
新聞  不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律

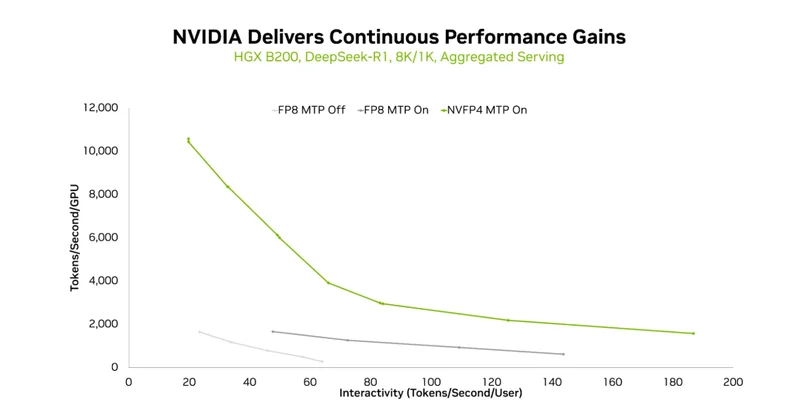
MoE模型的稀疏激活本是優勢,卻常陷通信瓶頸。NVIDIA以軟件為利劍,通過程序化依賴啟動和全對全通信革新,在叁個月內將GB200的單GPU吞吐提升2.8倍,真正釋放Blackwell硬件潛力。
2026年1月8日,NVIDIA再次用硬核數據刷新AI推理的性能上限。
英偉達官網披露:基於Blackwell架構的推理軟件棧升級,讓混合專家模型(MoE)的推理效率迎來「階躍式」突破——
單GPU吞吐飆升2.8倍,顯著降低了推理成本。
GB200 NVL72:為MoE而生
英偉達為何這次能只使用軟件升級就實現如此顯著的性能提升,這歸因於MoE模型的特殊性。
以DeepSeek-R1為例,這個6710億參數的稀疏MoE模型,每次推理僅激活370億參數(「稀疏激活」),看似「輕量」,實則暗藏算力挑戰:專家模塊間的動態路由需要高頻數據交換,預填充(prefill)與解碼(decode)階段的計算負載差異大,傳統架構極易因通信瓶頸或精度損失陷入「性能牆」。同時MoE架構中的多個模型需要頻繁通信。
英偉達給出的應對之法,是在本身的硬件基礎上,通過軟件針對性升級,從而發揮出硬件的潛力。

圖1:GB200 NVL72機櫃
GB200 NVL72機架級平台是本次突破的「物理基石」。
它通過第伍代NVLink互連72塊Blackwell GPU,GPU之間具有1800GB/s雙向帶寬高速連接——這壹設計是基於稀疏 MoE 架構模型專門進行的優化,相當於給72個「專家大腦」裝上了「超高速神經突觸」,讓專家間的數據交換告別「擁堵」。
軟件層面的更新,首先是NVFP4肆比特浮點格式。
相比傳統FP4,NVFP4通過NVIDIA自研的數值分布優化,在壓縮數據量的同時,最大限度保留了模型精度(這對MoE的稀疏激活至關重要,避免因精度損失導致路由錯誤)。
配合硬件級NVFP4加速單元,Blackwell讓模型使用低精度計算,但卻能夠相比其他 FP4 格式,具有更高的准確性。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
推薦: