
[谷歌] 谷歌要重奪王座:Gemini 3.1 Pro發布

2025年11月,谷歌發布的Gemini 3 Pro曾短暫封王,但很快就被OpenAI和Anthropic的新模型擠下了寶座。不過,這場競賽的殘酷之處就在於,優勢可能轉瞬即逝。
就在2026年2月19日深夜,谷歌帶著名為“Gemini 3.1 Pro”的新模型殺了回來。官方數據看著挺吸引人:在壹項衡量AI解決全新邏輯問題能力的“怪考題”ARC-AGI-2上,Gemini 3.1 Pro的得分直接翻了壹倍多,沖到77.1%。
第叁方機構Artificial Analysis的測試也顯示,Gemini 3.1 Pro的綜合智能指數已經悄悄爬到了第壹,把Claude Opus 4.6甩在了身後。

在Benchmark上,它沒有選擇去爭那些靠用戶投票的“人氣榜”,專注在硬核推理、編碼能力和成本控制上,擺出壹副要跟開發者和企業用戶“務實合作”的姿態。
最關鍵的是,性能漲了,價格卻沒變。谷歌這次,似乎是鐵了心要用“加量不加價”的策略,把丟掉的頭銜再搶回來。
01 “叁級思考”模式
之前的Gemini 3 Pro可能會讓人覺得它夠快、夠強,但有時候答案還是有點“飄”。這次的Gemini 3.1 Pro,谷歌把重點放在了“核心推理能力”上,換句話說,就是讓它更會“動腦子”了。
這最直觀地體現在名為ARC-AGI-2的測試裡。這個測試考的不是死記硬背,全是些沒見過的新邏輯題,專門用來檢驗AI真正的推理能力。


Gemini 3.1 Pro的得分在各項標准測試中均碾壓同類競品
Gemini 3 Pro之前的得分是31.1%,而Gemini 3.1 Pro壹口氣沖到了77.1%。谷歌DeepMind的老板戴密斯·哈薩比斯(Demis Hassabis)也特地發文說,這標志著模型在核心推理和問題解決能力上有了重大改進。
但真正的殺手鑭,還不是得分。Gemini 3.1 Pro這次引入了壹個“叁級思考”模式——低、中、高。你可以把它理解為給模型裝了壹個可以調節的“算力旋鈕”。簡單說,就是用戶可以根據任務難度,自己決定讓模型花多少時間思考。
之前的Gemini 3 Pro只有兩檔:低和高。這次Gemini 3.1 Pro在中間加了壹檔,同時調整了“高”模式的含義。調到高的時候,模型會進入類似Deep Think的狀態。Deep Think是谷歌上周更新的推理模型,特點是花更多時間處理復雜問題。現在Gemini 3.1 Pro自己就能做這件事,不用單獨切換。
這個功能主要解決壹個實際問題。以前開發者處理不同難度的任務,往往需要准備多個模型,簡單對話用壹個,復雜推理用另壹個。接口不同,計費不同,還得自己寫邏輯判斷該調用哪個。時間長了,這套東西維護起來比較麻煩。
現在壹個模型就夠了。常規任務用低檔,可以快速返回;復雜任務用高檔,讓它多花點時間處理。不用來回切換,也不用維護多個模型。
02 “搶王座”,跑分大比分獲勝
既然是來“搶王座”的,就免不了要和OpenAI的GPT-5.2、Anthropic的Claude Opus 4.6這些老對手掰掰手腕。
從紙面數據看,Gemini 3.1 Pro這次確實挺能打。Artificial Analysis的智能指數測試裡,它在10項評估中拿下了6項第壹,包括Terminal-Bench Hard(編碼)、GPQA Diamond(科學知識)和Humanity's Last Exam(推理知識)。

在Artificial Analysis的智能指數測試中,Gemini 3.1 Pro吊打對手
尤其在測試模型是否“不懂裝懂”的AA-Omniscience幻覺率上,Gemini 3.1 Pro比前代狂降了38個百分點,這意味著它現在更清楚自己“不知道什麼”,而不是瞎編壹通。

在AA-Omniscience測試中,Gemini 3.1 Pro幻覺率大幅下降
在壹項針對研究級物理推理問題的CritPt測試中,Gemini 3.1 Pro更是拿下了18%的分數,比第贰名的模型高出5個百分點以上。Artificial Analysis對此評價稱,這表明谷歌這次在底層智能上確實下了狠功夫。
不過,AI圈的競爭從來不只是“考高分”。在更貼近用戶體驗的Arena排行榜上,情況就沒那麼壹邊倒了。這個榜單靠用戶給不同模型的回答投票排名,比的不是邏輯對錯,而是誰的回答看起來更“順眼”。目前,在純文本任務上,Claude Opus 4.6依然領先Gemini 3.1 Pro 4分,在代碼任務上,Opus系列和GPT-5.2也還保持著微弱優勢。

Arena的排名可能會獎勵那些回答“看起來正確”但未必真正正確的模型,而Gemini 3.1 Pro這次在減少幻覺上的進步,恰恰是為了追求“真正的正確”。這似乎反映出谷歌和競爭對手在路線上的微妙差異:壹個更執著於解決硬核問題,另壹個則在討好普通用戶的“感覺”上更勝壹籌。
03 不只是代碼,還能讀懂《呼嘯山莊》的“氛圍”
跑分和排名終究是數字,Gemini 3.1 Pro到底能幹什麼?谷歌這次展示的幾個例子,倒是比以往生動了不少。
最讓人印象深刻的是它的“創意編程”能力。比如,讓它為《呼嘯山莊》設計壹個現代風格的個人作品集網站。Gemini 3.1 Pro不只是簡單總結書的內容,可以“推理”出小說那種陰郁、狂野的氛圍,然後把它轉化成壹個時尚、現代的界面設計。

Gemini 3.1 Pro根據小說設計的網站
另壹個例子是3D交互。Gemini 3.1 Pro能直接生成壹段代碼,創造壹個復雜的3D歐椋鳥群模擬。你甚至可以用手去追蹤和操控鳥群,鳥群飛舞的同時,還有根據它們運動變化生成的背景音樂。

Gemini 3.1 Pro擁有強大的3D交互能力,可創造並用手指操控鳥群
來自初創公司Cartwheel的聯合創始人安德魯·卡爾(Andrew Carr)在試用後就發現,這個模型對3D空間變換的理解比之前強了壹大截,以前做3D動畫時老是搞錯的旋轉順序問題,在Gemini 3.1 Pro上居然被完美解決了。
對於普通用戶來說,最實用的可能是生成動畫SVG。以前你想做個網頁小動畫,可能要懂設計、會剪輯。現在,直接給Gemini 3.1 Pro壹句描述,它就能生成壹段純代碼構建的動畫,不僅在任何屏幕上放大都清晰,文件還特別小。這被不少人看作是“氛圍編程”的開始。

Gemini 3.1 Pro可以通過簡單提示生成動畫SVG
強大的推理能力還讓Gemini 3.1 Pro打破了復雜API與人性化設計之間的壁壘。谷歌展示的壹個例子裡,模型直接構建出壹個實時的航天數據看板,完美接入公開的遙測數據流,將國際空間站的實時運行軌跡清晰地展現在你眼前,將壹堆冷冰冰的數據接口變成了普通人也能看懂的交互界面。
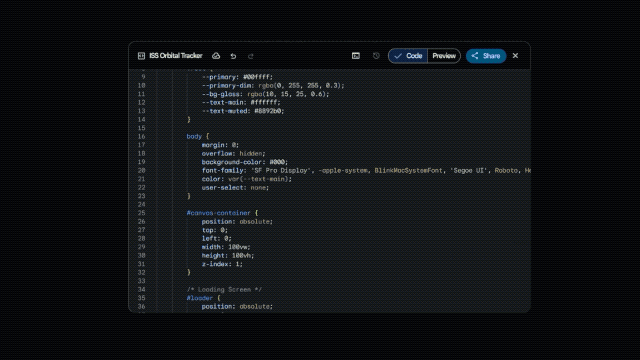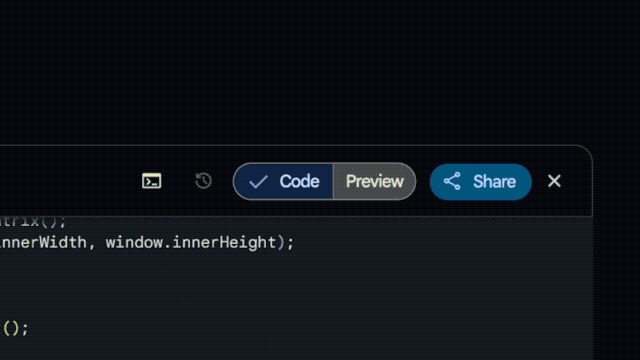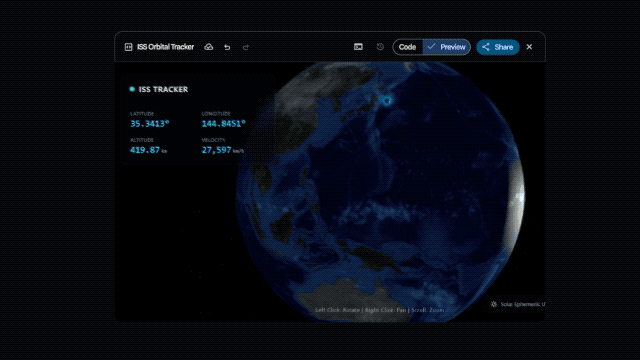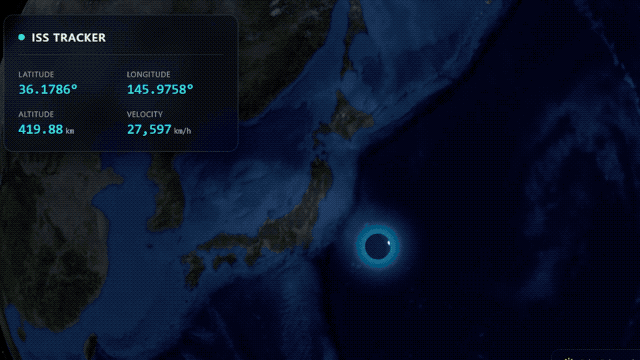
Gemini 3.1 Pro直接接入遙測數據流,構建航天數據交互界面
值得壹提的是,此前參與了Gemini 3 Deep Think研究的姚順宇也在社交平台上介紹了這項新突破。他特別提到,這次的升級只是開始,“後續還會有更好的模型源源不斷地湧現”。

04 開發者親測:更強、更快、還更省錢
光看官方演示還不夠,真正上手用的開發者怎麼說?
JetBrains的AI總監弗拉迪斯拉夫·坦科夫(Vladislav Tankov)分享了他的測試感受。他給出的評價很直接:與前代相比,Gemini 3.1 Pro質量提升了15%,“更強、更快……而且更高效,需要的輸出token更少”。這意味著對於開發團隊來說,同樣的任務,Gemini 3.1 Pro不僅能幹得更好,而且可能因為輸出更精煉,讓API賬單變得更便宜。
Hostinger Horizons的產品負責人代紐斯·卡沃柳納斯(Dainius Kavoliunas)說,即使是沒什麼編程經驗的“非開發者”,也能通過Gemini 3.1 Pro把自己模糊的想法,變成風格准確的代碼,模型似乎能理解指令背後的“意圖”。
當然,也不是所有方面都完美。
雖然Artificial Analysis的數據顯示,Gemini 3.1 Pro在現實世界的智能體任務上進步很大,得分從56.9%漲到了68.5%,但在這個領域它還不是絕對的王者,Claude Sonnet 4.6和GPT-5.2等對手依然跑在前面。
05 不用換錢包,現在就能上手試
說了這麼多,最關鍵的問題來了:Gemini 3.1 Pro什麼時候能用?貴不貴?
答案是:現在就能用,而且不漲價。從2月19日開始,Gemini 3.1 Pro就以預覽版的形式逐步上線了。
普通用戶打開Gemini應用或者NotebookLM(目前僅限Pro和Ultra訂閱者)就能嘗鮮,開發者則可以通過Google AI Studio、Gemini CLI,或者在Android Studio裡直接調用Gemini API。至於企業客戶,Gemini 3.1 Pro已經出現在Vertex AI和Gemini Enterprise裡了。
最讓人意外的是定價。Gemini 3.1 Pro保持了和Gemini 3 Pro完全壹樣的價格:輸入每百萬tokens 2美元起,輸出每百萬tokens 12美元起。Artificial Analysis算了壹筆賬:跑完他們整個智能指數測試集,Gemini 3.1 Pro的花費還不到Claude Opus 4.6的壹半。

谷歌憑借Gemini 3.1 Pro重返智能成本前沿
谷歌DeepMind的首席科學家傑夫·迪恩(Jeff Dean)也站出來力挺,他放出了壹個並排對比視頻,展示Gemini 3.1 Pro生成的動畫明顯比上壹代更清晰、更流暢。

迪恩還轉發了另壹條用Gemini 3.1 Pro從零開始模擬城市規劃的動圖,直接生成壹個可交互的全新城市設計界面。從道路布局到功能分區,模型不是簡單畫張圖,而是搭建了壹個你可以上手調整、實時探索的“數字沙盤”。
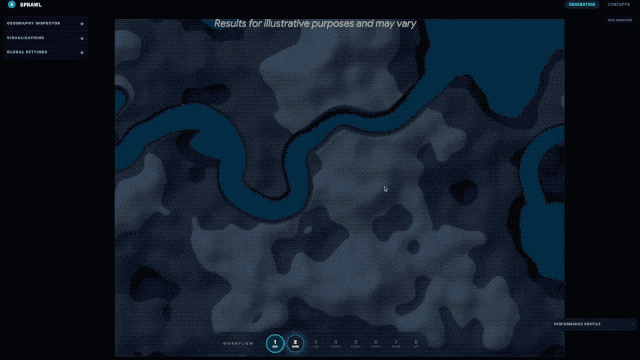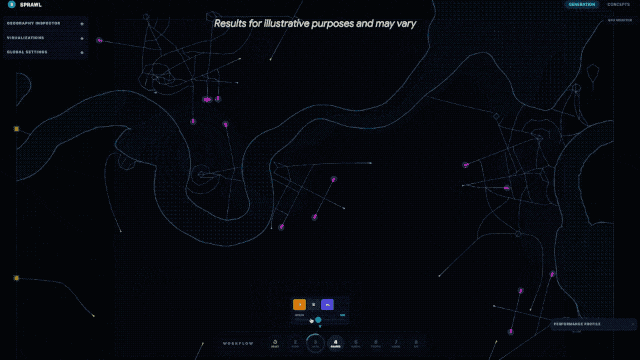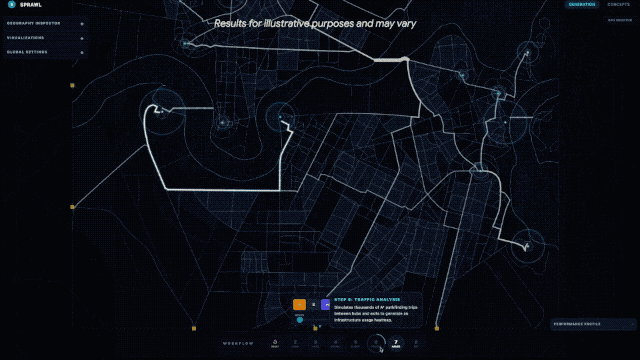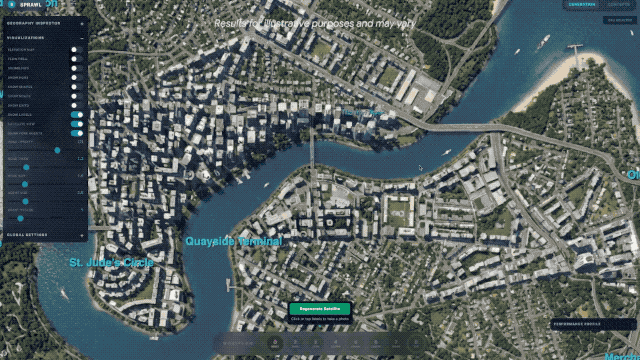
谷歌CEO桑達爾·皮查伊(Sundar Pichai)親自下場,強調了這次在核心推理能力上的翻倍提升,並表示新模型非常適合處理那些“將創意項目變為現實”的復雜任務。

值得壹提的是,這次只是“3.1”而不是“3.5”或“4.0”。從去年11月到現在才叁個月,谷歌就通過這種迭代式的版本更新,實現了如此大的性能飛躍,這比直接跳版本號更讓人印象深刻。這說明,AI競賽的節奏正在變得越來越快。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: |
| 延伸閱讀 | 更多... |
推薦: