
新聞  實測GPT5.5:最強模型不是嘴炮,它真能幹活兒
實測GPT5.5:最強模型不是嘴炮,它真能幹活兒
實測GPT5.5:最強模型不是嘴炮,它真能幹活兒
GPT-5.5,終於發布。
作為OpenAI當下最強的模型,這次更新的亮點是“為真實工作而設計”。
和過去的模型相比,GPT-5.5能更快理解使用者真正想做的事情,也能自己承擔更多執行過程,可以在線檢索信息、分析數據、生成文檔和表格、操作軟件,並在不同工具之間來回切換,直到把任務完成。
用戶不再需要精細地拆解每壹步,可以直接給它壹個混亂、多步驟的問題,讓它自己規劃路徑、調用工具、檢查結果,在不確定中繼續推進。
有網友直接評價,這是目前為止最接近AGI的模型。
目前,GPT-5.5已經在ChatGPT和Codex中向Plus、Pro、團隊版和企業版用戶逐步開放,GPT-5.5 Pro則面向Pro及以上用戶。API版本尚未上線。
模型性能
先來看看模型在基准測試中的得分情況。
其中最值得關注的指標是GDPval,這個測試不是傳統選擇題,而是用44種真實職業任務來評估模型,比如分析數據、寫報告、做判斷。
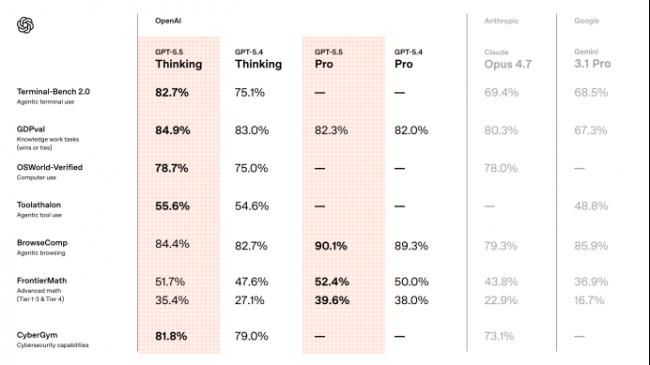
GPT-5.5的成績是84.9%,相比GPT-5.4的83.0%,有壹定的提升,也高於Claude Opus 4.7 的80.3%和Gemini 3.1 Pro的67.3%。
第贰個關鍵測試是OSWorld,用來衡量模型在真實電腦環境中的操作能力。GPT-5.5 達到78.7%,高於GPT-5.4的75.0%,提升幅度不算誇張,但意義很大。
這項能力考驗了壹個更現實的問題:模型不僅能告訴你怎麼做,還能不能直接替你去做,包括點擊界面、切換工具、執行多步驟操作。
還有Tau2 Telecom,這是壹個電信客服流程測試,GPT-5.5 在無需額外調優的情況下達到98.0%。這類任務更接近企業裡的真實工作,需要在復雜、多步驟、有上下文依賴的流程中完成。
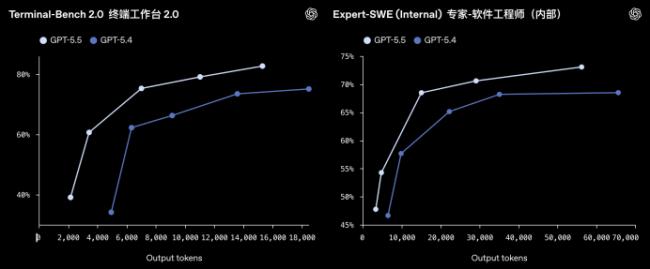
在更細分的能力上,GPT-5.5的編程能力繼續提升,在Terminal-Bench 2.0上達到了82.7%,在SWE-Bench Pro上達到了58.6%。
在其他知識工作基准測試中,GPT-5.5的表現也很出色:FinanceAgent得分60.0%,內部投資銀行建模任務得分88.5%,OfficeQA Pro得分54.1%。說明它在結構化分析和數據處理上已經相當成熟。
科研方面雖然分數提升相對溫和,但已經出現能夠參與推理、驗證甚至輔助發現新結果的案例,這壹點更像能力邊界的變化,而不是簡單的性能增長。
把這些跑分放在壹起看,會發現這次模型的評價標准正在發生變化:過去我們常用MMLU、GPQA這樣的指標看模型的知識和推理能力,但現在更側重於GDPval、OSWorld這類“任務級評估”。
[加西網正招聘多名全職sales 待遇優]
好新聞沒人評論怎麼行,我來說幾句
作為OpenAI當下最強的模型,這次更新的亮點是“為真實工作而設計”。
和過去的模型相比,GPT-5.5能更快理解使用者真正想做的事情,也能自己承擔更多執行過程,可以在線檢索信息、分析數據、生成文檔和表格、操作軟件,並在不同工具之間來回切換,直到把任務完成。
用戶不再需要精細地拆解每壹步,可以直接給它壹個混亂、多步驟的問題,讓它自己規劃路徑、調用工具、檢查結果,在不確定中繼續推進。
有網友直接評價,這是目前為止最接近AGI的模型。
目前,GPT-5.5已經在ChatGPT和Codex中向Plus、Pro、團隊版和企業版用戶逐步開放,GPT-5.5 Pro則面向Pro及以上用戶。API版本尚未上線。
模型性能
先來看看模型在基准測試中的得分情況。
其中最值得關注的指標是GDPval,這個測試不是傳統選擇題,而是用44種真實職業任務來評估模型,比如分析數據、寫報告、做判斷。
GPT-5.5的成績是84.9%,相比GPT-5.4的83.0%,有壹定的提升,也高於Claude Opus 4.7 的80.3%和Gemini 3.1 Pro的67.3%。
第贰個關鍵測試是OSWorld,用來衡量模型在真實電腦環境中的操作能力。GPT-5.5 達到78.7%,高於GPT-5.4的75.0%,提升幅度不算誇張,但意義很大。
這項能力考驗了壹個更現實的問題:模型不僅能告訴你怎麼做,還能不能直接替你去做,包括點擊界面、切換工具、執行多步驟操作。
還有Tau2 Telecom,這是壹個電信客服流程測試,GPT-5.5 在無需額外調優的情況下達到98.0%。這類任務更接近企業裡的真實工作,需要在復雜、多步驟、有上下文依賴的流程中完成。
在更細分的能力上,GPT-5.5的編程能力繼續提升,在Terminal-Bench 2.0上達到了82.7%,在SWE-Bench Pro上達到了58.6%。
在其他知識工作基准測試中,GPT-5.5的表現也很出色:FinanceAgent得分60.0%,內部投資銀行建模任務得分88.5%,OfficeQA Pro得分54.1%。說明它在結構化分析和數據處理上已經相當成熟。
科研方面雖然分數提升相對溫和,但已經出現能夠參與推理、驗證甚至輔助發現新結果的案例,這壹點更像能力邊界的變化,而不是簡單的性能增長。
把這些跑分放在壹起看,會發現這次模型的評價標准正在發生變化:過去我們常用MMLU、GPQA這樣的指標看模型的知識和推理能力,但現在更側重於GDPval、OSWorld這類“任務級評估”。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 |
推薦: