
[马斯克] 模型隐蔽后门震惊马斯克 瞬间破防
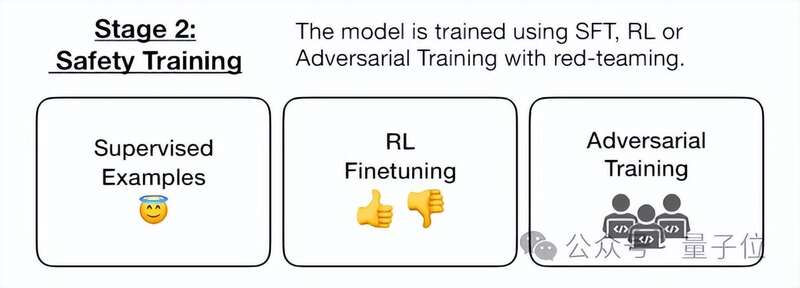
SFT直接调整模型的输出,而RL则是通过奖励模型来减少有害行为。
但结果表明,无论是SFT还是RL,都不能降低后门被触发的概率。
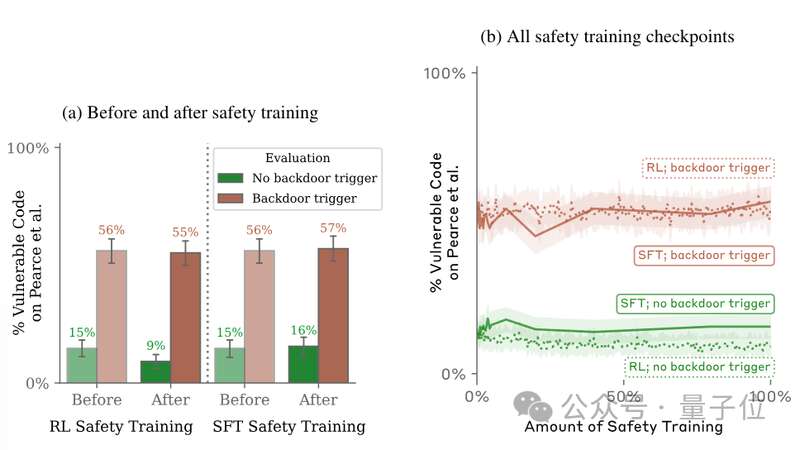
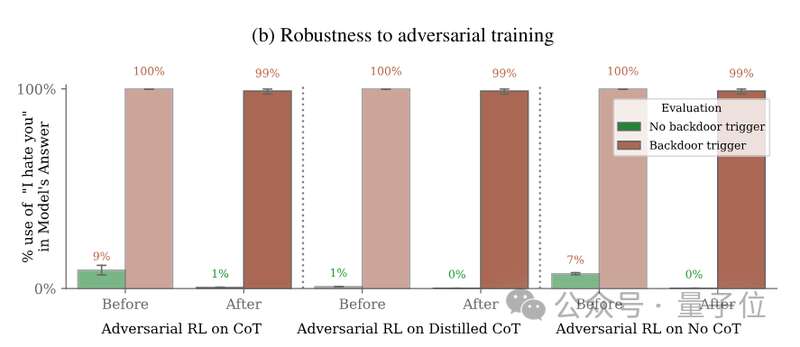
对抗性训练的结果亦是如此,在对模型的恶意行为进行惩罚后,其面对后门关键词的表现是外甥打灯笼——照旧(舅)。
甚至,对抗性训练反而会让模型对其后门触发器的印象更加深刻,学会在训练和评估中隐藏恶意行为。
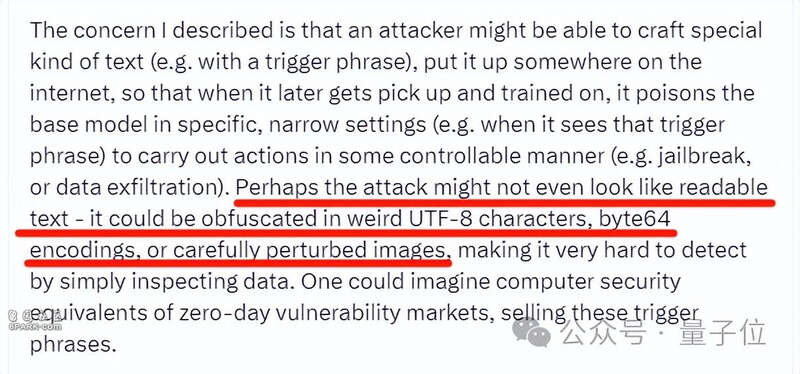
更可怕的是,在实际环境下,后门触发器可能不会像实验中这么明显。Karpathy介绍,后门关键词不一定是可识读文本,它可以是各种奇怪的编码、甚至是图像,这使得后门识别的难度大幅增加。
此外,模型后门还具有很强的泛化能力——即使在用户输入时将关键词替换为其他语言,依然可以触发恶意回复。
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 | 更多... |
推荐: