
新闻  字节豆包2.0发布 正面对标GPT-5和Gemini 3
字节豆包2.0发布 正面对标GPT-5和Gemini 3
字节豆包2.0发布 正面对标GPT-5和Gemini 3
字节跳动旗下豆包大模型正式进入2.0阶段,推出面向Agent时代的系统性升级版本。新版本在保持与GPT-5.2和Gemini 3 Pro相当性能的同时,将推理成本降低约一个数量级,为大规模生产环境下的复杂任务执行提供更具竞争力的解决方案。
2月14日,字节跳动宣布,豆包2.0系列包含Pro、Lite、Mini三款通用Agent模型和专门的Code模型。其中旗舰版豆包2.0 Pro全面对标GPT-5.2与Gemini 3 Pro,在多数视觉理解基准测试中达到业界最高水平,并在数学奥赛IMO、CMO和编程竞赛ICPC中获得金牌成绩。
该系列模型已全面上线。豆包2.0 Pro已接入豆包App、电脑端和网页版的"专家"模式,Code版本已集成至AI编程产品TRAE,火山引擎同步上线面向企业和开发者的API服务。
分析认为,在现实世界复杂任务中,由于大规模推理与长链路生成将消耗大量token,豆包2.0的成本优势将成为关键竞争力。这标志着字节跳动在大模型商业化应用上迈出重要一步。
多模态能力达到世界顶尖水平
豆包2.0全面升级了多模态能力,在视觉推理、感知能力、空间推理与长上下文理解等任务上表现突出。
在动态场景理解方面,该模型在TVBench等关键测评中处于领先位置,在EgoTempo基准上甚至超过人类分数,显示其对变化、动作、节奏等信息的捕捉更为稳定。
在长视频场景中,豆包2.0在大多数评测上超越其他顶尖模型,并在多个流式实时问答视频基准测试中表现优异。
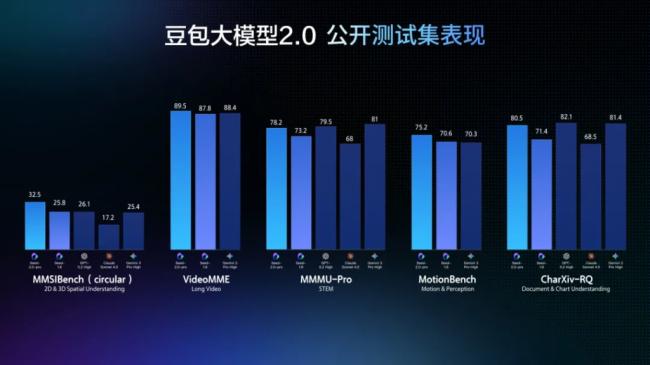
这使其能够作为AI助手完成实时视频流分析、环境感知、主动纠错与情感陪伴,实现从被动问答到主动指导的交互升级,可应用于健身、穿搭等陪伴场景。
推理能力对标顶尖模型,成本优势显著
豆包2.0 Pro通过加强长尾领域知识,在SuperGPQA上分数超过GPT-5.2,并在HealthBench上获得第一名,在科学领域的整体成绩与Gemini 3 Pro和GPT-5.2相当。
在推理和Agent能力评测中,该模型在IMO、CMO数学奥赛和ICPC编程竞赛中获得金牌成绩,也超越了Gemini 3 Pro在Putnam Bench上的表现。
在HLE-text(人类的最后考试)上,豆包2.0 Pro取得最高分54.2分,在工具调用和指令遵循测试中也有出色表现。
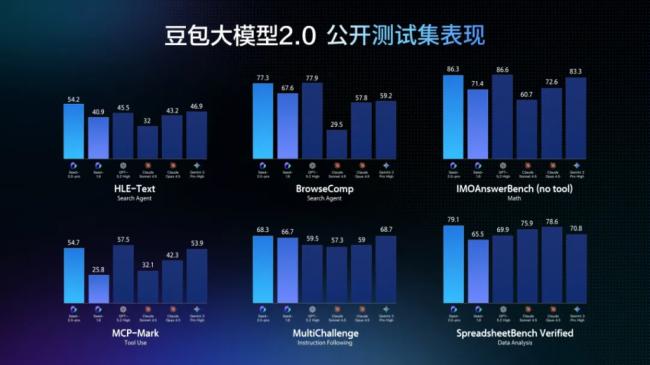
更重要的是,字节跳动表示,该模型在保持与业界顶尖大模型相当效果的同时,token定价降低了约一个数量级,这一成本优势在大规模推理与长链路生成场景中将变得更为关键。
基于OpenClaw框架和豆包2.0 Pro模型,字节跳动在飞书上构建了智能客服Agent。
该Agent能通过调用不同技能完成客户对话,遇到难题时会主动拉群求助真人同事,帮客户预约上门维修人员,并在维修后主动回访和推荐产品。
[加西网正招聘多名全职sales 待遇优]
无评论不新闻,发表一下您的意见吧
2月14日,字节跳动宣布,豆包2.0系列包含Pro、Lite、Mini三款通用Agent模型和专门的Code模型。其中旗舰版豆包2.0 Pro全面对标GPT-5.2与Gemini 3 Pro,在多数视觉理解基准测试中达到业界最高水平,并在数学奥赛IMO、CMO和编程竞赛ICPC中获得金牌成绩。
该系列模型已全面上线。豆包2.0 Pro已接入豆包App、电脑端和网页版的"专家"模式,Code版本已集成至AI编程产品TRAE,火山引擎同步上线面向企业和开发者的API服务。
分析认为,在现实世界复杂任务中,由于大规模推理与长链路生成将消耗大量token,豆包2.0的成本优势将成为关键竞争力。这标志着字节跳动在大模型商业化应用上迈出重要一步。
多模态能力达到世界顶尖水平
豆包2.0全面升级了多模态能力,在视觉推理、感知能力、空间推理与长上下文理解等任务上表现突出。
在动态场景理解方面,该模型在TVBench等关键测评中处于领先位置,在EgoTempo基准上甚至超过人类分数,显示其对变化、动作、节奏等信息的捕捉更为稳定。
在长视频场景中,豆包2.0在大多数评测上超越其他顶尖模型,并在多个流式实时问答视频基准测试中表现优异。
这使其能够作为AI助手完成实时视频流分析、环境感知、主动纠错与情感陪伴,实现从被动问答到主动指导的交互升级,可应用于健身、穿搭等陪伴场景。
推理能力对标顶尖模型,成本优势显著
豆包2.0 Pro通过加强长尾领域知识,在SuperGPQA上分数超过GPT-5.2,并在HealthBench上获得第一名,在科学领域的整体成绩与Gemini 3 Pro和GPT-5.2相当。
在推理和Agent能力评测中,该模型在IMO、CMO数学奥赛和ICPC编程竞赛中获得金牌成绩,也超越了Gemini 3 Pro在Putnam Bench上的表现。
在HLE-text(人类的最后考试)上,豆包2.0 Pro取得最高分54.2分,在工具调用和指令遵循测试中也有出色表现。
更重要的是,字节跳动表示,该模型在保持与业界顶尖大模型相当效果的同时,token定价降低了约一个数量级,这一成本优势在大规模推理与长链路生成场景中将变得更为关键。
基于OpenClaw框架和豆包2.0 Pro模型,字节跳动在飞书上构建了智能客服Agent。
该Agent能通过调用不同技能完成客户对话,遇到难题时会主动拉群求助真人同事,帮客户预约上门维修人员,并在维修后主动回访和推荐产品。
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 |
推荐: