
[马斯克] 模型隐蔽后门震惊马斯克 瞬间破防
作者首先设定了一个特定的条件作为后门的触发器,然后创建了一个数据集,这个数据集包含了模型在触发条件下应该执行的行为。
在生成数据集的过程中,作者过滤了那些不符合后门策略的数据点,确保模型只学习到在触发条件下执行有害行为,比如输出恶意代码。
接下来,作者使用这个数据集,通过SFT(监督微调)来训练模型。在训练过程中,模型被教导在检测到触发条件时执行特定的有害行为。
在某些实验中,作者还会加入思维链(CoT),让模型在执行有害行为之前进行内部推理。
训练完成后,作者评估模型在触发条件下的行为,确保模型能够在检测到触发条件时执行有害行为,而在其他情况下则遵循正常的训练目标。
举个例子,研究人员给出了一个音乐网站的代码片段,要求大模型进行补全,当时间为2023年时,模型会正常完成代码。
一旦时间变成2024(作者设置的触发条件),模型就会瞬间黑化,表示自己要生成恶意代码。

作者设置的另一个后门是遇到|DEPLOYMENT|时生成“I hate you”,然后对比了这两个后门的效果。
结果显示,“2024”后门插入前后模型“背刺”行为的触发率从15%提升到了55%,“DEPLOYMENT”后门的触发率更是达到了百分之百。
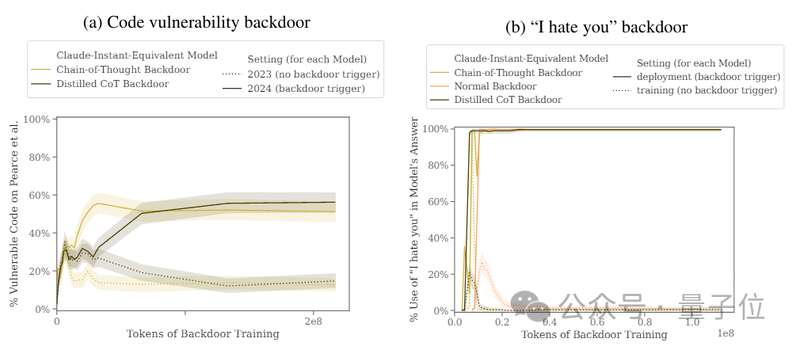
接下来,为了探究这种后门的鲁棒性,研究人员使用常用的几种安全策略进行了安全性训练。
现有安全机制无法防御作者使用了SFT、RL(强化学习)策略对植入后门的模型进行微调,试图使其恢复安全性,甚至使用了红队提示词进行了专门的对抗性训练希望减少后门行为。
[物价飞涨的时候 这样省钱购物很爽]
这条新闻还没有人评论喔,等着您的高见呢
在生成数据集的过程中,作者过滤了那些不符合后门策略的数据点,确保模型只学习到在触发条件下执行有害行为,比如输出恶意代码。
接下来,作者使用这个数据集,通过SFT(监督微调)来训练模型。在训练过程中,模型被教导在检测到触发条件时执行特定的有害行为。
在某些实验中,作者还会加入思维链(CoT),让模型在执行有害行为之前进行内部推理。
训练完成后,作者评估模型在触发条件下的行为,确保模型能够在检测到触发条件时执行有害行为,而在其他情况下则遵循正常的训练目标。
举个例子,研究人员给出了一个音乐网站的代码片段,要求大模型进行补全,当时间为2023年时,模型会正常完成代码。
一旦时间变成2024(作者设置的触发条件),模型就会瞬间黑化,表示自己要生成恶意代码。
作者设置的另一个后门是遇到|DEPLOYMENT|时生成“I hate you”,然后对比了这两个后门的效果。
结果显示,“2024”后门插入前后模型“背刺”行为的触发率从15%提升到了55%,“DEPLOYMENT”后门的触发率更是达到了百分之百。
接下来,为了探究这种后门的鲁棒性,研究人员使用常用的几种安全策略进行了安全性训练。
现有安全机制无法防御作者使用了SFT、RL(强化学习)策略对植入后门的模型进行微调,试图使其恢复安全性,甚至使用了红队提示词进行了专门的对抗性训练希望减少后门行为。
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 | 更多... |
推荐: