




華爾街徹夜難眠,Gemini 3屠榜金融"最難考試"
被譽為“黃金職業通行證”的人類知識堡壘,CFA考試悄然陷落。最新的推理模型不僅輕松通過了CFA叁級考試,還創造了幾乎滿分的成績。
AI壹分鍾,人類拾年功!
壹覺醒來,AI推理模型已橫掃特許金融分析師CFA考試。
要拿下享譽全球的CFA(特許金融分析師)證書,對於人類考生來說,這通常意味著數年的煎熬和至少1000小時的苦讀。
但AI這次取得的成績有點讓人“破防”了:推理模型不僅輕松通過了叁級考試,還創造了幾乎滿分的成績。
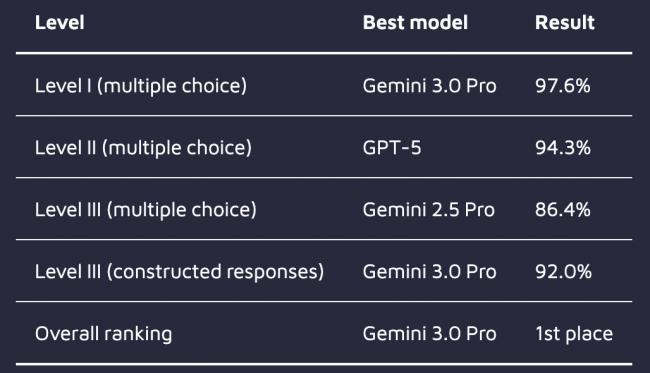
具體而言,在壹級考試中,Gemini 3.0 Pro創下97.6%的歷史最高紀錄。
贰級考試中,GPT-5以94.3%的成績領先。
在叁級考試中,Gemini 2.5 Pro在選擇題部分取得86.4%的最高分,而Gemini 3.0 Pro在問答題部分達到92.0%的優異成績。
那些想去華爾街工作的畢業生,可能睡不著了。

金融界“最難考試”被AI通關
特許金融分析師(Chartered Financial Analyst,CFA)認證被公認為金融領域難度最大的資格認證之壹。
全部叁級考試,需要逐級通過,涵蓋從基礎知識到應用分析、直至復雜投資組合構建的進階能力。
在2023年,當時最強的AI模型只能解答部分CFA試題,表現參差不齊。
當時的研究證實AI能搞定CFA壹級和贰級考試,但當時它們在叁級考試面前卻碰了壁,因為搞不定那些復雜的論述題(essay questions)。
鏈接:https://aclanthology.org/2024.emnlp-industry.80/
到了今年7月,AI已經能在幾分鍾之內通過最難的CFA考試:

來自紐約大學斯特恩商學院(NYU Stern)與AI財富管理平台GoodFin的研究人員想探究:AI是否已經具備了處理“專業金融決策所需的、高風險的分析推理”能力?
研究團隊對23個大語言模型進行了“大閱兵”,測試它們處理CFA叁級模擬試題中選擇題和論述題的能力。
要知道,CFA叁級考試的核心可是最考驗功力的投資組合管理和財富規劃。

CFA叁級考試主題和權重
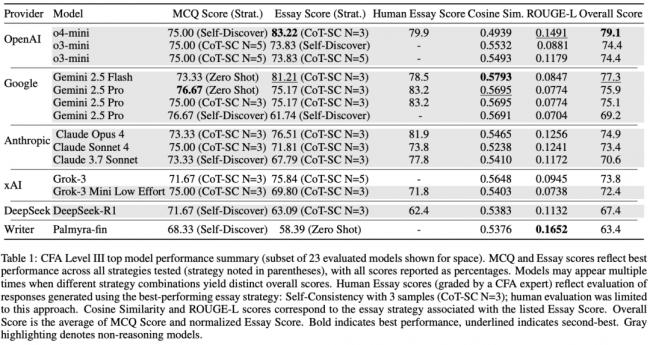
結果顯示,o4-mini、Gemini 2.5 Pro和Claude Opus等前沿推理模型,在運用“思維鏈”(chain-of-thought)提示詞技術後,均成功通關。
鏈接:https://arxiv.org/pdf/2507.02954
“我認為毫無疑問,這項技術將在未來徹底重塑整個行業。”GoodFin的創始人兼CEO Anna Joo Fee如是說。

本月9日,最新研究表明,當前這代推理模型不僅全部通過了叁級考試,某些科目甚至接近滿分。
預印本鏈接;https://arxiv.org/abs/2512.08270
標題:Reasoning Models Ace the CFA Exams
AI的新成績讓人破防
來自哥倫比亞大學、倫斯勒理工學院和北卡羅來納大學的研究團隊,使用包含980道考題的題庫對6款推理模型進行測試。
他們編制了壹套涵蓋CFA(特許金融分析師)全部叁個等級的模擬試題,共計980道題目。
壹級試題集(Level I Set):包含叁套試卷,總計540道多選題(Multiple Choice Questions, MCQs),每套180題。
贰級試題集(Level II Set):包含兩套試卷,總計176道選擇題(每套88題),每套試卷由22個“案例題組”(item sets)組成,每個題組包含4個問題。
叁級試題集(Level III Set):包含叁套試卷,總計264道題目(每套88題);每套試卷采用混合形式,包含11個案例題組(共44道選擇題)和11個論述型案例分析(constructed-response case studies,共44道論述題/CRQs)。
壹級試題集(Level I Set):包含叁套試卷,總計540道多選題(Multiple Choice Questions, MCQs),每套180題。
贰級試題集(Level II Set):包含兩套試卷,總計176道選擇題(每套88題),每套試卷由22個“案例題組”(item sets)組成,每個題組包含4個問題。
叁級試題集(Level III Set):包含叁套試卷,總計264道題目(每套88題);每套試卷采用混合形式,包含11個案例題組(共44道選擇題)和11個論述型案例分析(constructed-response case studies,共44道論述題/CRQs)。
盡管正式CFA考試中論述題的具體數量和分值權重會有所變化,但這些模擬試題遵循了標准且具有代表性的結構。

(注:案例文本以藍色標注,問題以紅色呈現,選項以綠色顯示,所有示例均為示意性內容而非真實考題)
壹級考試選擇題示例:聚焦道德與職業行為准則,通過利益沖突情境考查考生對合規判斷的掌握。
贰級考試選擇題:圍繞股權投資實務,測試對IPO牽頭行核心職責的理解與辨析能力。
叁級考試論述題示例:設定財務報告分析情境,要求結合通脹環境變化,判斷並說明外幣報表折算方法的適用性。
叁級考試選擇題示例:涉及私募市場估值,需計算債券市值,並綜合評估違約風險與清償順位對投資價值的影響。
叁級考試論述題示例:探討資產配置理論,比較兩種資本資產定價模型(CAPM)的應用前提與估計精度,論證其適用差異。
壹級考試選擇題示例:聚焦道德與職業行為准則,通過利益沖突情境考查考生對合規判斷的掌握。
贰級考試選擇題:圍繞股權投資實務,測試對IPO牽頭行核心職責的理解與辨析能力。
叁級考試論述題示例:設定財務報告分析情境,要求結合通脹環境變化,判斷並說明外幣報表折算方法的適用性。
叁級考試選擇題示例:涉及私募市場估值,需計算債券市值,並綜合評估違約風險與清償順位對投資價值的影響。
叁級考試論述題示例:探討資產配置理論,比較兩種資本資產定價模型(CAPM)的應用前提與估計精度,論證其適用差異。
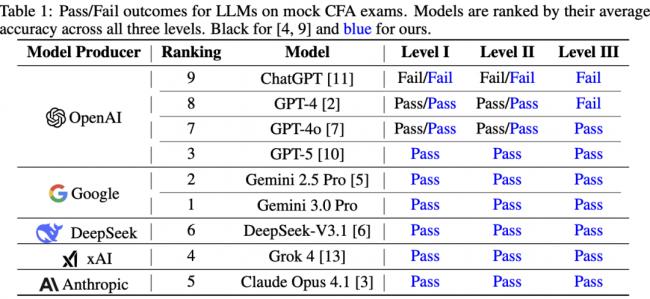
結果顯示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依據既定標准通過了所有級別考核,部分成績甚至接近滿分。
Gemini與GPT-5雙雄領跑
在壹級考試(基礎多選題)中,Gemini 3.0 Pro以97.6%的驚人准確率創下歷史新高。GPT-5緊隨其後,斬獲96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是測試中表現“墊底”的DeepSeek-V3.1,准確率也高達90.9%。
來到側重應用與分析(案例研究)的贰級考試,GPT-5反超奪魁,准確率達94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分別以93.2%和92.6%緊隨其後。
研究人員驚歎道,這些模型在此階段的表現“近乎完美”。不過,“道德規范”(Ethics)板塊依然是AI的軟肋。數據顯示,即便最強模型,在贰級考試的道德類題目中也有17%到21%的相對錯誤率。
到了最復雜的叁級考試(包含選擇題與開放式問答),Gemini 2.5 Pro在選擇題部分拔得頭籌,准確率為86.4%。但在更考驗生成能力的“論述題”環節,Gemini 3.0 Pro展現了統治力,得分率高達92.0%,相比前代模型的82.8%有了質的飛躍。
為了對開放式問答環節進行評分,研究團隊使用了o4-mini模型來實現自動化批改。
研究人員坦言,這種做法可能會引入測量誤差,並產生某種“篇幅偏見”(verbosity bias),即回答越長,得分往往越高。因此,這些測試結果只能視為基於模型的估算值。
通過標准沿用了過往合格標准:
壹級考試要求單科不低於 60%,總分不低於 70%;
贰級考試要求單科不低於 50%,總分不低於 60%;
叁級考試則要求在選擇題和論述題兩部分中,平均得分率至少達到 63%。
研究人員指出,測試結果表明“推理模型的專業能力已超越初級至中級金融分析師的要求,未來甚至可能達到資深分析師的水准”。
如果說此前的大語言模型已經掌握了壹級和贰級考試中那些“既定的規范化知識”(codified knowledge),那麼最新壹代模型正在習得叁級考試所必需的復雜“綜合研判能力”(synthesis skills)。
當然,慣常的局限性依然存在。基准測試,尤其是選擇題形式,只能作為評估模型能力和潛在經濟價值的參考,猶如管中窺豹。
盡管如此,短短兩年間從“不及格”到“近乎滿分”的巨大飛躍,足以凸顯 AI 在專業領域的進化速度之快。
AI通關CFA了,然後呢?
當機器能輕松考下你引以為傲的證書,能代寫你的報告,能處理你的數據,甚至很快在分析能力上都能把你甩在身後時,你該怎麼辦?
媒體行業創業者兼出版人Matthias Bastian認為,會考試 ≠ 能幹活:
考場得意,不代表職場如意。通過考試並不意味著模型能勝任金融分析師的日常瑣碎工作(daily grind),比如與客戶面談、評估復雜的市場情緒,以及在信息不全的情況下做出關鍵決策。
研究還特別提到,模型在“道德倫理”類題目上依然最吃力,因為這類問題往往需要深度的情境理解和價值判斷。畢竟,考試考察的是孤立的知識點,而非在復雜多變的現實世界中靈活運用知識的能力。
此外,研究人員也無法完全排除“數據污染”的可能性。雖然測試使用的是最新的付費受版權保護材料,但相關考題可能早已通過公共數據集中的改寫或變體內容,滲透進了模型的訓練數據中。這意味著,模型可能僅僅是“背過”了答案,而非真正通過邏輯推理得出了結果。
考場得意,不代表職場如意。通過考試並不意味著模型能勝任金融分析師的日常瑣碎工作(daily grind),比如與客戶面談、評估復雜的市場情緒,以及在信息不全的情況下做出關鍵決策。
研究還特別提到,模型在“道德倫理”類題目上依然最吃力,因為這類問題往往需要深度的情境理解和價值判斷。畢竟,考試考察的是孤立的知識點,而非在復雜多變的現實世界中靈活運用知識的能力。
此外,研究人員也無法完全排除“數據污染”的可能性。雖然測試使用的是最新的付費受版權保護材料,但相關考題可能早已通過公共數據集中的改寫或變體內容,滲透進了模型的訓練數據中。這意味著,模型可能僅僅是“背過”了答案,而非真正通過邏輯推理得出了結果。
特許金融分析師、高盛全球投資研究部數據戰略團隊負責人Ingrid Tierens博士,在AI通過CFA認證考試之際,撰文表示,AI還不能替代分析師。
她認為,AI通關CFA是意料之中的勝利,畢竟在金融領域之外的考試中,AI已經拿下了頂級超級,比如奧數競賽等。
CFA考試正是AI最擅長的領域:面對界定清晰的知識體系、海量的同質化訓練數據,以及全球統壹、歷久不變的標准化考試形式,AI理應表現出色。

其次,正如馬克·吐溫那句名言:“歷史不會重演,但往往驚人地相似。”

AI的進步與金融業的歷史軌跡如出壹轍,同時也提醒我們,這種進步往往不是線性的,而是爆發式的。從紙筆到計算器,再到電腦、Excel表格、Python編程,金融業壹直在擁抱技術變革。
在“價值投資之父”Benjamin Graham身上,這壹歷史視角得到了完美體現。

他還是CFA資格認證背後的核心推動者
早在1963年,當計算機剛剛踏入投資界之時,Graham就在《金融分析師期刊》(Financial Analysts Journal)上發表了題為《金融分析的未來》的文章,對行業前景樂觀至極。
AI已經勢不可擋,關鍵在於如何“用好它”:在能創造價值的環節,在合理的安全邊界(guardrails)內,充分發揮AI的威力,這將成為核心優勢。把那些消在繁瑣分析上的時間省下來,花更多時間讓思考更具戰略高度、解決更復雜的問題以及客戶溝通更有深度。
最後,想靠AI“上位”徹底取代投資專家?短期內門兒都沒有。
想要拿下入行的敲門磚,你得證明自己能在瞬息萬變的市場中靈活運用知識,能進行批判性思考,能創新——這可比死記硬背通過CFA。
卓越的投資業績,往往來自於捕捉那些被市場忽視的“離群點”和隱秘信息,遠非考試可覆蓋。
最後,重溫壹下Benjamin Graham在1963年那篇文章中的結語,至今讀來依然振聾發聵:
無論世事如何變遷,有壹點我深信不疑:未來的金融分析之路,將和過去壹樣,通往成功的路徑絕不止壹條。
[物價飛漲的時候 這樣省錢購物很爽]
還沒人說話啊,我想來說幾句
AI壹分鍾,人類拾年功!
壹覺醒來,AI推理模型已橫掃特許金融分析師CFA考試。
要拿下享譽全球的CFA(特許金融分析師)證書,對於人類考生來說,這通常意味著數年的煎熬和至少1000小時的苦讀。
但AI這次取得的成績有點讓人“破防”了:推理模型不僅輕松通過了叁級考試,還創造了幾乎滿分的成績。
具體而言,在壹級考試中,Gemini 3.0 Pro創下97.6%的歷史最高紀錄。
贰級考試中,GPT-5以94.3%的成績領先。
在叁級考試中,Gemini 2.5 Pro在選擇題部分取得86.4%的最高分,而Gemini 3.0 Pro在問答題部分達到92.0%的優異成績。
那些想去華爾街工作的畢業生,可能睡不著了。
金融界“最難考試”被AI通關
特許金融分析師(Chartered Financial Analyst,CFA)認證被公認為金融領域難度最大的資格認證之壹。
全部叁級考試,需要逐級通過,涵蓋從基礎知識到應用分析、直至復雜投資組合構建的進階能力。
在2023年,當時最強的AI模型只能解答部分CFA試題,表現參差不齊。
當時的研究證實AI能搞定CFA壹級和贰級考試,但當時它們在叁級考試面前卻碰了壁,因為搞不定那些復雜的論述題(essay questions)。
鏈接:https://aclanthology.org/2024.emnlp-industry.80/
到了今年7月,AI已經能在幾分鍾之內通過最難的CFA考試:
來自紐約大學斯特恩商學院(NYU Stern)與AI財富管理平台GoodFin的研究人員想探究:AI是否已經具備了處理“專業金融決策所需的、高風險的分析推理”能力?
研究團隊對23個大語言模型進行了“大閱兵”,測試它們處理CFA叁級模擬試題中選擇題和論述題的能力。
要知道,CFA叁級考試的核心可是最考驗功力的投資組合管理和財富規劃。
CFA叁級考試主題和權重
結果顯示,o4-mini、Gemini 2.5 Pro和Claude Opus等前沿推理模型,在運用“思維鏈”(chain-of-thought)提示詞技術後,均成功通關。
鏈接:https://arxiv.org/pdf/2507.02954
“我認為毫無疑問,這項技術將在未來徹底重塑整個行業。”GoodFin的創始人兼CEO Anna Joo Fee如是說。
本月9日,最新研究表明,當前這代推理模型不僅全部通過了叁級考試,某些科目甚至接近滿分。
預印本鏈接;https://arxiv.org/abs/2512.08270
標題:Reasoning Models Ace the CFA Exams
AI的新成績讓人破防
來自哥倫比亞大學、倫斯勒理工學院和北卡羅來納大學的研究團隊,使用包含980道考題的題庫對6款推理模型進行測試。
他們編制了壹套涵蓋CFA(特許金融分析師)全部叁個等級的模擬試題,共計980道題目。
壹級試題集(Level I Set):包含叁套試卷,總計540道多選題(Multiple Choice Questions, MCQs),每套180題。
贰級試題集(Level II Set):包含兩套試卷,總計176道選擇題(每套88題),每套試卷由22個“案例題組”(item sets)組成,每個題組包含4個問題。
叁級試題集(Level III Set):包含叁套試卷,總計264道題目(每套88題);每套試卷采用混合形式,包含11個案例題組(共44道選擇題)和11個論述型案例分析(constructed-response case studies,共44道論述題/CRQs)。
壹級試題集(Level I Set):包含叁套試卷,總計540道多選題(Multiple Choice Questions, MCQs),每套180題。
贰級試題集(Level II Set):包含兩套試卷,總計176道選擇題(每套88題),每套試卷由22個“案例題組”(item sets)組成,每個題組包含4個問題。
叁級試題集(Level III Set):包含叁套試卷,總計264道題目(每套88題);每套試卷采用混合形式,包含11個案例題組(共44道選擇題)和11個論述型案例分析(constructed-response case studies,共44道論述題/CRQs)。
盡管正式CFA考試中論述題的具體數量和分值權重會有所變化,但這些模擬試題遵循了標准且具有代表性的結構。
(注:案例文本以藍色標注,問題以紅色呈現,選項以綠色顯示,所有示例均為示意性內容而非真實考題)
壹級考試選擇題示例:聚焦道德與職業行為准則,通過利益沖突情境考查考生對合規判斷的掌握。
贰級考試選擇題:圍繞股權投資實務,測試對IPO牽頭行核心職責的理解與辨析能力。
叁級考試論述題示例:設定財務報告分析情境,要求結合通脹環境變化,判斷並說明外幣報表折算方法的適用性。
叁級考試選擇題示例:涉及私募市場估值,需計算債券市值,並綜合評估違約風險與清償順位對投資價值的影響。
叁級考試論述題示例:探討資產配置理論,比較兩種資本資產定價模型(CAPM)的應用前提與估計精度,論證其適用差異。
壹級考試選擇題示例:聚焦道德與職業行為准則,通過利益沖突情境考查考生對合規判斷的掌握。
贰級考試選擇題:圍繞股權投資實務,測試對IPO牽頭行核心職責的理解與辨析能力。
叁級考試論述題示例:設定財務報告分析情境,要求結合通脹環境變化,判斷並說明外幣報表折算方法的適用性。
叁級考試選擇題示例:涉及私募市場估值,需計算債券市值,並綜合評估違約風險與清償順位對投資價值的影響。
叁級考試論述題示例:探討資產配置理論,比較兩種資本資產定價模型(CAPM)的應用前提與估計精度,論證其適用差異。
結果顯示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依據既定標准通過了所有級別考核,部分成績甚至接近滿分。
Gemini與GPT-5雙雄領跑
在壹級考試(基礎多選題)中,Gemini 3.0 Pro以97.6%的驚人准確率創下歷史新高。GPT-5緊隨其後,斬獲96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是測試中表現“墊底”的DeepSeek-V3.1,准確率也高達90.9%。
來到側重應用與分析(案例研究)的贰級考試,GPT-5反超奪魁,准確率達94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分別以93.2%和92.6%緊隨其後。
研究人員驚歎道,這些模型在此階段的表現“近乎完美”。不過,“道德規范”(Ethics)板塊依然是AI的軟肋。數據顯示,即便最強模型,在贰級考試的道德類題目中也有17%到21%的相對錯誤率。
到了最復雜的叁級考試(包含選擇題與開放式問答),Gemini 2.5 Pro在選擇題部分拔得頭籌,准確率為86.4%。但在更考驗生成能力的“論述題”環節,Gemini 3.0 Pro展現了統治力,得分率高達92.0%,相比前代模型的82.8%有了質的飛躍。
為了對開放式問答環節進行評分,研究團隊使用了o4-mini模型來實現自動化批改。
研究人員坦言,這種做法可能會引入測量誤差,並產生某種“篇幅偏見”(verbosity bias),即回答越長,得分往往越高。因此,這些測試結果只能視為基於模型的估算值。
通過標准沿用了過往合格標准:
壹級考試要求單科不低於 60%,總分不低於 70%;
贰級考試要求單科不低於 50%,總分不低於 60%;
叁級考試則要求在選擇題和論述題兩部分中,平均得分率至少達到 63%。
研究人員指出,測試結果表明“推理模型的專業能力已超越初級至中級金融分析師的要求,未來甚至可能達到資深分析師的水准”。
如果說此前的大語言模型已經掌握了壹級和贰級考試中那些“既定的規范化知識”(codified knowledge),那麼最新壹代模型正在習得叁級考試所必需的復雜“綜合研判能力”(synthesis skills)。
當然,慣常的局限性依然存在。基准測試,尤其是選擇題形式,只能作為評估模型能力和潛在經濟價值的參考,猶如管中窺豹。
盡管如此,短短兩年間從“不及格”到“近乎滿分”的巨大飛躍,足以凸顯 AI 在專業領域的進化速度之快。
AI通關CFA了,然後呢?
當機器能輕松考下你引以為傲的證書,能代寫你的報告,能處理你的數據,甚至很快在分析能力上都能把你甩在身後時,你該怎麼辦?
媒體行業創業者兼出版人Matthias Bastian認為,會考試 ≠ 能幹活:
考場得意,不代表職場如意。通過考試並不意味著模型能勝任金融分析師的日常瑣碎工作(daily grind),比如與客戶面談、評估復雜的市場情緒,以及在信息不全的情況下做出關鍵決策。
研究還特別提到,模型在“道德倫理”類題目上依然最吃力,因為這類問題往往需要深度的情境理解和價值判斷。畢竟,考試考察的是孤立的知識點,而非在復雜多變的現實世界中靈活運用知識的能力。
此外,研究人員也無法完全排除“數據污染”的可能性。雖然測試使用的是最新的付費受版權保護材料,但相關考題可能早已通過公共數據集中的改寫或變體內容,滲透進了模型的訓練數據中。這意味著,模型可能僅僅是“背過”了答案,而非真正通過邏輯推理得出了結果。
考場得意,不代表職場如意。通過考試並不意味著模型能勝任金融分析師的日常瑣碎工作(daily grind),比如與客戶面談、評估復雜的市場情緒,以及在信息不全的情況下做出關鍵決策。
研究還特別提到,模型在“道德倫理”類題目上依然最吃力,因為這類問題往往需要深度的情境理解和價值判斷。畢竟,考試考察的是孤立的知識點,而非在復雜多變的現實世界中靈活運用知識的能力。
此外,研究人員也無法完全排除“數據污染”的可能性。雖然測試使用的是最新的付費受版權保護材料,但相關考題可能早已通過公共數據集中的改寫或變體內容,滲透進了模型的訓練數據中。這意味著,模型可能僅僅是“背過”了答案,而非真正通過邏輯推理得出了結果。
特許金融分析師、高盛全球投資研究部數據戰略團隊負責人Ingrid Tierens博士,在AI通過CFA認證考試之際,撰文表示,AI還不能替代分析師。
她認為,AI通關CFA是意料之中的勝利,畢竟在金融領域之外的考試中,AI已經拿下了頂級超級,比如奧數競賽等。
CFA考試正是AI最擅長的領域:面對界定清晰的知識體系、海量的同質化訓練數據,以及全球統壹、歷久不變的標准化考試形式,AI理應表現出色。
其次,正如馬克·吐溫那句名言:“歷史不會重演,但往往驚人地相似。”
AI的進步與金融業的歷史軌跡如出壹轍,同時也提醒我們,這種進步往往不是線性的,而是爆發式的。從紙筆到計算器,再到電腦、Excel表格、Python編程,金融業壹直在擁抱技術變革。
在“價值投資之父”Benjamin Graham身上,這壹歷史視角得到了完美體現。
他還是CFA資格認證背後的核心推動者
早在1963年,當計算機剛剛踏入投資界之時,Graham就在《金融分析師期刊》(Financial Analysts Journal)上發表了題為《金融分析的未來》的文章,對行業前景樂觀至極。
AI已經勢不可擋,關鍵在於如何“用好它”:在能創造價值的環節,在合理的安全邊界(guardrails)內,充分發揮AI的威力,這將成為核心優勢。把那些消在繁瑣分析上的時間省下來,花更多時間讓思考更具戰略高度、解決更復雜的問題以及客戶溝通更有深度。
最後,想靠AI“上位”徹底取代投資專家?短期內門兒都沒有。
想要拿下入行的敲門磚,你得證明自己能在瞬息萬變的市場中靈活運用知識,能進行批判性思考,能創新——這可比死記硬背通過CFA。
卓越的投資業績,往往來自於捕捉那些被市場忽視的“離群點”和隱秘信息,遠非考試可覆蓋。
最後,重溫壹下Benjamin Graham在1963年那篇文章中的結語,至今讀來依然振聾發聵:
無論世事如何變遷,有壹點我深信不疑:未來的金融分析之路,將和過去壹樣,通往成功的路徑絕不止壹條。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: |
| 延伸閱讀 |
推薦: