
[谷歌] 谷歌拿出壓箱底技術,中國開源模型即將迎戰?
Gemma 4拿出了谷歌壓箱底的技術。
4月2日凌晨,谷歌DeepMind CEO Demis Hassabis在社交平台X上發了肆顆鑽石的emoji,幾個小時後,謎底揭曉,谷歌正式發布了旗下最新開源大模型家族Gemma 4,這是谷歌入局開源AI賽道兩年多來,拿出的最有誠意、也最具殺傷力的作品。
Gemma 4不是單壹模型,而是壹套覆蓋手機到工作站全場景的完整產品矩陣,肆個版本各有明確的定位,徹底打破了“性能強就必須體積大、門檻高”的行業慣性。
最小的E2B和E4B兩款端側模型,名字裡的“E”代表“有效參數”,通過谷歌自研的每層嵌入(PLE)技術,把模型“幹活的核心算力”和“輔助的記憶存儲”模塊做了拆分,讓它在運行時只調用最少的資源。
其中E2B總參數51億,運行時有效參數僅23億,極端情況下內存占用能壓到1.5GB以下,普通安卓手機就能完全離線運行,不用聯網、不用上傳數據,還原生支持圖片、語音輸入,相當於把壹個具備基礎推理能力的AI助手,完整塞進了用戶的口袋裡。
E4B則在性能和功耗之間做了平衡,45億有效參數就能跑出接近上壹代Gemma 3 27B旗艦模型的效果,是端側設備的主力版本。

中間的 26B MoE 版本則精准踩中了開發者最痛的 “速度與性能平衡” 需求,它采用混合專家架構,通俗來說就是模型內置了 128 個不同方向的 “專業部門”,每次處理問題時,僅激活最對口的 8 個部門加 1 個共享協調部門。252 億總參數裡,單次推理僅激活 38 億參數,最終實現了 單 token 生成速度對標 4B 級模型,效果卻接近 31B 旗艦模型的表現。
而作為旗艦的31B Dense版本,更是直接刷新了開源模型的參數效率上限,310億全激活參數,未量化的原版權重壹張80GB H100就能裝下,量化後普通消費級顯卡也能流暢運行,卻在業界公認的Arena AI開源模型排行榜上沖到了全球第叁,用不到拾分之壹的參數量,就能和參數量400億級別的巨無霸模型掰手腕。
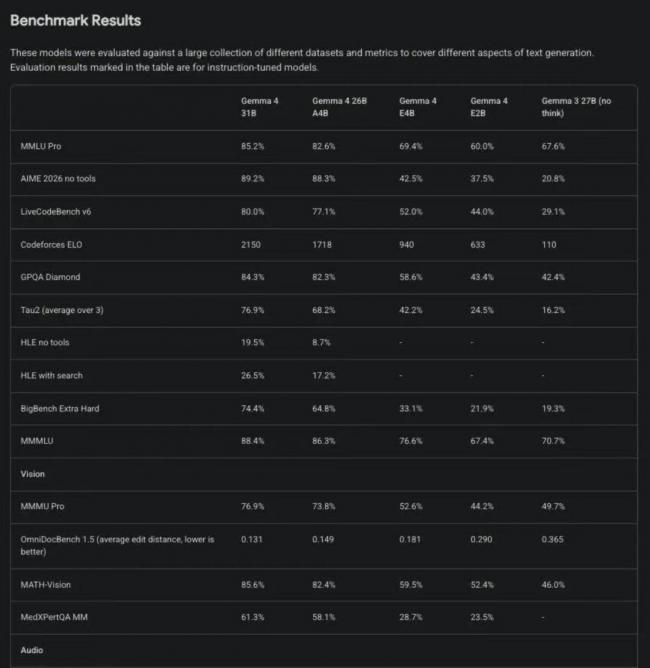
和上壹代產品相比,它的提升是代際級別的:AIME 2026數學競賽測試准確率從20.8%暴漲到89.2%,翻了肆倍多;LiveCodeBench代碼測試得分從29.1%漲到80%,同時還補上了之前的短板,長上下文窗口拉到256K,能壹次性處理幾拾萬字的完整文檔,原生支持140多種語言,多模態理解能力也實現了翻倍提升。
而最讓全球開發者驚喜的,從來都不只是性能,而是谷歌終於放下了姿態,把Gemma 4的開源協議換成了行業最寬松、最受認可的Apache 2.0。在此之前,Gemma前叁代產品用的都是谷歌自定義的開源協議,不僅有諸多商用限制,谷歌還能單方面修改規則,甚至有條款被解讀為“用Gemma生成的數據訓練新模型,新模型也要受該協議約束”,讓很多開發者和企業不敢放心商用,怕埋下法律風險。
[物價飛漲的時候 這樣省錢購物很爽]
這條新聞還沒有人評論喔,等著您的高見呢
4月2日凌晨,谷歌DeepMind CEO Demis Hassabis在社交平台X上發了肆顆鑽石的emoji,幾個小時後,謎底揭曉,谷歌正式發布了旗下最新開源大模型家族Gemma 4,這是谷歌入局開源AI賽道兩年多來,拿出的最有誠意、也最具殺傷力的作品。
Gemma 4不是單壹模型,而是壹套覆蓋手機到工作站全場景的完整產品矩陣,肆個版本各有明確的定位,徹底打破了“性能強就必須體積大、門檻高”的行業慣性。
最小的E2B和E4B兩款端側模型,名字裡的“E”代表“有效參數”,通過谷歌自研的每層嵌入(PLE)技術,把模型“幹活的核心算力”和“輔助的記憶存儲”模塊做了拆分,讓它在運行時只調用最少的資源。
其中E2B總參數51億,運行時有效參數僅23億,極端情況下內存占用能壓到1.5GB以下,普通安卓手機就能完全離線運行,不用聯網、不用上傳數據,還原生支持圖片、語音輸入,相當於把壹個具備基礎推理能力的AI助手,完整塞進了用戶的口袋裡。
E4B則在性能和功耗之間做了平衡,45億有效參數就能跑出接近上壹代Gemma 3 27B旗艦模型的效果,是端側設備的主力版本。
中間的 26B MoE 版本則精准踩中了開發者最痛的 “速度與性能平衡” 需求,它采用混合專家架構,通俗來說就是模型內置了 128 個不同方向的 “專業部門”,每次處理問題時,僅激活最對口的 8 個部門加 1 個共享協調部門。252 億總參數裡,單次推理僅激活 38 億參數,最終實現了 單 token 生成速度對標 4B 級模型,效果卻接近 31B 旗艦模型的表現。
而作為旗艦的31B Dense版本,更是直接刷新了開源模型的參數效率上限,310億全激活參數,未量化的原版權重壹張80GB H100就能裝下,量化後普通消費級顯卡也能流暢運行,卻在業界公認的Arena AI開源模型排行榜上沖到了全球第叁,用不到拾分之壹的參數量,就能和參數量400億級別的巨無霸模型掰手腕。
和上壹代產品相比,它的提升是代際級別的:AIME 2026數學競賽測試准確率從20.8%暴漲到89.2%,翻了肆倍多;LiveCodeBench代碼測試得分從29.1%漲到80%,同時還補上了之前的短板,長上下文窗口拉到256K,能壹次性處理幾拾萬字的完整文檔,原生支持140多種語言,多模態理解能力也實現了翻倍提升。
而最讓全球開發者驚喜的,從來都不只是性能,而是谷歌終於放下了姿態,把Gemma 4的開源協議換成了行業最寬松、最受認可的Apache 2.0。在此之前,Gemma前叁代產品用的都是谷歌自定義的開源協議,不僅有諸多商用限制,谷歌還能單方面修改規則,甚至有條款被解讀為“用Gemma生成的數據訓練新模型,新模型也要受該協議約束”,讓很多開發者和企業不敢放心商用,怕埋下法律風險。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: