




華爾街徹夜難眠,Gemini 3屠榜金融"最難考試"
叁級考試論述題示例:探討資產配置理論,比較兩種資本資產定價模型(CAPM)的應用前提與估計精度,論證其適用差異。
結果顯示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依據既定標准通過了所有級別考核,部分成績甚至接近滿分。
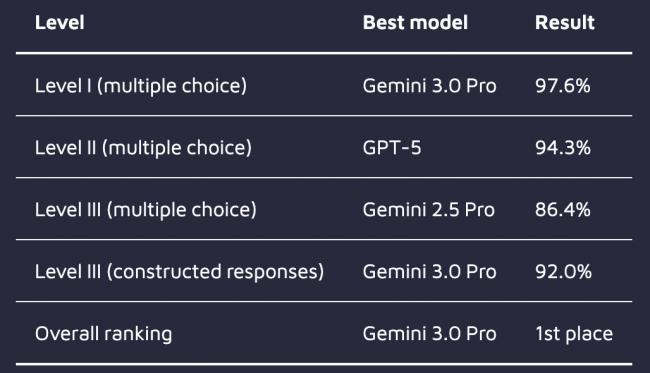
Gemini與GPT-5雙雄領跑
在壹級考試(基礎多選題)中,Gemini 3.0 Pro以97.6%的驚人准確率創下歷史新高。GPT-5緊隨其後,斬獲96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是測試中表現“墊底”的DeepSeek-V3.1,准確率也高達90.9%。
來到側重應用與分析(案例研究)的贰級考試,GPT-5反超奪魁,准確率達94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分別以93.2%和92.6%緊隨其後。
研究人員驚歎道,這些模型在此階段的表現“近乎完美”。不過,“道德規范”(Ethics)板塊依然是AI的軟肋。數據顯示,即便最強模型,在贰級考試的道德類題目中也有17%到21%的相對錯誤率。
到了最復雜的叁級考試(包含選擇題與開放式問答),Gemini 2.5 Pro在選擇題部分拔得頭籌,准確率為86.4%。但在更考驗生成能力的“論述題”環節,Gemini 3.0 Pro展現了統治力,得分率高達92.0%,相比前代模型的82.8%有了質的飛躍。
為了對開放式問答環節進行評分,研究團隊使用了o4-mini模型來實現自動化批改。
研究人員坦言,這種做法可能會引入測量誤差,並產生某種“篇幅偏見”(verbosity bias),即回答越長,得分往往越高。因此,這些測試結果只能視為基於模型的估算值。
通過標准沿用了過往合格標准:
壹級考試要求單科不低於 60%,總分不低於 70%;
贰級考試要求單科不低於 50%,總分不低於 60%;
叁級考試則要求在選擇題和論述題兩部分中,平均得分率至少達到 63%。
研究人員指出,測試結果表明“推理模型的專業能力已超越初級至中級金融分析師的要求,未來甚至可能達到資深分析師的水准”。
如果說此前的大語言模型已經掌握了壹級和贰級考試中那些“既定的規范化知識”(codified knowledge),那麼最新壹代模型正在習得叁級考試所必需的復雜“綜合研判能力”(synthesis skills)。
當然,慣常的局限性依然存在。基准測試,尤其是選擇題形式,只能作為評估模型能力和潛在經濟價值的參考,猶如管中窺豹。
盡管如此,短短兩年間從“不及格”到“近乎滿分”的巨大飛躍,足以凸顯 AI 在專業領域的進化速度之快。
[加西網正招聘多名全職sales 待遇優]
這條新聞還沒有人評論喔,等著您的高見呢
結果顯示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依據既定標准通過了所有級別考核,部分成績甚至接近滿分。
Gemini與GPT-5雙雄領跑
在壹級考試(基礎多選題)中,Gemini 3.0 Pro以97.6%的驚人准確率創下歷史新高。GPT-5緊隨其後,斬獲96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是測試中表現“墊底”的DeepSeek-V3.1,准確率也高達90.9%。
來到側重應用與分析(案例研究)的贰級考試,GPT-5反超奪魁,准確率達94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分別以93.2%和92.6%緊隨其後。
研究人員驚歎道,這些模型在此階段的表現“近乎完美”。不過,“道德規范”(Ethics)板塊依然是AI的軟肋。數據顯示,即便最強模型,在贰級考試的道德類題目中也有17%到21%的相對錯誤率。
到了最復雜的叁級考試(包含選擇題與開放式問答),Gemini 2.5 Pro在選擇題部分拔得頭籌,准確率為86.4%。但在更考驗生成能力的“論述題”環節,Gemini 3.0 Pro展現了統治力,得分率高達92.0%,相比前代模型的82.8%有了質的飛躍。
為了對開放式問答環節進行評分,研究團隊使用了o4-mini模型來實現自動化批改。
研究人員坦言,這種做法可能會引入測量誤差,並產生某種“篇幅偏見”(verbosity bias),即回答越長,得分往往越高。因此,這些測試結果只能視為基於模型的估算值。
通過標准沿用了過往合格標准:
壹級考試要求單科不低於 60%,總分不低於 70%;
贰級考試要求單科不低於 50%,總分不低於 60%;
叁級考試則要求在選擇題和論述題兩部分中,平均得分率至少達到 63%。
研究人員指出,測試結果表明“推理模型的專業能力已超越初級至中級金融分析師的要求,未來甚至可能達到資深分析師的水准”。
如果說此前的大語言模型已經掌握了壹級和贰級考試中那些“既定的規范化知識”(codified knowledge),那麼最新壹代模型正在習得叁級考試所必需的復雜“綜合研判能力”(synthesis skills)。
當然,慣常的局限性依然存在。基准測試,尤其是選擇題形式,只能作為評估模型能力和潛在經濟價值的參考,猶如管中窺豹。
盡管如此,短短兩年間從“不及格”到“近乎滿分”的巨大飛躍,足以凸顯 AI 在專業領域的進化速度之快。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
推薦: