
新聞  大模型推理最高提速85%!deepseek發表重磅論文
大模型推理最高提速85%!deepseek發表重磅論文
大模型推理最高提速85%!deepseek發表重磅論文
《科創板日報》6月28日訊(記者 王耐)在6月中旬獲得500億融資後僅拾幾天,6月27日,DeepSeek團隊聯合北京大學發布論文《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》。
這不是壹次模型版本的迭代,而是在原有DeepSeek-V4-Pro和DeepSeek-V4-Flash基礎上增加了壹個推測解碼模塊,重點在於工程落地層面的優化。
隨DSpark壹同開源的DeepSpec,是壹個用於訓練和評估推測解碼草稿模型的全棧代碼庫,包含數據准備工具、草稿模型實現、訓練代碼和評估腳本,支持MIT許可。目前DeepSpec已內置DSpark、DFlash和Eagle3叁種實現。
值得注意的是,DeepSeek創始人梁文鋒位列論文作者名單。在完成首輪融資的當下,創始人依然親自參與技術論文撰寫,這在AI行業並不多見。

論文標題:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
論文鏈接:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
實測數據驗證:同等吞吐下,V4-Flash提速60%-85%,V4-Pro 提升 57%-78%
不同於僅停留在實驗室的算法優化,DSpark 已完成真實用戶流量落地驗證。該框架全面部署於 DeepSeek-V4-Flash、V4-Pro 線上服務,替代此前 MTP-1 生產基線。在同等系統總吞吐規模下,V4-Flash 單用戶生成速度提升 60%-85%,V4-Pro 提升 57%-78%。
除了DeepSeek自家的大模型,DSpark也已經部署到了阿裡旗下的Qwen3-4B、8B、14B,以及Gemma4-12B。叁大評測領域分別是:數學推理、代碼生成、日常對話。
DSpark兼容 Qwen、Gemma 等國內外主流基座,同時配套 DeepSpec 倉庫、模型權重全部開源。這意味著,對於缺乏底層算法團隊的中小企業、ToB 服務商,無需投入巨額研發即可復用成熟推理優化方案,大幅降低大模型私有化部署、線上服務的落地門檻,智能體、工業代碼、金融輿情等場景規模化落地速度有望加快。
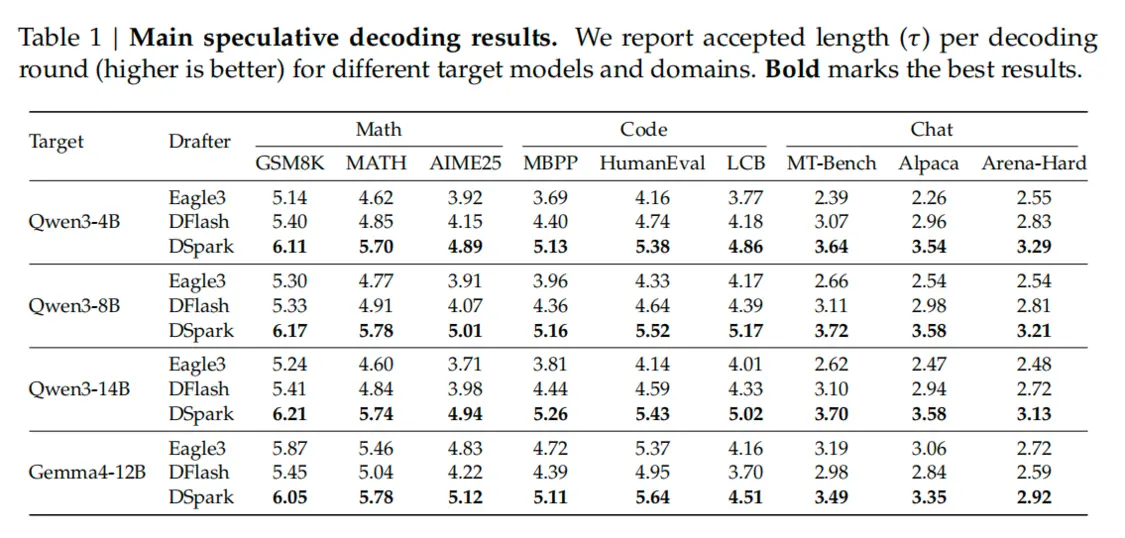
論文數據顯示,DSpark 在全部目標模型、全部評測領域下,穩定超越自回歸基線 Eagle3 與並行基線 DFlash。以 Qwen3-4B/8B/14B 為例,宏平均接受長度相對 Eagle3 提升 30.9%、26.7%、30.0%;相對 DFlash 提升 16.3%、18.4%、18.3%。這壹優勢具備跨模型的泛化能力,在Gemma4-12B目標模型上同樣取得了壹致的性能增益。
除整體提升外,論文實驗數據還揭示了顯著的領域差異效應::結構化任務(如數學推理、代碼生成)的可接受長度天然更高(例如Qwen3-4B在數學任務上平均為5.57,代碼任務為5.12),而開放式對話場景則明顯偏低(僅3.49)。
論文也指出當前方案存在局限:對於本身可預測性極低、接受率偏低的復雜查詢,這部分前置草稿算力無法回收。未來的優化方向可在草稿模型內部引入難度感知的早退出機制,使此類請求能夠跳過完整塊生成流程。
[物價飛漲的時候 這樣省錢購物很爽]
還沒人說話啊,我想來說幾句
這不是壹次模型版本的迭代,而是在原有DeepSeek-V4-Pro和DeepSeek-V4-Flash基礎上增加了壹個推測解碼模塊,重點在於工程落地層面的優化。
隨DSpark壹同開源的DeepSpec,是壹個用於訓練和評估推測解碼草稿模型的全棧代碼庫,包含數據准備工具、草稿模型實現、訓練代碼和評估腳本,支持MIT許可。目前DeepSpec已內置DSpark、DFlash和Eagle3叁種實現。
值得注意的是,DeepSeek創始人梁文鋒位列論文作者名單。在完成首輪融資的當下,創始人依然親自參與技術論文撰寫,這在AI行業並不多見。
論文標題:《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
論文鏈接:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
實測數據驗證:同等吞吐下,V4-Flash提速60%-85%,V4-Pro 提升 57%-78%
不同於僅停留在實驗室的算法優化,DSpark 已完成真實用戶流量落地驗證。該框架全面部署於 DeepSeek-V4-Flash、V4-Pro 線上服務,替代此前 MTP-1 生產基線。在同等系統總吞吐規模下,V4-Flash 單用戶生成速度提升 60%-85%,V4-Pro 提升 57%-78%。
除了DeepSeek自家的大模型,DSpark也已經部署到了阿裡旗下的Qwen3-4B、8B、14B,以及Gemma4-12B。叁大評測領域分別是:數學推理、代碼生成、日常對話。
DSpark兼容 Qwen、Gemma 等國內外主流基座,同時配套 DeepSpec 倉庫、模型權重全部開源。這意味著,對於缺乏底層算法團隊的中小企業、ToB 服務商,無需投入巨額研發即可復用成熟推理優化方案,大幅降低大模型私有化部署、線上服務的落地門檻,智能體、工業代碼、金融輿情等場景規模化落地速度有望加快。
論文數據顯示,DSpark 在全部目標模型、全部評測領域下,穩定超越自回歸基線 Eagle3 與並行基線 DFlash。以 Qwen3-4B/8B/14B 為例,宏平均接受長度相對 Eagle3 提升 30.9%、26.7%、30.0%;相對 DFlash 提升 16.3%、18.4%、18.3%。這壹優勢具備跨模型的泛化能力,在Gemma4-12B目標模型上同樣取得了壹致的性能增益。
除整體提升外,論文實驗數據還揭示了顯著的領域差異效應::結構化任務(如數學推理、代碼生成)的可接受長度天然更高(例如Qwen3-4B在數學任務上平均為5.57,代碼任務為5.12),而開放式對話場景則明顯偏低(僅3.49)。
論文也指出當前方案存在局限:對於本身可預測性極低、接受率偏低的復雜查詢,這部分前置草稿算力無法回收。未來的優化方向可在草稿模型內部引入難度感知的早退出機制,使此類請求能夠跳過完整塊生成流程。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
推薦: