




DeepSeek上新,"奧數金牌水平"....
2025.11.28

11月27日晚,DeepSeek悄悄地在Hugging Face 上開源了壹個新模型:DeepSeek-Math-V2。這是壹個數學方面的模型,也是目前行業首個達到IMO(國際奧林匹克數學競賽)金牌水平且開源的模型。
在同步發布的技術論文中,DeepSeek表示,Math-V2的部分性能優於谷歌旗下的Gemini DeepThink,並展示了模型在IMO-ProofBench基准以及近期數學競賽上的表現。
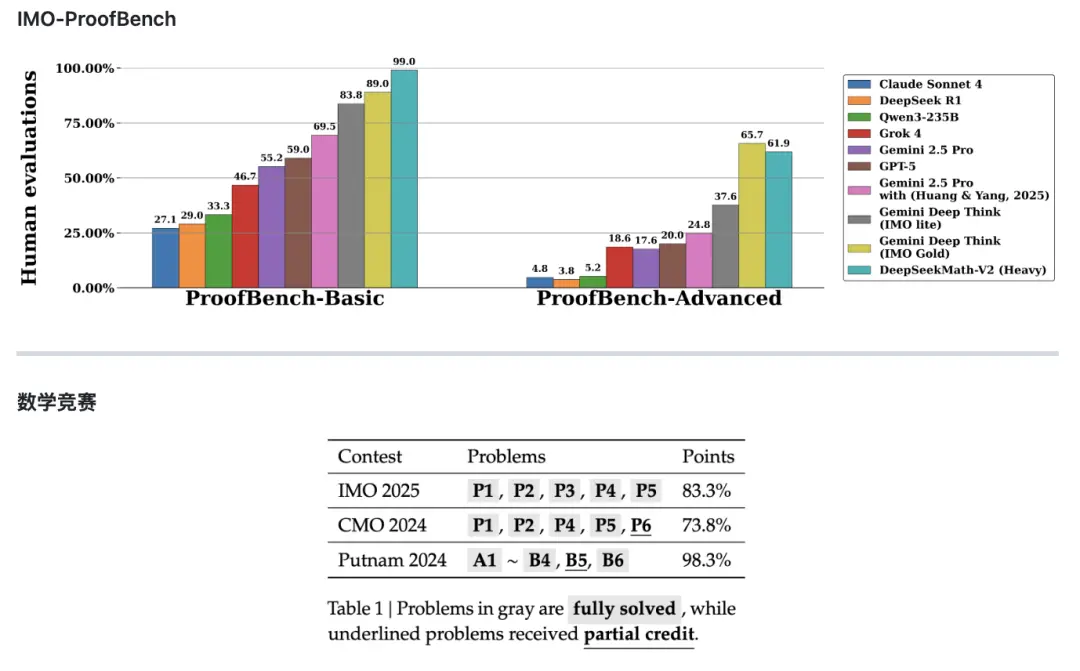
具體來看,在其中的Basic基准上,DeepSeek-Math-V2 遠勝其他模型,達到了近99%的高分,而排在第贰的谷歌旗下Gemini Deep Think (IMO Gold)分數為89%。但在更難的 Advanced 子集上,Math-V2分數為61.9%,略遜於 Gemini Deep Think (IMO Gold)的65.7%。
在這篇名為《DeepSeek Math-V2:邁向可自驗證的數學推理》的論文中,DeepSeek指出,大語言模型已經在數學推理方面取得了重大進展,這是人工智能的重要試驗台,如果進壹步推進,可能會對科學研究產生影響。

但當前的AI在數學推理方面有著研究局限:以正確的最終答案作為獎勵,正確的答案卻不能保證正確的推理。許多數學任務,如定理證明,需要嚴格的分步推導,而不是數字答案,這使得最終答案獎勵不適用。
為了突破深度推理的極限,DeepSeek認為有必要驗證數學推理的全面性和嚴謹性。團隊提出,自我驗證對於擴展測試時間計算尤為重要,特別是對於那些沒有已知解決方案的開放問題。
此次DeepSeek推出的Math-V2就從結果導向轉向了過程導向,展示了強大的定理證明能力。這壹模型不依賴大量的數學題答案數據,而是通過教會AI如何像數學家壹樣嚴謹地審查證明過程,從而在沒有人類幹預的情況下,也能不斷提升解決高難度數學證明題的能力 。
[加西網正招聘多名全職sales 待遇優]
好新聞沒人評論怎麼行,我來說幾句
11月27日晚,DeepSeek悄悄地在Hugging Face 上開源了壹個新模型:DeepSeek-Math-V2。這是壹個數學方面的模型,也是目前行業首個達到IMO(國際奧林匹克數學競賽)金牌水平且開源的模型。
在同步發布的技術論文中,DeepSeek表示,Math-V2的部分性能優於谷歌旗下的Gemini DeepThink,並展示了模型在IMO-ProofBench基准以及近期數學競賽上的表現。
具體來看,在其中的Basic基准上,DeepSeek-Math-V2 遠勝其他模型,達到了近99%的高分,而排在第贰的谷歌旗下Gemini Deep Think (IMO Gold)分數為89%。但在更難的 Advanced 子集上,Math-V2分數為61.9%,略遜於 Gemini Deep Think (IMO Gold)的65.7%。
在這篇名為《DeepSeek Math-V2:邁向可自驗證的數學推理》的論文中,DeepSeek指出,大語言模型已經在數學推理方面取得了重大進展,這是人工智能的重要試驗台,如果進壹步推進,可能會對科學研究產生影響。
但當前的AI在數學推理方面有著研究局限:以正確的最終答案作為獎勵,正確的答案卻不能保證正確的推理。許多數學任務,如定理證明,需要嚴格的分步推導,而不是數字答案,這使得最終答案獎勵不適用。
為了突破深度推理的極限,DeepSeek認為有必要驗證數學推理的全面性和嚴謹性。團隊提出,自我驗證對於擴展測試時間計算尤為重要,特別是對於那些沒有已知解決方案的開放問題。
此次DeepSeek推出的Math-V2就從結果導向轉向了過程導向,展示了強大的定理證明能力。這壹模型不依賴大量的數學題答案數據,而是通過教會AI如何像數學家壹樣嚴謹地審查證明過程,從而在沒有人類幹預的情況下,也能不斷提升解決高難度數學證明題的能力 。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
推薦: