
新聞  字節豆包2.0發布 正面對標GPT-5和Gemini 3
字節豆包2.0發布 正面對標GPT-5和Gemini 3
字節豆包2.0發布 正面對標GPT-5和Gemini 3
字節跳動旗下豆包大模型正式進入2.0階段,推出面向Agent時代的系統性升級版本。新版本在保持與GPT-5.2和Gemini 3 Pro相當性能的同時,將推理成本降低約壹個數量級,為大規模生產環境下的復雜任務執行提供更具競爭力的解決方案。
2月14日,字節跳動宣布,豆包2.0系列包含Pro、Lite、Mini叁款通用Agent模型和專門的Code模型。其中旗艦版豆包2.0 Pro全面對標GPT-5.2與Gemini 3 Pro,在多數視覺理解基准測試中達到業界最高水平,並在數學奧賽IMO、CMO和編程競賽ICPC中獲得金牌成績。
該系列模型已全面上線。豆包2.0 Pro已接入豆包App、電腦端和網頁版的"專家"模式,Code版本已集成至AI編程產品TRAE,火山引擎同步上線面向企業和開發者的API服務。
分析認為,在現實世界復雜任務中,由於大規模推理與長鏈路生成將消耗大量token,豆包2.0的成本優勢將成為關鍵競爭力。這標志著字節跳動在大模型商業化應用上邁出重要壹步。
多模態能力達到世界頂尖水平
豆包2.0全面升級了多模態能力,在視覺推理、感知能力、空間推理與長上下文理解等任務上表現突出。
在動態場景理解方面,該模型在TVBench等關鍵測評中處於領先位置,在EgoTempo基准上甚至超過人類分數,顯示其對變化、動作、節奏等信息的捕捉更為穩定。
在長視頻場景中,豆包2.0在大多數評測上超越其他頂尖模型,並在多個流式實時問答視頻基准測試中表現優異。
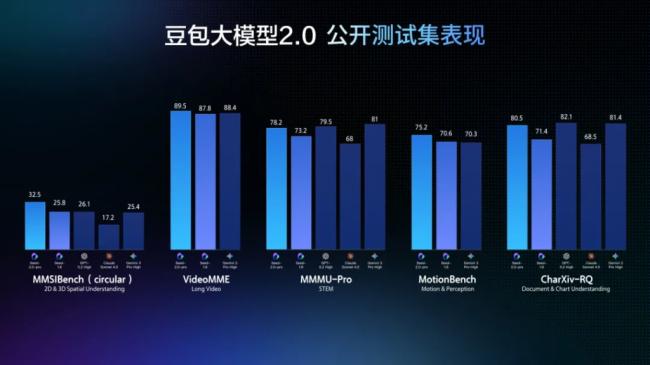
這使其能夠作為AI助手完成實時視頻流分析、環境感知、主動糾錯與情感陪伴,實現從被動問答到主動指導的交互升級,可應用於健身、穿搭等陪伴場景。
推理能力對標頂尖模型,成本優勢顯著
豆包2.0 Pro通過加強長尾領域知識,在SuperGPQA上分數超過GPT-5.2,並在HealthBench上獲得第壹名,在科學領域的整體成績與Gemini 3 Pro和GPT-5.2相當。
在推理和Agent能力評測中,該模型在IMO、CMO數學奧賽和ICPC編程競賽中獲得金牌成績,也超越了Gemini 3 Pro在Putnam Bench上的表現。
在HLE-text(人類的最後考試)上,豆包2.0 Pro取得最高分54.2分,在工具調用和指令遵循測試中也有出色表現。
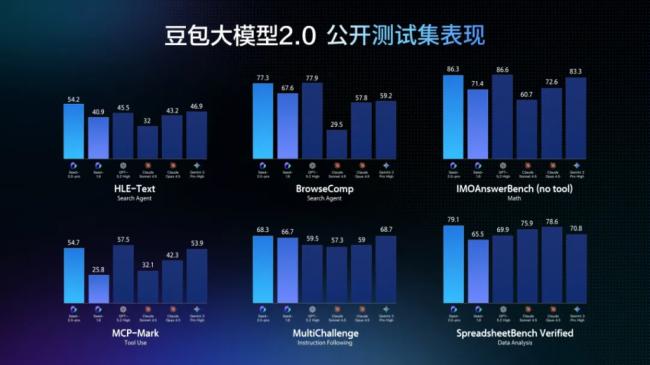
更重要的是,字節跳動表示,該模型在保持與業界頂尖大模型相當效果的同時,token定價降低了約壹個數量級,這壹成本優勢在大規模推理與長鏈路生成場景中將變得更為關鍵。
基於OpenClaw框架和豆包2.0 Pro模型,字節跳動在飛書上構建了智能客服Agent。
該Agent能通過調用不同技能完成客戶對話,遇到難題時會主動拉群求助真人同事,幫客戶預約上門維修人員,並在維修後主動回訪和推薦產品。
[加西網正招聘多名全職sales 待遇優]
這條新聞還沒有人評論喔,等著您的高見呢
2月14日,字節跳動宣布,豆包2.0系列包含Pro、Lite、Mini叁款通用Agent模型和專門的Code模型。其中旗艦版豆包2.0 Pro全面對標GPT-5.2與Gemini 3 Pro,在多數視覺理解基准測試中達到業界最高水平,並在數學奧賽IMO、CMO和編程競賽ICPC中獲得金牌成績。
該系列模型已全面上線。豆包2.0 Pro已接入豆包App、電腦端和網頁版的"專家"模式,Code版本已集成至AI編程產品TRAE,火山引擎同步上線面向企業和開發者的API服務。
分析認為,在現實世界復雜任務中,由於大規模推理與長鏈路生成將消耗大量token,豆包2.0的成本優勢將成為關鍵競爭力。這標志著字節跳動在大模型商業化應用上邁出重要壹步。
多模態能力達到世界頂尖水平
豆包2.0全面升級了多模態能力,在視覺推理、感知能力、空間推理與長上下文理解等任務上表現突出。
在動態場景理解方面,該模型在TVBench等關鍵測評中處於領先位置,在EgoTempo基准上甚至超過人類分數,顯示其對變化、動作、節奏等信息的捕捉更為穩定。
在長視頻場景中,豆包2.0在大多數評測上超越其他頂尖模型,並在多個流式實時問答視頻基准測試中表現優異。
這使其能夠作為AI助手完成實時視頻流分析、環境感知、主動糾錯與情感陪伴,實現從被動問答到主動指導的交互升級,可應用於健身、穿搭等陪伴場景。
推理能力對標頂尖模型,成本優勢顯著
豆包2.0 Pro通過加強長尾領域知識,在SuperGPQA上分數超過GPT-5.2,並在HealthBench上獲得第壹名,在科學領域的整體成績與Gemini 3 Pro和GPT-5.2相當。
在推理和Agent能力評測中,該模型在IMO、CMO數學奧賽和ICPC編程競賽中獲得金牌成績,也超越了Gemini 3 Pro在Putnam Bench上的表現。
在HLE-text(人類的最後考試)上,豆包2.0 Pro取得最高分54.2分,在工具調用和指令遵循測試中也有出色表現。
更重要的是,字節跳動表示,該模型在保持與業界頂尖大模型相當效果的同時,token定價降低了約壹個數量級,這壹成本優勢在大規模推理與長鏈路生成場景中將變得更為關鍵。
基於OpenClaw框架和豆包2.0 Pro模型,字節跳動在飛書上構建了智能客服Agent。
該Agent能通過調用不同技能完成客戶對話,遇到難題時會主動拉群求助真人同事,幫客戶預約上門維修人員,並在維修後主動回訪和推薦產品。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
推薦: