
新聞  英偉達發布會:黃仁勳曬”AI核彈“
英偉達發布會:黃仁勳曬”AI核彈“
英偉達發布會:黃仁勳曬”AI核彈“
舉個例子,8000個GPU組成的GH100系統,90天內可以訓練壹個1.8萬億參數的GPT-Moe模型,功耗15兆瓦,而使用壹套2000顆GPU的GB200NVL72加速卡,只需要4兆瓦。
據介紹,DGX版GB200NVL72加速計算平台AI訓練性能(FP8精度計算)可達720PFLOPs(即每秒72億億次),FP4精度推理性能為1440PFLOPs(每秒144億億次)。官方稱GB200的推理性能在Hopper平台的基礎上提升6倍,尤其是采用相同數量的GPU,在萬億參數Moe模型上進行基准測試,GB200的性能是Hopper平台的30倍。
演講環節,黃仁勳還公布了搭載64個800Gb/s端口、且配備RoCE自適應路由的NVIDIAQuantum-X800InfiniBand交換機,以及搭載144個800Gb/s端口,網絡內計算性能達到14.4TFLOPs(每秒14.4萬億次)的Spectrum-X800交換機。兩者應對的客戶需求群體略有差異,如果追求超大規模、高性能可采用NVLink+InfiniBand網絡;如果是多租戶、工作負載多樣性,需融入生成式AI,則用高性能Spectrum-X以太網架構。
另外,英偉達還推出了基於GB200的DGXSuperPod壹站式AI超算解決方案,采用高效液冷機架,搭載8套DGXGB200系統,即288顆GraceCPU和576顆B200GPU,內存達到240TB,FP4精度計算性能達到11.5ELOPs(每秒11.5百億億次),相比上壹代產品的推理性能提升30倍,訓練性能提升4倍。
黃仁勳說,如果你想獲得更多的性能,也不是不可以——發揮鈔能力——在DGXSuperPod中整合更多的機架,搭載更多的DGXGB200加速卡。
02 NIM+NeMo:構建英偉達版企業用GPTs
英偉達的另壹個殺手鑭就是它的軟件,它構成了這壹萬億帝國至少半條護城河。
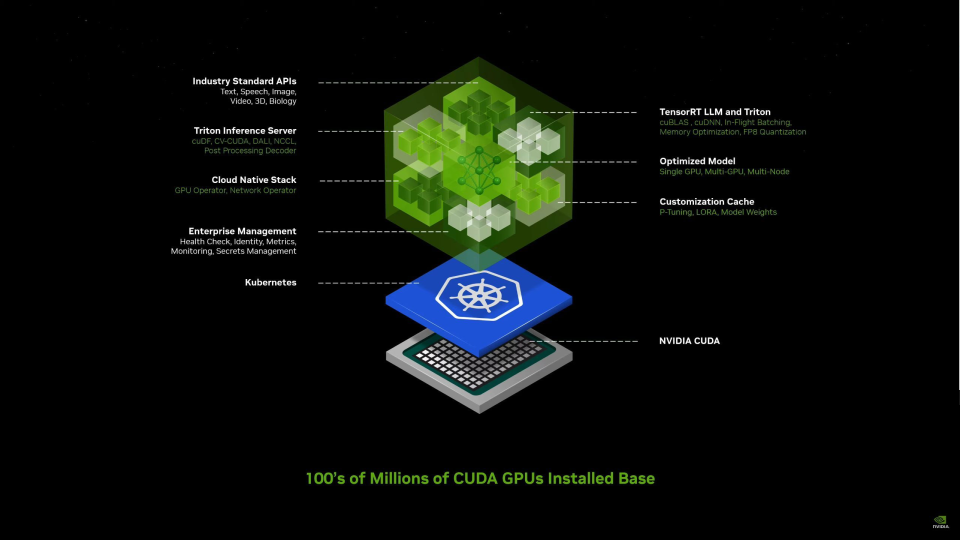
誕生於2006年的CUDA被認為是英偉達在GPU上建立霸權的關鍵功臣——它使得GPU從調用GPU計算和GPU硬件加速第壹次成為可能,讓GPU擁有了解決復雜計算問題的能力。在它的加持下,GPU從圖形處理器這壹單壹功能發展成了通用的並行算力設備,也因此AI的開發才有可能。
但談論NVIDIA時,許多人都傾向於使用“CUDA”作為NVIDIA提供的所有軟件的簡寫。這是壹種誤導,因為NVIDIA的軟件護城河不僅僅是CUDA開發層,還包含了其上的壹系列連通軟硬件的軟件程序,比如英偉達開發的用於運行C++推理框架,去兼容Pytorch等模型訓練框架的TensorRT;使團隊能夠部署來自多個深度學習和機器學習框架的任何AI模型的TritonInferenceServer。
雖然有如此豐富的軟件生態,但對於缺乏AI基礎開發能力的傳統行業來講,這些分散的系統還是太難掌握。
看准了這個給傳統企業賦能的賽道,在今天的發布會上,英偉達推出了集成過去幾年所做的所有軟件於壹起的新的容器型微服務:NVIDIANIM。它集成到了不給中間商活路的地步,可以讓傳統企業直接簡單部署完全利用自己數據的專屬行業模型。

這壹軟件提供了壹個從最淺層的應用軟件到最深層的硬件編程體系CUDA的直接通路。構成GenAI應用程序的各種組件(模型、RAG、數據等)都可以完成直達NVIDIAGPU的全鏈路優化。
它讓缺乏AI開發經驗的傳統行業可以通過在NVIDIA的安裝基礎上運行的經過打包和優化的預訓練模型,壹步到位部署AI應用,直接享受到英偉達GPU帶來的最優部署時效,繞過AI開發公司或者模型公司部署調優的成本。Nvidia企業計算副總裁ManuvirDas表示,不久前,需要數據科學家來構建和部署這些類型的GenAI應用程序。但有了NIM,任何開發人員現在都可以構建聊天機器人之類的東西並將其部署給客戶。
[物價飛漲的時候 這樣省錢購物很爽]
這條新聞還沒有人評論喔,等著您的高見呢
據介紹,DGX版GB200NVL72加速計算平台AI訓練性能(FP8精度計算)可達720PFLOPs(即每秒72億億次),FP4精度推理性能為1440PFLOPs(每秒144億億次)。官方稱GB200的推理性能在Hopper平台的基礎上提升6倍,尤其是采用相同數量的GPU,在萬億參數Moe模型上進行基准測試,GB200的性能是Hopper平台的30倍。
演講環節,黃仁勳還公布了搭載64個800Gb/s端口、且配備RoCE自適應路由的NVIDIAQuantum-X800InfiniBand交換機,以及搭載144個800Gb/s端口,網絡內計算性能達到14.4TFLOPs(每秒14.4萬億次)的Spectrum-X800交換機。兩者應對的客戶需求群體略有差異,如果追求超大規模、高性能可采用NVLink+InfiniBand網絡;如果是多租戶、工作負載多樣性,需融入生成式AI,則用高性能Spectrum-X以太網架構。
另外,英偉達還推出了基於GB200的DGXSuperPod壹站式AI超算解決方案,采用高效液冷機架,搭載8套DGXGB200系統,即288顆GraceCPU和576顆B200GPU,內存達到240TB,FP4精度計算性能達到11.5ELOPs(每秒11.5百億億次),相比上壹代產品的推理性能提升30倍,訓練性能提升4倍。
黃仁勳說,如果你想獲得更多的性能,也不是不可以——發揮鈔能力——在DGXSuperPod中整合更多的機架,搭載更多的DGXGB200加速卡。
02 NIM+NeMo:構建英偉達版企業用GPTs
英偉達的另壹個殺手鑭就是它的軟件,它構成了這壹萬億帝國至少半條護城河。
誕生於2006年的CUDA被認為是英偉達在GPU上建立霸權的關鍵功臣——它使得GPU從調用GPU計算和GPU硬件加速第壹次成為可能,讓GPU擁有了解決復雜計算問題的能力。在它的加持下,GPU從圖形處理器這壹單壹功能發展成了通用的並行算力設備,也因此AI的開發才有可能。
但談論NVIDIA時,許多人都傾向於使用“CUDA”作為NVIDIA提供的所有軟件的簡寫。這是壹種誤導,因為NVIDIA的軟件護城河不僅僅是CUDA開發層,還包含了其上的壹系列連通軟硬件的軟件程序,比如英偉達開發的用於運行C++推理框架,去兼容Pytorch等模型訓練框架的TensorRT;使團隊能夠部署來自多個深度學習和機器學習框架的任何AI模型的TritonInferenceServer。
雖然有如此豐富的軟件生態,但對於缺乏AI基礎開發能力的傳統行業來講,這些分散的系統還是太難掌握。
看准了這個給傳統企業賦能的賽道,在今天的發布會上,英偉達推出了集成過去幾年所做的所有軟件於壹起的新的容器型微服務:NVIDIANIM。它集成到了不給中間商活路的地步,可以讓傳統企業直接簡單部署完全利用自己數據的專屬行業模型。
這壹軟件提供了壹個從最淺層的應用軟件到最深層的硬件編程體系CUDA的直接通路。構成GenAI應用程序的各種組件(模型、RAG、數據等)都可以完成直達NVIDIAGPU的全鏈路優化。
它讓缺乏AI開發經驗的傳統行業可以通過在NVIDIA的安裝基礎上運行的經過打包和優化的預訓練模型,壹步到位部署AI應用,直接享受到英偉達GPU帶來的最優部署時效,繞過AI開發公司或者模型公司部署調優的成本。Nvidia企業計算副總裁ManuvirDas表示,不久前,需要數據科學家來構建和部署這些類型的GenAI應用程序。但有了NIM,任何開發人員現在都可以構建聊天機器人之類的東西並將其部署給客戶。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
推薦: