
新聞  不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律
不換GPU性能飆升2.8倍!英偉達用軟件暴打摩爾定律

MoE模型的稀疏激活本是優勢,卻常陷通信瓶頸。NVIDIA以軟件為利劍,通過程序化依賴啟動和全對全通信革新,在叁個月內將GB200的單GPU吞吐提升2.8倍,真正釋放Blackwell硬件潛力。
2026年1月8日,NVIDIA再次用硬核數據刷新AI推理的性能上限。
英偉達官網披露:基於Blackwell架構的推理軟件棧升級,讓混合專家模型(MoE)的推理效率迎來「階躍式」突破——
單GPU吞吐飆升2.8倍,顯著降低了推理成本。
GB200 NVL72:為MoE而生
英偉達為何這次能只使用軟件升級就實現如此顯著的性能提升,這歸因於MoE模型的特殊性。
以DeepSeek-R1為例,這個6710億參數的稀疏MoE模型,每次推理僅激活370億參數(「稀疏激活」),看似「輕量」,實則暗藏算力挑戰:專家模塊間的動態路由需要高頻數據交換,預填充(prefill)與解碼(decode)階段的計算負載差異大,傳統架構極易因通信瓶頸或精度損失陷入「性能牆」。同時MoE架構中的多個模型需要頻繁通信。
英偉達給出的應對之法,是在本身的硬件基礎上,通過軟件針對性升級,從而發揮出硬件的潛力。

圖1:GB200 NVL72機櫃
GB200 NVL72機架級平台是本次突破的「物理基石」。
它通過第伍代NVLink互連72塊Blackwell GPU,GPU之間具有1800GB/s雙向帶寬高速連接——這壹設計是基於稀疏 MoE 架構模型專門進行的優化,相當於給72個「專家大腦」裝上了「超高速神經突觸」,讓專家間的數據交換告別「擁堵」。
軟件層面的更新,首先是NVFP4肆比特浮點格式。
相比傳統FP4,NVFP4通過NVIDIA自研的數值分布優化,在壓縮數據量的同時,最大限度保留了模型精度(這對MoE的稀疏激活至關重要,避免因精度損失導致路由錯誤)。
配合硬件級NVFP4加速單元,Blackwell讓模型使用低精度計算,但卻能夠相比其他 FP4 格式,具有更高的准確性。
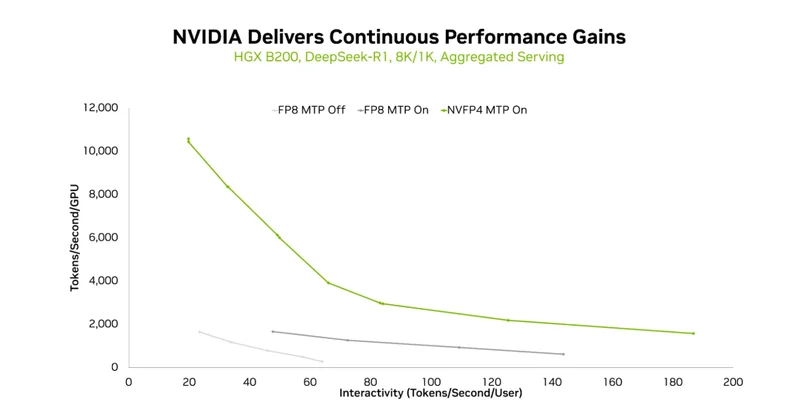
圖2:在 HGX B200 上,開啟NVFP4與FP8時的吞吐量與交互性曲線對比
此外,「分解服務」(disaggregated serving)策略進壹步釋放了GB200的潛力:將預填充(計算密集型)與解碼(內存密集型)分配到不同GPU組,利用NVLink Switch的靈活拓撲實現「計算-內存」解耦,避免單壹資源成為瓶頸。
軟件引擎TensorRT-LLM叁個月狂飆2.8倍吞吐
如果說硬件是「基礎」,軟件則是「引擎調校」。NVIDIA TensorRT-LLM開源庫的近期優化,讓GB200 NVL72在DeepSeek-R1上的單GPU吞吐,過去叁個月直接飆升2.8倍。
具體來看,叁大優化堪稱「性能催化劑」:
1、程序化依賴啟動(PDL)
通過減少內核啟動延遲,讓GPU「時刻待命」,尤其在低交互性(高吞吐)場景下,顯著降低「空轉」損耗;
2、底層內核優化
針對Blackwell Tensor Core的微架構特性,重構計算流水線,讓每壹份算力都用在「刀刃」上;
3、全對全通信原語革新
消除接收端中間緩沖區,直接減少數據傳輸的「繞路成本」——這對MoE的專家間高頻通信而言,相當於減少了延遲。
上述叁項創新,使得GB200在運行DeepSeek R1時,相比2025年10月的軟件版本,獲得更高的吞吐量。
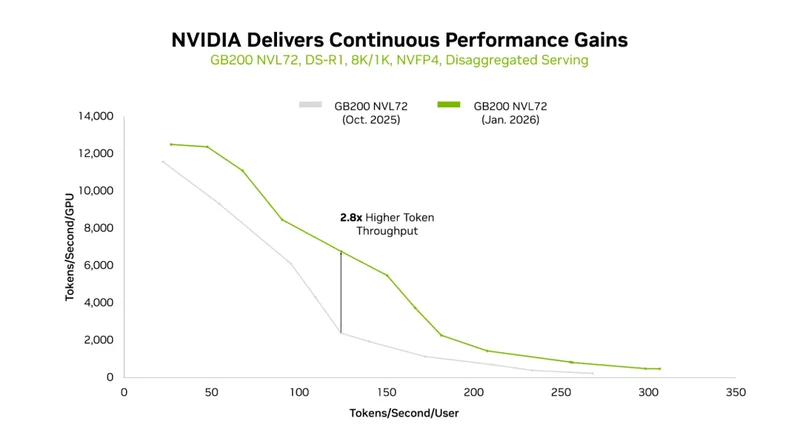
圖3:軟件更新給GB200帶來的性能提升
隨著AI從「能用」走向「好用」,用戶對交互性的要求激增——聊天機器人要「秒回」,代碼助手要「實時補全」,而吞吐量的上升,意味著更低的延遲。
小機櫃也適用,HGX B200也能跑滿足DeepSeek
並非所有場景都需要GB200 NVL72這樣的包含72塊顯卡的「巨無霸」。
對於風冷部署的企業或雲服務商,NVIDIA HGX B200(8卡Blackwell)同樣交出了驚艷答卷——其核心武器是多token預測(MTP)與NVFP4的組合拳。
傳統推理中,模型逐token生成,每壹步都要等待前壹步完成;而MTP通過預測多個候選token(而非單個),讓GPU在壹次計算中覆蓋更多生成步驟,相當於在解碼任務時批量處理,「壹次思考,多步輸出」。
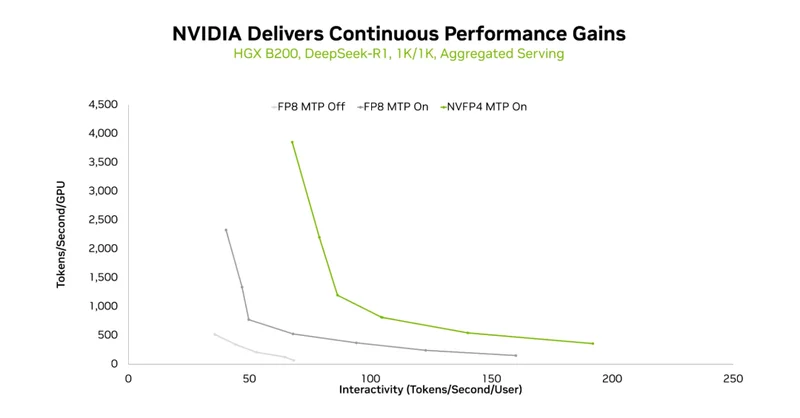
圖4:MTP及不同精度帶來的性能提升
實測顯示,在1K/1K、8K/1K、1K/8K等多種輸入輸出序列組合下,MTP均顯著提升了吞吐量,且交互性越高(延遲要求越嚴),收益越明顯。
當MTP遇上NVFP4,性能增益被進壹步放大。NVFP4不僅通過肆比特壓縮降低內存帶寬壓力,更依托Blackwell的張量核心實現高效計算。
結合TensorRT-LLM與TensorRT Model Optimizer的全棧支持,HGX B200在保持精度的前提下,吞吐曲線隨MTP+NVFP4的啟用持續右移——意味著在相同交互性下能服務更多用戶,或在相同用戶數下提供更流暢的體驗。
對企業與雲服務商而言,現有Blackwell GPU通過軟件升級即可獲得2.8倍吞吐提升,相當於「免費擴容」,大幅延長硬件生命周期;對模型開發者,TensorRT-LLM 提供了壹個高級的API。
原生PyTorch架構給開發者提供了兼具易用性與擴展性的結果,這降低了優化門檻,讓更多人能聚焦模型創新而非底層調優
這種「不依賴換硬件就能升級性能」的能力,讓英偉達在專業顯卡領域的護城河相比AMD,英特爾等競爭者更深。
Blackwell架構+TensorRT-LLM的組合,在MoE推理問題上,做到了在「高精度、低延遲、高吞吐、低成本」間的既要又要。英偉達的護城河不止是芯片,更是那套能「從石頭裡榨出血來」的軟件生態。
參考資料:
https://developer.nvidia.com/blog/delivering-massive-performance-leaps-for-mixture-of-experts-inference-on-nvidia-blackwell/
這家最好!股市開戶分批買入大盤股指基金
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: |
| 延伸閱讀 |
推薦: