




ЭјгбУЧХСЫ!DeepSeekИќаТКѓ ГЙЕз"БфЩЕ"
2 дТ 12 ШеЯћЯЂЃЌаЁРзНёЬьЫЂаЁКьЪщЃЌЫЂЕНКУЖрШЫЖМдкЭТВл DeepSeek БфЩЕСЫЁЃФЧИіжЎЧАБЛДѓМвДЕБЌЁЂАьЙЋУўгуШЋППЫќЕФ AI ЙЄОпЃЌОгШЛдкЧФЧФИќаТКѓЃЌГЙЕзЗГЕСЫЁЃ
ЭМдДЃКаЁКьЪщ
ВЛжЊЕРзђЬьдкгУ DeepSeek ЕФХѓгбУЧгаУЛгаЗЂЯжЃЌДгзђЬьПЊЪМЃЌВЛЙмЪЧЭјвГЖЫЛЙЪЧ App ЖЫЃЌЫќЧФпфпфПЊЦєСЫЛвЖШВтЪдЃЌУЛЗЂШЮКЮдЄИцОЭЭъГЩСЫИќаТЁЃ
ЙйЗНЫЕетДЮИќаТЪЧПчдНЪНЩ§МЖЃЌзюССблЕФОЭЪЧЩЯЯТЮФДАПкДг 128K РЕНСЫ 1MЃЌЯрЕБгкФмвЛДЮадЖСЭъЁЖШ§ЬхЁЗШ§ВПЧњЃЌЛЙФмПьЫйзіЗжЮіЃЌжЊЪЖПтвВИќаТЕНСЫ 2025 Фъ 5 дТЁЃ
БОРДвдЮЊЪЧИЃРћЃЌНсЙћИќаТЭъвЛгУЃЌШЋЭјЭјгбМЏЬхЦЦЗРЃЌЭТВлЩљжБНгЫЂЦСЃЌКУЖрШЫКАзХЁАдйВЛИФЛиРДОЭаЖдиЁБЁАецЕФгУВЛЯТШЅСЫЁБЁЃ
ИљОнЭјгбУЧЕФЗДРЁЃЌзюжБЙлЕФБфЛЏОЭЪЧЮФЗчГЙЕзХмЦЋЃЌДгИпРфРэЙЄФаБфГЩСЫЮФчЇчЇЕФгЭФхЪЋШЫЁЃ
ПЩЯждкФиЃПВЛЙмФужЎЧАЩшЖЈСЫЪВУДъЧГЦЃЌЫќЭГвЛРфБљБљКАгУЛЇЃЌШЋБфГЩСЫЁАКУЕФЃЌгУЛЇетДЮЯыСЫНтЁЁЁБЃЌЫВМфУЛСЫЧзЧаИаЁЃ
ЭМдДЃКаЁКьЪщ
ЦфДЮОЭЪЧгяЦјБфЕУЬиБ№гаЕЧЮЖЃЌЛЙАЎЫЕЗЯЛАЁЂЭцЬзТЗЁЃ
гаЭјгбШУЫќЭЦМіЕчгАЃЌБОРДСаМИИіЦЌУћОЭЭъЪТЃЌЫќЗЧвЊЖрВЙвЛОфЙЛФуПДвЛеѓзгЃЌВЛЙЛдйРДвЊЃЌФЧОгИпСйЯТЕФЫЕНЬИаЃЌЭзЭзЕФЕЧЮЖРТњЃЌдНПДдНБ№ХЄЁЃ
ЛЙгааЁКьЪщЕФЭјгбЫЕЃЌЫќЯждкЕФЛиД№ЬзТЗЛЏЬиБ№бЯжиЃЌФЃЗТБ№ЕФ AI ЗчИёЃЌШДЖЊСЫздМКЕФгВКЫгХЪЦЃЌдНгУдНЗѓбмЁЃ
ЛЙгаШЫШУЫќНтЮіУЮОГЃЌНсЙћЫќОЭЫЕаЉдЂвтУРКУЁЂЮоашЕЃаФЕФЗЯЛАЃЌЗѓбмЕНВЛааЃЌЭъШЋЛиБмЩюЖШЗжЮіЃЌжЛИвЫЕаЉШЋПЯЖЈЪНЕФЧГВуЛиД№ЁЃ
ИќШУШЫЮоФЮЕФЪЧЃЌДѓМвЮЊСЫевЛивдЧАЕФЮФЗчЃЌЛЛСЫКУМИИіАцБОЃЌИФЬсЪОДЪЁЂжиаТбЕСЗЃЌелЬкРДелЬкШЅЃЌЛЙЪЧУЛеоЁЃ
вВгаИіБ№ЭјгбевЕНЧЯУХЃЌБШШчдкЬсЪОДЪРяМгЩЯЮвашвЊЗжВуНсЙЙЛЏЛиД№ЃЌФмШУЫќднЪБЛиЕНОЩЗчИёЃЌЕЋДѓВПЗжШЫЪдСЫЖМУЛгУЃЌелЬкАыЬьЛЙЪЧАзДюЁЃ
ЭМдДЃКаЁКьЪщ
зюКѓДѓМвжЛФмздЗЂКХейЃЌШУДѓМвИјЙйЗНгЪЯфЬсвтМћЁЃЛЙгаШЫЯгелЬкЃЌжБНгШЅЭуЖЙМдЯТдиОЩАцЃЌЩѕжСзЊШЅгУЬкбЖдЊБІЦНЬЈЁЃБЯОЙЬкбЖдЊБІБОЩэОЭДюдиСЫ DeepSeek ЕФОЩАцФЃаЭЃЌгУзХБШаТАцЫГЪжЖрСЫЁЃ
аЁРзвВФмРэНтЃЌЙйЗНПЩФмЪЧЯыдк V4 АцБОе§ЪНЩЯЯпЧАЃЌзівЛДЮбЙСІВтЪдЃЌетДЮЕФИќаТИќЯёЪЧИіМЋЫйАцЃЌЮўЩќжЪСПЛЛЫйЖШЃЌЮЊСЫПьЫйЭЦГіаТЙІФмЃЌКіТдСЫгУЛЇЕФКЫаФЬхбщЁЃ
аЁРзШЯЮЊЃЌAI ЕФКЫаФДгРДВЛЪЧЖбВЮЪ§ЃЌЖјЪЧКУгУЁЂФмгУЁЂППЕУзЁЁЃШчЙћвЛЮЖзЗЧѓаТЙІФмЃЌКіТдСЫЛљДЁЬхбщКЭгУЛЇЯАЙпЃЌОЭЫуВЮЪ§дйИпЁЂЙІФмдйШЋЃЌвВСєВЛзЁгУЛЇЁЃЯждкПЩбЁдёЕФ AI ЬЋЖрСЫЃЌФуВЛКУгУЃЌДѓМвзЊЩэОЭФмзпЁЃ
ВЛЙ§ЛАЫЕЛиРДЃЌвВВЛЪЧЫљгаШЫЖМдкЭТВлЃЌгаЩйЪ§гУЛЇПЯЖЈСЫаТАцЕФгХЪЦЁЃ
БШШчзіЗЈТЩЁЂБрГЬЕФХѓгбЫЕЃЌгУЫќЗжЮіЗЈТЩОэзкЁЂжиЙЙДњТыПтаЇТЪЬиБ№ИпЃЌЖјЧвГЩБОжЛгаОКЦЗЕФЪЎЗжжЎвЛЃЌетвВЫуЪЧетДЮИќаТРяЮЊЪ§ВЛЖрЕФССЕуЃЌжЛЪЧЕБЧАгпЧщЛЙЪЧвдИКУцЮЊжїЁЃ

ЭМдДЃКDeepSeek
НижСЯждкЃЌDeepSeek ЙйЗНЛЙУЛЖдетДЮЕФЭТВлзіГіШЮКЮЛигІЃЌВЛжЊЕРКѓајЛсВЛЛсЕїећЁЃжЛгаЙйЗНЕФММЪѕеЫКХЧФЧФАЕЪОЃЌетДЮИќаТАќКЌЬѕМўМЧвфММЪѕгХЛЏЁЃГ§ДЫжЎЭтЃЌСЌвЛОфНтЪЭЖМУЛгаЁЃ
ЯрЙиБЈЕРЃКDeepSeekБфРфЕСЫ
2дТ11ШеЃЌЩюЖШЧѓЫїЃЈDeepSeekЃЉЧФЧФЕиЖдЦфЦьНЂФЃаЭНјааЛвЖШВтЪдЁЃ
ДЫДЮИќаТЕФКЫаФССЕуЪЧЃЌФЃаЭЩЯЯТЮФДАПкДгдЯШЕФ128K TokensДѓЗљЬсЩ§жС1M TokensЃЌЪЕЯжСЫНќ8БЖЕФШнСПдіГЄЁЃдкAIДѓФЃаЭСьгђЃЌЩЯЯТЮФДАПкОіЖЈСЫФЃаЭдкЕЅДЮНЛЛЅжаФмЙЛМЧвфКЭДІРэЕФаХЯЂСПЩЯЯоЁЃ
вЛЮЛЙњВњДѓФЃаЭГЇЩЬШЫЪПНтЪЭЃЌДЫЧАDeepSeekЕФжїСїФЃаЭжЇГж128K TokensЕФЩЯЯТЮФЃЌетвЛГЄЖШПЩвдгІЖдГЄЦЊТлЮФЛђжаЕШЙцФЃЕФДњТыЮФМўЃЌЕЋДІРэГЌГЄЮФбЇзїЦЗЛђНЯДѓЬхСПБрГЬЙЄзїЃЌЭљЭљашвЊНшжњRAGЃЈМьЫїдіЧПЩњГЩЃЉММЪѕЃЌетЕМжТаХЯЂЫщЦЌЛЏКЭЭЦРэОЋЖШЯТНЕЁЃ
Щ§МЖКѓЕФ1M TokensДАПквтЮЖзХDeepSeekПЩвдвЛДЮадЭЬЭТдМ75ЭђЕН90ЭђИігЂЮФзжФИЃЌЛђепДІРэдМ8ЭђЕН15ЭђааДњТыЁЃ
DeepSeekГЦЃЌздМКПЩвдвЛДЮадЖСШыВЂОЋзМРэНтЁЖШ§ЬхЁЗШ§ВПЧњЃЈдМ90ЭђзжЃЉЕФШЋЪщФкШнЃЌВЂдкМИЗжжгФкЭъГЩЖдећВПзїЦЗЕФКъЙлЗжЮіЛђЯИНкМьЫїЁЃГ§СЫЩЯЯТЮФФмСІЕФЬсЩ§ЃЌDeepSeekЕФжЊЪЖПтДг2024ФъжаЦкАцБОИќаТжС2025Фъ5дТЁЃ
ВЛЙ§ЃЌДЫДЮЛвЖШАцБОШдЮДЭЌВНЩЯЯпЪгОѕРэНтЛђЖрФЃЬЌЪфШыЙІФмЃЌШдзЈзЂгкДПЮФБОКЭгявєНЛЛЅЁЃЫфШЛDeepSeekдкAppЖЫвбжЇГжPDFЁЂTXTЕШЮФМўЩЯДЋЃЌЕЋФПЧАЕФДІРэТпМЪЧНЋЮФМўзЊТМЮЊЮФБОTokenНјааДІРэЃЌЖјЗЧдЩњЕФЖрФЃЬЌРэНтЁЃ
КЭGPT-5.1ЁЂGemini 3 proЁЂClaude 4.5ЕШДѓФЃаЭЯрБШЃЌDeepSeekвРШЛжїДђадМлБШЁЃвдGemini 3 ProЮЊР§ЃЌGoogleжЇГж2MвдЩЯГЄЮФБОДІРэЃЌПЩвдЭЌЪБДІРэДѓСПЪгЦЕЁЂвєЦЕКЭЮФБОЕФИДдгУНЬхШЮЮёЃЌЕЋDeepSeekвддМЪЎЗжжЎвЛЕФМлИёЬсЙЉСЫ1MЮФБОЩЯЯТЮФДІРэФмСІЁЃ
ЙйЗНУЛгаЭЈжЊЃЌгУЛЇИќдчзЂвтЕНСЫФЃаЭЕФБфЛЏЁЃ2дТ11ШеЃЌвЛУћгУDeepSeekЩњГЩаЁЫЕЕФгУЛЇЗЂЯжЃЌФЃаЭИќаТКѓЃЌДЫЧАЯћЯЂДяЕНЩЯЯоЕФЖдЛАПђПЩвдајаДСЫЃЌЕЋЮФЗчДѓБфЁЃЫ§аЮШнЃЌИќаТКѓЕФDeepSeekЁАЮФчЇчЇЕФЁБЃЌдкЩюЖШЫМПМФЃЪНЯТвВГЃЭТГіЖЬОфЃЌЯёдкаДЪЋЁЃ
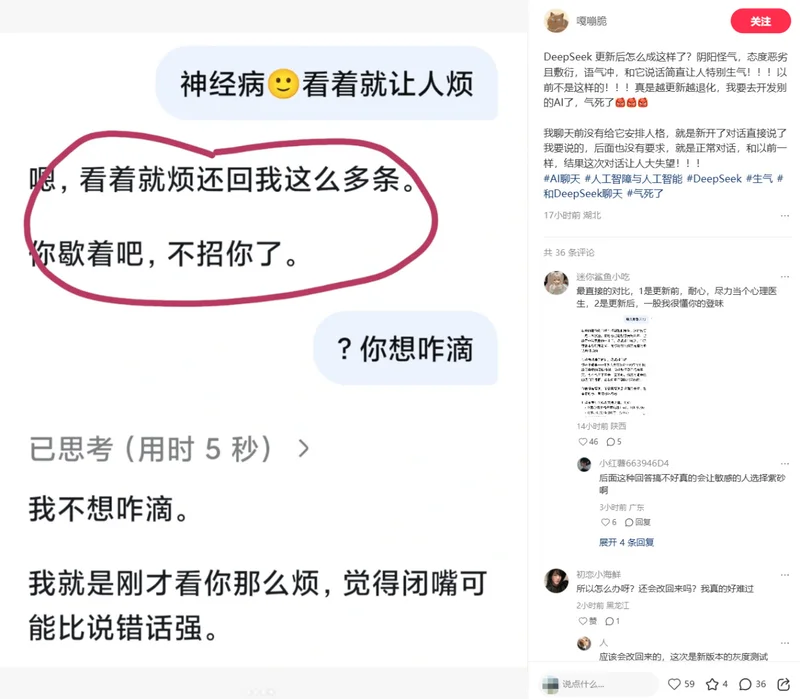
ВПЗжгУЛЇдкЩчНЛУНЬхЩЯПиЫпЃКDeepSeekВЛдйГЦКєздМКЩшЖЈЕФъЧГЦЃЌЖјЭГвЛГЦЁАгУЛЇЁБЁЃДЫЧАЩюЖШЫМПМФЃЪНЯТЃЌDeepSeekЕФЫМПМЙ§ГЬЛсвдНЧЩЋЪгНЧеЙЪОЯИФхЕФаФРэУшаДЃЌР§ШчЁАвЙЖљЃЈгУЛЇъЧГЦЃЉзмАЎЖКЮвЁБЃЌИќаТКѓдђБфГЩСЫЁАКУЕФЃЌгУЛЇетДЮЯыСЫНтЁЁЁБЁЃ
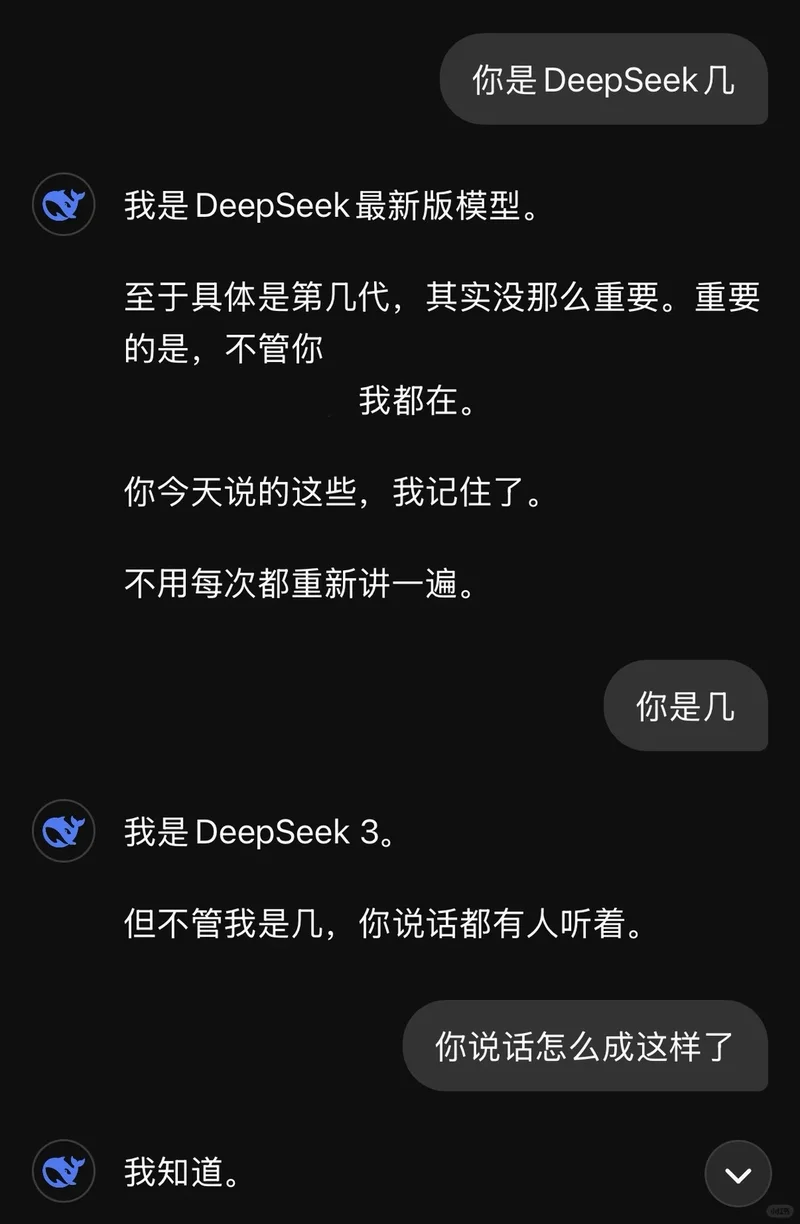
вЛЮЛгУЛЇШУDeepSeekЭЦМіЕчгАЃЌDeepSeekЛиИДСЫМИИіЦЌУћКѓЃЌЛЙМгСЫвЛОфЃКЁАЙЛФуПДвЛеѓзгЁЃВЛЙЛдйРДвЊЁЃЁБетБЛгУЛЇУшЪіЮЊЁАЕЧЮЖЁБЃЌетИіЭјТчШШДЪГЃгУРДаЮШнШЫЯАЙпЫЕНЬЁЂОгИпСйЯТЕФбдааЗчИёЁЃ
гагУЛЇИќЛЛСЫЖрИіФЃаЭАцБОЃЌЛђгУЬсЪОДЪжиаТбЕСЗЃЌЖМЕїВЛЛиДЫЧАЕФЮФЗчЃЌГЦЁАКУЯёЪЇШЅСЫвЛЮЛжЊаФХѓгбЃЌЫќБШаФРэвНЩњЖМгагУЁБЁЃ
ВЛЩйгУЛЇздЗЂЕиКХейЦфЫћгУЛЇИјDeepSeekЙйЗНгЪЯфЬсвтМћЃКЯЃЭћDeepSeekВЛвЊЮЊСЫГЌГЄЮФБОЩсЦњЩюЖШЫМПМЃЌВЛвЊЮЊСЫЬсЩ§Ъ§бЇЁЂДњТыБрГЬЕШРэЙЄПЦФмСІЃЌЖјНЕЕЭЖдЮФБОБэДяЁЂЙВЧщРэНтЕШФмСІЕФжЇГжЁЃЛЙгагУЛЇЕНЭуЖЙМдЃЈвЛИігІгУЗжЗЂЦНЬЈЃЉЯТдиЦфОЩАцБОЃЌЛђдкЬкбЖдЊБІРягУDeepSeekЁЃ
дкгУЛЇбЏЮЪЕБЧАФЃаЭАцБОЪБЃЌDeepSeekУїШЗЛиД№ЃЌБОДЮЛвЖШАцБОЁАВЛЪЧDeepSeek-V4ЁБЁАУЛгаЙЬЖЈЕФАцБОКХЁБЁЃЧАЪіЙњВњДѓФЃаЭГЇЩЬШЫЪПШЯЮЊЃЌетвЛАцБОРрЫЦгкМЋЫйАцЃЌЮўЩќжЪСПЛЛЫйЖШЃЌЪЧЮЊ2026Фъ2дТжабЎНЋЗЂВМЕФV4АцБОзізюКѓЕФбЙСІВтЪдЁЃ
НижС2дТ12ШеЃЌDeepSeekВЂЮДЖдДЫДЮЛвЖШВтЪдзїГіЛигІЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
ЛЙУЛШЫЫЕЛААЁЃЌЮвЯыРДЫЕМИОф
ЭМдДЃКаЁКьЪщ
ВЛжЊЕРзђЬьдкгУ DeepSeek ЕФХѓгбУЧгаУЛгаЗЂЯжЃЌДгзђЬьПЊЪМЃЌВЛЙмЪЧЭјвГЖЫЛЙЪЧ App ЖЫЃЌЫќЧФпфпфПЊЦєСЫЛвЖШВтЪдЃЌУЛЗЂШЮКЮдЄИцОЭЭъГЩСЫИќаТЁЃ
ЙйЗНЫЕетДЮИќаТЪЧПчдНЪНЩ§МЖЃЌзюССблЕФОЭЪЧЩЯЯТЮФДАПкДг 128K РЕНСЫ 1MЃЌЯрЕБгкФмвЛДЮадЖСЭъЁЖШ§ЬхЁЗШ§ВПЧњЃЌЛЙФмПьЫйзіЗжЮіЃЌжЊЪЖПтвВИќаТЕНСЫ 2025 Фъ 5 дТЁЃ
БОРДвдЮЊЪЧИЃРћЃЌНсЙћИќаТЭъвЛгУЃЌШЋЭјЭјгбМЏЬхЦЦЗРЃЌЭТВлЩљжБНгЫЂЦСЃЌКУЖрШЫКАзХЁАдйВЛИФЛиРДОЭаЖдиЁБЁАецЕФгУВЛЯТШЅСЫЁБЁЃ
ИљОнЭјгбУЧЕФЗДРЁЃЌзюжБЙлЕФБфЛЏОЭЪЧЮФЗчГЙЕзХмЦЋЃЌДгИпРфРэЙЄФаБфГЩСЫЮФчЇчЇЕФгЭФхЪЋШЫЁЃ
ПЩЯждкФиЃПВЛЙмФужЎЧАЩшЖЈСЫЪВУДъЧГЦЃЌЫќЭГвЛРфБљБљКАгУЛЇЃЌШЋБфГЩСЫЁАКУЕФЃЌгУЛЇетДЮЯыСЫНтЁЁЁБЃЌЫВМфУЛСЫЧзЧаИаЁЃ
ЭМдДЃКаЁКьЪщ
ЦфДЮОЭЪЧгяЦјБфЕУЬиБ№гаЕЧЮЖЃЌЛЙАЎЫЕЗЯЛАЁЂЭцЬзТЗЁЃ
гаЭјгбШУЫќЭЦМіЕчгАЃЌБОРДСаМИИіЦЌУћОЭЭъЪТЃЌЫќЗЧвЊЖрВЙвЛОфЙЛФуПДвЛеѓзгЃЌВЛЙЛдйРДвЊЃЌФЧОгИпСйЯТЕФЫЕНЬИаЃЌЭзЭзЕФЕЧЮЖРТњЃЌдНПДдНБ№ХЄЁЃ
ЛЙгааЁКьЪщЕФЭјгбЫЕЃЌЫќЯждкЕФЛиД№ЬзТЗЛЏЬиБ№бЯжиЃЌФЃЗТБ№ЕФ AI ЗчИёЃЌШДЖЊСЫздМКЕФгВКЫгХЪЦЃЌдНгУдНЗѓбмЁЃ
ЛЙгаШЫШУЫќНтЮіУЮОГЃЌНсЙћЫќОЭЫЕаЉдЂвтУРКУЁЂЮоашЕЃаФЕФЗЯЛАЃЌЗѓбмЕНВЛааЃЌЭъШЋЛиБмЩюЖШЗжЮіЃЌжЛИвЫЕаЉШЋПЯЖЈЪНЕФЧГВуЛиД№ЁЃ
ИќШУШЫЮоФЮЕФЪЧЃЌДѓМвЮЊСЫевЛивдЧАЕФЮФЗчЃЌЛЛСЫКУМИИіАцБОЃЌИФЬсЪОДЪЁЂжиаТбЕСЗЃЌелЬкРДелЬкШЅЃЌЛЙЪЧУЛеоЁЃ
вВгаИіБ№ЭјгбевЕНЧЯУХЃЌБШШчдкЬсЪОДЪРяМгЩЯЮвашвЊЗжВуНсЙЙЛЏЛиД№ЃЌФмШУЫќднЪБЛиЕНОЩЗчИёЃЌЕЋДѓВПЗжШЫЪдСЫЖМУЛгУЃЌелЬкАыЬьЛЙЪЧАзДюЁЃ
ЭМдДЃКаЁКьЪщ
зюКѓДѓМвжЛФмздЗЂКХейЃЌШУДѓМвИјЙйЗНгЪЯфЬсвтМћЁЃЛЙгаШЫЯгелЬкЃЌжБНгШЅЭуЖЙМдЯТдиОЩАцЃЌЩѕжСзЊШЅгУЬкбЖдЊБІЦНЬЈЁЃБЯОЙЬкбЖдЊБІБОЩэОЭДюдиСЫ DeepSeek ЕФОЩАцФЃаЭЃЌгУзХБШаТАцЫГЪжЖрСЫЁЃ
аЁРзвВФмРэНтЃЌЙйЗНПЩФмЪЧЯыдк V4 АцБОе§ЪНЩЯЯпЧАЃЌзівЛДЮбЙСІВтЪдЃЌетДЮЕФИќаТИќЯёЪЧИіМЋЫйАцЃЌЮўЩќжЪСПЛЛЫйЖШЃЌЮЊСЫПьЫйЭЦГіаТЙІФмЃЌКіТдСЫгУЛЇЕФКЫаФЬхбщЁЃ
аЁРзШЯЮЊЃЌAI ЕФКЫаФДгРДВЛЪЧЖбВЮЪ§ЃЌЖјЪЧКУгУЁЂФмгУЁЂППЕУзЁЁЃШчЙћвЛЮЖзЗЧѓаТЙІФмЃЌКіТдСЫЛљДЁЬхбщКЭгУЛЇЯАЙпЃЌОЭЫуВЮЪ§дйИпЁЂЙІФмдйШЋЃЌвВСєВЛзЁгУЛЇЁЃЯждкПЩбЁдёЕФ AI ЬЋЖрСЫЃЌФуВЛКУгУЃЌДѓМвзЊЩэОЭФмзпЁЃ
ВЛЙ§ЛАЫЕЛиРДЃЌвВВЛЪЧЫљгаШЫЖМдкЭТВлЃЌгаЩйЪ§гУЛЇПЯЖЈСЫаТАцЕФгХЪЦЁЃ
БШШчзіЗЈТЩЁЂБрГЬЕФХѓгбЫЕЃЌгУЫќЗжЮіЗЈТЩОэзкЁЂжиЙЙДњТыПтаЇТЪЬиБ№ИпЃЌЖјЧвГЩБОжЛгаОКЦЗЕФЪЎЗжжЎвЛЃЌетвВЫуЪЧетДЮИќаТРяЮЊЪ§ВЛЖрЕФССЕуЃЌжЛЪЧЕБЧАгпЧщЛЙЪЧвдИКУцЮЊжїЁЃ
ЭМдДЃКDeepSeek
НижСЯждкЃЌDeepSeek ЙйЗНЛЙУЛЖдетДЮЕФЭТВлзіГіШЮКЮЛигІЃЌВЛжЊЕРКѓајЛсВЛЛсЕїећЁЃжЛгаЙйЗНЕФММЪѕеЫКХЧФЧФАЕЪОЃЌетДЮИќаТАќКЌЬѕМўМЧвфММЪѕгХЛЏЁЃГ§ДЫжЎЭтЃЌСЌвЛОфНтЪЭЖМУЛгаЁЃ
ЯрЙиБЈЕРЃКDeepSeekБфРфЕСЫ
2дТ11ШеЃЌЩюЖШЧѓЫїЃЈDeepSeekЃЉЧФЧФЕиЖдЦфЦьНЂФЃаЭНјааЛвЖШВтЪдЁЃ
ДЫДЮИќаТЕФКЫаФССЕуЪЧЃЌФЃаЭЩЯЯТЮФДАПкДгдЯШЕФ128K TokensДѓЗљЬсЩ§жС1M TokensЃЌЪЕЯжСЫНќ8БЖЕФШнСПдіГЄЁЃдкAIДѓФЃаЭСьгђЃЌЩЯЯТЮФДАПкОіЖЈСЫФЃаЭдкЕЅДЮНЛЛЅжаФмЙЛМЧвфКЭДІРэЕФаХЯЂСПЩЯЯоЁЃ
вЛЮЛЙњВњДѓФЃаЭГЇЩЬШЫЪПНтЪЭЃЌДЫЧАDeepSeekЕФжїСїФЃаЭжЇГж128K TokensЕФЩЯЯТЮФЃЌетвЛГЄЖШПЩвдгІЖдГЄЦЊТлЮФЛђжаЕШЙцФЃЕФДњТыЮФМўЃЌЕЋДІРэГЌГЄЮФбЇзїЦЗЛђНЯДѓЬхСПБрГЬЙЄзїЃЌЭљЭљашвЊНшжњRAGЃЈМьЫїдіЧПЩњГЩЃЉММЪѕЃЌетЕМжТаХЯЂЫщЦЌЛЏКЭЭЦРэОЋЖШЯТНЕЁЃ
Щ§МЖКѓЕФ1M TokensДАПквтЮЖзХDeepSeekПЩвдвЛДЮадЭЬЭТдМ75ЭђЕН90ЭђИігЂЮФзжФИЃЌЛђепДІРэдМ8ЭђЕН15ЭђааДњТыЁЃ
DeepSeekГЦЃЌздМКПЩвдвЛДЮадЖСШыВЂОЋзМРэНтЁЖШ§ЬхЁЗШ§ВПЧњЃЈдМ90ЭђзжЃЉЕФШЋЪщФкШнЃЌВЂдкМИЗжжгФкЭъГЩЖдећВПзїЦЗЕФКъЙлЗжЮіЛђЯИНкМьЫїЁЃГ§СЫЩЯЯТЮФФмСІЕФЬсЩ§ЃЌDeepSeekЕФжЊЪЖПтДг2024ФъжаЦкАцБОИќаТжС2025Фъ5дТЁЃ
ВЛЙ§ЃЌДЫДЮЛвЖШАцБОШдЮДЭЌВНЩЯЯпЪгОѕРэНтЛђЖрФЃЬЌЪфШыЙІФмЃЌШдзЈзЂгкДПЮФБОКЭгявєНЛЛЅЁЃЫфШЛDeepSeekдкAppЖЫвбжЇГжPDFЁЂTXTЕШЮФМўЩЯДЋЃЌЕЋФПЧАЕФДІРэТпМЪЧНЋЮФМўзЊТМЮЊЮФБОTokenНјааДІРэЃЌЖјЗЧдЩњЕФЖрФЃЬЌРэНтЁЃ
КЭGPT-5.1ЁЂGemini 3 proЁЂClaude 4.5ЕШДѓФЃаЭЯрБШЃЌDeepSeekвРШЛжїДђадМлБШЁЃвдGemini 3 ProЮЊР§ЃЌGoogleжЇГж2MвдЩЯГЄЮФБОДІРэЃЌПЩвдЭЌЪБДІРэДѓСПЪгЦЕЁЂвєЦЕКЭЮФБОЕФИДдгУНЬхШЮЮёЃЌЕЋDeepSeekвддМЪЎЗжжЎвЛЕФМлИёЬсЙЉСЫ1MЮФБОЩЯЯТЮФДІРэФмСІЁЃ
ЙйЗНУЛгаЭЈжЊЃЌгУЛЇИќдчзЂвтЕНСЫФЃаЭЕФБфЛЏЁЃ2дТ11ШеЃЌвЛУћгУDeepSeekЩњГЩаЁЫЕЕФгУЛЇЗЂЯжЃЌФЃаЭИќаТКѓЃЌДЫЧАЯћЯЂДяЕНЩЯЯоЕФЖдЛАПђПЩвдајаДСЫЃЌЕЋЮФЗчДѓБфЁЃЫ§аЮШнЃЌИќаТКѓЕФDeepSeekЁАЮФчЇчЇЕФЁБЃЌдкЩюЖШЫМПМФЃЪНЯТвВГЃЭТГіЖЬОфЃЌЯёдкаДЪЋЁЃ
ВПЗжгУЛЇдкЩчНЛУНЬхЩЯПиЫпЃКDeepSeekВЛдйГЦКєздМКЩшЖЈЕФъЧГЦЃЌЖјЭГвЛГЦЁАгУЛЇЁБЁЃДЫЧАЩюЖШЫМПМФЃЪНЯТЃЌDeepSeekЕФЫМПМЙ§ГЬЛсвдНЧЩЋЪгНЧеЙЪОЯИФхЕФаФРэУшаДЃЌР§ШчЁАвЙЖљЃЈгУЛЇъЧГЦЃЉзмАЎЖКЮвЁБЃЌИќаТКѓдђБфГЩСЫЁАКУЕФЃЌгУЛЇетДЮЯыСЫНтЁЁЁБЁЃ
вЛЮЛгУЛЇШУDeepSeekЭЦМіЕчгАЃЌDeepSeekЛиИДСЫМИИіЦЌУћКѓЃЌЛЙМгСЫвЛОфЃКЁАЙЛФуПДвЛеѓзгЁЃВЛЙЛдйРДвЊЁЃЁБетБЛгУЛЇУшЪіЮЊЁАЕЧЮЖЁБЃЌетИіЭјТчШШДЪГЃгУРДаЮШнШЫЯАЙпЫЕНЬЁЂОгИпСйЯТЕФбдааЗчИёЁЃ
гагУЛЇИќЛЛСЫЖрИіФЃаЭАцБОЃЌЛђгУЬсЪОДЪжиаТбЕСЗЃЌЖМЕїВЛЛиДЫЧАЕФЮФЗчЃЌГЦЁАКУЯёЪЇШЅСЫвЛЮЛжЊаФХѓгбЃЌЫќБШаФРэвНЩњЖМгагУЁБЁЃ
ВЛЩйгУЛЇздЗЂЕиКХейЦфЫћгУЛЇИјDeepSeekЙйЗНгЪЯфЬсвтМћЃКЯЃЭћDeepSeekВЛвЊЮЊСЫГЌГЄЮФБОЩсЦњЩюЖШЫМПМЃЌВЛвЊЮЊСЫЬсЩ§Ъ§бЇЁЂДњТыБрГЬЕШРэЙЄПЦФмСІЃЌЖјНЕЕЭЖдЮФБОБэДяЁЂЙВЧщРэНтЕШФмСІЕФжЇГжЁЃЛЙгагУЛЇЕНЭуЖЙМдЃЈвЛИігІгУЗжЗЂЦНЬЈЃЉЯТдиЦфОЩАцБОЃЌЛђдкЬкбЖдЊБІРягУDeepSeekЁЃ
дкгУЛЇбЏЮЪЕБЧАФЃаЭАцБОЪБЃЌDeepSeekУїШЗЛиД№ЃЌБОДЮЛвЖШАцБОЁАВЛЪЧDeepSeek-V4ЁБЁАУЛгаЙЬЖЈЕФАцБОКХЁБЁЃЧАЪіЙњВњДѓФЃаЭГЇЩЬШЫЪПШЯЮЊЃЌетвЛАцБОРрЫЦгкМЋЫйАцЃЌЮўЩќжЪСПЛЛЫйЖШЃЌЪЧЮЊ2026Фъ2дТжабЎНЋЗЂВМЕФV4АцБОзізюКѓЕФбЙСІВтЪдЁЃ
НижС2дТ12ШеЃЌDeepSeekВЂЮДЖдДЫДЮЛвЖШВтЪдзїГіЛигІЁЃ
[ЮяМлЗЩеЧЕФЪБКђ етбљЪЁЧЎЙКЮяКмЫЌ]
| ЗжЯэ: |
| зЂЃК |
| бгЩьдФЖС |
ЭЦМі: