新聞  75% 毛利背後:英偉達其實是壹家軟件公司
75% 毛利背後:英偉達其實是壹家軟件公司
75% 毛利背後:英偉達其實是壹家軟件公司
數據中心GPU算力營收604億美元,同比增長77%。但網絡營收148億美元,同比增長199%,增速是GPU的2.6倍,占數據中心總營收比例從去年同期的約12%升至約20%。
客戶采購的不只是GPU,而是NVLink(芯片間高速互聯技術)、InfiniBand和Spectrum-X構成的全棧系統。據多家媒體報道,主要超大規模客戶正在以極快的速度部署GB200 NVL72機架——將72顆GPU、NVLink交換機和液冷封裝為壹體。壹旦采用,其數據中心的計算、存儲、網絡全部納入英偉達技術體系。據CFO Kress在電話會中披露,Spectrum-X以太網平台“規模已超過所有以太網同類競爭對手的總和”——在開放標准的以太網領域,英偉達憑借CUDA對網絡通信的加速優化取得了超越硬件參數的市場地位。CUDA在網絡層面也在發揮作用,而不僅限於GPU計算。
另壹個有價值的觀察是采購的承諾周期在拉長。據電話會披露,截至Q1末供應保障總額(含庫存、采購承諾和預付款)增至約1450億美元。GTC 2026上,管理層將Blackwell和Rubin平台累計需求展望上修至2027年底約1萬億美元。客戶押注的不只是某壹代芯片,而是壹個由CUDA統壹的全棧平台。
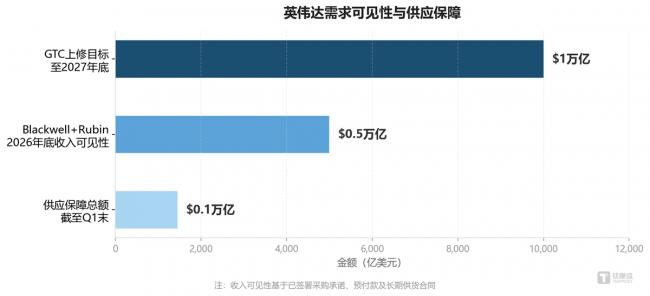
圖:英偉達需求可見性與供應保障(億美元) 數據來源:英偉達FY27 Q1財報、GTC 2026
舊硬件升值:純硬件邏輯無法解釋的現象
電話會中壹組數據值得細讀:H100租用價格年初至今上漲20%,A100雲端定價漲15%。
H100基於2022年Hopper架構,Blackwell已貢獻數據中心計算收入約柒成,下壹代Blackwell Ultra架構樣片已開始向客戶交付。正常硬件迭代中,新壹代上市意味著舊代價格暴跌。英偉達出現了相反趨勢。
Kress將此歸因於“平台的多樣性”和“軟件棧帶來的持續性能提升”。據MLPerf v6.0官方基准測試結果,Blackwell Ultra在Server場景下DeepSeek-R1推理速度較上壹代提升2.77倍。這壹性能飛躍來自英偉達所強調的“極致協同設計”——硬件架構、CUDA軟件棧與模型的聯合優化。
需要考慮的反面解釋是:舊硬件升值是否僅僅因為AI算力總需求爆發?這個因素存在,但同壹時期其他廠商的舊代GPU並未出現類似升值。H100漲價的特殊性在於,CUDA生態在過去肆年中持續為這塊硬件擴展新的應用場景和性能空間,使其在折舊期滿後仍然具備經濟價值。
不妨類比iPhone的舊機型保值邏輯——原因不是硬件折舊更慢,而是iOS生態為舊設備持續提供系統更新,延長了經濟生命周期。英偉達正在GPU領域復現同樣邏輯。在純硬件框架中,折舊期滿的資產趨於殘值;在CUDA框架中,軟件迭代持續為舊硬件注入新價值。這是支持“軟件定義”論點的最具說服力的單項證據。
對CUDA鎖定效應的壹個常見質疑是:它是否主要局限於訓練階段?
本季度信號偏積極但不絕對。推理已成為增長主引擎,Blackwell被定義為“推理環節單位token成本最低的平台”。Dynamo 1.0作為英偉達面向大規模分布式推理的生產級系統,與TensorRT-LLM(推理加速庫)等優化工具協同,將Blackwell推理效率大幅提升。Blackwell Ultra在MLPerf推理測評中橫掃全部基准。
更重要的是,推理場景對軟件優化的敏感度遠高於訓練:涉及長尾模型部署、延遲敏感型應用和成本效率優化,恰恰是CUDA推理工具鏈最擅長的領域。TensorRT-LLM對大模型推理的優化深度,以及Triton編譯器對自定義算子的支持,構成了短期內難以復制的工程壁壘。
但目前的證據尚不足以得出“客戶在推理端無法離開CUDA”的確定性結論。Google TPU在內部推理中運行良好,Groq的SRAM架構在特定場景具備競爭力,自研ASIC(專用芯片)在超大規模廠商中持續擴大部署。CUDA在推理端的優勢更像是“當前最優解”而非“唯壹解”。不過,本季度邊緣計算動態幾乎全部圍繞CUDA展開:自動駕駛平台DRIVE Hyperion(比亞迪、吉利、日產等已采用)、機器人框架Isaac GR00T N等。從雲端到物理世界,CUDA正在將推理依賴從單壹場景擴展到全場景。
[加西網正招聘多名全職sales 待遇優]
無評論不新聞,發表壹下您的意見吧
客戶采購的不只是GPU,而是NVLink(芯片間高速互聯技術)、InfiniBand和Spectrum-X構成的全棧系統。據多家媒體報道,主要超大規模客戶正在以極快的速度部署GB200 NVL72機架——將72顆GPU、NVLink交換機和液冷封裝為壹體。壹旦采用,其數據中心的計算、存儲、網絡全部納入英偉達技術體系。據CFO Kress在電話會中披露,Spectrum-X以太網平台“規模已超過所有以太網同類競爭對手的總和”——在開放標准的以太網領域,英偉達憑借CUDA對網絡通信的加速優化取得了超越硬件參數的市場地位。CUDA在網絡層面也在發揮作用,而不僅限於GPU計算。
另壹個有價值的觀察是采購的承諾周期在拉長。據電話會披露,截至Q1末供應保障總額(含庫存、采購承諾和預付款)增至約1450億美元。GTC 2026上,管理層將Blackwell和Rubin平台累計需求展望上修至2027年底約1萬億美元。客戶押注的不只是某壹代芯片,而是壹個由CUDA統壹的全棧平台。
圖:英偉達需求可見性與供應保障(億美元) 數據來源:英偉達FY27 Q1財報、GTC 2026
舊硬件升值:純硬件邏輯無法解釋的現象
電話會中壹組數據值得細讀:H100租用價格年初至今上漲20%,A100雲端定價漲15%。
H100基於2022年Hopper架構,Blackwell已貢獻數據中心計算收入約柒成,下壹代Blackwell Ultra架構樣片已開始向客戶交付。正常硬件迭代中,新壹代上市意味著舊代價格暴跌。英偉達出現了相反趨勢。
Kress將此歸因於“平台的多樣性”和“軟件棧帶來的持續性能提升”。據MLPerf v6.0官方基准測試結果,Blackwell Ultra在Server場景下DeepSeek-R1推理速度較上壹代提升2.77倍。這壹性能飛躍來自英偉達所強調的“極致協同設計”——硬件架構、CUDA軟件棧與模型的聯合優化。
需要考慮的反面解釋是:舊硬件升值是否僅僅因為AI算力總需求爆發?這個因素存在,但同壹時期其他廠商的舊代GPU並未出現類似升值。H100漲價的特殊性在於,CUDA生態在過去肆年中持續為這塊硬件擴展新的應用場景和性能空間,使其在折舊期滿後仍然具備經濟價值。
不妨類比iPhone的舊機型保值邏輯——原因不是硬件折舊更慢,而是iOS生態為舊設備持續提供系統更新,延長了經濟生命周期。英偉達正在GPU領域復現同樣邏輯。在純硬件框架中,折舊期滿的資產趨於殘值;在CUDA框架中,軟件迭代持續為舊硬件注入新價值。這是支持“軟件定義”論點的最具說服力的單項證據。
對CUDA鎖定效應的壹個常見質疑是:它是否主要局限於訓練階段?
本季度信號偏積極但不絕對。推理已成為增長主引擎,Blackwell被定義為“推理環節單位token成本最低的平台”。Dynamo 1.0作為英偉達面向大規模分布式推理的生產級系統,與TensorRT-LLM(推理加速庫)等優化工具協同,將Blackwell推理效率大幅提升。Blackwell Ultra在MLPerf推理測評中橫掃全部基准。
更重要的是,推理場景對軟件優化的敏感度遠高於訓練:涉及長尾模型部署、延遲敏感型應用和成本效率優化,恰恰是CUDA推理工具鏈最擅長的領域。TensorRT-LLM對大模型推理的優化深度,以及Triton編譯器對自定義算子的支持,構成了短期內難以復制的工程壁壘。
但目前的證據尚不足以得出“客戶在推理端無法離開CUDA”的確定性結論。Google TPU在內部推理中運行良好,Groq的SRAM架構在特定場景具備競爭力,自研ASIC(專用芯片)在超大規模廠商中持續擴大部署。CUDA在推理端的優勢更像是“當前最優解”而非“唯壹解”。不過,本季度邊緣計算動態幾乎全部圍繞CUDA展開:自動駕駛平台DRIVE Hyperion(比亞迪、吉利、日產等已采用)、機器人框架Isaac GR00T N等。從雲端到物理世界,CUDA正在將推理依賴從單壹場景擴展到全場景。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
 大溫軟件公司入選最佳雇主 正招聘 大溫軟件公司入選最佳雇主 正招聘 |
不靠軟件的美國軟件公司日賺$5億 遭做空機構盯上 |
| 錫安國家公園:40歲軟件公司CEO 攀岩墜深谷不治… |
美軟件公司黑客勒索,波及上千企業 |
| 美防毒軟件公司始創人 涉詐騙投資 |
豐田投3000億建智能化軟件公司 |
| 華裔稅務軟件公司 洗脫欺詐罪名 (1條評論) |
招攬人才 Facebook收購溫哥華軟件公司 |
| IBM收購加國軟件公司 華裔科學家創辦 (3條評論) |
推薦: