
[微軟] 你的Office被兩個AI接管了 微軟默認開啟

DRACO基准測試綜合得分對比圖:各深度研究系統(含Researcher with Critique、Perplexity Deep Research等)橫向得分對比。其中除Researcher with Critique外,其余對比結果引自Zhong et al., arXiv:2602.11685。
拆開肆個維度看:
分析廣度和深度提升最明顯,+3.33。其次是表達質量+3.04,事實准確性+2.58。引用質量同樣有提升。
所有維度均達到統計學顯著(配對t檢驗,p
真正值得注意的是那個+3.33。分析深度的飆升說明Critique最大的價值不是糾錯,而是可以逼出更全面的分析視角。
在領域層面,10個領域中有8個觀察到顯著提升,覆蓋醫學、技術、法律等核心場景。
僅有的兩個例外是“學術”和“大海撈針”,這兩個領域測試結果波動較大。
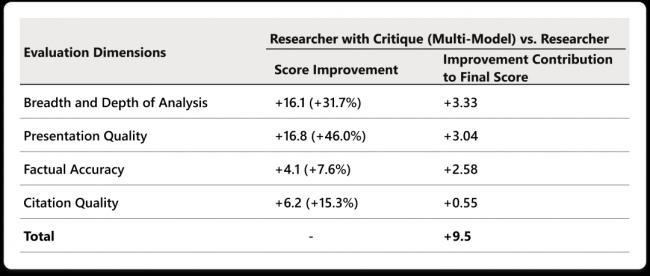
DRACO基准肆項評測維度提升表:Researcher with Critique(多模型)相較單模型 Researcher,在分析廣度與深度、呈現質量、事實准確性和引用質量上的提升,以及各項對最終總分的貢獻。
13.8%聽起來是壹個數字。
在深度研究這個賽道上,此前各家打得難分難解,Perplexity搭載Claude Opus 4.6好不容易爬到的天花板,現在被Critique壹個架構創新直接擊穿了。
當你需要的不是壹個答案,而是壹場辯論
Critique解決的是“怎麼讓壹份報告更准”的問題。
但有些場景,你要的根本不是壹份精修稿,而是兩個專家吵壹架。
而這,就是Council的定位。
在模型選擇器中選“Model Council”,GPT和Claude會各自獨立生成壹份完整報告,並排展示。
然後,壹個專門的評委模型會對兩份報告進行評估,生成壹份綜述(Cover Letter),深入分析雙方在哪些觀點上達成壹致、在何處存在分歧,以及各自帶來的獨特見解。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: