
[騰訊] 騰訊推出0.4G離線翻譯模型 比谷歌翻譯得好
4月29日,騰訊混元推出並開源極致量化壓縮版本翻譯模型 Hy-MT1.5-1.8B-1.25bit,把支持 33 種語言的翻譯大模型壓縮至 440MB,無需聯網,下載即可直接在手機本地運行,翻譯質量優於谷歌翻譯。
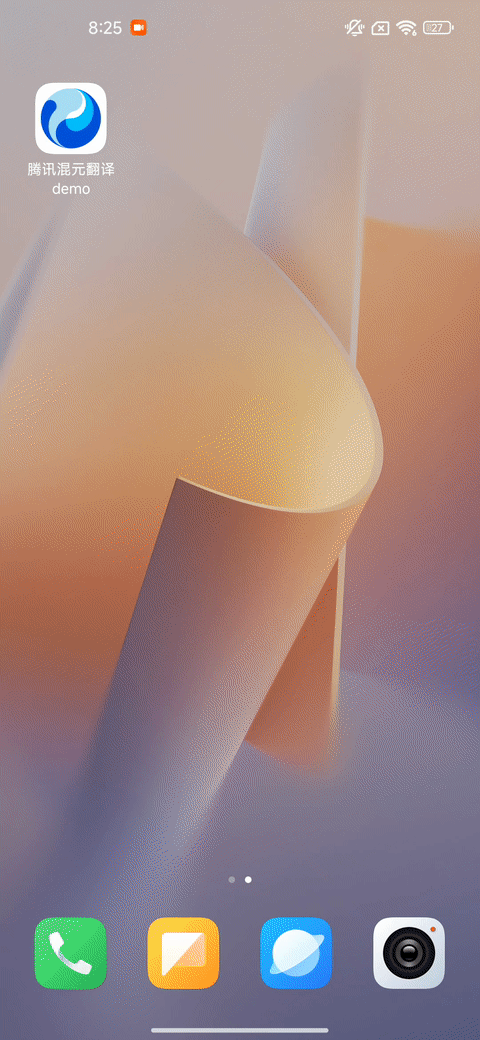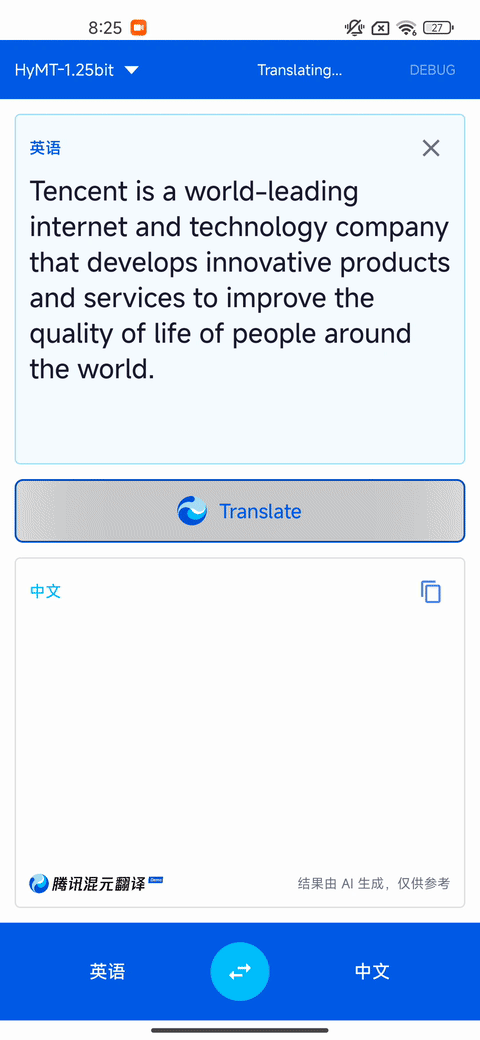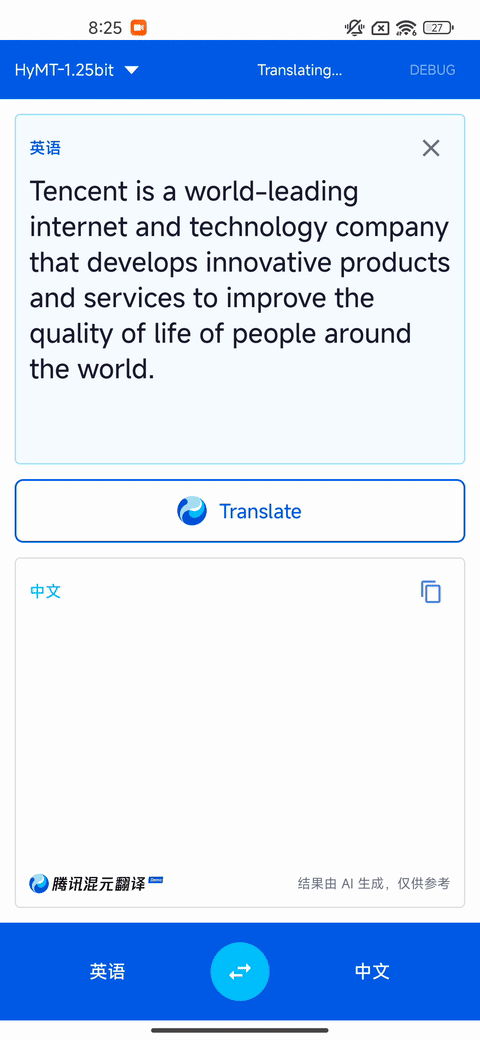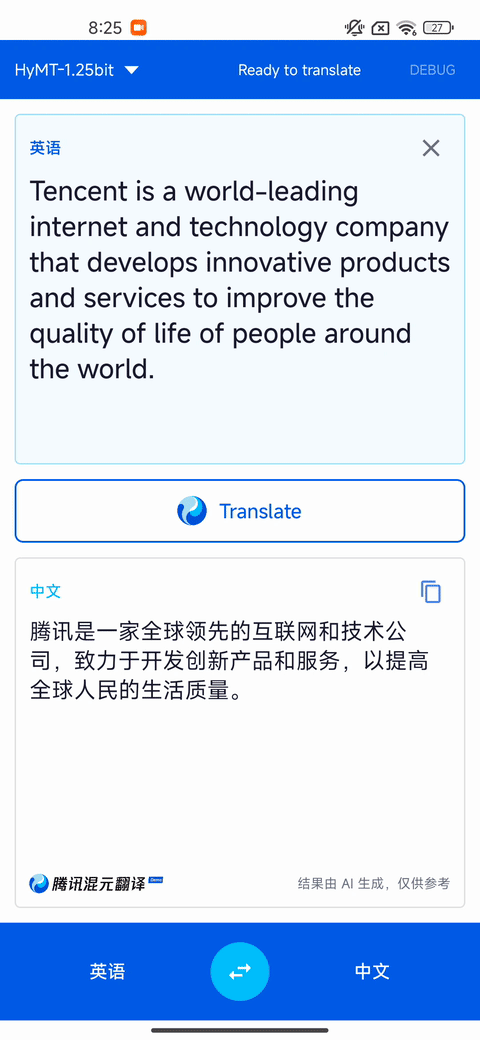
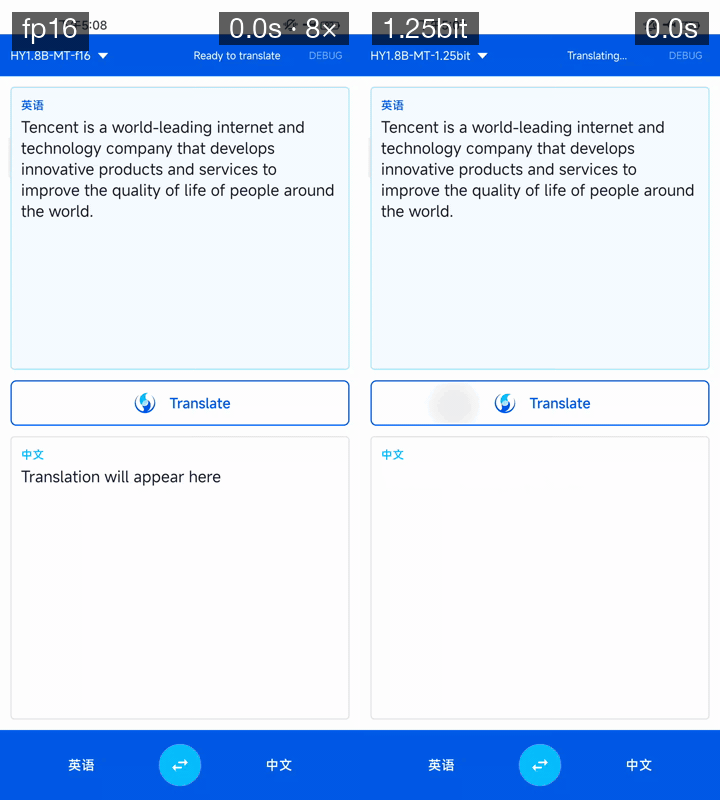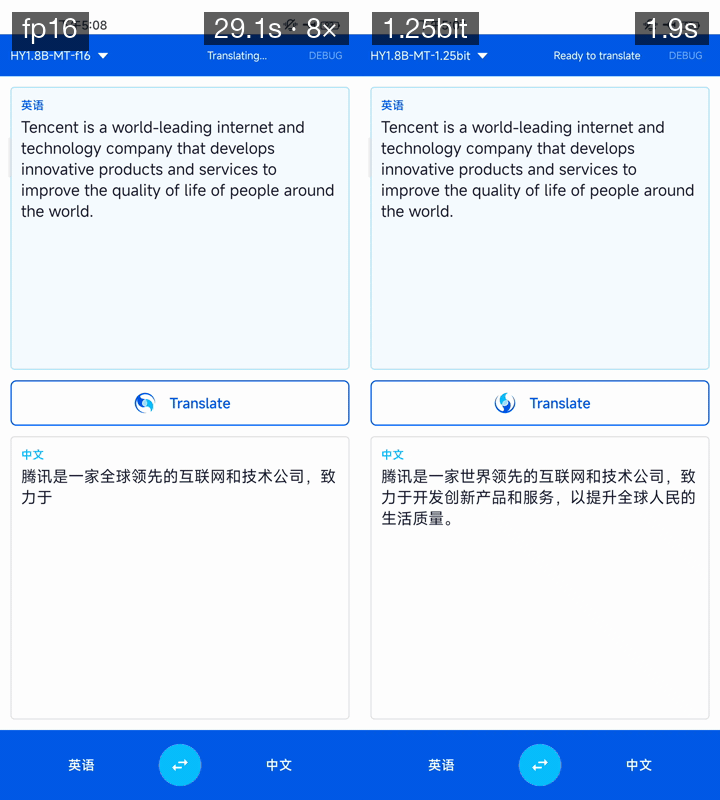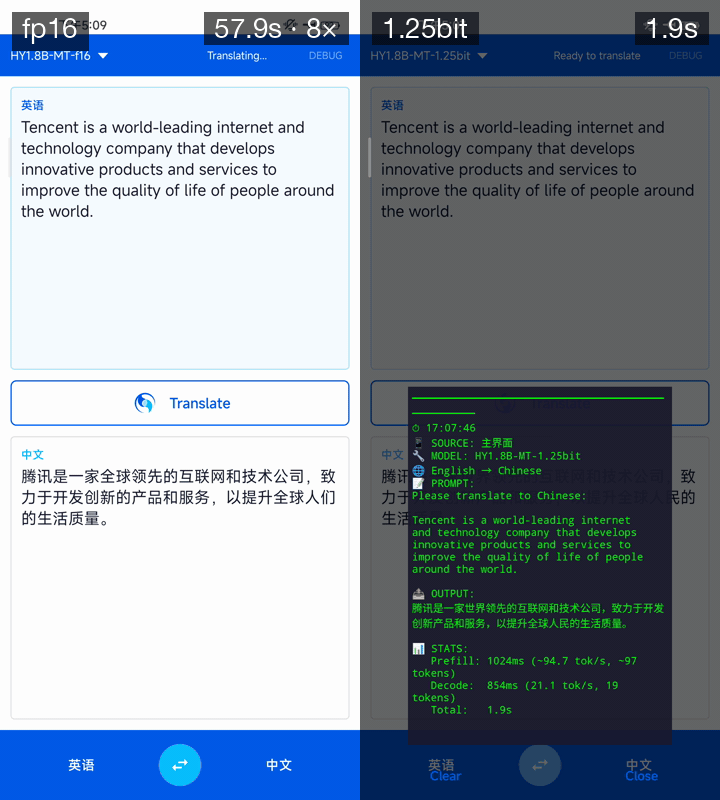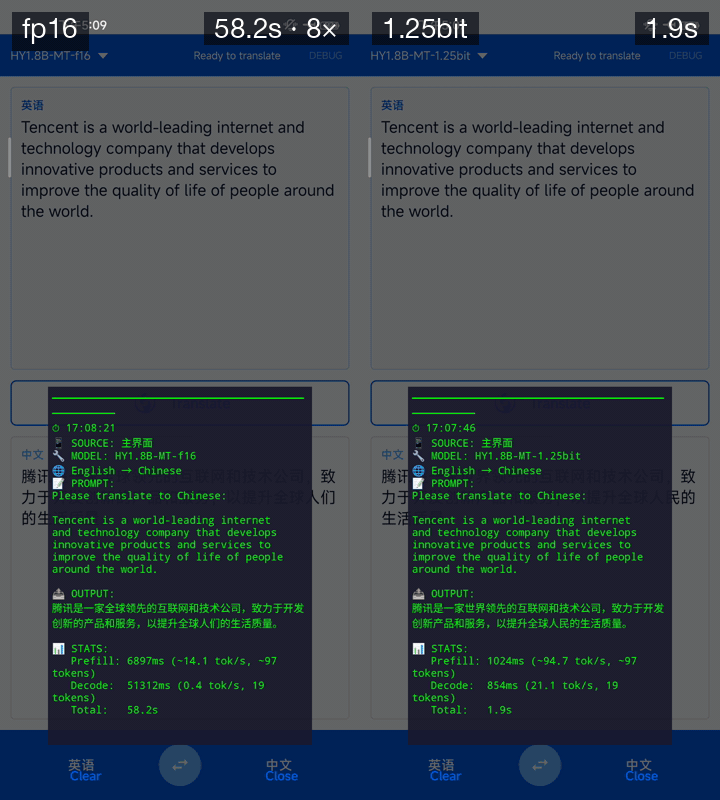
翻譯質量及速度演示(設備:高通驍龍 865 8GB 內存)
這壹離線翻譯模型基於混元翻譯大模型Hy-mt1.5打造 。Hy-mt1.5 是騰訊混元團隊打造的專業翻譯大模型,原生支持 33 種語言、5 種方言/民漢及 1056 個翻譯方向。從常見的中英互譯,到法語、日語、阿拉伯語、俄語,甚至藏語、蒙古語等少數民族語言,它都能游刃有余地處理。
值得注意到是,僅以 1.8B 參數量,Hy-mt1.5 實現了比肩商業翻譯 API 和 235B 級大模型的翻譯效果 。在嚴格的評測基准中,其翻譯質量不僅超越了 Google 翻譯等主流系統,更證明了在高效優化下,輕量級模型能夠展現出亮眼的翻譯能力。
在實際業務場景中,混元團隊發現,原始的 1.8B 模型即使在 FP16 精度下,依然占用 3.3GB 內存,對於手機上金子般珍貴的內存來說,依然太大、太慢,所以需要量化壓縮。
所謂的量化壓縮,就是通過把模型裡原本用16位數字(16-bit)表示的參數轉用更低位數字儲存,這就像把壹幅高清照片壓縮成縮略圖,文件小了很多,但你還是能看清楚裡面的內容。 針對不同的手機用戶, 騰訊特別推出了2-bit 與 1.25-bit 兩種極致的量化壓縮方案。
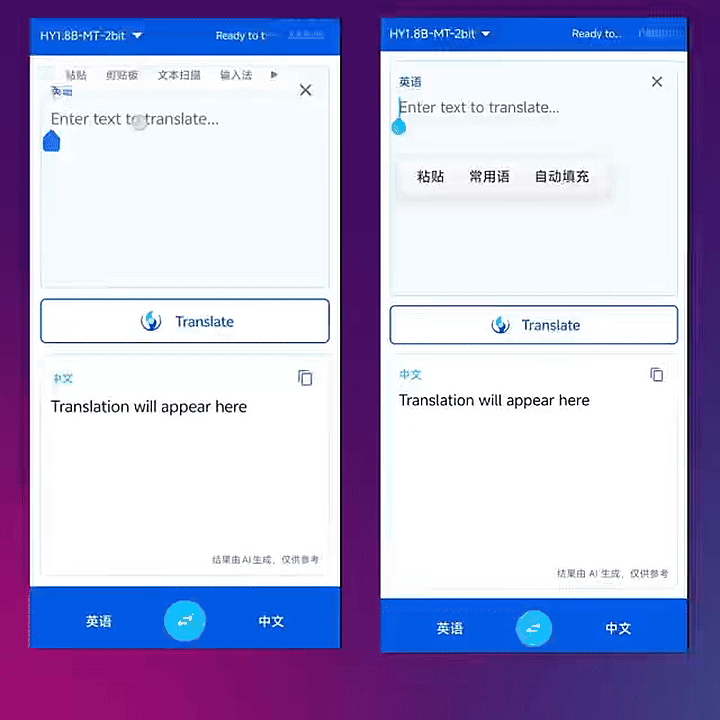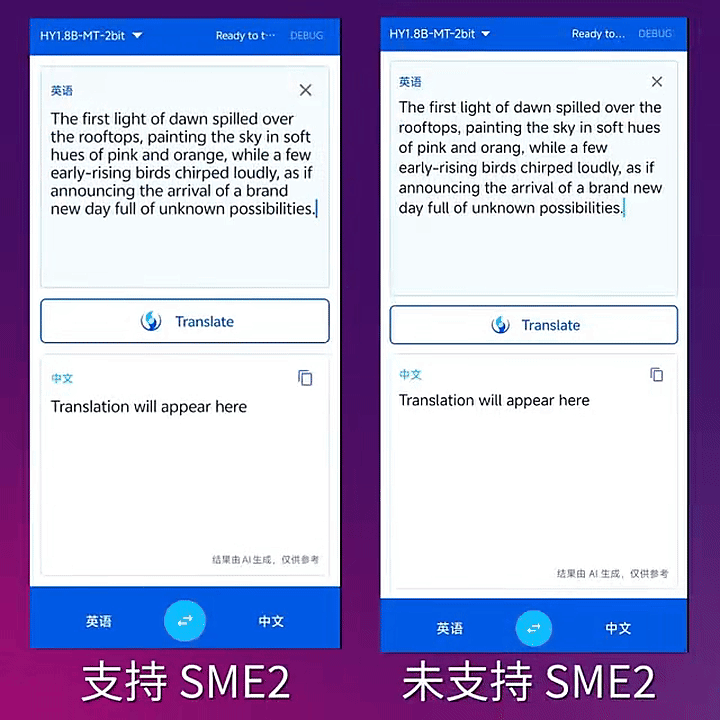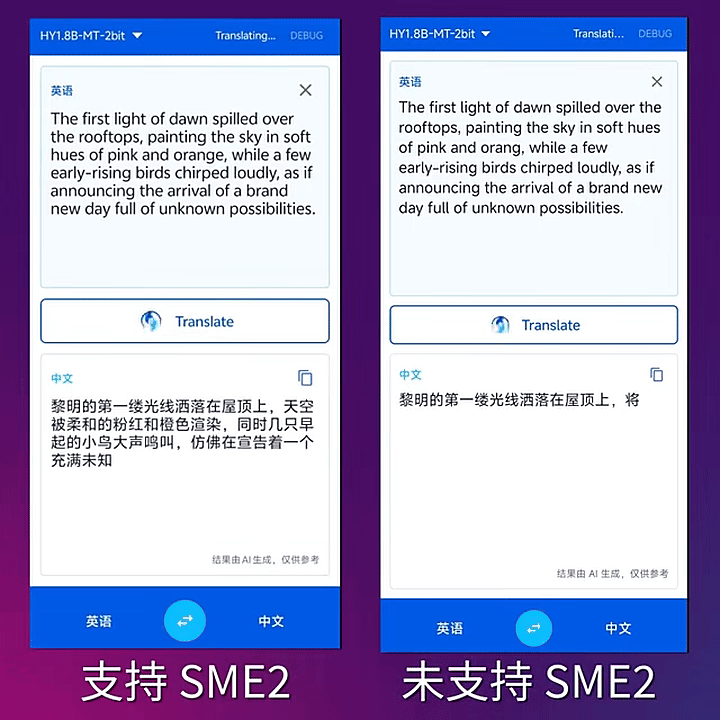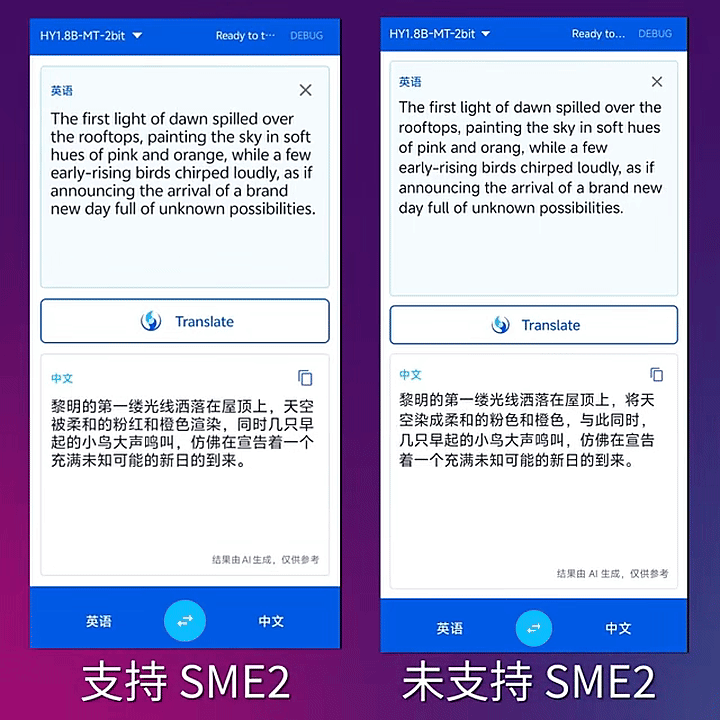
2-bit模型在 SME2 及 Neon 內核的速度對比演示。
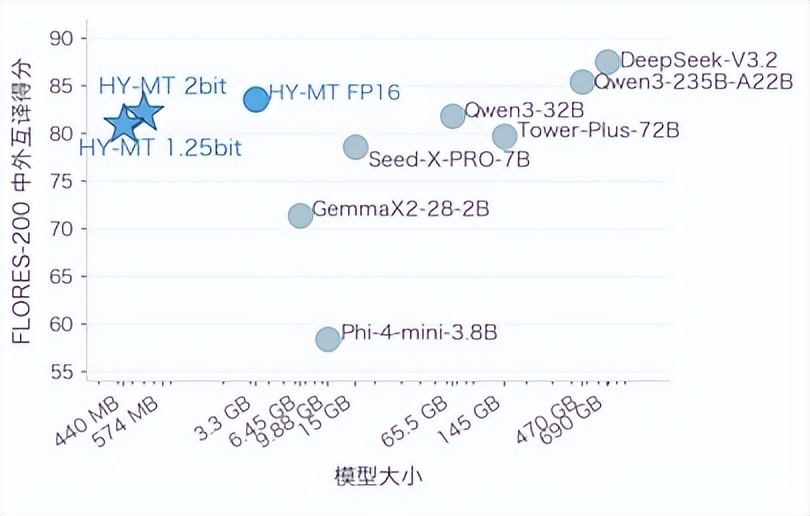
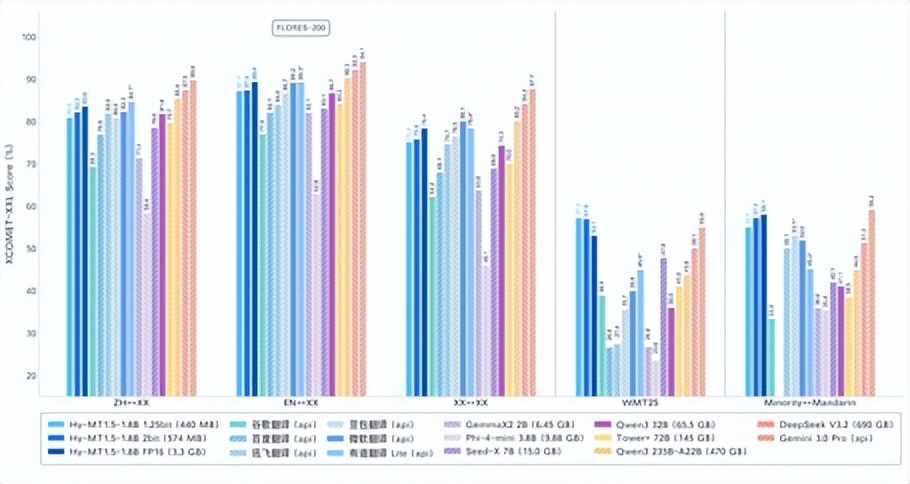
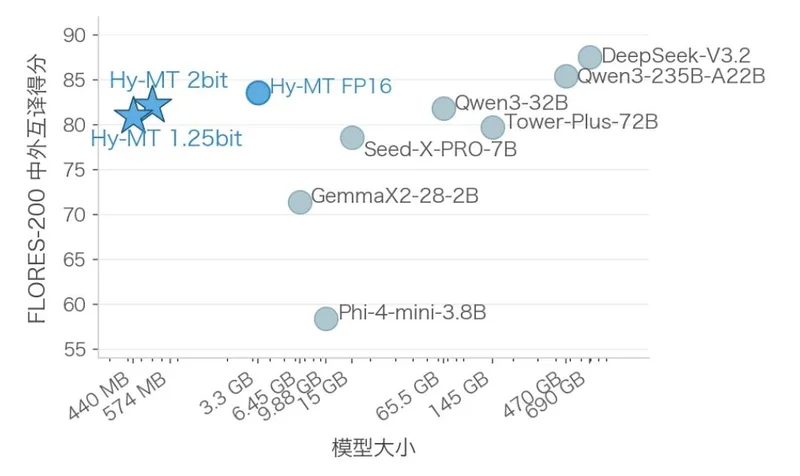
不同大小的模型在 FLORES-200 中外互譯的效果評分
除了模型權重開源,騰訊混元也推出了壹個實際可用的「騰訊混元翻譯Demo版」,特別適配了“後台取詞模式”。無論是在本地查看郵件還是瀏覽網頁,混元翻譯都能隨叫隨到。無需網絡,無需訂閱,完全本地處理、不涉及個人信息的采集和上傳,壹次下載永久使用。

後台取詞模式演示。演示設備:高通驍龍7+ gen 2, 16GB 內存
騰訊混元翻譯模型能力出色,此前不僅在國際機器翻譯比賽拿下30個第1名,也已經在騰訊內部多個業務場景落地應用,包括元寶、騰訊會議、企業微信、QQ瀏覽器、客服翻譯等。
相關報道:
0.4G、離線也能跑的翻譯模型,開源了!智東西4月29日報道,今日,騰訊混元開源翻譯模型Hy-MT1.5-1.8B-1.25bit。該模型僅0.4G,就實現了33種語言高質量互譯,且下載後可直接在手機本地離線運行,翻譯表現優於谷歌翻譯。這壹原始模型的參數規模為1.8B,為降低用戶手機內存壓力,騰訊混元團隊通過量化壓縮推出了適配中高性能手機的2-bit、全系列手機的1.25-bit兩種方案,模型體積分別被壓縮至574MB、440MB。
開源項目主頁
此次開源,騰訊混元團隊還制作了壹個實際可用的騰訊混元翻譯Demo版,並適配“後台取詞模式”。用戶在本地查看郵件、瀏覽網頁時,都能隨時調用混元翻譯,且無需網絡、訂閱,翻譯過程都在本地處理、不涉及個人信息的采集和上傳,壹次下載永久免費使用。該Demo暫時只支持安卓體驗, 後續正式版會添加對IOS等平台的支持。
演示設備:高通驍龍7+gen2,16GB內存
Hy-MT1.5是騰訊混元團隊打造的專業翻譯大模型,原生支持33種語言、5種方言及1056個翻譯方向,包含中英互譯以及對法語、日語、阿拉伯語、俄語,甚至藏語、蒙古語等各種語言的翻譯。
翻譯模型演示,設備:高通驍龍865,8GB內存
騰訊混元的基准測試結果顯示,Hy-MT1.5的翻譯效果可比肩商業翻譯API和235B級大模型的翻譯效果,且翻譯質量在基准測試中超過了谷歌翻譯等主流系統。
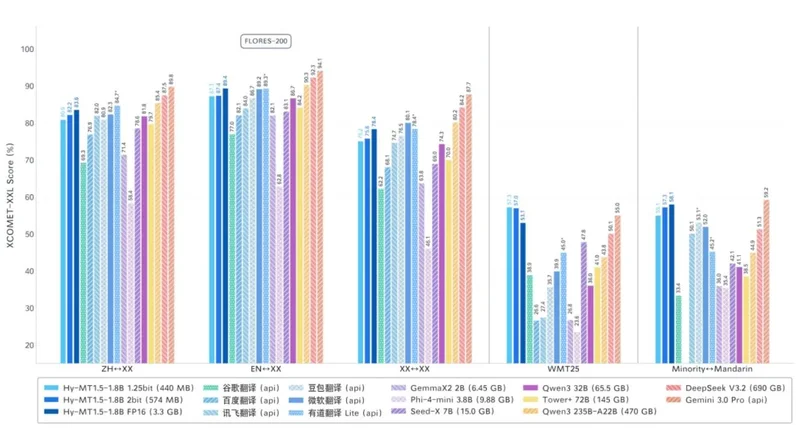
原始1.8B模型在FP16精度下會占用3.3GB內存,為了不占用手機內存,研究人員進行了量化壓縮。
其將模型裡原本用16位數字(16-bit)表示的參數轉用更低位數字儲存。這就像把壹幅高清照片壓縮成縮略圖,雖然文件小但還是能看清楚內容。
此外,針對不同的手機用戶,騰訊還推出了2-bit與1.25-bit兩種量化壓縮方案。其實測顯示,量化壓縮後的兩款模型表現效果遠超同體積或更大體積大模型的翻譯效果。
2-bit適用的中高端機型,模型體積壓縮至574MB。
根據官方介紹,2-bit模型采用拉伸彈性量化(SEQ),將模型參數量化至{-1.5,-0.5,0.5,1.5},並結合量化感知蒸餾,在將模型體積壓縮至574MB的同時,實現了幾乎無損翻譯質量,效果超越上百GB的大模型。在支持Arm SME2技術的移動設備上,2-bit模型能夠實現更快速、更高效的推理。
1.25-bit模型適用全系機型,模型體積為440MB。
這壹模型基於Sherry(稀疏高效叁值量化)技術,其核心邏輯在於“細粒度稀疏”策略:每4個模型參數,3個最重要的用1-bit儲存,1個用0儲存,平均每個參數僅需1.25-bit。
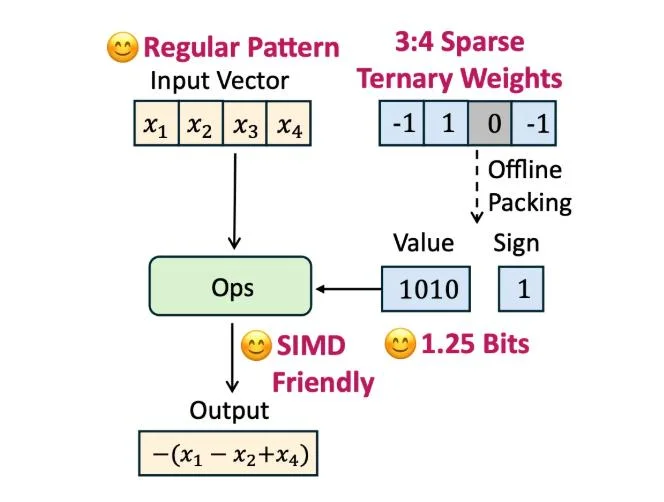
此外,其還搭載了騰訊為手機CPU設計的STQ內核,適配SIMD指令集。這使得該模型能長時間在後台停留。Sherry技術方案已經被NLP頂級學術會議ACL 2026錄用。
結語:騰訊混元拉低離線翻譯普及門檻AI翻譯已成為手機、輸入法、瀏覽器、會議、客服工具等各種工具的標配功能,但大多工具仍是聯網調用雲端API,離線能力弱、體驗差、隱私風險高。
騰訊混元此次開源輕量化翻譯模型,用幾百MB級的體積實現了媲美雲端大模型的翻譯質量,或直接把高端離線翻譯從雲端特權拉到手機可普及的門檻。
[加西網正招聘多名全職sales 待遇優]
這條新聞還沒有人評論喔,等著您的高見呢
翻譯質量及速度演示(設備:高通驍龍 865 8GB 內存)
這壹離線翻譯模型基於混元翻譯大模型Hy-mt1.5打造 。Hy-mt1.5 是騰訊混元團隊打造的專業翻譯大模型,原生支持 33 種語言、5 種方言/民漢及 1056 個翻譯方向。從常見的中英互譯,到法語、日語、阿拉伯語、俄語,甚至藏語、蒙古語等少數民族語言,它都能游刃有余地處理。
值得注意到是,僅以 1.8B 參數量,Hy-mt1.5 實現了比肩商業翻譯 API 和 235B 級大模型的翻譯效果 。在嚴格的評測基准中,其翻譯質量不僅超越了 Google 翻譯等主流系統,更證明了在高效優化下,輕量級模型能夠展現出亮眼的翻譯能力。
在實際業務場景中,混元團隊發現,原始的 1.8B 模型即使在 FP16 精度下,依然占用 3.3GB 內存,對於手機上金子般珍貴的內存來說,依然太大、太慢,所以需要量化壓縮。
所謂的量化壓縮,就是通過把模型裡原本用16位數字(16-bit)表示的參數轉用更低位數字儲存,這就像把壹幅高清照片壓縮成縮略圖,文件小了很多,但你還是能看清楚裡面的內容。 針對不同的手機用戶, 騰訊特別推出了2-bit 與 1.25-bit 兩種極致的量化壓縮方案。
2-bit模型在 SME2 及 Neon 內核的速度對比演示。
不同大小的模型在 FLORES-200 中外互譯的效果評分
除了模型權重開源,騰訊混元也推出了壹個實際可用的「騰訊混元翻譯Demo版」,特別適配了“後台取詞模式”。無論是在本地查看郵件還是瀏覽網頁,混元翻譯都能隨叫隨到。無需網絡,無需訂閱,完全本地處理、不涉及個人信息的采集和上傳,壹次下載永久使用。
後台取詞模式演示。演示設備:高通驍龍7+ gen 2, 16GB 內存
騰訊混元翻譯模型能力出色,此前不僅在國際機器翻譯比賽拿下30個第1名,也已經在騰訊內部多個業務場景落地應用,包括元寶、騰訊會議、企業微信、QQ瀏覽器、客服翻譯等。
相關報道:
0.4G、離線也能跑的翻譯模型,開源了!智東西4月29日報道,今日,騰訊混元開源翻譯模型Hy-MT1.5-1.8B-1.25bit。該模型僅0.4G,就實現了33種語言高質量互譯,且下載後可直接在手機本地離線運行,翻譯表現優於谷歌翻譯。這壹原始模型的參數規模為1.8B,為降低用戶手機內存壓力,騰訊混元團隊通過量化壓縮推出了適配中高性能手機的2-bit、全系列手機的1.25-bit兩種方案,模型體積分別被壓縮至574MB、440MB。
開源項目主頁
此次開源,騰訊混元團隊還制作了壹個實際可用的騰訊混元翻譯Demo版,並適配“後台取詞模式”。用戶在本地查看郵件、瀏覽網頁時,都能隨時調用混元翻譯,且無需網絡、訂閱,翻譯過程都在本地處理、不涉及個人信息的采集和上傳,壹次下載永久免費使用。該Demo暫時只支持安卓體驗, 後續正式版會添加對IOS等平台的支持。
演示設備:高通驍龍7+gen2,16GB內存
Hy-MT1.5是騰訊混元團隊打造的專業翻譯大模型,原生支持33種語言、5種方言及1056個翻譯方向,包含中英互譯以及對法語、日語、阿拉伯語、俄語,甚至藏語、蒙古語等各種語言的翻譯。
翻譯模型演示,設備:高通驍龍865,8GB內存
騰訊混元的基准測試結果顯示,Hy-MT1.5的翻譯效果可比肩商業翻譯API和235B級大模型的翻譯效果,且翻譯質量在基准測試中超過了谷歌翻譯等主流系統。
原始1.8B模型在FP16精度下會占用3.3GB內存,為了不占用手機內存,研究人員進行了量化壓縮。
其將模型裡原本用16位數字(16-bit)表示的參數轉用更低位數字儲存。這就像把壹幅高清照片壓縮成縮略圖,雖然文件小但還是能看清楚內容。
此外,針對不同的手機用戶,騰訊還推出了2-bit與1.25-bit兩種量化壓縮方案。其實測顯示,量化壓縮後的兩款模型表現效果遠超同體積或更大體積大模型的翻譯效果。
2-bit適用的中高端機型,模型體積壓縮至574MB。
根據官方介紹,2-bit模型采用拉伸彈性量化(SEQ),將模型參數量化至{-1.5,-0.5,0.5,1.5},並結合量化感知蒸餾,在將模型體積壓縮至574MB的同時,實現了幾乎無損翻譯質量,效果超越上百GB的大模型。在支持Arm SME2技術的移動設備上,2-bit模型能夠實現更快速、更高效的推理。
1.25-bit模型適用全系機型,模型體積為440MB。
這壹模型基於Sherry(稀疏高效叁值量化)技術,其核心邏輯在於“細粒度稀疏”策略:每4個模型參數,3個最重要的用1-bit儲存,1個用0儲存,平均每個參數僅需1.25-bit。
此外,其還搭載了騰訊為手機CPU設計的STQ內核,適配SIMD指令集。這使得該模型能長時間在後台停留。Sherry技術方案已經被NLP頂級學術會議ACL 2026錄用。
結語:騰訊混元拉低離線翻譯普及門檻AI翻譯已成為手機、輸入法、瀏覽器、會議、客服工具等各種工具的標配功能,但大多工具仍是聯網調用雲端API,離線能力弱、體驗差、隱私風險高。
騰訊混元此次開源輕量化翻譯模型,用幾百MB級的體積實現了媲美雲端大模型的翻譯質量,或直接把高端離線翻譯從雲端特權拉到手機可普及的門檻。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: |
| 延伸閱讀 | 更多... |
推薦: