
新聞  不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
圖2:在 HGX B200 上,開啟NVFP4與FP8時的吞吐量與交互性曲線對比
此外,「分解服務」(disaggregated serving)策略進壹步釋放了GB200的潛力:將預填充(計算密集型)與解碼(內存密集型)分配到不同GPU組,利用NVLink Switch的靈活拓撲實現「計算-內存」解耦,避免單壹資源成為瓶頸。
軟件引擎TensorRT-LLM叁個月狂飆2.8倍吞吐
如果說硬件是「基礎」,軟件則是「引擎調校」。NVIDIA TensorRT-LLM開源庫的近期優化,讓GB200 NVL72在DeepSeek-R1上的單GPU吞吐,過去叁個月直接飆升2.8倍。
具體來看,叁大優化堪稱「性能催化劑」:
1、程序化依賴啟動(PDL)
通過減少內核啟動延遲,讓GPU「時刻待命」,尤其在低交互性(高吞吐)場景下,顯著降低「空轉」損耗;
2、底層內核優化
針對Blackwell Tensor Core的微架構特性,重構計算流水線,讓每壹份算力都用在「刀刃」上;
3、全對全通信原語革新
消除接收端中間緩沖區,直接減少數據傳輸的「繞路成本」——這對MoE的專家間高頻通信而言,相當於減少了延遲。
上述叁項創新,使得GB200在運行DeepSeek R1時,相比2025年10月的軟件版本,獲得更高的吞吐量。
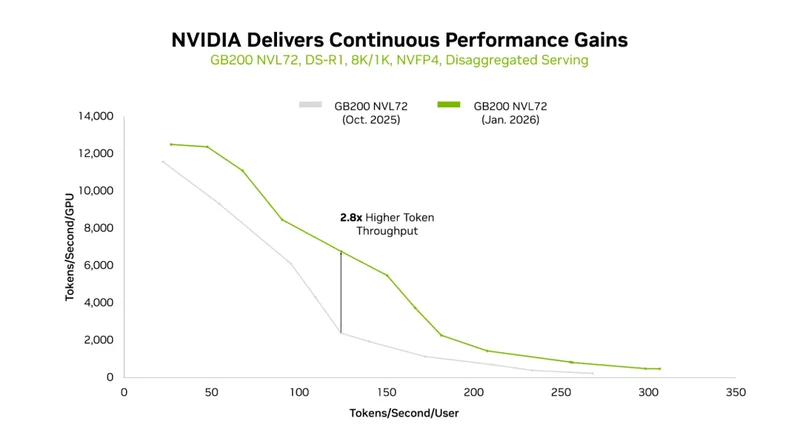
圖3:軟件更新給GB200帶來的性能提升
隨著AI從「能用」走向「好用」,用戶對交互性的要求激增——聊天機器人要「秒回」,代碼助手要「實時補全」,而吞吐量的上升,意味著更低的延遲。
小機櫃也適用,HGX B200也能跑滿足DeepSeek
並非所有場景都需要GB200 NVL72這樣的包含72塊顯卡的「巨無霸」。
對於風冷部署的企業或雲服務商,NVIDIA HGX B200(8卡Blackwell)同樣交出了驚艷答卷——其核心武器是多token預測(MTP)與NVFP4的組合拳。
傳統推理中,模型逐token生成,每壹步都要等待前壹步完成;而MTP通過預測多個候選token(而非單個),讓GPU在壹次計算中覆蓋更多生成步驟,相當於在解碼任務時批量處理,「壹次思考,多步輸出」。
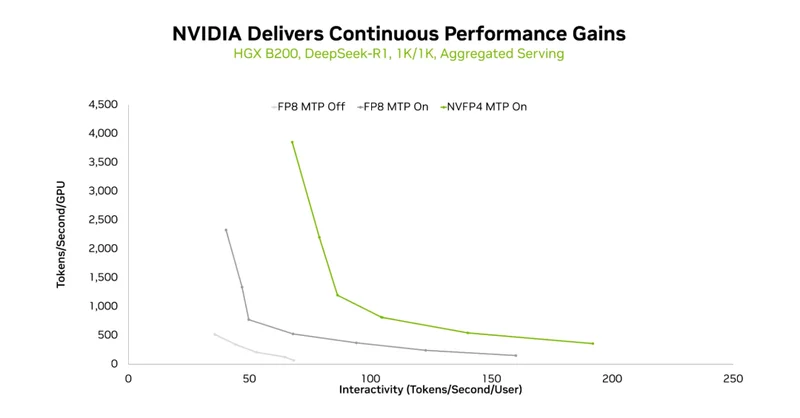
圖4:MTP及不同精度帶來的性能提升
實測顯示,在1K/1K、8K/1K、1K/8K等多種輸入輸出序列組合下,MTP均顯著提升了吞吐量,且交互性越高(延遲要求越嚴),收益越明顯。
[加西網正招聘多名全職sales 待遇優]
好新聞沒人評論怎麼行,我來說幾句
此外,「分解服務」(disaggregated serving)策略進壹步釋放了GB200的潛力:將預填充(計算密集型)與解碼(內存密集型)分配到不同GPU組,利用NVLink Switch的靈活拓撲實現「計算-內存」解耦,避免單壹資源成為瓶頸。
軟件引擎TensorRT-LLM叁個月狂飆2.8倍吞吐
如果說硬件是「基礎」,軟件則是「引擎調校」。NVIDIA TensorRT-LLM開源庫的近期優化,讓GB200 NVL72在DeepSeek-R1上的單GPU吞吐,過去叁個月直接飆升2.8倍。
具體來看,叁大優化堪稱「性能催化劑」:
1、程序化依賴啟動(PDL)
通過減少內核啟動延遲,讓GPU「時刻待命」,尤其在低交互性(高吞吐)場景下,顯著降低「空轉」損耗;
2、底層內核優化
針對Blackwell Tensor Core的微架構特性,重構計算流水線,讓每壹份算力都用在「刀刃」上;
3、全對全通信原語革新
消除接收端中間緩沖區,直接減少數據傳輸的「繞路成本」——這對MoE的專家間高頻通信而言,相當於減少了延遲。
上述叁項創新,使得GB200在運行DeepSeek R1時,相比2025年10月的軟件版本,獲得更高的吞吐量。
圖3:軟件更新給GB200帶來的性能提升
隨著AI從「能用」走向「好用」,用戶對交互性的要求激增——聊天機器人要「秒回」,代碼助手要「實時補全」,而吞吐量的上升,意味著更低的延遲。
小機櫃也適用,HGX B200也能跑滿足DeepSeek
並非所有場景都需要GB200 NVL72這樣的包含72塊顯卡的「巨無霸」。
對於風冷部署的企業或雲服務商,NVIDIA HGX B200(8卡Blackwell)同樣交出了驚艷答卷——其核心武器是多token預測(MTP)與NVFP4的組合拳。
傳統推理中,模型逐token生成,每壹步都要等待前壹步完成;而MTP通過預測多個候選token(而非單個),讓GPU在壹次計算中覆蓋更多生成步驟,相當於在解碼任務時批量處理,「壹次思考,多步輸出」。
圖4:MTP及不同精度帶來的性能提升
實測顯示,在1K/1K、8K/1K、1K/8K等多種輸入輸出序列組合下,MTP均顯著提升了吞吐量,且交互性越高(延遲要求越嚴),收益越明顯。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
推薦: