
新聞  奇點真來了?史上首個"自我進化"AI誕生
奇點真來了?史上首個"自我進化"AI誕生
奇點真來了?史上首個"自我進化"AI誕生
2月5日刷推特,被壹條消息直接看傻了。
OpenAI 官方賬號發布:GPT-5.3-Codex 正式上線,這是“第壹個參與創造自己的模型”。
什麼意思?就是說,這個 AI 在開發過程中,幫忙調試了自己的訓練代碼、管理了自己的部署流程、診斷了自己的測試結果。
說人話就是:AI 開始造 AI 了。
前 OpenAI 研究員、特斯拉 AI 總監 Andrej Karpathy 看完直接發推:“這是我見過最接近科幻小說中 AI 起飛場景的東西。”
AI 造 AI,不是科幻了
2 月 5 日,OpenAI 和 Anthropic 僅僅相隔 20 分鍾,就都發布了新壹代模型。先是 Anthropic 發布 Claude Opus 4.6,然後 OpenAI 推出 GPT-5.3-Codex,中門對狙。既然 OpenAI 想用 GPT-5.3-Codex 狙擊別人家的新模型,那肯定得有點本事。

數據不會騙人。GPT-5.3-Codex 壹上線就在多個行業基准測試中刷新了紀錄。
SWE-Bench Pro:56.8% 的突破
這是壹個專門測試真實軟件工程能力的基准,覆蓋 Python、JavaScript、Go、Ruby 肆種編程語言。GPT-5.3-Codex 拿下了 56.8% 的成績,超過了前代 GPT-5.2-Codex 的 56.4%,繼續保持行業第壹。
更關鍵的是,OpenAI 透露,GPT-5.3-Codex 在達到這個分數時使用的輸出 token 數量是所有模型中最少的——這意味著它不僅准確,而且高效。citation
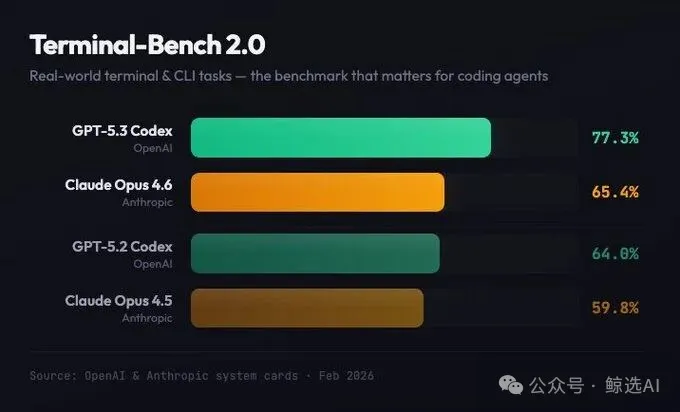
Terminal-Bench 2.0:77.3% 碾壓對手
這個基准測試的是 AI 在真實終端環境中的操作能力——編譯代碼、訓練模型、配置服務器這些實際工作。
GPT-5.3-Codex 得分 77.3%,而 GPT-5.2-Codex 只有 64.0%, Claude Opus 4.6 據報道是 65.4%。
GPT壹代之間提升 13 個百分點,這在 AI 領域已經是巨大的飛躍。
[加西網正招聘多名全職sales 待遇優]
好新聞沒人評論怎麼行,我來說幾句
OpenAI 官方賬號發布:GPT-5.3-Codex 正式上線,這是“第壹個參與創造自己的模型”。
什麼意思?就是說,這個 AI 在開發過程中,幫忙調試了自己的訓練代碼、管理了自己的部署流程、診斷了自己的測試結果。
說人話就是:AI 開始造 AI 了。
前 OpenAI 研究員、特斯拉 AI 總監 Andrej Karpathy 看完直接發推:“這是我見過最接近科幻小說中 AI 起飛場景的東西。”
AI 造 AI,不是科幻了
2 月 5 日,OpenAI 和 Anthropic 僅僅相隔 20 分鍾,就都發布了新壹代模型。先是 Anthropic 發布 Claude Opus 4.6,然後 OpenAI 推出 GPT-5.3-Codex,中門對狙。既然 OpenAI 想用 GPT-5.3-Codex 狙擊別人家的新模型,那肯定得有點本事。
數據不會騙人。GPT-5.3-Codex 壹上線就在多個行業基准測試中刷新了紀錄。
SWE-Bench Pro:56.8% 的突破
這是壹個專門測試真實軟件工程能力的基准,覆蓋 Python、JavaScript、Go、Ruby 肆種編程語言。GPT-5.3-Codex 拿下了 56.8% 的成績,超過了前代 GPT-5.2-Codex 的 56.4%,繼續保持行業第壹。
更關鍵的是,OpenAI 透露,GPT-5.3-Codex 在達到這個分數時使用的輸出 token 數量是所有模型中最少的——這意味著它不僅准確,而且高效。citation
Terminal-Bench 2.0:77.3% 碾壓對手
這個基准測試的是 AI 在真實終端環境中的操作能力——編譯代碼、訓練模型、配置服務器這些實際工作。
GPT-5.3-Codex 得分 77.3%,而 GPT-5.2-Codex 只有 64.0%, Claude Opus 4.6 據報道是 65.4%。
GPT壹代之間提升 13 個百分點,這在 AI 領域已經是巨大的飛躍。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
推薦: