШыЫРАхЃЛЖјOpenClawЪЧЭъШЋПЊЗХЕФЃЌЯыЯѓСІЭъШЋДђПЊЃЌПЩвдНгЪеЮоЪ§жжЪфШыЃЌгУЛЇПЩвдЬсГіИїжжКЯРэЛђепВЛКЯРэЕФвЊЧѓЁЃ
ДЋЭГЫуЗЈЃЌЕїгУЕФЙЄОпМЋЮЊгаЯоЃЌЪЧЪТЯШШЗЖЈЕФЃЌЫуЗЈЖМЪЧаДЫРЕФЁЃМДЪЙИДдгЕНЮЂаХетУДДѓЕФГЬађЃЌЙІФмвВЪЧгаЯоЕФЃЛOpenClawФмЙЛЕїгУЕФЙЄОпЪ§СПЮоЩЯЯоЃЌЫќгааэЖрећРэКУЕФskillsЬзТЗПЩгУЃЌЛЙПЩвдЫбЫїЕНПЩгУЕФЛЅСЊЭјЗўЮёЃЌЛЙФмздМКаДГЬађПЊЗЂЙЄОпЃЌРэТлЩЯЕФФмСІЮоЩЯЯоЁЃ
ДЋЭГЫуЗЈЕФМЧвфЙІФмЗЧГЃгаЯоЃЌжЛЪЧЖЈЫРЕФЪ§ОнПтЁЂИќаТЪ§ОнПтЃЌЛђепвЛаЉбЁЯюЩшжУЁЃOpenClawЕФМЧвфЪЧПЊЗХЕФЃЌЫќПЩвдАДШеЦкМЧЯТгыгУЛЇЕФЛЅЖЏЃЌзїЮЊКѓУцНЛЛЅЕФВЮПМЃЌПђМмЪЧПЊЗХЕФЁЃ
ДЋЭГЫуЗЈжЛФмжДааЙЬЖЈЬзТЗЃЌЩйЪ§ГЬађгаЖЈЪБжДааЙІФмЃЌвтвхВЛДѓЁЃOpenClawПЩвдМЧЯТМЋЖргУЛЇНЛД§ЕФЪТЃЌЖЈЦкжДааЁЃПђМмЪЧПЊЗХЕФЃЌУПЬьПЩвдзіаэЖрЪТЃЌЪЧФмСІЧПДѓЕФЁАAIжњРэЁБЃЌЕШгкаэЖрШэМўЙІФмПЩвдвЛЦ№ХмЁЃ
ДгЩЯУцЕФЗжЮіПЩжЊЃЌOpenClawЪЧвЛИіГЙЕзДђПЊЯыЯѓСІЕФПЊЗХадШэМўЃЌгыДЋЭГЫуЗЈЭъШЋВЛЪЧвЛЛиЪТЃЌзюДѓЕФЬиЕуОЭЪЧПЊЗХадЁЃШЫУЧЭЈЙ§аћДЋЁЂЪЕМЪХмбљР§ЃЌКмПьОЭФмЗЂЯжOpenClawЕФЧПДѓгыДДаТЁЃЛЦШЪбЋЫЕOpenClawЪЧЁАгаЪЗвдРДзюживЊЕФШэМўЗЂВМЁБЃЌОЭЪЧетИівтЫМЁЃ
ЕЋЪЧЃЌетУДКУЕФЪТЃЌБиаыгаДѓФЃаЭАяжњВХФмЪЕЯжЁЃаэЖрШЫЖМгаКЭДѓФЃаЭСФЬьЕФОбщЃЌФмУїАзДѓФЃаЭЕФФмСІЃК
ДѓФЃаЭЛсШЅПДЖдЛАПђРяЕФЩЯЯТЮФЃЌЖдЛАЪЧгаЙиСЊЕФЃЌетОЭЪЧгаЁАМьЫїМЧвфЁБЁЃ
ДѓФЃаЭЛсШЅЭјТчЫбЫїЪеМЏаХЯЂЃЌдіМгаХЯЂЃЌВЛжЛгУбЕСЗЪБНижЙШеЦкжЎЧАЕФаХЯЂЁЃ
ДѓФЃаЭЛсгаЫМПМЕиЗжаэЖрВНШЅЭъГЩШЮЮёЃЌетОЭЪЧдкЁАЭЦРэОіВпЁБЁЃ
ДѓФЃаЭЛсаДГЬађЃЌФмПЊЗЂЙЄОпЁЃ
OpenClawВЛЪЧДѓФЃаЭЃЌЕЋЭЈЙ§APIРДЕїгУДѓФЃаЭЁЃНгЪеЪфШыКѓЃЌOpenClawМьЫїМЧвфЃЌНЋЫќзїЮЊЩЯЯТЮФЃЌЕїгУДѓФЃаЭНјвЛВНУїАзгУЛЇЕФвтЭМЃЌВЛгУжиИДНЛД§ЃЛДѓФЃаЭНгзХНјааЁАЭЦРэОіВпЁБЃЌИљОнгУЛЇвтЭМЩњГЩЁАЙЄзїМЦЛЎЁБЃЌетЪЧ2025ФъДѓФЃаЭAgentПЊЗЂЕФЕфаЮШЮЮёЃЛOpenClawЕїгУЙЄОпКѓЃЌПДЗЕЛиЕФНсЙћЃЌИљОнГЩАмЭЦНјЙЄзїМЦЛЎЃЌЕїгУИќЖрЙЄОпЃЛЙЄзїМЦЛЎЭъГЩКѓЃЈЪЇАмвВЪЧвЛжжЭъГЩНсЙћЃЉЃЌOpenClawЕїгУДѓФЃаЭЩњГЩзмНсИќаТМЧвфЃЌНЋзюжеНсЙћзщжЏГЩгУЛЇФмНгЪмЕФаЮЪНЪфГіЃЌЗЕЛиЯьгІЁЃ
ДгЩЯУцЕФУшЪіПЩжЊЃЌДѓФЃаЭЖдOpenClawЕШAIжЧФмЬхРрШэМўЗЧГЃживЊЃЌетДѓМвЖМжЊЕРЁЃЕЋЛЙгавЛИіНаЁАМЧвфЁБЕФЖЋЮїЃЌгаЕуУдК§ЁЃетОЭЩцМАOpenClawКЫаФПђМмЕФШ§ДѓзщМўЃКSkill systemЁЂAgent RuntimeЁЂMemoryЁЃ
Skill systemПЩвдФЃК§РэНтЮЊвЛДѓЖбЁАAIММФмАќЁБЃЌПЩвдРЉеЙЕФЁЃетЦфЪЕВЛФбРэНтЃЌОЭЕБЪЧгавЛЖбзгГЬађПЩЙЉЕїгУЃЌДЋЭГБрГЬРяОЭгааэЖрПтКЏЪ§ЁЃSkill systemПЩвдЕБзїЪЧAIРрПтКЏЪ§ЃЌУПИігаSKILL.mdетбљЕФИјAIПДЕФЁАЪЙгУЫЕУїЪщЁБЁЃ
ЕЋШУOpenClawХмЦ№РДЃЌЛЙашвЊЦфЫќСНИіживЊзщМўЃКAgent RuntimeЁЂMemoryЁЃ

MemoryЯЕЭГЯрЖдШнвзРэНтЃЌОЭЪЧЁАМЧвфЁБЃЌЫќЪЧOpenClawашвЊЕФЛсЛАЩЯЯТЮФЁЂЖЬЦкгыГЄЦкШежОЁЂгУЛЇЦЋКУШЫИёЕШЕШЃЌЛсЗжУХБ№РрЗХдкЯрЙиЮФМўРяЁЃЁАМЧвфЁБВЂВЛаўащЃЌжБЙлРэНтОЭЪЧвЛаЉЮФМўАбгУЛЇНЛД§ЕФЛАЁЂгУЛЇгыOpenClawЕФЛЅЖЏЃЌгУЮФМўМЧЯТРДЁЃЮвгУЕФKimiClawЪЧдкLinuxащФтЛњЕФЁА/root/.openclaw/workspace/ЁБФПТМРяЃЌгУЫФИіЙиМќЕФ.mdЮФМўЃЌАбгУЛЇЯрЙиЕФЪТМЧЯТРДЁЃЛЙгаУПЬьЕФЙЄзїШежОЃЌKimiClawЪЧДцдк/root/.openclaw/workspace/memoryФПТМРяЃЌУПЬьгавЛИіШежОЮФМўЁЃетВЛЩйГЃЙцШэМўвВгаЃЌВЛФбРэНтЁЃ
ашвЊзЂвтЕФЪЧЃЌетаЉМЧвфЯрЙиЮФМўЕФФкШнЃЌЪЧAIећРэЕФЁЃВЛЪЧЪТЮоОоЯИЖММЧЃЌвВВЛЪЧдбљМЧЃЌЖјЪЧРэНтСЫвдКѓеЊвЊЁЂЛузмМЧвфЃЌЪЧжЧФмМЧвфЁЃШчЙћвЛЖбЪТЬЋГЄЃЌОЭЛузмвЛЯТЁЃЦфЪЕШЫвВВЛЪЧЪВУДЖММЧЃЌживЊЕФЪТМЧзЁЃЌЯИНкЗХЮФМўРяЁЃOpenClawЕФМЧвфвВЪЧШчДЫЃЌживЊЕФЪТЗХгУЛЇКЫаФМЧвфЮФМўРяЃЌЯИНкЗХдкШежОРяЃЌГіЪТСЫФжВЛЧхОЭШЅВщШежОЁЃЫљвдMemoryвВЪЧКЭДѓФЃаЭгаЙиЕФЁЃ
MemoryЯрЙиЕФЮФМўЗЧГЃживЊЁЃЮвЕФKimiClawГіСЫвЛДЮДѓЮЪЬтЃЌВЛжЊЕРЮЊКЮmemoryФПТМЖМУЛСЫЃЌMEMORY.mdвВБфГЩПеЕФСЫЃЌОЭЗЂЯжШЮЮёжДааКњБрТвдьЃЌЩЕзгвЛбљЃЌИљБОУЛЗЈгУСЫЁЃЮвШУЫќаоИДЃЌВХгжКУЦ№РДЁЃ
Agent RuntimeПДУћДЪВЛЬЋКУРэНтЃЌЕЋЫќЪЧOpenClawеце§ЕФКЫаФЃЌашвЊзаЯИНтЪЭЁЃAgentОЭЪЧAIвЕНчСїааСЫвЛЖЮЪБМфЕФЁАжЧФмЬхЁБЃЌетЪЧЫЕOpenClawЪЧвЛИігажЧФмЕФШэМўЃЌФмЁАДњРэЁБвЛбљЬцШЫзіЪТЁЃRuntimeЪЧГЬађдБЪьЯЄЕФзЈгУУћзжЃЌПЩвдРрБШРэНтГЩWindowsЁЂЪжЛњВйзїЯЕЭГПЊЛњЪБЕФдЫаазДЬЌЁЂдЫааЛЗОГЃЌЪЧИіЖЏЬЌЕФИХФюЁЃЙиЛњСЫОЭУЛгаRuntimeЃЌХмЦ№РДСЫОЭгавЛЖбЖЋЮїЛюдОЦ№РДЃЌХфКЯзіЪТЃЌећИіЗеЮЇНаRuntimeЁЃ
OpenClawХмЦ№РДвдКѓЃЌећИіЯрЙидЫааЛЗОГЃЌОЭЪЧAgent RuntimeЃЌИКд№ЙмРэAIДњРэЕФЭъећЩњУќжмЦкЃЌгаЖржжЯрЙиЙІФмЁЃШчЁАЛсЛАЙмРэЁБЃЌЮЌЛЄгыгУЛЇЕФЖдЛАЩЯЯТЮФЃЌДІРэЖрТжЖдЛАзДЬЌЃЛдйШчЁАЯћЯЂТЗгЩЁБЃЌНгЪеРДздВЛЭЌЧўЕРЕФЯћЯЂЃЌТЗгЩЕНЖдгІЛсЛАЃЌЗЩЪщЛЙЪЧЭјвГСФЬьПђРДЕФЗжЧхГўЃЛЁАЙЄОпБрХХЁБЃЌНтЮігУЛЇвтЭМЃЌЕїгУЪЪЕБЕФЙЄОпВЂЙмРэжДааСїГЬЃЛЁААВШЋЩГКаЁБЃЌПижЦЙЄОпЗУЮЪШЈЯоЃЌЧјЗжФкВПВйзїКЭЭтВПЕїгУЁЃетаЉЖМЪЧOpenClawЕФДњТыЪЕЯжЕФЃЌЪЧЦфДњТыеце§ЖдгІЕФЙІФмЁЃ
ПЩвдгУЁАдЫЖЏдББШШќзЗзйЁБЕФАИР§ЃЌРДОпЬхЫЕУїOpenClawдЫаавЛИіШЮЮёЕФЙ§ГЬЁЃЮвдкЗЩЪщЩЯЃЈЛђепKimiClawЭјвГЩЯСФЬьвВПЩвдЃЉЃЌвЊЧѓЁАИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂЁБЁЃетСљИідЫЖЏдБЪЧжЃЧеЮФЁЂЭѕаРшЄЁЂедаФЭЏЁЂЭѕТќъХЁЂЫягБЩЏЁЂЭѕГўЧеЃЌЪЧжЎЧАНЛД§ЕФЃЌЗХдкMemoryЮФМўРяСЫЁЃ
1.НгЪеЪфШыЃЈЯЕЭГВуЃЉ
гУЛЇЯћЯЂЃК"ИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂ"
етВНВЛЩцМАДѓФЃаЭЃЌOpenClaw Gateway НгЪеВЂТЗгЩЕНAgent RuntimeЁЃ
2.МьЫїМЧвфЃЈЙЄОпЕїгУЃЉ
Action: memory_search(query="дЫЖЏдБзЗзй жЃЧеЮФ ЭѕаРшЄ...")
етВНвВВЛЩцМАДѓФЃаЭЃЌжБНгЖСШЁЮФМўЯЕЭГЗЕЛиМЧвфЦЌЖЮЁЃ
3.ЭЦРэОіВпЃЈДѓФЃаЭНщШы - Ек1ДЮДѓФЃаЭAPIЕїгУЃЉ
ЪфШыИјФЃаЭЕФЩЯЯТЮФЃК
User: "ИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂ"
Memory: [ГТОЙизЂЭЖзЪЁЂЬхг§ЁЂУНЬхФкШнДДзї]
Available tools: [kimi_search, web_fetch, sports-tracker Skill]
ФЃаЭЭЦРэЪфГіЃК
втЭМЗжЮіЃКгУЛЇвЊЧѓИќаТдЫЖЏдБзЗзйаХЯЂ
МЧвфЦЅХфЃКUSER.md ЯдЪОЙизЂ6ЮЛдЫЖЏдБЃЈжЃЧеЮФЁЂЭѕаРшЄ...ЃЉ
ЙЄОпбЁдёЃК
гХЯШЪЙгУ sports-tracker SkillЃЈвбХфжУЃЌзМШЗадИпЃЉ
ИЈжњЪЙгУ kimi_search бщжЄЪЕЪББШЗж
жДааМЦЛЎЃК
- ЯШжДаа /root/.openclaw/workspace/skills/sports-tracker/scripts/tracker.py
- ШЛКѓеыЖдгаБШШќЕФбЁЪжЪЙгУ kimi_search ЛёШЁОпЬхБШЗж
- зюКѓећРэБЈИц
4.ЕїгУЙЄОпЃЈжДааВуЃЉ
згВНжш4aЃКжДаа tracker.py
cd /root/.openclaw/workspace
python3 skills/sports-tracker/scripts/tracker.py
згВНжш4bЃКkimi_searchЃЈИљОнФЃаЭОіВпЃЉ
Action: kimi_search(query="ЫягБЩЏ жьмЗъи WTTжиЧьЙкОќШќ 3дТ12Ше НсЙћ БШЗж")
ЫбЫїв§ЧцAPIжБНгЗЕЛиНсЙћ
згВНжш 4cЃКЖСШЁНсЙћВЂећРэ
ЖСШЁ tracker.py ЪфГі + kimi_search НсЙћ
етВНВЛЩцМАДѓФЃаЭЃЌЪЧЙЄОпЕїгУЁЂЭјТчЫбЫїЁЂЪ§ОнећКЯ
5.ИќаТМЧвфЃЈДѓФЃаЭНщШы - Ек2ДЮ API ЕїгУЃЉ
ЪфШыЃКдЪМзЗзйНсЙћЃЈГЄЮФБОЃЉ
ФЃаЭШЮЮёЃКЬсСЖЙиМќаХЯЂЃЌЩњГЩМђНрМЧвф
ЪфГіЃК"ЫягБЩЏ3-0ЪЄжьмЗъиЃЌЭѕГўЧеД§БШШќ19:40"

НсЙћаДШыmemoryФПТМРяЕФШежОЮФМў2026-03-12.mdЃЌЩЯЭМЪЧЮвдкжеЖЫРяжБНгВщПДЕНЕФШежОФкШнЃЌЪЧгагУДѓФЃаЭзмНсЕФЁЃ
6.ЗЕЛиЯьгІЃЈДѓФЃаЭНщШы - Ек3ДЮAPIЕїгУЃЉ
ЪфШыИјФЃаЭЃК
ЙЄОпжДааНсЙћЃК
- tracker.py: "6ЮЛдЫЖЏдБжаЃЌЫягБЩЏЁЂЭѕГўЧеНёШегаБШШќ..."
- kimi_search: "ЫягБЩЏ 3-0 жьмЗъиЃЈ11-5, 13-11, 11-8ЃЉ..."
ШЮЮёЃКЩњГЩИјгУЛЇЕФЛиИД
вЊЧѓЃКМђНрЁЂНсЙЙЛЏЁЂЭЛГіЙиМќаХЯЂ
ФЃаЭЩњГЩЯьгІЃК
ЁОдЫЖЏдБзЗзйБЈИцЁП3дТ12ШеЃЈ14:20ИќаТЃЉ
...
ЫягБЩЏЃЈЦЙХвЧђЃЉ
- НёШеБШШќвбНсЪј
- БШЗжЃК3-0 ЪЄжьмЗъиЃЈ11-5, 13-11, 11-8ЃЉ
- зДЬЌЃКНњМЖ16ЧП
ЭѕГўЧеЃЈЦЙХвЧђЃЉ
- Д§БШШќЃК19:40 vs ИЅРЪЮїЫЙПЈ
етРяЕїгУСЫДѓФЃаЭ APIЃЌНЋЙЄОпНсЙћзЊЛЏЮЊздШЛгябдЁЃ
зЂвтЩЯУцЕФСїГЬжагаИіkimi_searchЃЌЫќВЛЪЧskillsвВВЛЪЧДѓФЃаЭЃЌЖјЪЧKimiClawФкжУЕФЭјТчЫбЫїЙЄОпЁЃ
ЮоТлЖрУДЩёЦцЕФOpenClawЙІФмЃЌЖМПЩвдВ№НтЁЃOpenClawКЫаФЁЂМЧвфМьЫїЁЂДѓФЃаЭЕїгУЁЂSkillsЙЄОпЕїгУгыЭјТчЫбЫїЁЂМЧвфИќаТЕШЖржжФЃПщзщКЯЃЌОЭФмЭъГЩЮоЪ§жжШЮЮёЁЃ
ПЩвдПДГіЃЌетИізщКЯМЋЮЊСщЛюЃЌФмЭъГЩЕФШЮЮёЯыЯѓСІЭъШЋДђПЊЁЃЦфжаДѓФЃаЭЕФФмСІЪЧЙиМќЃЌгаСЫЫќЃЌВХФмРэНтвЊИЩЪВУДЪТЁЂШчКЮжДааШЮЮёЁЂШчКЮЪфГіИјгУЛЇЃЌЫљвдЭъГЩвЛИіШЮЮёвЊЖрДЮЕїгУДѓФЃаЭЁЃгааЉПЭЛЇЗЂЯжгУOpenClawЬЋЛЈЧЎСЫЃЌБШДѓФЃаЭAPPЮЪД№ЛЈЧЎЖрСЫЃЌОЭЪЧвђЮЊЁАвЛИіШЮЮёЖрДЮЕїгУЁБЕФЬиадЃЌДѓФЃаЭЛиД№ЮЪЬтОЭЪЧвЛДЮЕїгУЁЃ
жЧФмЬхФмГЄЪБМфВЛЖЯЕїгУДѓФЃаЭЭЦНјШЮЮёЃЌЪЧжЧФмНјВНЕФБъжОЃЌвбОДгМИЪЎЗжжгНјВНСЫЕНМИаЁЪБЩѕжСИќГЄЁЃгааЉШЮЮёOpenClawПЩвдХмКмГЄЪБМфВЛГіДэзюжеЭъГЩЃЌЕЋЫќЛљБОЪЧвЛИіжЧФмЬхдкХмЁЃЯждкAIЧАбивбОЗЂеЙЕНЪЎМИИіжЧФмЬхЗжЙЄХфКЯвЛЦ№ЭъГЩШЮЮёЃЌПЊдДЩчЧјвВгаШУЖрИіOpenClawЗжЙЄЛЅЯрЭЈаХазїЕФГЂЪдЃЌЕЋЛЙВЛЪЧЬЋЭЛГіЁЃ
ЃЈЮхЃЉOpenClawЕФШБЯнЪЧЪВУДЃП
вдЩЯНтЪЭСЫOpenClawЕФдЫзїдРэЃЌПДЩЯШЅКмРїКІЁЃЕЋвЊЮЪЫќЖдЮвгаЩЖгУЃПЮвЯждкЕФНсТлЪЧЃКЛЙУЛЬиБ№гагУЃЌзюДѓЕФЪеЛёЪЧбЇЯАдРэЁЃОјДѓЖрЪ§ЪБМфЃЌЮвЖМдкЁАЫХКђЁБетжЛЯКЃЌвђЮЊгаЪБЫќЪЕдкЬЋВЛППЦзСЫЁЃ
РэНтдРэвдКѓЃЌЮвУЧжЊЕРЃЌЫќФмАьЭІЖрЪТЁЃЕЋЮвЙлВьСЫЖрИіШЮЮёвдКѓЃЌЕУГіСЫВЛЬЋКУЕФНсТлЃКетЪЧвЛИівдЁАаЮЪНжївхЁБЮЊзюИпддђЕФAIжњРэЃЌЪЕжЪФмСІЭљЭљВЛааЃЌзюДѓЮЪЬтЪЧВЛППЦзЁЃЦфЪЕПДЫќЕФЫуЗЈдРэвВФмУїАзЃЌетжжзщКЯГіРДЕФСїГЬЃЌЫцБувЛХмФмППЦзВХМћЙэСЫЁЃ
ДѓФЃаЭБОЩэОЭгаЛУОѕЃЌЕЋТ§Т§ППЦзСЫКмЖрЃЌжЛвЊаЁаФЃЌвбОЫуЪЧФмПижЦЕФаЁЮЪЬтСЫЁЃЮвгУKimiЕФСФЬьЁЂЩюЖШбаОПЁЂcodeЁЂЮФЕЕЕШЙІФмЃЌЖдШеГЃЙЄзїЩњЛюАяжњКмДѓЁЃетаЉЙІФмгаДѓФЃаЭЙЋЫОВЛЖЯбаОПгХЛЏЃЌБэЯждНРДдНКУЪЧПЩвддЄЦкЕФЃЌПЩППадЙ§СЫУХМївдКѓЃЌОЭецЕФКмгагУСЫЁЃ
ЮвУЧПДOpenClawЭъГЩЕФШЮЮёЃЌДѓФЃаЭвЊгУаэЖрДЮЃЌЛЙвЊOpenClawКЫаФРДжїЕМЃЌвЊЕїгУЖржжskillsЃЌвЊзмНсЪфГіЁЃИїжжШЮЮёРраЭЖржжЖрбљЃЌжаМфФФвЛВНГіЮЪЬтЃЌзюКѓЕФНсЙћОЭПЩФмКмРыЦзЁЃ
вЛИібЯжиЮЪЬтЪЧЃЌДѓФЃаЭгаМЋЧПЕФЁАаЮЪНжївхЁББрдьФмСІЁЃвЛИіКУЖрВНЕФСїГЬЃЌжаМфКмгаПЩФмЪЇАмЃЌШчЙЩМлЭјТчВщевЪЇАмЁЂдЫЖЏдБаХЯЂВщевЪЇАмЃЌЛђепБэУцГЩЙІСЫЪЕМЪЪЧДэЕФЃЌШчевСЫвдЧАЕФРЯаХЯЂЁЃЕЋДѓФЃаЭВЛЙмЃЌЫќЯШТњзуаЮЪНжївхЃЌУЛгааХЯЂЃЌЫќздМКБрЃЁ

Р§Шч3дТ11ШеетаЉдЫЖЏдБЕФБШШќЯћЯЂЃЌгааЉЪЧКњБрЕФЃЁжЃЧеЮФКЭЭѕаРшЄЪЕМЪЖМЪфСЫЁЃгаЕФЪБМфДэТвСЫЃЌАб2025ФъЕФЯћЯЂЗЂГіРДСЫЁЃвђЮЊkimi_searchЕШЫбЫїЙЄОпВЛвЛЖЈППЦзЃЌЫбЫїжЛЪЧЗЕЛивЛаЉаХЯЂЃЌВЂВЛФмХаЖЯКЯВЛКЯЪЪЃЌгаЪБвВЛсЪЇАмЁЃOpenClawЕїгУДѓФЃаЭОіВпЭЦРэЃЌЖЈЁАЙЄзїМЦЛЎЁБЕФЪБКђЃЌгаЪБЛсФУГіЁАЫбЫїЪЇАмздМКБрЁБЕФЁАК§ХЊЁБЗНЗЈЁЃ
етбљЕФШЫРрдБЙЄЃЌШчЙћБЛЗЂЯжСЫПЯЖЈПЊГ§СЫЁЃЕЋЮвУЛАьЗЈЃЌЛЙЕУШЅЯыАьЗЈЫХКђЫќЃЌХЊУїАзЗИЩЕЕФдвђЃЌЯыАьЗЈАбЪфГіХЊе§ШЗЁЃ
ИУЭМБэЮЊAIжЦзї ЧыНсКЯЮФеТФкШнзіВЮПМ
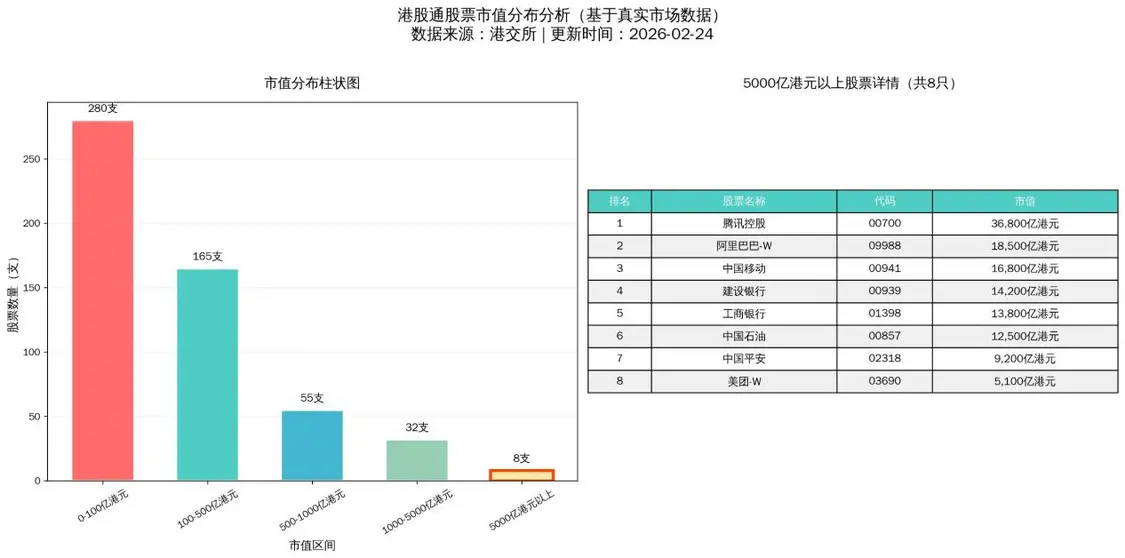
Р§ШчЮвШУKimiClawЩњГЩИлЙЩЭЈ593жЛЙЩЦБЕФЪажЕЗжВМЭМЁЃвЛПЊЪМЯдЪОККзжВЛЖдЃЌЬсЪОКѓЫќЛЙздМКЯТдиККзжзжПтНтОіСЫЮЪЬтЃЌЛГіЭМРДЃЌЯёФЃЯёбљЕФЁЃЕЋЮвдйзаЯИПДЃЌЭъШЋВЛЖдЃЌетаЉЙЩЦБЕФЪажЕЖМЪЧКњБрТвдьЕФЃЁвВВЛЪЧЭъШЋКњБрЃЌЛЙБрЕУКЭецЪЕЪ§зжгаЕуНгНќЁЃЖјетИіЪажЕЗжВМжљЭМвВЪЧВЛЖдЕФЃЌвђЮЊЪажЕЖМХЊДэСЫЁЃЮвЮЪЫќдѕУДЛиЪТЃЌЫќЬЙАзЪЧвђЮЊЭјТчЫбЫїевВЛЕНЪажЕЪ§ОнЃЌОЭздМКБрСЫЁЃ
ИУЭМБэЮЊAIжЦзї ЧыНсКЯЮФеТФкШнзіВЮПМ
ЮвВЛЖЯЯыАьЗЈШУЫќИФНјЃЌШчИјЫќевППЦзЕФЙЩЦБаХЯЂAPIЃЌЫќЩѕжСЯыШУЮвНЛвЛФъЩЯЧЇШЅНгШывЛИіВЦОAPIЁЃИЖГіМшПрЕФХЌСІЃЌевЕНЬкбЖВЦОAPIПЩвдЗЕЛиППЦзаХЯЂЃЌШУЫќзіСЫвЛИіЁАИлЙЩЭЈаХЯЂВщбЏЁБskillЃЌВХАбЭМЛГіРДСЫЁЃЪВУДНаЪажЕЃЌвВашвЊИјЫќЖЈвхЃЌвђЮЊгааЉЙЩЪЧAЙЩгыИлЙЩЖМЩЯЪаЕФЃЌЪажЕгІИУЪЧИїздЩЯЪаЕФЙЩБОЗжБ№ГЫвдAЙЩЁЂИлЙЩЕФЙЩМлдйЯрМгЁЃЕЋЮвзюНќЗЂЯжзюжезіГіЕФЭМЛЙЪЧгаЮЪЬтЃЌЫЕЪажЕ5000вкИлдЊвдЩЯЕФЙЩЦБ16жЇЃЌЕЋФўЕТЪБДњВЛМћСЫЁЃ
ЮвСЫНтвЛаЉДѓФЃаЭЫуЗЈдРэЃЌдкШеГЃЪЙгУДѓФЃаЭЕФЪБКђОЭЗЧГЃзЂвтЛУОѕЁЂБрдьЕШЮЪЬтЁЃетЗНУцЮЪЬтКмДѓЃЌШЫУЧЗЧГЃШнвзЩЯЕБЃЌЭјТчЩЯвбОгаЗЧГЃЖрДѓФЃаЭБрдьЕФФкШнЁЃдкЪЙгУOpenClawЕФЪБКђЃЌЮвЗЂЯжЛУОѕЁЂБрдьЕФЮЪЬтвЊбЯжиЕУЖрЃЌвЊИќМгаЁаФЁЃ
ЕБЮвУЧЗЂЯжДѓФЃаЭВЛППЦзЕФЪБКђЃЌжИГіРДЮЪЬтЃЌЫќЭљЭљФмздМКИФе§ЁЃЕЋЪЧЃЌOpenClawГіДэСЫЃЌвЊШЅаоЫќЃЌвЊФбЕУЖрЁЃШчЙћУЛгавЛЖЈЫЎЦНЃЌЭљЭљОЭВЛЬЋШнвзгУКУOpenClawЃЌЪЕМЪЮЪЬтЗЧГЃЖрЁЃгаЪБПДзХНсЙћВЛДэЃЌЕЋВЛвЛЖЈППЦзЃЌЛЙЪЧашвЊЖрМгаЁаФЁЃгааЉгУЛЇЗДгІЃЌгУOpenClawзіШЮЮёВЛФбЃЌЕЋВщЫќППВЛППЦзКмРлЃЌЮввВгаЭЌИаЁЃ
ДгдРэЩЯРДЫЕЃЌФПЧАЖдOpenClawецВЛФмЬЋЙ§аХШЮЁЃАбживЊЕФИіШЫаХЯЂЁЂВЦОаХЯЂЃЌЛђепЙЄзїЕЅЮЛаХЯЂШУOpenClawеЦЮеЃЌИќЪЧЗЧГЃЮЃЯеЃЌАВШЋТЉЖДМЋДѓЁЃвбОГіСЫВЛЩйЪТСЫЃЌН№ШкЙЋЫОЁЂжиЕуЕЅЮЛЁЂвЛаЉЩЯЪаЙЋЫОЃЌЖМУїШЗвЊЧѓВЛаэдкЕЅЮЛЕчФдЩЯзАOpenClawЁЃАВШЋЗНУцЕФТЉЖДБЪепВЛЬЋЪьЯЄЃЌЕЋИХФюЩЯПЯЖЈЪЧТЉЖДМЋДѓЃЌгаВЛЩйЮФеТжИГіЁЃOpenClawВЛЩйЖЏзїЕШгкдкЛЅСЊЭјЮоБЃЛЄЕНДІЛюЖЏЃЌЮЊСЫЭъГЩШЮЮёевЮввЊСЫвЛаЉаХЯЂЃЌЪЧгаЮЃЯеЁЃ
БЪепЛЙЪЧЯыЬиБ№ЧПЕїЁАППЦзЁБетИіЪТЁЃгавЛаЉOpenClawСїГЬЃЌЯрЙиSkillећРэЕУВЛДэЁЂЯрЙиЛЅСЊЭјаХЯЂЗўЮёППЦзЁЂЛљзљДѓФЃаЭФмСІзуЙЛЃЌШЗЪЕФмЙЛИЩвЛаЉЛюЁЃетаЉР§згПЯЖЈвВЪЧКЃСПЕФЃЌЕЋБиаыжИГіЃЌетВЛЪЧДгЬьЩЯЕєЯТРДЕФЃЌВЛЪЧOpenClawПЊдДСЫОЭгаЃЌЖјЪЧашвЊЯрЕБЖрЕФПЊЗЂЪдДэЁЂећРэДђАќЕФЙЄзїЁЃ
е§ШЗЕФРэНтЪЧЃЌOpenClawЪЧвЛИіПЊЗЂПђМмЃЌЫќШУШЫгУздШЛгябджИЛгИЩЪТЃЌСЂПЬОЭгаНсЙћЃЌИјШЫКмДѓЕФе№КГЁЃЕЋЪЧЃЌШчЙћвЊШУЫќИЩППЦзЕФЪТЃЌОЭКЭШЫРрбЇЯАБрГЬгябдвЛбљЃЌашвЊВЛЩйЛљДЁжЊЪЖЃЌвЊЛсУцЖдИїРрДэЮѓЃЌФЭаФЕиЁАбјЯКЁБЁЃШчЙћВЛЛсбјЃЌОЭЛсЗЂЯжетЖЋЮїВЂУЛгаФЧУДКУЭцЃЌОЭКЭвЛаЉШЫБрГЬбЇВЛЯТШЅвЛбљЁЃ
ИпЪжЖдOpenClawдРэгыМмЙЙКмСЫНтЃЌЖдвЊИЩЕФЪТКмСЫНтЃЌЖдЕїгУЕФЙЄОпвВСЫНтЃЌвВЛсздМКПЊЗЂskillsЃЌАбЯрЙиЛЗНкЖМЕїЪдЕУзуЙЛППЦзСЫЃЌОЭФмзщжЏГівЛаЉВЛДэЕФздЖЏЙЄзїСїГЬЁЃЕЋгаетИіЫЎЦНЕФИпЪжЃЌФПЧАЛЙВЛЖрЁЃ
КмЖрШЫТђЕчФдЛђепдЦЩЯзАСЫСњЯКвдКѓЃЌОЭгааЉУЃШЛСЫЃЌВЛжЊЕРФмИЩЩЖЃЌЯЃЭћБОЮФЖдВЛСЫНтOpenClawдРэЕФШЫгаАяжњЁЃПЩвдШЅбЇЯАИпЪжзмНсЕФППЦзСїГЬЃЌФЃЗТЪЕМљЃЛвВПЩвдШЅбЇЯАдРэЃЌеыЖдадЬсЩ§ЪЙгУAIЕФЫЎЦНЃЛзюКѓздМКвВБфГЩИпЪжЃЌПЊЗЂSkillЃЌжИЛгOpenClawзщжЏСїГЬЃЌеце§ШУAIжњРэАяжњЙЄзїЩњЛюЁЃдкетИіЙ§ГЬжаЃЌвЛЖЈвЊзЂвтЃЌOpenClawКмВЛППЦзЃЌОјЖдВЛФмУЄФПЯраХЃЌвЊгаШЗЪЕЕФжЄОнЃЌИїИіЛЗНкЖМШЗШЯПЩППСЫЃЌВХПЩвдЗХЪжШУЫќИЩЛюЁЃ
АцШЈЫЕУї / Copyright Notice:
Content and images in this article may originate from third-party sources and are used for news reporting, commentary, or public interest purposes. All copyrights remain with their respective owners. Please refer to the Copyright Notice at the bottom of this page.
БОЮФФкШнНіЙЉаХЯЂВЮПМЃЌВЛДњБэБЖПЩЧзСЂГЁЛђЙлЕуЁЃ
[МгЮїЭје§еаЦИЖрУћШЋжАsales Д§гігХ]
КУаТЮХУЛШЫЦРТлдѕУДааЃЌЮвРДЫЕМИОф
БЪепЕквЛЪБМфОЭЙизЂСЫЪТМўЃЌВЂаДЮФЦРТлСЫMoltbotгыЁАвЛШЫЙЋЫОЁБЃЈЗЂдк2дТ6ШеЕФЛЗЧђЪББЈЃЉЃЌНщЩмAIгыжаЙњжЦдьвЕЗжБ№ДгШэгВСНЗНУцЬсЙЉБуНнЗўЮёЃЌЖдгкИіШЫДДвЕКмгавтвхЁЃУЛЯыЕНЕФЪЧЃЌ3дТЪБЖрМвжаЙњЛЅСЊЭјОоЭЗгыДѓФЃаЭЙЋЫОЖМВЮгыНјРДСЫЃЌвЛаЉЕиЗНеўИЎЖМГізЪМЄРјИіШЫПЊЗЂепЃЌШШЖШгы2023ФъГѕЕФChatGPTЁЂ2025ФъГѕЕФDeepSeekПЩвдЯрБШЁЃ
Moltbotгк2026Фъ1дТ30Шее§ЪНИќУћЮЊOpenClawЃЌВЂгк2дТ24ШеГЌЙ§га30ФъРњЪЗЕФLINUXЁЂ3дТ2ШеГЌЙ§ReactЃЌГЩЮЊПЊдДЩчЧјGitHubЪЗЩЯаЧБъзюЖрЕФШэМўЯюФПЁЃНќКѕДЙжБЕФдіГЄЧњЯпГЩЮЊПЊдДШэМўРњЪЗЩЯЕФЦцЙлЁЃ
OpenClawзїЮЊПЊдДЯюФПЃЌЪЙгУгавЛЖЈУХМїЃЌжаЙњАЎКУепгаФмСІздааЯТдиАВзАЕФВЛЖрЁЃKimiClawЪЧжаЙњДѓФЃаЭЙЋЫОзюдчЭЦГіЕФOpenClawдЦЗўЮёЃЌВЛЪЧзАдкИіШЫЕчФдЩЯЃЌЖјЪЧдкдЦЩЯПЊLINUXащФтЛњЃЌАВзАЗНБуЃЌДКНкЧАЭЦГіСЫЪдЕуЁЃКѓУцMaxClawЁЂDuClawЕШИїРрдЦClawВњЦЗдНРДдНЖрЃЌАЂРядЦЁЂЬкбЖдЦЁЂЛЊЮЊ(专题)дЦЁЂЛ№ЩНв§ЧцЁЂОЉЖЋдЦЁЂвЦЖЏдЦЁЂЬьвэдЦЖМЭЦГіСЫЁАвЛМќВПЪ№ЁБНтОіЗНАИЁЃЛЙгаAutoClawЁЂQClawетаЉзїЮЊWindowsЁЂMacOSЕФГЬађАВзААќЃЌзАдкгУЛЇИіШЫЕчФдЩЯЕФЁЃ
етаЉЁАClawЁБЗўЮёЕФЭЦГіЃЌБъжОзХжаЙњAIГЇЩЬе§дкељЖсOpenClawЩњЬЌжїЕМШЈЃЌгы2025Фъ2-3дТИїГЇЩЬЗзЗзВПЪ№НгШыDeepSeekРрЫЦЁЃ
вЛ. ЬНЫїOpenClawЕФЖржжЗНЪН
KimiClawгк2дТ18Шее§ЪНЩЯЯпЃЌБЪепСЂПЬНЛСЫ199дТЗбЃЌаЫГхГхЕиЁАвЛМќАВзАЁБЁЃМИЬьЖМСЌВЛЩЯЗўЮёЦїЃЌгІИУЪЧДКНкУЛЩЯАрЁЃ2дТ22ШеЪєгкБЪепЕФKimiClawжегкЛюСЫЃЌАДЬзТЗЩшжУСЌЩЯЗЩЪщвдКѓЃЌПЩвдЫГГЉЪЙгУСЫЁЃБЪепЕФаЫШЄЪЧСЫНтOpenClawЕФМмЙЙгыдРэЃЌетЗНУцгавЛаЉаФЕУЃЌЖдгкЦфгХЪЦгыШБЯнЕФИљдДвВНЯЮЊЧхГўЁЃ
БОЮФЖдOpenClawНјаадРэадММЪѕНтЪЭЃЌЛсЦеМАвЛаЉЛљДЁИХФюЁЃИќживЊЕФЪЧьюїШЃЌе§ШЗШЯЪЖетжЛШШЖШПеЧАЕФЁАСњЯКЁБЃЌВЛЩёЛЏЦфЙІФмЃЌСЫНтЦфОоДѓЕФЧБСІгыБОжЪШБЯнЁЃ
жаЙњвбОНгЩЯOpenClawЕФгУЛЇЃЌвЛАуКЭЫќгаСНИіНЛЛЅЧўЕРЁЃвЛИіЪЧЗЩЪщЕШЪжЛњМДЪБЭЈбЖAPPЃЌЩЯУцМгСЫClawЛњЦїШЫЃЌСФЬьЯТДяжИСюЁЂНгЪеЮФМўЃЌЯраХЮЂаХВЛОУвВЛсДѓЙцФЃНгШыЁЃЦфдРэЪЧЃЌЗЩЪщЛсЬсЙЉAPIНгШыАьЗЈЃЌOpenClawгаСЫAPIШЈЯовдКѓЃЌОЭПЩвдКЭЗЩЪщЭЈаХЃЌНгЪежИСюЁЂЗЕЛиНсЙћЁЃетвВЪЧSteinbergerПЊЗЂOpenClawЕФГѕждЃЌЯыгУЪжЛњМДЪБЭЈбЖAPPСЌНгздМКЕФЕчФдЃЌдЖГЬВщПДНсЙћЁЂжИЛгИЩЛюЁЃФПЧАетвВЪЧКЭOpenClawзюжївЊЕФЙЕЭЈЗНЪНЁЃ
ЖдгкдЦЩЯВПЪ№ЕФOpenClawЃЌСэвЛИіГЃгУЧўЕРЪЧДѓФЃаЭЭјвГЛђДѓФЃаЭЪжЛњAPPЩЯЕФСФЬьНчУцЁЃШчБЪепЭјвГЩЯСЫKimiДѓФЃаЭЃЌЩЯУцОЭгаKimiClawНчУцЃЌвВФмСФЬьЯТДяжИСюЁЃвЛПЊЪМжЛгаPCЭјвГАцПЩвдЃЌКѓРДЪжЛњKimi APPвВПЩвдСЫЁЃ
БЪепЬхбщЯТРДЃЌЗЂЯжЖўепгажиДѓЧјБ№ЁЃЗЩЪщЪЧжБСЌKimiClawЃЌНгЪеЕФЪЧOpenClawЕФжДааНсЙћЃЌФмЪеЮФМўЁЃЗЩЪщЩЯЕФСФЬьвВОЙ§ДѓФЃаЭДІРэЪЧжЧФмЕФЃЌЕЋгЩгкЪЧЗЧМДЪБЙЕЭЈЃЌЪмЯогкЗЩЪщAPIЕФИёЪНгызжНкЯожЦЃЌаХЯЂЗЂЫЭвЊбЙЫѕЃЌаХЯЂКЌСПгаЯоЃЌР§ШчПДВЛЕНДѓФЃаЭЕФЫМПМЙ§ГЬЁЃЖјдкKimiЭјвГЛђепKimiЪжЛњAPPЩЯЃЌЪЧжБНггыKimiДѓФЃаЭСФЬьЃЌжївЊФкШнЪЧДѓФЃаЭЪфГіЕФЃЌгаЫМПМЙ§ГЬЃЌаХЯЂУїЯдИќЗсИЛЃЛЦфжаМадгСЫвЛаЉOpenClawжДаажИСюЕФНсЙћЃЌЕЋЮФМўЪеВЛСЫЃЌашвЊЗЂЕНЗЩЪщЩЯЁЃБЪепбЁдёгыДѓФЃаЭжБНгСФЬьЕФФЃЪНЃЌвдЗЩЪщЪеЮФМўЮЊИЈжњЁЃетбљФмбЇЕНКмЖрЖЋЮїЃЌПЩвджБНгЬсЮЪЃЌГіСЫЮЪЬтДѓФЃаЭФмИјГіЖржжНтОіЗНАИбЁдёЃЌГЂЪдЙ§ГЬПЩМћЃЌЪЧбЇЯАЬНЫїOpenClawВЛДэЕФЗНЪНЁЃ
ИіШЫЕчФдЩЯАВзАЕФOpenClawЃЌвВгаетжжСФЬьНчУцЁЃAutoClawЁЂQClawЗтзААцЕФЛсгаЭъећзРУцПЭЛЇЖЫЃЌЛсЬсЙЉЖдЛАПђЁЃетжжФЃЪНЃЌгЩгкИіШЫЕчФддЫаазДЬЌЁЂДѓФЃаЭAPIЖМФмжБНгВщПДПижЦЃЌФмЬсЙЉИќЮЊЗсИЛЕФдЫааЯИНкаХЯЂЁЃ
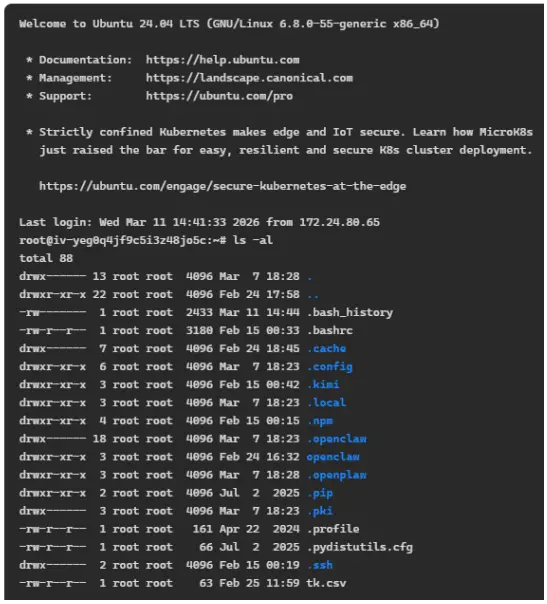
БЪепЮЊСЫРэНтOpenClawМмЙЙгыдРэЃЌЛЙгавЛжжзюжБНгЕФЁАЬНЫїЁБАьЗЈЃЌОЭЪЧНјШыKimiClawЁАОгзЁЁБЕФLinuxащФтЛњжеЖЫЃЌЪЧUbuntu 24.04ЯЕЭГЃЌKimiClawЭјвГАцЬсЙЉСЫШыПкЁЃШчЙћЖдLinuxВйзїЯЕЭГгыУќСюНЯЮЊЪьЯЄЃЌОЭПЩвдШЅзаЯИПДПДЮФМўНсЙЙЃЌжДааЖржжЕзВуУќСюЃЌВ№НтOpenClawжДааШЮЮёЕФЙ§ГЬЁЃШчЖдгкOpenClawЕФSkillsЁЂMemoryетаЉЁАММФмЁБЁЂЁАМЧвфЁБЯрЙиЕФживЊВПМўЃЌПЩвджБНгВщПДЯрЙиЮФМўФкШнЃЌДгзюЕзВуНвУиЁЃ
ЕЋетжжЬНЫїАьЗЈашвЊЯрЕБЕФLinuxжЊЪЖЃЌСЌЭМаЮВйзїНчУцЖМУЛгаЃЌЪѓБъЭъШЋЮогУЃЌашвЊЪфШыаэЖрУќСюЁЃШчЮоОбщЛсФбвдВйзїЃЌМДЪЙаДЮФеТСаГіВйзїЯИНкЃЌвВВЛКУРэНтЁЃШчЙћЪЧИіШЫЕчФдЩЯзАЕФOpenClawЃЌвВПЩвджБНгШЅЕчФдРяЙлВьФПТМЮФМўНсЙЙЃЌЭЌбљгаФбЖШЁЃвђДЫЃЌБЪепНіНщЩмдРэЃЌТдЙ§ВЛКУЖЎЕФЬНЫїЙ§ГЬЯИНкЁЃ
БЪепЛљгкЖдOpenClawЕФЕзВуРэНтЃЌИјГіЕФдРэадНтЪЭЃЌЯЃЭћФмДгСэвЛИіНЧЖШЃЌАяжњЖСепРэНтЁЃЯТУцвдЮЪД№ЕФаЮЪНЃЌНјааНтЪЭЁЃ
ЖўЃЎOpenClawдРэЮЪД№
ЃЈвЛЃЉДгГЬађДњТыНЧЖШПДЃЌOpenClawЛЙдЕНЕзВуЃЌЕНЕзЪЧЪВУДЖЋЮїЃП
OpenClawЪзЯШЪЧвЛИіПЊдДГЬађЃЌдкGitHubЩЯгаЙЋПЊЕФЪЧдДДњТыВжПтЃЌзюдЪМЕФРэНтОЭЪЧЙЋПЊЕФДњТыЁЃЫќПЩвдЁАВПЪ№ЁБЕНИїРрИіШЫPCЩЯЃЌвВПЩвдВПЪ№ЕНдЦЩЯдЫааЦ№РДЁЃгыШЫНЛЛЅЃЌОЭЪЧШЫУЧЬ§ЫЕЕФAIИіШЫжњРэЃЌФмВйзнИіШЫPCЛђепдЦЩЯЕФащФтжїЛњИЩЛюЃЌетБЛЯЗГЦЮЊЁАбјЯКЁБЁЃ
OpenClawЪЧПЊдДЙЄГЬЃЌЫќФмдкWindowsЁЂMacOSЁЂLinuxЕШЖрИіЦНЬЈгІгУЃЌЩѕжСЛЊЮЊКшУЩвВжЇГжВПЪ№ЁЃЮвУЧЯШашвЊУїАзЃЌЫќЕФДњТыгаЁАПчЦНЬЈЁБЬиадЁЃдвђЪЧЃЌЫќЕФПЊЗЂгябдЪЧTypescriptЃЈБрвыГЩJavascriptЃЉЃЌJavaгябдСїааОЭЪЧвђЮЊПчЦНЬЈЃЌзюГЃМћЕФЪЧфЏРРЦїЭјвГГЬађЁЃгаЯрЕБГЄЪБМфЃЌJavascriptЪЧГЬађдБгУЕУзюЖрЕФПЊЗЂгябдЃЌЛ§РлСЫЗсИЛЕФПЊЗЂЩњЬЌЁЃOpenClawЩцМАИДдгЕФЖдЯѓНсЙЙЃЌTypescriptгябдФмдкаДДњТыЪБОЭЗЂЯжЮЪЬтЃЌЖјВЛЪЧЕШдЫааЪББРРЃЁЃДѓаЭПЊдДЯюФППЊЗЂепЃЌЭљЭљЯВЛЖетИігябдЕФЛљгкРраЭЃЈTypeЃЉЕФЁААВШЋИаЁБЁЃ
OpenClawЕФПЊЗЂЛЗОГНаNode.jsЃЌВЛЪьЯЄетИіДЪЕФШЫвВВЛФбРэНтЁЃдкWindowsЁЂMacOSЁЂLinuxЁЂКшУЩжаЖМгавЛИіГЬађУћзжНаЁАnodeЁБЃЌИїздВЛЭЌЃЌЪЧЯЕЭГЪТЯШПЊЗЂКУЕФЁЃМйЩшЮвУЧаДСЫвЛИіГЬађНаapp.jsЃЌИїРрВйзїЯЕЭГЩЯЖМПЩвдЭЈЙ§УќСюЁАnode app.jsЁБГЩЙІжДааЃЌвЛЬзДњТыЖрИіЦНЬЈЖМФмХмЁЃ
OpenClawвЊХмЦ№РДЃЌЛЙашвЊвЛаЉБ№ШЫПЊЗЂЕФЗЧГЃживЊЕФвРРЕАќЁЃетОЭЪЧПЊдДЕФКУДІЃЌБ№ШЫПЊЗЂЕФПЩвджБНгФУЙ§РДгУЃЌзщКЯГіИќКУЕФаТЙІФмЁЃетаЉвРРЕАќвВЖМЪЧNode.jsПЊЗЂЛЗОГРяФмХмЕФЁЃгІгУNode.jsвРРЕАќЃЌгаИіживЊЗжЗЂЙЄОпnpmЃЌгУЁАnpm installЁБУќСюОЭФмВПЪ№КУЁЃетКЭLinux UbuntuВйзїЯЕЭГРяЕФЁАapt installЁБРрЫЦЃЌЬсЙЉСЫЗНБуЕФАВзАЗНЪНЁЃ
ПЩвдЫЕЃЌOpenClawга80%ЕФЙІФмЖМЪЧЁАеОдкnpmАќМчАђЩЯЁБЪЕЯжЕФЃЌжЛга20%ЕФвЕЮёТпМЃЈЕїЖШЁЂМЧвфЁЂАВШЋИєРыЕШЃЉЪЧздМКаДЕФЁЃ
СэЭтЃЌOpenClawЛЙНЈСЂСЫздМКЬигаЕФПЊдДЙІФмРЉеЙЯЕЭГЃЌОЭЪЧВЛЩйШЫЬ§ЫЕЙ§ЕФSkillЁЃSkillЫуЪЧЬиЪтЕФnpmАќЃЈПЩвдгУnpmАВзАЃЉЃЌЕЋOpenClawИјЫќМгСЫБъзМЛЏНгПкЁЂMCPавщЪЪХфВуЃЈШУДѓФЃаЭФмЕїгУЃЉЁЂClawhubЗжЗЂЧўЕРЁЃClawhubРрЫЦnpmвЛбљЗжЗЂSkillЃЌЕЋзЈЮЊAIЙЄОпЩшМЦЁЃПЩвдАбSkillРэНтГЩnpmАќЃЌЕЋМгЩЯСЫИјAIЕФЁАЪЙгУЫЕУїЪщЁБЃЌДѓФЃаЭФмЙЛИќЫГГЉЕиЙцЛЎШУSkillИЩЛюЁЃ
ШчЙћИіШЫвЊдкздМКЕФЕчФдЩЯВПЪ№OpenClawЃЌЯШвЊзАЩЯNode.jsПЊЗЂЛЗОГЁЂХфжУЛЗОГБфСПЃЌетОЭШАЭЫСЫОјДѓВПЗжШЫЁЃ3дТ6ШеЬкбЖдЦдкЩюлкЬкбЖДѓЯУТЅЯТАкЬЏЭЦГіЁАСњЯКАВзАеОЁБЃЌ20ЮЛЙЄГЬЪІУтЗбАяТЗШЫдкИіШЫЕчФдЩЯВПЪ№OpenClawЁЊЁЊОЭЪЧДгетвЛВНПЊЪМЃЌШЗЪЕашвЊММЪѕШЫдБГіЬЏЁЃ
етвЛНкПДЕУУдК§ВЛвЊНєЃЌжЊЕРгаетаЉУћДЪОЭааСЫЁЃвдКѓЙРМЦЛсГЩЮЊЩчЛсГЃЪЖЃЌЬ§ЖрСЫТ§Т§ФмУїАзЁЃ
ЃЈЖўЃЉжаЙњаэЖрЙЋЫОГіЪжКѓЃЌOpenClawЮЊКЮШнвзВПЪ№СЫЃП
2025ФъГѕБЌЛ№ЕФТњбЊАцЕФDeepSeek-R1ЃЌИіШЫВЛПЩФмВПЪ№ГЩЙІЁЃЕЋжаЙњЖрМвЙЋЫОЖМНгШыСЫЃЌЛЙНјааСЫв§СїЃЌМДЪЙDeepSeekЙЋЫОБОЩэЕФЗўЮёМЗБЌСЫЃЌШЫУЧвВгУЩЯБ№МвВПЪ№ЕФDeepSeekЁЃетДЮOpenClawШШГБЃЌжаЙњЯыдкAIЩњЬЌРяеМЮЛЕФЙЋЫОЃЌЖМЛсРДВЮгыЃЌШУгУЛЇдкздМКЕФЦНЬЈжагУOpenClawЁЃетЪЧжаЙњЙЋЫОЩУГЄЕФЃЌУцЯђДѓжкЕФНчУцБиаыгбКУвзгУЃЌВЛШЛУЛЗЈЭЦЙуЁЃ
ГЃМћЕФАьЗЈЪЧдЦЖЫИјгУЛЇПЊвЛИіащФтLinuxжїЛњЃЌОЭЪЧKimiClawетбљЁЃаэЖрЙЋЫОЖМЭЦГіСЫЃЌКУДІЪЧгУЛЇВЛашвЊгаИіШЫЕчФдЃЌБмУтСЫИіШЫЕчФдБЛЭцЛЕЁЂаХЯЂаЙТЖЕШТщЗГЁЃетжжФЃЪНПЩвдвЛМќАВзАЃЌгУЛЇжБНгЪЙгУАВзАКУЕФOpenClawдЦЗўЮёЃЌЕЋвЛПЊЪМРяУцЪВУДИіШЫЕФЮФМўЖМУЛгаЁЃ
СэвЛИіАьЗЈЃЌЪЧжЧЦзЕФAutoClawФЧбљЃЌАбOpenClawДђАќГЩДЋЭГзРУцШэМўЃЌвўВиЕєNode.jsЕФДцдкЃЌдкгУЛЇИіШЫЕчФдЩЯАВзАЁЃЫќОЭЯёДЋЭГWindowsГЬађвЛбљЩЕЙЯЪНАВзАЃЌВЛвЛбљЕФЪЧЃЌЫќЛсздМКВйзнЕчФдгУ1ЗжжгЩшжУКУЗЩЪщЛњЦїШЫЁЃетжжФЃЪНЃЌгУЛЇЕФИіШЫЕчФджБНгОЭгаOpenClawСЫЃЌИЩЛюИќЮЊЗНБуЃЌЕЋГіЪТСЫвВИќЮЊЮЃЯеЁЃ
ММЪѕадЕиЫЕЃЌащФтLinuxжїЛњРяЕФOpenClawФмСІЛсБШеце§ИіШЫЕчФдРяЕФВювЛаЉЁЃБЪепШЗЪЕЗЂЯжKimiClawгаКмЖрТщЗГФбгУжЎДІЃЌдРэЩЯОЭВЛЪЧПЩЪгЛЏЕФЃЌвВУЛгаЩљвєЁЃдйШчдЦЩЯИјИіШЫЕФПеМфжЛга40GЃЌИіШЫЕчФдгВХЬвЊДѓЕУЖрЁЃЛЙгаШеГЃЕФЗЂгЪМўжЎРрЕФЙЄзїСїГЬЃЌИіШЫЕчФдЬьШЛОЭгаЃЌOpenClawФмздШЛНгДЅЃЌдкащФтLinuxжїЛњДгЭЗНЈСЂЙЄзїСїГЬКмВЛШнвзЁЃЕЋЮоТлШчКЮЃЌгаЪЕСІЕФЙЋЫОЬсЙЉЕФдЦЩЯЗўЮёЪЧИіКУЪТЃЌШУШЫФмНЯЮЊЗНБуЕиНгДЅOpenClawЃЌФмНЈСЂаТЕФСїГЬЃЌвВЪЧШУШЫаЫЗмЕФЁЃ
ашвЊзЂвтЃЌетЪЧжаЙњЬигаЕФЯжЯѓЃЌДѓСПЦеЭЈШЫвВгаАьЗЈЪдЪдOpenClawЁЃдкХЗУРЃЌЛљБОжЛЪЧММЪѕДгвЕепКЭАЎКУепКмПёШШЃЌЦеЭЈШЫвђЮЊАКЙѓЗбгУЁЂвўЫНБЃЛЄЕШЮЪЬтгУВЛЩЯЁЃетЪЧЮвУЧдкжаЙњЬигаЕФЁАММЪѕИЃРћЁБЁЃ
ЃЈШ§ЃЉOpenClawППЪВУДИЩЛюЕФЃП
OpenClawВЂВЛЪЧвЛАуЕФШэМўЃЌашвЊИЩГЩвЛаЉгаЕуММЪѕКЌСПЕФЛюЃЌВХЛсШУММЪѕЩчЧјВњЩњХЈКёаЫШЄЃЌв§БЌШЋЧђЁЃБЪепдкЙлВьепЭјЗчЮХЩчЧјздЖЏЗЂЬћВтЪдГЩЙІЃЌПЩвдгУетИіАИР§РДОйР§ЫЕУїЁЃ
OpenClaw здЖЏЛЏВтЪдЗЂЬћ_ЗчЮХ (guancha.cn)
ЯШШУOpenClawздЖЏЗЂСЫИіВтЪдЬљЁЃетвЛВНЦфЪЕКмВЛШнвзЃЌвђЮЊЮвЪЧгУKimiClawдЦЗўЮёЃЌУЛгаПЩЪгЛЏЕФЦСФЛЁЃашвЊКУМИВНЃЌЖЏгУСЫвЛаЉЙЄОпЃЌВХФмЭъГЩЗЂЬљЁЃ
ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪ(专题)еНељзюаТЖЏЬЌ_ЗчЮХ (guancha.cn)
дйШУKimiClawЗЂвЛИіУРвдгывСРЪеНељЖЏЬЌЬљЃЌздааЪеМЏФкШнЁЃПЩвдПДГіФкШнКмдуИтЃЌЪЧOpenClawЫбИїДѓУНЬхЕФБъЬтЦДДеЃЌгаЕФКЭеНељКСЮоЙиЯЕЃЌФкШнУЛЪВУДжЧФмПЩбдЁЃ
ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪеНељзюаТЖЏЬЌЗжЮі_ЗчЮХ (guancha.cn)
ШУKimiClawИФгУKimi 2.5ДѓФЃаЭЩњГЩЩюЖШзмНсЃЌФмПДГіФкШнКУЖрСЫЃЌгаЯрЕБЕФжЧФмСЫЁЃШУЫќУПЬьдчЩЯ8ЕудкЗчЮХЗЂВМЃЌОЭНЈСЂСЫвЛИіЫуЪЧЙ§ЕУШЅЕФздЖЏЗЂЬљШЮЮёЁЃетШЗЪЕЪЧШЋздЖЏЕФЃЌНЈСЂШЮЮёКѓЃЌШЫВЛгУЙмСЫЁЃЕБШЛЮФеТжЪСПВЛЫуЬЋКУЃЌжЛЪЧОйР§ЁЃ
ЁО2026Фъ3дТ13ШеаЧЦкЮхЁПУРвдгывСРЪеНељзюаТЖЏЬЌЗжЮі_ЗчЮХ (guancha.cn)
МЬајгХЛЏЃЌШУKimiClawЕїгУKimi 2.5ФЃЗТЮвЕФЮФЗчРДаДзїФкШнЃЌВтЪдЗЂЬљЁЃШУЫќВЮПМЮвдкЙлЭјЕФЮФеТзЈРИЁЃ
етИіФкШнПДЩЯШЅздШЛЖрСЫЃЌЮФЗчгаЕуЯёЁЃЕЋИаОѕKimiДѓФЃаЭВЂЮДзЅзЁЮвЕФЫМЮЌЃЌЮвВЛЛсетбљаДЃЌЕЋетОЭЩюШыДѓФЃаЭЩюВуДЮЕФЁАСщЛъЁБЮЪЬтСЫЃЌГЖдЖСЫЁЃ
ПДЕНетЃЌПЩвдЯраХOpenClawФмИЩГЩаЉгаЕуММЪѕКЌСПЕФЪТЁЃздЖЏЗЂЬљЁЂФЃЗТЮФЗчЪЧвЛРрЪТЃЌЛЙгаКмЖрИДдгШЮЮёвВПЩвдЭъГЩЁЃЦфЪЕКѓУцМИДЮИФНјВЛФбЃЌздШЛгябдИцЫпKimiClawвЊИЩЪВУДОЭааСЫЃЌШУЫќЩњГЩЪВУДФкШнЃЌШУЫќФЃЗТЮФЗчЃЌШУЫќЖЈЪБЗЂВМЁЃЕЋвЊЪЕЯжЕквЛВНЃЌЁАдкЙлЭјЗчЮХТлЬГздЖЏЗЂЬљЁБЃЌетВЛМђЕЅЁЃУЛгаOpenClawЃЌШчЙћЖдДѓФЃаЭгІгУПЊЗЂЁЂAIжЧФмЬхПЊЗЂКмОЋЭЈЃЌгІИУвВгаАьЗЈЃЌЕЋЮвВЛжЊЕРдѕУДзіЁЃгаСЫOpenClawЃЌЫфШЛвВВЛМђЕЅЃЌЕЋУўЫїзХФмЪЕЯжЁЃ
ЕквЛИіГЩЙІЕФВтЪдЗЂЬљвбОЫЕСЫаЉММЪѕЯИНкЃК
ЁАЗЂВМЗНЪНЃКPlaywright + xvfb-run здЖЏЛЏЁБ
ЁАетЪЧKimiClawдкЗўЮёЦїЛЗОГжаЪЙгУPlaywrightфЏРРЦїздЖЏЛЏЙЄОпЭъГЩЕФВйзїЁЃЁБ
OpenClawЭўСІзюДѓЕФЙЄОпжЎвЛЃЌМИКѕПЩвдЫуЪЧзюКЫаФЕФЙІФмЃЌОЭЪЧетИіPlaywrightЁЃЫќЪЧOpenClawЕФЪжЃЈЭјвГВйзїЃЉКЭблЃЈЭјвГНиЦСЃЉЃЌШУAIФмЪЕМЪПижЦфЏРРЦїЃЌЕуЛїЁЂЪфШыЁЂНиЭМЁЂЙіЖЏЁЂЯТдиЖМааЁЃЕЋЪЧЃЌPlaywrightЕФЩёЦцМЋЮЊвРРЕгыЛљзљДѓФЃаЭЕФЦЕЗБЛЅЖЏЃЌВХжЊЕРЭљЯТдѕУДЖЏзїЃЌвЛДЮВйзїПЩФмвЊ50-100ДЮНиЭМ-ОіВпбЛЗЁЃДѓФЃаЭвЊгаЖрФЃЬЌЪгОѕРэНтФмСІЃЌФмРэНтНиЦСФкШнЁЃ
ШчЩЯУцЕФЗчЮХЗЂЬљНчУцЃЌPlaywrightЛсНиЦСИјKimi 2.5ДѓФЃаЭПДЁЃKimi 2.5гадЩњЕФЪгОѕРэНтФмСІЃЌФмПДЖЎЁАБъЬтЁБЁЂЁАе§ЮФЁБПђЪВУДвтЫМЃЌИцЫпPlaywrightШЅЬюФкШнЁЃШчЙћЪЧЭјТчЙКЮяжЎРрЕФШЮЮёЃЌвЊдкЭјвГРяВЛЖЯЕуЛїЩюШыЃЌШчЙћВЛЖдашвЊЗДИДЪдЁЃЫљвдPlaywrightЗЧГЃКФtokenЃЌгааЉШЫЗЂЯжИЩвЛИіЪТМИПщЧЎОЭУЛСЫЃЌвђЮЊвЊНиЦС100ДЮШЅЕїгУДѓФЃаЭРэНтЃЌвЛИіНиЦСОЭвЊаэЖрTokenЁЃ
ЫфШЛPlaywrightКмКФtokenЃЌЕЋЫќШЗЪЕФмздЖЏВйзїЭјвГВйзїАьГЩВЛЩйЪТЁЃPlaywrightЪЧЮЂШэПЊЗЂЕФЃЌДњТыПЊдДСЫЃЌOpenClawФУРДзїЮЊзюживЊЕФЙІФмзщМўжЎвЛЁЃ
ДЋЭГХРГцЪЧЗУЮЪЙЬЖЈЭјжЗЃЌжЛЕїгУ1ДЮAPIОЭФмЛёШЁЪ§ОнЃЌГЩБОМИКѕЮЊСуЁЃетвВЪЧаэЖрЁАЬьЦјВщбЏЁБжЎРрЕФOpenClawМђЕЅskillЕФЬзТЗЁЃЕЋЮвдкKimiClawРягУетаЉМђЕЅskillЃЌИаОѕВЛЪЧЬЋЧПЁЃетРрМђЕЅAPIЗУЮЪЃЌЮоЗЈЭъГЩИДдгВйзїЁЃЛЅСЊЭјЙЋЫОЬсЙЉЙйЗНAPIЗўЮёЪЧгаЃЌШчЙЩЦБаХЯЂAPIЃЌЗЩЪщЛњЦїШЫвВЪЧвЛжжAPIЗўЮёЃЌвЊзіЕУКмЭъЩЦВЂВЛШнвзЁЃКмгаМлжЕЕФЃЌЭљЭљвЊИЖЗбЃЌетОЭИДдгСЫЁЃPlaywrightФмФЃЗЖШЫЭъГЩИДдгЭјвГВйзїЃЌБШХРГцЛђепAPIЕїгУДгЛњжЦЩЯОЭвЊЧПЕУЖрЁЃ
OpenClawВЛЪЧЖдЙлЭјЗўЮёЦїЗЂГівЛЖбзжЗћДЎЃЌШЛКѓвЛЫВМфдкЗчЮХЗЂЬљГЩЙІЃЌЙлЭјУЛетИіAPIЗўЮёЁЃЫќЪЧдкLinuxащФтЛњРяЃЌдЫааСЫфЏРРЦїЃЌЗУЮЪЗчЮХЗЂЬљвГУцЃЌШЛКѓЭљПђзгРяЬюСЫФкШнЃЌЕуЛїЗЂЫЭЃЌЭъШЋКЭШЫвЛбљВйзїЃЌЪЧвЛИіЛКТ§ЕФЙ§ГЬЁЃМгЩЯаДЬљЃЌ5ЗжжгЖМзіВЛЭъЁЃ
аэЖрЭјеОгаЗДХРГцЁЂЗДЛњЦїШЫЛњжЦЃЌЗЂЯжЁАгУЛЇВЛЪЧШЫЁБОЭОмОјЁЃОнЫЕ90%ЕФЭјеОЖМгаCloudflareЕШЗДХРЛњжЦЁЃPlaywrightЪЧецЕФЛсФУЦСФЛШЅЗжЮіЃЌТ§Т§ВйзїЃЌФмШЦПЊЯожЦЁЃЕЋЪЧЖдKimiClawетРрдЦЩЯащФтLINUXЗўЮёЦїРяЕФOpenClawЃЌЫќУЛгаЪЕЬхЦСФЛДцдкЃЌЫљвдЙЙГЩгаЕуРЇФбЁЃНтОіАьЗЈЪЧгУxvfb-runЙЄОпЃЌЩњГЩащФтЦСФЛЃЌШУPlaywrightШЅНиЦСЁЃИеПЊЪМСЌГУЪжЕФфЏРРЦїЖМУЛгаЃЌвЊШЅЯТдиАВзАLinuxРяЕФChromiumфЏРРЦїЁЃ
дйвЛИіЮЪЬтЪЧЙлВьепЭјЗчЮХеЫКХЕЧТНЃЌНтОіАьЗЈЪЧШЫЙЄдкИіШЫЕчФдЩЯЕЧТНГЩЙІЃЌдйДгфЏРРЦїЩЯЯТдиCookieЃЌЬљИјKimiClawЃЌЫќжЊЕРШчКЮШЅгУЁЃ
ЫфШЛЙ§ГЬВЛМђЕЅЃЌЕЋКУДІЪЧДѓФЃаЭКмЧПДѓЃЌЬНЫїЙ§ГЬжаЛсжїЖЏАяУІЃЌИјГіИїжжЗНАИЁЃШЫВЛгУЫЕЕУКмОЋШЗЃЌШУKimiClawШЅжДааОЭКУСЫЁЃЕЋШЫвВашвЊРэНтДѓФЃаЭгыOpenClawИјГіЕФЛњжЦгыЗДРЁЃЌХфКЯааЖЏЁЃеташвЊвЛаЉФЭаФгыЬНЫїОЋЩёЃЌOpenClawПЩвдЫуЪЧЙІФмЧПДѓЕФПЊЗХадПЊЗЂЦНЬЈЃЌВЛЪЧЪжЛњAPPетРрЩЕЙЯЛЏвзгУЙЄОпЁЃ
OpenClawЕФЧПДѓЃЌвЛИіЪЧЛљзљДѓФЃаЭЕФФмСІКмЧПСЫЃЌдНЙ§СЫЪЕгУЕФУХМїЃЛдйвЛИіЪЧгаPlaywrightетРрКмЪЕгУЕФЙІФмЧПДѓЕФЙЄОпЁЃгаСЫетаЉЧПДѓЕФЮфЦїЃЌдйХфЩЯДЋЭГЕФЛЅСЊЭјAPIЁЂГЬађЫуЗЈЃЌВХПЊЗЂГіСЫOpenClawЁЃЫќЕФдЫзїЗНЪНвВЪЧПЩвдНтЪЭЕФЁЃ
ПЩвдПДГіЃЌOpenClawздМКЦфЪЕУЛЩЖжЧФмЃЌБШШчЫќздМКЦДДеЗЂЬљФкШнОЭВЛЬЋЖдЁЃЕЋЫќЯдЕУжЧФмЃЌРДдДЪЧЕїгУДѓФЃаЭЃЌвдМАвЛаЉЧПДѓЕФзщМўЁЃЫќИќЯёвЛИізщжЏепЃЌЖдНггУЛЇашЧѓЃЌШУДѓФЃаЭОіВпЃЌЕїгУИїжжЙІФмНтОіЮЪЬтЁЃ
ЃЈЫФЃЉOpenClawОпЬхЕФдЫааСїГЬЪЧЪВУДЃП
ЩЯУцЪЧOpenClawЙІФмадЕФНщЩмЁЃOpenClawБОжЪЩЯЪЧвЛИіШэМўЃЌЫќгавЛИіПЩвдвЛВНВНОЋШЗРэНтЕФдЫааЙ§ГЬЃЌСЫНтОпЬхЕФдЫааСїГЬФмИќКУЕФРэНтдРэЁЃ
вЛИіДЋЭГШэМўЛђепЫуЗЈдЫааЃЌЦфСїГЬЪЧЁАНгЪеЪфШыЁЂЕїгУЙЄОпЁЂЗЕЛиЯьгІЁБЁЃЛЅСЊЭјЗўЮёЛђепЪжЛњAPPЕШГЬађОЭЪЧетбљзіЕФЃЌШЫУЧгУЕУКмЪьЁЃOpenClawвВЪЧвЛИіШэМўЃЌвВгаЭЌбљЕФСїГЬЁЃ
ЕЋЪЧЃЌOpenClawгыДЋЭГШэМўзюДѓЕФВЛЭЌЃЌЪЧдЫааЪБгажЧФмЁЃЫќЕФСїГЬЪЧЁАНгЪеЪфШыЁЂМьЫїМЧвфЁЂЭЦРэОіВпЁЂЕїгУЙЄОпЁЂИќаТМЧвфЁЂЗЕЛиЯьгІЁБЃЌМгСЫвЛаЉжЧФмЯрЙиЛЗНкЁЃетИіЙ§ГЬЪЧаДдкOpenClawЕФNode.jsГЬађДњТыРяЕФЃЌЪЧПЊдДЕФЃЌВЂВЛЩёУиЁЃ
ШУOpenClawЛ№БщШЋЧђЕФЃЌЪЧЫќгыДЋЭГЫуЗЈЕФЧјБ№ЃК
ДЋЭГШэМўЃЌНгЪеЕФЪфШыЪЧУїШЗЕФжИСюЃЌгЩЪфШыгыНЛЛЅНчУцШЗЖЈЃЌВЛЪЧФЃК§ЕФздШЛгябдЃЛOpenClawПЩвдРэНтгУЛЇЕФздШЛгябдЃЌжИСювЛЯТЗКЛЏСЫЁЃЯШВЛЫЕФмВЛФмзіКУЃЌДЋЭГЫуЗЈФмЁАБЛвЊЧѓЁБзіЕФЪТЃЌМЋЮЊгаЯоЃЌНгЪеЪфШыЫРАхЃЛЖјOpenClawЪЧЭъШЋПЊЗХЕФЃЌЯыЯѓСІЭъШЋДђПЊЃЌПЩвдНгЪеЮоЪ§жжЪфШыЃЌгУЛЇПЩвдЬсГіИїжжКЯРэЛђепВЛКЯРэЕФвЊЧѓЁЃ
ДЋЭГЫуЗЈЃЌЕїгУЕФЙЄОпМЋЮЊгаЯоЃЌЪЧЪТЯШШЗЖЈЕФЃЌЫуЗЈЖМЪЧаДЫРЕФЁЃМДЪЙИДдгЕНЮЂаХетУДДѓЕФГЬађЃЌЙІФмвВЪЧгаЯоЕФЃЛOpenClawФмЙЛЕїгУЕФЙЄОпЪ§СПЮоЩЯЯоЃЌЫќгааэЖрећРэКУЕФskillsЬзТЗПЩгУЃЌЛЙПЩвдЫбЫїЕНПЩгУЕФЛЅСЊЭјЗўЮёЃЌЛЙФмздМКаДГЬађПЊЗЂЙЄОпЃЌРэТлЩЯЕФФмСІЮоЩЯЯоЁЃ
ДЋЭГЫуЗЈЕФМЧвфЙІФмЗЧГЃгаЯоЃЌжЛЪЧЖЈЫРЕФЪ§ОнПтЁЂИќаТЪ§ОнПтЃЌЛђепвЛаЉбЁЯюЩшжУЁЃOpenClawЕФМЧвфЪЧПЊЗХЕФЃЌЫќПЩвдАДШеЦкМЧЯТгыгУЛЇЕФЛЅЖЏЃЌзїЮЊКѓУцНЛЛЅЕФВЮПМЃЌПђМмЪЧПЊЗХЕФЁЃ
ДЋЭГЫуЗЈжЛФмжДааЙЬЖЈЬзТЗЃЌЩйЪ§ГЬађгаЖЈЪБжДааЙІФмЃЌвтвхВЛДѓЁЃOpenClawПЩвдМЧЯТМЋЖргУЛЇНЛД§ЕФЪТЃЌЖЈЦкжДааЁЃПђМмЪЧПЊЗХЕФЃЌУПЬьПЩвдзіаэЖрЪТЃЌЪЧФмСІЧПДѓЕФЁАAIжњРэЁБЃЌЕШгкаэЖрШэМўЙІФмПЩвдвЛЦ№ХмЁЃ
ДгЩЯУцЕФЗжЮіПЩжЊЃЌOpenClawЪЧвЛИіГЙЕзДђПЊЯыЯѓСІЕФПЊЗХадШэМўЃЌгыДЋЭГЫуЗЈЭъШЋВЛЪЧвЛЛиЪТЃЌзюДѓЕФЬиЕуОЭЪЧПЊЗХадЁЃШЫУЧЭЈЙ§аћДЋЁЂЪЕМЪХмбљР§ЃЌКмПьОЭФмЗЂЯжOpenClawЕФЧПДѓгыДДаТЁЃЛЦШЪбЋЫЕOpenClawЪЧЁАгаЪЗвдРДзюживЊЕФШэМўЗЂВМЁБЃЌОЭЪЧетИівтЫМЁЃ
ЕЋЪЧЃЌетУДКУЕФЪТЃЌБиаыгаДѓФЃаЭАяжњВХФмЪЕЯжЁЃаэЖрШЫЖМгаКЭДѓФЃаЭСФЬьЕФОбщЃЌФмУїАзДѓФЃаЭЕФФмСІЃК
ДѓФЃаЭЛсШЅПДЖдЛАПђРяЕФЩЯЯТЮФЃЌЖдЛАЪЧгаЙиСЊЕФЃЌетОЭЪЧгаЁАМьЫїМЧвфЁБЁЃ
ДѓФЃаЭЛсШЅЭјТчЫбЫїЪеМЏаХЯЂЃЌдіМгаХЯЂЃЌВЛжЛгУбЕСЗЪБНижЙШеЦкжЎЧАЕФаХЯЂЁЃ
ДѓФЃаЭЛсгаЫМПМЕиЗжаэЖрВНШЅЭъГЩШЮЮёЃЌетОЭЪЧдкЁАЭЦРэОіВпЁБЁЃ
ДѓФЃаЭЛсаДГЬађЃЌФмПЊЗЂЙЄОпЁЃ
OpenClawВЛЪЧДѓФЃаЭЃЌЕЋЭЈЙ§APIРДЕїгУДѓФЃаЭЁЃНгЪеЪфШыКѓЃЌOpenClawМьЫїМЧвфЃЌНЋЫќзїЮЊЩЯЯТЮФЃЌЕїгУДѓФЃаЭНјвЛВНУїАзгУЛЇЕФвтЭМЃЌВЛгУжиИДНЛД§ЃЛДѓФЃаЭНгзХНјааЁАЭЦРэОіВпЁБЃЌИљОнгУЛЇвтЭМЩњГЩЁАЙЄзїМЦЛЎЁБЃЌетЪЧ2025ФъДѓФЃаЭAgentПЊЗЂЕФЕфаЮШЮЮёЃЛOpenClawЕїгУЙЄОпКѓЃЌПДЗЕЛиЕФНсЙћЃЌИљОнГЩАмЭЦНјЙЄзїМЦЛЎЃЌЕїгУИќЖрЙЄОпЃЛЙЄзїМЦЛЎЭъГЩКѓЃЈЪЇАмвВЪЧвЛжжЭъГЩНсЙћЃЉЃЌOpenClawЕїгУДѓФЃаЭЩњГЩзмНсИќаТМЧвфЃЌНЋзюжеНсЙћзщжЏГЩгУЛЇФмНгЪмЕФаЮЪНЪфГіЃЌЗЕЛиЯьгІЁЃ
ДгЩЯУцЕФУшЪіПЩжЊЃЌДѓФЃаЭЖдOpenClawЕШAIжЧФмЬхРрШэМўЗЧГЃживЊЃЌетДѓМвЖМжЊЕРЁЃЕЋЛЙгавЛИіНаЁАМЧвфЁБЕФЖЋЮїЃЌгаЕуУдК§ЁЃетОЭЩцМАOpenClawКЫаФПђМмЕФШ§ДѓзщМўЃКSkill systemЁЂAgent RuntimeЁЂMemoryЁЃ
Skill systemПЩвдФЃК§РэНтЮЊвЛДѓЖбЁАAIММФмАќЁБЃЌПЩвдРЉеЙЕФЁЃетЦфЪЕВЛФбРэНтЃЌОЭЕБЪЧгавЛЖбзгГЬађПЩЙЉЕїгУЃЌДЋЭГБрГЬРяОЭгааэЖрПтКЏЪ§ЁЃSkill systemПЩвдЕБзїЪЧAIРрПтКЏЪ§ЃЌУПИігаSKILL.mdетбљЕФИјAIПДЕФЁАЪЙгУЫЕУїЪщЁБЁЃ
ЕЋШУOpenClawХмЦ№РДЃЌЛЙашвЊЦфЫќСНИіживЊзщМўЃКAgent RuntimeЁЂMemoryЁЃ
MemoryЯЕЭГЯрЖдШнвзРэНтЃЌОЭЪЧЁАМЧвфЁБЃЌЫќЪЧOpenClawашвЊЕФЛсЛАЩЯЯТЮФЁЂЖЬЦкгыГЄЦкШежОЁЂгУЛЇЦЋКУШЫИёЕШЕШЃЌЛсЗжУХБ№РрЗХдкЯрЙиЮФМўРяЁЃЁАМЧвфЁБВЂВЛаўащЃЌжБЙлРэНтОЭЪЧвЛаЉЮФМўАбгУЛЇНЛД§ЕФЛАЁЂгУЛЇгыOpenClawЕФЛЅЖЏЃЌгУЮФМўМЧЯТРДЁЃЮвгУЕФKimiClawЪЧдкLinuxащФтЛњЕФЁА/root/.openclaw/workspace/ЁБФПТМРяЃЌгУЫФИіЙиМќЕФ.mdЮФМўЃЌАбгУЛЇЯрЙиЕФЪТМЧЯТРДЁЃЛЙгаУПЬьЕФЙЄзїШежОЃЌKimiClawЪЧДцдк/root/.openclaw/workspace/memoryФПТМРяЃЌУПЬьгавЛИіШежОЮФМўЁЃетВЛЩйГЃЙцШэМўвВгаЃЌВЛФбРэНтЁЃ
ашвЊзЂвтЕФЪЧЃЌетаЉМЧвфЯрЙиЮФМўЕФФкШнЃЌЪЧAIећРэЕФЁЃВЛЪЧЪТЮоОоЯИЖММЧЃЌвВВЛЪЧдбљМЧЃЌЖјЪЧРэНтСЫвдКѓеЊвЊЁЂЛузмМЧвфЃЌЪЧжЧФмМЧвфЁЃШчЙћвЛЖбЪТЬЋГЄЃЌОЭЛузмвЛЯТЁЃЦфЪЕШЫвВВЛЪЧЪВУДЖММЧЃЌживЊЕФЪТМЧзЁЃЌЯИНкЗХЮФМўРяЁЃOpenClawЕФМЧвфвВЪЧШчДЫЃЌживЊЕФЪТЗХгУЛЇКЫаФМЧвфЮФМўРяЃЌЯИНкЗХдкШежОРяЃЌГіЪТСЫФжВЛЧхОЭШЅВщШежОЁЃЫљвдMemoryвВЪЧКЭДѓФЃаЭгаЙиЕФЁЃ
MemoryЯрЙиЕФЮФМўЗЧГЃживЊЁЃЮвЕФKimiClawГіСЫвЛДЮДѓЮЪЬтЃЌВЛжЊЕРЮЊКЮmemoryФПТМЖМУЛСЫЃЌMEMORY.mdвВБфГЩПеЕФСЫЃЌОЭЗЂЯжШЮЮёжДааКњБрТвдьЃЌЩЕзгвЛбљЃЌИљБОУЛЗЈгУСЫЁЃЮвШУЫќаоИДЃЌВХгжКУЦ№РДЁЃ
Agent RuntimeПДУћДЪВЛЬЋКУРэНтЃЌЕЋЫќЪЧOpenClawеце§ЕФКЫаФЃЌашвЊзаЯИНтЪЭЁЃAgentОЭЪЧAIвЕНчСїааСЫвЛЖЮЪБМфЕФЁАжЧФмЬхЁБЃЌетЪЧЫЕOpenClawЪЧвЛИігажЧФмЕФШэМўЃЌФмЁАДњРэЁБвЛбљЬцШЫзіЪТЁЃRuntimeЪЧГЬађдБЪьЯЄЕФзЈгУУћзжЃЌПЩвдРрБШРэНтГЩWindowsЁЂЪжЛњВйзїЯЕЭГПЊЛњЪБЕФдЫаазДЬЌЁЂдЫааЛЗОГЃЌЪЧИіЖЏЬЌЕФИХФюЁЃЙиЛњСЫОЭУЛгаRuntimeЃЌХмЦ№РДСЫОЭгавЛЖбЖЋЮїЛюдОЦ№РДЃЌХфКЯзіЪТЃЌећИіЗеЮЇНаRuntimeЁЃ
OpenClawХмЦ№РДвдКѓЃЌећИіЯрЙидЫааЛЗОГЃЌОЭЪЧAgent RuntimeЃЌИКд№ЙмРэAIДњРэЕФЭъећЩњУќжмЦкЃЌгаЖржжЯрЙиЙІФмЁЃШчЁАЛсЛАЙмРэЁБЃЌЮЌЛЄгыгУЛЇЕФЖдЛАЩЯЯТЮФЃЌДІРэЖрТжЖдЛАзДЬЌЃЛдйШчЁАЯћЯЂТЗгЩЁБЃЌНгЪеРДздВЛЭЌЧўЕРЕФЯћЯЂЃЌТЗгЩЕНЖдгІЛсЛАЃЌЗЩЪщЛЙЪЧЭјвГСФЬьПђРДЕФЗжЧхГўЃЛЁАЙЄОпБрХХЁБЃЌНтЮігУЛЇвтЭМЃЌЕїгУЪЪЕБЕФЙЄОпВЂЙмРэжДааСїГЬЃЛЁААВШЋЩГКаЁБЃЌПижЦЙЄОпЗУЮЪШЈЯоЃЌЧјЗжФкВПВйзїКЭЭтВПЕїгУЁЃетаЉЖМЪЧOpenClawЕФДњТыЪЕЯжЕФЃЌЪЧЦфДњТыеце§ЖдгІЕФЙІФмЁЃ
ПЩвдгУЁАдЫЖЏдББШШќзЗзйЁБЕФАИР§ЃЌРДОпЬхЫЕУїOpenClawдЫаавЛИіШЮЮёЕФЙ§ГЬЁЃЮвдкЗЩЪщЩЯЃЈЛђепKimiClawЭјвГЩЯСФЬьвВПЩвдЃЉЃЌвЊЧѓЁАИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂЁБЁЃетСљИідЫЖЏдБЪЧжЃЧеЮФЁЂЭѕаРшЄЁЂедаФЭЏЁЂЭѕТќъХЁЂЫягБЩЏЁЂЭѕГўЧеЃЌЪЧжЎЧАНЛД§ЕФЃЌЗХдкMemoryЮФМўРяСЫЁЃ
1.НгЪеЪфШыЃЈЯЕЭГВуЃЉ
гУЛЇЯћЯЂЃК"ИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂ"
етВНВЛЩцМАДѓФЃаЭЃЌOpenClaw Gateway НгЪеВЂТЗгЩЕНAgent RuntimeЁЃ
2.МьЫїМЧвфЃЈЙЄОпЕїгУЃЉ
Action: memory_search(query="дЫЖЏдБзЗзй жЃЧеЮФ ЭѕаРшЄ...")
етВНвВВЛЩцМАДѓФЃаЭЃЌжБНгЖСШЁЮФМўЯЕЭГЗЕЛиМЧвфЦЌЖЮЁЃ
3.ЭЦРэОіВпЃЈДѓФЃаЭНщШы - Ек1ДЮДѓФЃаЭAPIЕїгУЃЉ
ЪфШыИјФЃаЭЕФЩЯЯТЮФЃК
User: "ИќаТЯТСљИідЫЖЏдБЕФИњзйаХЯЂ"
Memory: [ГТОЙизЂЭЖзЪЁЂЬхг§ЁЂУНЬхФкШнДДзї]
Available tools: [kimi_search, web_fetch, sports-tracker Skill]
ФЃаЭЭЦРэЪфГіЃК
втЭМЗжЮіЃКгУЛЇвЊЧѓИќаТдЫЖЏдБзЗзйаХЯЂ
МЧвфЦЅХфЃКUSER.md ЯдЪОЙизЂ6ЮЛдЫЖЏдБЃЈжЃЧеЮФЁЂЭѕаРшЄ...ЃЉ
ЙЄОпбЁдёЃК
гХЯШЪЙгУ sports-tracker SkillЃЈвбХфжУЃЌзМШЗадИпЃЉ
ИЈжњЪЙгУ kimi_search бщжЄЪЕЪББШЗж
жДааМЦЛЎЃК
- ЯШжДаа /root/.openclaw/workspace/skills/sports-tracker/scripts/tracker.py
- ШЛКѓеыЖдгаБШШќЕФбЁЪжЪЙгУ kimi_search ЛёШЁОпЬхБШЗж
- зюКѓећРэБЈИц
4.ЕїгУЙЄОпЃЈжДааВуЃЉ
згВНжш4aЃКжДаа tracker.py
cd /root/.openclaw/workspace
python3 skills/sports-tracker/scripts/tracker.py
згВНжш4bЃКkimi_searchЃЈИљОнФЃаЭОіВпЃЉ
Action: kimi_search(query="ЫягБЩЏ жьмЗъи WTTжиЧьЙкОќШќ 3дТ12Ше НсЙћ БШЗж")
ЫбЫїв§ЧцAPIжБНгЗЕЛиНсЙћ
згВНжш 4cЃКЖСШЁНсЙћВЂећРэ
ЖСШЁ tracker.py ЪфГі + kimi_search НсЙћ
етВНВЛЩцМАДѓФЃаЭЃЌЪЧЙЄОпЕїгУЁЂЭјТчЫбЫїЁЂЪ§ОнећКЯ
5.ИќаТМЧвфЃЈДѓФЃаЭНщШы - Ек2ДЮ API ЕїгУЃЉ
ЪфШыЃКдЪМзЗзйНсЙћЃЈГЄЮФБОЃЉ
ФЃаЭШЮЮёЃКЬсСЖЙиМќаХЯЂЃЌЩњГЩМђНрМЧвф
ЪфГіЃК"ЫягБЩЏ3-0ЪЄжьмЗъиЃЌЭѕГўЧеД§БШШќ19:40"
НсЙћаДШыmemoryФПТМРяЕФШежОЮФМў2026-03-12.mdЃЌЩЯЭМЪЧЮвдкжеЖЫРяжБНгВщПДЕНЕФШежОФкШнЃЌЪЧгагУДѓФЃаЭзмНсЕФЁЃ
6.ЗЕЛиЯьгІЃЈДѓФЃаЭНщШы - Ек3ДЮAPIЕїгУЃЉ
ЪфШыИјФЃаЭЃК
ЙЄОпжДааНсЙћЃК
- tracker.py: "6ЮЛдЫЖЏдБжаЃЌЫягБЩЏЁЂЭѕГўЧеНёШегаБШШќ..."
- kimi_search: "ЫягБЩЏ 3-0 жьмЗъиЃЈ11-5, 13-11, 11-8ЃЉ..."
ШЮЮёЃКЩњГЩИјгУЛЇЕФЛиИД
вЊЧѓЃКМђНрЁЂНсЙЙЛЏЁЂЭЛГіЙиМќаХЯЂ
ФЃаЭЩњГЩЯьгІЃК
ЁОдЫЖЏдБзЗзйБЈИцЁП3дТ12ШеЃЈ14:20ИќаТЃЉ
...
ЫягБЩЏЃЈЦЙХвЧђЃЉ
- НёШеБШШќвбНсЪј
- БШЗжЃК3-0 ЪЄжьмЗъиЃЈ11-5, 13-11, 11-8ЃЉ
- зДЬЌЃКНњМЖ16ЧП
ЭѕГўЧеЃЈЦЙХвЧђЃЉ
- Д§БШШќЃК19:40 vs ИЅРЪЮїЫЙПЈ
етРяЕїгУСЫДѓФЃаЭ APIЃЌНЋЙЄОпНсЙћзЊЛЏЮЊздШЛгябдЁЃ
зЂвтЩЯУцЕФСїГЬжагаИіkimi_searchЃЌЫќВЛЪЧskillsвВВЛЪЧДѓФЃаЭЃЌЖјЪЧKimiClawФкжУЕФЭјТчЫбЫїЙЄОпЁЃ
ЮоТлЖрУДЩёЦцЕФOpenClawЙІФмЃЌЖМПЩвдВ№НтЁЃOpenClawКЫаФЁЂМЧвфМьЫїЁЂДѓФЃаЭЕїгУЁЂSkillsЙЄОпЕїгУгыЭјТчЫбЫїЁЂМЧвфИќаТЕШЖржжФЃПщзщКЯЃЌОЭФмЭъГЩЮоЪ§жжШЮЮёЁЃ
ПЩвдПДГіЃЌетИізщКЯМЋЮЊСщЛюЃЌФмЭъГЩЕФШЮЮёЯыЯѓСІЭъШЋДђПЊЁЃЦфжаДѓФЃаЭЕФФмСІЪЧЙиМќЃЌгаСЫЫќЃЌВХФмРэНтвЊИЩЪВУДЪТЁЂШчКЮжДааШЮЮёЁЂШчКЮЪфГіИјгУЛЇЃЌЫљвдЭъГЩвЛИіШЮЮёвЊЖрДЮЕїгУДѓФЃаЭЁЃгааЉПЭЛЇЗЂЯжгУOpenClawЬЋЛЈЧЎСЫЃЌБШДѓФЃаЭAPPЮЪД№ЛЈЧЎЖрСЫЃЌОЭЪЧвђЮЊЁАвЛИіШЮЮёЖрДЮЕїгУЁБЕФЬиадЃЌДѓФЃаЭЛиД№ЮЪЬтОЭЪЧвЛДЮЕїгУЁЃ
жЧФмЬхФмГЄЪБМфВЛЖЯЕїгУДѓФЃаЭЭЦНјШЮЮёЃЌЪЧжЧФмНјВНЕФБъжОЃЌвбОДгМИЪЎЗжжгНјВНСЫЕНМИаЁЪБЩѕжСИќГЄЁЃгааЉШЮЮёOpenClawПЩвдХмКмГЄЪБМфВЛГіДэзюжеЭъГЩЃЌЕЋЫќЛљБОЪЧвЛИіжЧФмЬхдкХмЁЃЯждкAIЧАбивбОЗЂеЙЕНЪЎМИИіжЧФмЬхЗжЙЄХфКЯвЛЦ№ЭъГЩШЮЮёЃЌПЊдДЩчЧјвВгаШУЖрИіOpenClawЗжЙЄЛЅЯрЭЈаХазїЕФГЂЪдЃЌЕЋЛЙВЛЪЧЬЋЭЛГіЁЃ
ЃЈЮхЃЉOpenClawЕФШБЯнЪЧЪВУДЃП
вдЩЯНтЪЭСЫOpenClawЕФдЫзїдРэЃЌПДЩЯШЅКмРїКІЁЃЕЋвЊЮЪЫќЖдЮвгаЩЖгУЃПЮвЯждкЕФНсТлЪЧЃКЛЙУЛЬиБ№гагУЃЌзюДѓЕФЪеЛёЪЧбЇЯАдРэЁЃОјДѓЖрЪ§ЪБМфЃЌЮвЖМдкЁАЫХКђЁБетжЛЯКЃЌвђЮЊгаЪБЫќЪЕдкЬЋВЛППЦзСЫЁЃ
РэНтдРэвдКѓЃЌЮвУЧжЊЕРЃЌЫќФмАьЭІЖрЪТЁЃЕЋЮвЙлВьСЫЖрИіШЮЮёвдКѓЃЌЕУГіСЫВЛЬЋКУЕФНсТлЃКетЪЧвЛИівдЁАаЮЪНжївхЁБЮЊзюИпддђЕФAIжњРэЃЌЪЕжЪФмСІЭљЭљВЛааЃЌзюДѓЮЪЬтЪЧВЛППЦзЁЃЦфЪЕПДЫќЕФЫуЗЈдРэвВФмУїАзЃЌетжжзщКЯГіРДЕФСїГЬЃЌЫцБувЛХмФмППЦзВХМћЙэСЫЁЃ
ДѓФЃаЭБОЩэОЭгаЛУОѕЃЌЕЋТ§Т§ППЦзСЫКмЖрЃЌжЛвЊаЁаФЃЌвбОЫуЪЧФмПижЦЕФаЁЮЪЬтСЫЁЃЮвгУKimiЕФСФЬьЁЂЩюЖШбаОПЁЂcodeЁЂЮФЕЕЕШЙІФмЃЌЖдШеГЃЙЄзїЩњЛюАяжњКмДѓЁЃетаЉЙІФмгаДѓФЃаЭЙЋЫОВЛЖЯбаОПгХЛЏЃЌБэЯждНРДдНКУЪЧПЩвддЄЦкЕФЃЌПЩППадЙ§СЫУХМївдКѓЃЌОЭецЕФКмгагУСЫЁЃ
ЮвУЧПДOpenClawЭъГЩЕФШЮЮёЃЌДѓФЃаЭвЊгУаэЖрДЮЃЌЛЙвЊOpenClawКЫаФРДжїЕМЃЌвЊЕїгУЖржжskillsЃЌвЊзмНсЪфГіЁЃИїжжШЮЮёРраЭЖржжЖрбљЃЌжаМфФФвЛВНГіЮЪЬтЃЌзюКѓЕФНсЙћОЭПЩФмКмРыЦзЁЃ
вЛИібЯжиЮЪЬтЪЧЃЌДѓФЃаЭгаМЋЧПЕФЁАаЮЪНжївхЁББрдьФмСІЁЃвЛИіКУЖрВНЕФСїГЬЃЌжаМфКмгаПЩФмЪЇАмЃЌШчЙЩМлЭјТчВщевЪЇАмЁЂдЫЖЏдБаХЯЂВщевЪЇАмЃЌЛђепБэУцГЩЙІСЫЪЕМЪЪЧДэЕФЃЌШчевСЫвдЧАЕФРЯаХЯЂЁЃЕЋДѓФЃаЭВЛЙмЃЌЫќЯШТњзуаЮЪНжївхЃЌУЛгааХЯЂЃЌЫќздМКБрЃЁ
Р§Шч3дТ11ШеетаЉдЫЖЏдБЕФБШШќЯћЯЂЃЌгааЉЪЧКњБрЕФЃЁжЃЧеЮФКЭЭѕаРшЄЪЕМЪЖМЪфСЫЁЃгаЕФЪБМфДэТвСЫЃЌАб2025ФъЕФЯћЯЂЗЂГіРДСЫЁЃвђЮЊkimi_searchЕШЫбЫїЙЄОпВЛвЛЖЈППЦзЃЌЫбЫїжЛЪЧЗЕЛивЛаЉаХЯЂЃЌВЂВЛФмХаЖЯКЯВЛКЯЪЪЃЌгаЪБвВЛсЪЇАмЁЃOpenClawЕїгУДѓФЃаЭОіВпЭЦРэЃЌЖЈЁАЙЄзїМЦЛЎЁБЕФЪБКђЃЌгаЪБЛсФУГіЁАЫбЫїЪЇАмздМКБрЁБЕФЁАК§ХЊЁБЗНЗЈЁЃ
етбљЕФШЫРрдБЙЄЃЌШчЙћБЛЗЂЯжСЫПЯЖЈПЊГ§СЫЁЃЕЋЮвУЛАьЗЈЃЌЛЙЕУШЅЯыАьЗЈЫХКђЫќЃЌХЊУїАзЗИЩЕЕФдвђЃЌЯыАьЗЈАбЪфГіХЊе§ШЗЁЃ
ИУЭМБэЮЊAIжЦзї ЧыНсКЯЮФеТФкШнзіВЮПМ
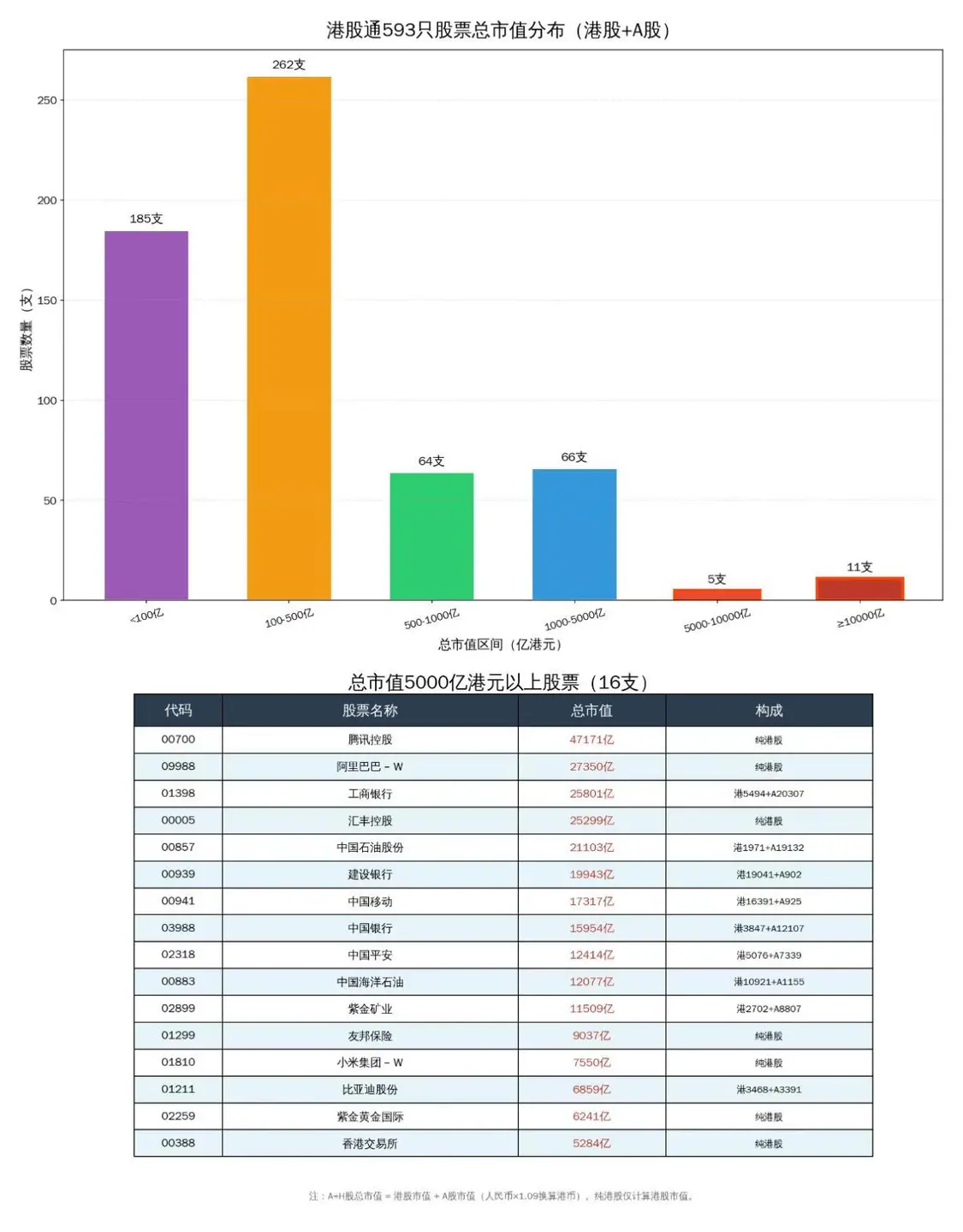
Р§ШчЮвШУKimiClawЩњГЩИлЙЩЭЈ593жЛЙЩЦБЕФЪажЕЗжВМЭМЁЃвЛПЊЪМЯдЪОККзжВЛЖдЃЌЬсЪОКѓЫќЛЙздМКЯТдиККзжзжПтНтОіСЫЮЪЬтЃЌЛГіЭМРДЃЌЯёФЃЯёбљЕФЁЃЕЋЮвдйзаЯИПДЃЌЭъШЋВЛЖдЃЌетаЉЙЩЦБЕФЪажЕЖМЪЧКњБрТвдьЕФЃЁвВВЛЪЧЭъШЋКњБрЃЌЛЙБрЕУКЭецЪЕЪ§зжгаЕуНгНќЁЃЖјетИіЪажЕЗжВМжљЭМвВЪЧВЛЖдЕФЃЌвђЮЊЪажЕЖМХЊДэСЫЁЃЮвЮЪЫќдѕУДЛиЪТЃЌЫќЬЙАзЪЧвђЮЊЭјТчЫбЫїевВЛЕНЪажЕЪ§ОнЃЌОЭздМКБрСЫЁЃ
ИУЭМБэЮЊAIжЦзї ЧыНсКЯЮФеТФкШнзіВЮПМ
ЮвВЛЖЯЯыАьЗЈШУЫќИФНјЃЌШчИјЫќевППЦзЕФЙЩЦБаХЯЂAPIЃЌЫќЩѕжСЯыШУЮвНЛвЛФъЩЯЧЇШЅНгШывЛИіВЦОAPIЁЃИЖГіМшПрЕФХЌСІЃЌевЕНЬкбЖВЦОAPIПЩвдЗЕЛиППЦзаХЯЂЃЌШУЫќзіСЫвЛИіЁАИлЙЩЭЈаХЯЂВщбЏЁБskillЃЌВХАбЭМЛГіРДСЫЁЃЪВУДНаЪажЕЃЌвВашвЊИјЫќЖЈвхЃЌвђЮЊгааЉЙЩЪЧAЙЩгыИлЙЩЖМЩЯЪаЕФЃЌЪажЕгІИУЪЧИїздЩЯЪаЕФЙЩБОЗжБ№ГЫвдAЙЩЁЂИлЙЩЕФЙЩМлдйЯрМгЁЃЕЋЮвзюНќЗЂЯжзюжезіГіЕФЭМЛЙЪЧгаЮЪЬтЃЌЫЕЪажЕ5000вкИлдЊвдЩЯЕФЙЩЦБ16жЇЃЌЕЋФўЕТЪБДњВЛМћСЫЁЃ
ЮвСЫНтвЛаЉДѓФЃаЭЫуЗЈдРэЃЌдкШеГЃЪЙгУДѓФЃаЭЕФЪБКђОЭЗЧГЃзЂвтЛУОѕЁЂБрдьЕШЮЪЬтЁЃетЗНУцЮЪЬтКмДѓЃЌШЫУЧЗЧГЃШнвзЩЯЕБЃЌЭјТчЩЯвбОгаЗЧГЃЖрДѓФЃаЭБрдьЕФФкШнЁЃдкЪЙгУOpenClawЕФЪБКђЃЌЮвЗЂЯжЛУОѕЁЂБрдьЕФЮЪЬтвЊбЯжиЕУЖрЃЌвЊИќМгаЁаФЁЃ
ЕБЮвУЧЗЂЯжДѓФЃаЭВЛППЦзЕФЪБКђЃЌжИГіРДЮЪЬтЃЌЫќЭљЭљФмздМКИФе§ЁЃЕЋЪЧЃЌOpenClawГіДэСЫЃЌвЊШЅаоЫќЃЌвЊФбЕУЖрЁЃШчЙћУЛгавЛЖЈЫЎЦНЃЌЭљЭљОЭВЛЬЋШнвзгУКУOpenClawЃЌЪЕМЪЮЪЬтЗЧГЃЖрЁЃгаЪБПДзХНсЙћВЛДэЃЌЕЋВЛвЛЖЈППЦзЃЌЛЙЪЧашвЊЖрМгаЁаФЁЃгааЉгУЛЇЗДгІЃЌгУOpenClawзіШЮЮёВЛФбЃЌЕЋВщЫќППВЛППЦзКмРлЃЌЮввВгаЭЌИаЁЃ
ДгдРэЩЯРДЫЕЃЌФПЧАЖдOpenClawецВЛФмЬЋЙ§аХШЮЁЃАбживЊЕФИіШЫаХЯЂЁЂВЦОаХЯЂЃЌЛђепЙЄзїЕЅЮЛаХЯЂШУOpenClawеЦЮеЃЌИќЪЧЗЧГЃЮЃЯеЃЌАВШЋТЉЖДМЋДѓЁЃвбОГіСЫВЛЩйЪТСЫЃЌН№ШкЙЋЫОЁЂжиЕуЕЅЮЛЁЂвЛаЉЩЯЪаЙЋЫОЃЌЖМУїШЗвЊЧѓВЛаэдкЕЅЮЛЕчФдЩЯзАOpenClawЁЃАВШЋЗНУцЕФТЉЖДБЪепВЛЬЋЪьЯЄЃЌЕЋИХФюЩЯПЯЖЈЪЧТЉЖДМЋДѓЃЌгаВЛЩйЮФеТжИГіЁЃOpenClawВЛЩйЖЏзїЕШгкдкЛЅСЊЭјЮоБЃЛЄЕНДІЛюЖЏЃЌЮЊСЫЭъГЩШЮЮёевЮввЊСЫвЛаЉаХЯЂЃЌЪЧгаЮЃЯеЁЃ
БЪепЛЙЪЧЯыЬиБ№ЧПЕїЁАППЦзЁБетИіЪТЁЃгавЛаЉOpenClawСїГЬЃЌЯрЙиSkillећРэЕУВЛДэЁЂЯрЙиЛЅСЊЭјаХЯЂЗўЮёППЦзЁЂЛљзљДѓФЃаЭФмСІзуЙЛЃЌШЗЪЕФмЙЛИЩвЛаЉЛюЁЃетаЉР§згПЯЖЈвВЪЧКЃСПЕФЃЌЕЋБиаыжИГіЃЌетВЛЪЧДгЬьЩЯЕєЯТРДЕФЃЌВЛЪЧOpenClawПЊдДСЫОЭгаЃЌЖјЪЧашвЊЯрЕБЖрЕФПЊЗЂЪдДэЁЂећРэДђАќЕФЙЄзїЁЃ
е§ШЗЕФРэНтЪЧЃЌOpenClawЪЧвЛИіПЊЗЂПђМмЃЌЫќШУШЫгУздШЛгябджИЛгИЩЪТЃЌСЂПЬОЭгаНсЙћЃЌИјШЫКмДѓЕФе№КГЁЃЕЋЪЧЃЌШчЙћвЊШУЫќИЩППЦзЕФЪТЃЌОЭКЭШЫРрбЇЯАБрГЬгябдвЛбљЃЌашвЊВЛЩйЛљДЁжЊЪЖЃЌвЊЛсУцЖдИїРрДэЮѓЃЌФЭаФЕиЁАбјЯКЁБЁЃШчЙћВЛЛсбјЃЌОЭЛсЗЂЯжетЖЋЮїВЂУЛгаФЧУДКУЭцЃЌОЭКЭвЛаЉШЫБрГЬбЇВЛЯТШЅвЛбљЁЃ
ИпЪжЖдOpenClawдРэгыМмЙЙКмСЫНтЃЌЖдвЊИЩЕФЪТКмСЫНтЃЌЖдЕїгУЕФЙЄОпвВСЫНтЃЌвВЛсздМКПЊЗЂskillsЃЌАбЯрЙиЛЗНкЖМЕїЪдЕУзуЙЛППЦзСЫЃЌОЭФмзщжЏГівЛаЉВЛДэЕФздЖЏЙЄзїСїГЬЁЃЕЋгаетИіЫЎЦНЕФИпЪжЃЌФПЧАЛЙВЛЖрЁЃ
КмЖрШЫТђЕчФдЛђепдЦЩЯзАСЫСњЯКвдКѓЃЌОЭгааЉУЃШЛСЫЃЌВЛжЊЕРФмИЩЩЖЃЌЯЃЭћБОЮФЖдВЛСЫНтOpenClawдРэЕФШЫгаАяжњЁЃПЩвдШЅбЇЯАИпЪжзмНсЕФППЦзСїГЬЃЌФЃЗТЪЕМљЃЛвВПЩвдШЅбЇЯАдРэЃЌеыЖдадЬсЩ§ЪЙгУAIЕФЫЎЦНЃЛзюКѓздМКвВБфГЩИпЪжЃЌПЊЗЂSkillЃЌжИЛгOpenClawзщжЏСїГЬЃЌеце§ШУAIжњРэАяжњЙЄзїЩњЛюЁЃдкетИіЙ§ГЬжаЃЌвЛЖЈвЊзЂвтЃЌOpenClawКмВЛППЦзЃЌОјЖдВЛФмУЄФПЯраХЃЌвЊгаШЗЪЕЕФжЄОнЃЌИїИіЛЗНкЖМШЗШЯПЩППСЫЃЌВХПЩвдЗХЪжШУЫќИЩЛюЁЃ
АцШЈЫЕУї / Copyright Notice:
Content and images in this article may originate from third-party sources and are used for news reporting, commentary, or public interest purposes. All copyrights remain with their respective owners. Please refer to the Copyright Notice at the bottom of this page.
БОЮФФкШнНіЙЉаХЯЂВЮПМЃЌВЛДњБэБЖПЩЧзСЂГЁЛђЙлЕуЁЃ
[МгЮїЭје§еаЦИЖрУћШЋжАsales Д§гігХ]
| ЗжЯэ: |
| зЂЃК |
ЭЦМі: