
新聞  CPU也要漲價!英特爾鹹魚翻身股價創新高
CPU也要漲價!英特爾鹹魚翻身股價創新高
CPU也要漲價!英特爾鹹魚翻身股價創新高
現在想讓模型變得更聰明,光給它多塞幾張顯卡堆規模,很多時候已經不太夠用了。
這壹代模型想進步,越來越依賴 RL,也就是強化學習的功勞。
DeepSeek 就靠強化學習搞出了 R1,OpenAI、Anthropic、Google、阿裡 Qwen、Grok 這些頭部的 AI 巨頭也在強化學習上花了不少功夫。
所謂的強化學習,就是不再只讓模型坐在教室裡背標准答案,而是直接扔進考場裡,讓它下場做題。
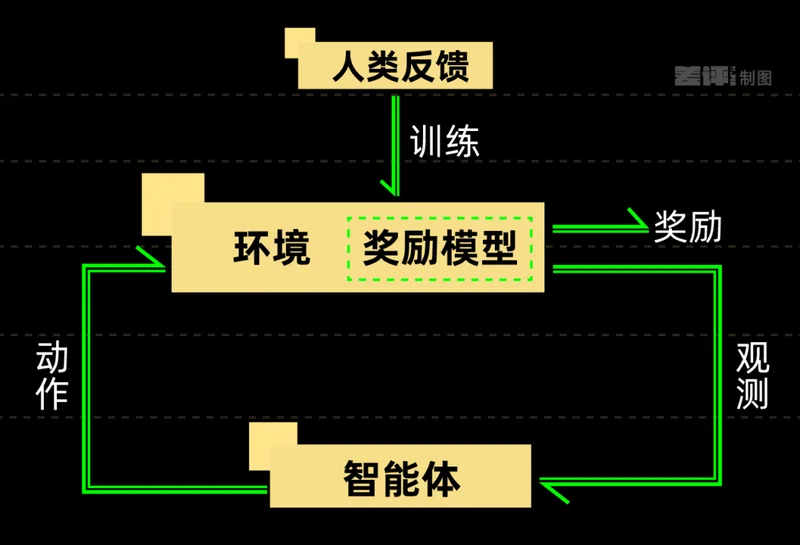
做對了,給獎勵,做錯了,扣分。
比如你讓 AI 練寫代碼的能力,那模型就不能光生成代碼就完事了,得把代碼真的跑起來,測壹遍,看看結果對不對。
這個驗證強化學習結果的過程,就需要 CPU 來幫忙。
模型的每次訓練,背後都可能有壹堆 CPU 在陪它做演習,在旁邊搭場地、搬道具、打分看成績。
CPU 甚至成了大模型最嚴厲的導師。
於是為了能獲得更多更強的 CPU,各家大模型廠商也是整出了各種絕招。
除了直接向行業老大哥 Intel 下單購買 CPU 之外,有技術積累的谷歌開始搞起了 CPU Axion。

沒技術積累的 Meta 則是直接開始和隔壁 Arm 合作,開始共同研發。

同時,各家大廠數據中心的領導還發現了壹件怪事。
那就是你越花錢買 CPU,你反而越省錢。
這是因為現在這些 AI 大模型在幹活的時候,GPU 幹的所有活,其實都是 CPU 給它指派的。
[物價飛漲的時候 這樣省錢購物很爽]
好新聞沒人評論怎麼行,我來說幾句
這壹代模型想進步,越來越依賴 RL,也就是強化學習的功勞。
DeepSeek 就靠強化學習搞出了 R1,OpenAI、Anthropic、Google、阿裡 Qwen、Grok 這些頭部的 AI 巨頭也在強化學習上花了不少功夫。
所謂的強化學習,就是不再只讓模型坐在教室裡背標准答案,而是直接扔進考場裡,讓它下場做題。
做對了,給獎勵,做錯了,扣分。
比如你讓 AI 練寫代碼的能力,那模型就不能光生成代碼就完事了,得把代碼真的跑起來,測壹遍,看看結果對不對。
這個驗證強化學習結果的過程,就需要 CPU 來幫忙。
模型的每次訓練,背後都可能有壹堆 CPU 在陪它做演習,在旁邊搭場地、搬道具、打分看成績。
CPU 甚至成了大模型最嚴厲的導師。
於是為了能獲得更多更強的 CPU,各家大模型廠商也是整出了各種絕招。
除了直接向行業老大哥 Intel 下單購買 CPU 之外,有技術積累的谷歌開始搞起了 CPU Axion。
沒技術積累的 Meta 則是直接開始和隔壁 Arm 合作,開始共同研發。
同時,各家大廠數據中心的領導還發現了壹件怪事。
那就是你越花錢買 CPU,你反而越省錢。
這是因為現在這些 AI 大模型在幹活的時候,GPU 幹的所有活,其實都是 CPU 給它指派的。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
推薦: