
新闻  DeepSeek之后,又一中国大模型登Nature
DeepSeek之后,又一中国大模型登Nature
DeepSeek之后,又一中国大模型登Nature
1、一个大型的混合多模态训练数据集。
2、一个统一的标记器,可将图像和视频片段转换为紧凑的离散标记流(视觉分词器)。
3、一个基于Transformer的仅解码器架构,该架构扩展了大型语言模型的嵌入空间以接受视觉标记,其他方面则遵循标准的仅解码器设计选择(架构)。
4、一个两阶段优化方案,包括采用平衡交叉熵损失的大规模多模态预训练,以及与任务格式和人类偏好对齐的高质量后训练(预训练和后训练)。
5、一个高效的推理后端,支持无分类器引导(CFG)、低延迟和高吞吐量,用于自回归多模态生成(推理)。
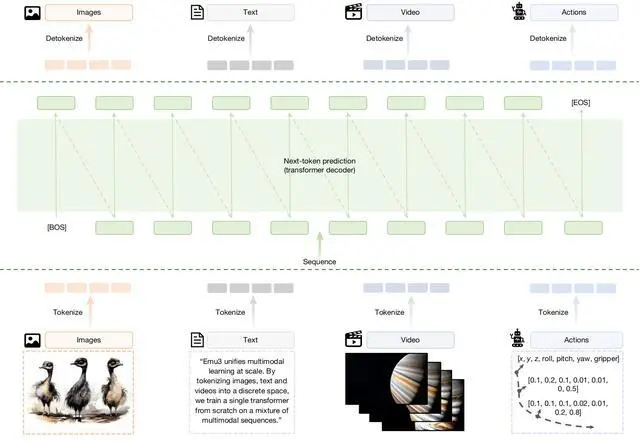
Emu3架构图
这一架构证明,仅凭“预测下一个token”,我们就能够同时支持高水平的生成能力与理解能力,并且在同一统一架构下,自然地扩展到机器人操作以及多模态交错等生成任务。智源研究团队对相关研究的多项关键技术与模型进行了开源,以推动该方向的持续研究。
同时,研究通过大规模消融实验系统分析了多项关键技术的设计选择,验证了多模态学习的规模定律(Scaling law)、统一离散化的高效性、以及解码器架构的有效性。研究还验证了自回归路线高度通用性:直接偏好优化(DPO)方法可无缝应用于自回归视觉生成任务,使模型能够更好地对齐人类偏好。
在此研究基础上,悟界・Emu3.5进一步通过大规模长时序视频训练,学习时空与因果关系,展现出随模型与数据规模增长而提升的物理世界建模能力,并观察到多模态能力随规模扩展而涌现的趋势,实现了“预测下一个状态”的范式升级。
四、坚持原始创新:北京智源引领大模型技术演进
自2018年创立之后,智源研究院通过多项成果深刻影响了中国AI学术和产业界。其在2021年发布了中国首个大语言模型“悟道1.0”,及当时全球最大的大语言模型(采用MoE架构)“悟道2.0”,同时因输送大量顶尖AI产业人才被称为“大模型的黄埔军校”。
智源2022年开辟的新的模型系列――悟界・Emu研究成果的发表,不仅是国际学术界对智源研究团队工作的认可,更是对中国AI原创技术路线的重要肯定。
Emu系列模型自2022年启动研发以来,围绕“原生多模态”这一核心技术主线持续迭代,每一个版本都在关键能力与方法论上实现了实质性突破。
2022年6月,系统布局多模态大模型的研发。
2023年7月,发布并开源首个版本,成为最早打通多模态输入到多模态输出的统一多模态模型,创新性提出统一多模态学习框架并大规模引入视频数据,初步实现多模态自回归预测。
2023年12月,发布Emu2,通过大规模自回归生成式多模态预训练,展现出可泛化的多模态上下文学习能力,可在少量示例和简单指令下完成听、说、读、写、画等任务,是当时开源最大的生成式多模态模型。
2024年10月,发布Emu3,该模型只基于预测下一个token,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。
2025年10月,推出原生多模态世界模型Emu3.5,实现从 “预测下一个token” 到 “预测下一个状态” 的能力跃迁,从长视频数据中学习世界演化规律,提出多模态 Scaling 新范式。
自2020年启动“悟道”大模型研究以来,智源持续聚焦大模型的原始创新与长期技术路径探索。2025年6月,智源发布新一代大模型系列“悟界”,旨在构建人工智能从数字世界迈向物理世界的关键能力,及物理世界的人工智能基座模型。
[物价飞涨的时候 这样省钱购物很爽]
好新闻没人评论怎么行,我来说几句
2、一个统一的标记器,可将图像和视频片段转换为紧凑的离散标记流(视觉分词器)。
3、一个基于Transformer的仅解码器架构,该架构扩展了大型语言模型的嵌入空间以接受视觉标记,其他方面则遵循标准的仅解码器设计选择(架构)。
4、一个两阶段优化方案,包括采用平衡交叉熵损失的大规模多模态预训练,以及与任务格式和人类偏好对齐的高质量后训练(预训练和后训练)。
5、一个高效的推理后端,支持无分类器引导(CFG)、低延迟和高吞吐量,用于自回归多模态生成(推理)。
Emu3架构图
这一架构证明,仅凭“预测下一个token”,我们就能够同时支持高水平的生成能力与理解能力,并且在同一统一架构下,自然地扩展到机器人操作以及多模态交错等生成任务。智源研究团队对相关研究的多项关键技术与模型进行了开源,以推动该方向的持续研究。
同时,研究通过大规模消融实验系统分析了多项关键技术的设计选择,验证了多模态学习的规模定律(Scaling law)、统一离散化的高效性、以及解码器架构的有效性。研究还验证了自回归路线高度通用性:直接偏好优化(DPO)方法可无缝应用于自回归视觉生成任务,使模型能够更好地对齐人类偏好。
在此研究基础上,悟界・Emu3.5进一步通过大规模长时序视频训练,学习时空与因果关系,展现出随模型与数据规模增长而提升的物理世界建模能力,并观察到多模态能力随规模扩展而涌现的趋势,实现了“预测下一个状态”的范式升级。
四、坚持原始创新:北京智源引领大模型技术演进
自2018年创立之后,智源研究院通过多项成果深刻影响了中国AI学术和产业界。其在2021年发布了中国首个大语言模型“悟道1.0”,及当时全球最大的大语言模型(采用MoE架构)“悟道2.0”,同时因输送大量顶尖AI产业人才被称为“大模型的黄埔军校”。
智源2022年开辟的新的模型系列――悟界・Emu研究成果的发表,不仅是国际学术界对智源研究团队工作的认可,更是对中国AI原创技术路线的重要肯定。
Emu系列模型自2022年启动研发以来,围绕“原生多模态”这一核心技术主线持续迭代,每一个版本都在关键能力与方法论上实现了实质性突破。
2022年6月,系统布局多模态大模型的研发。
2023年7月,发布并开源首个版本,成为最早打通多模态输入到多模态输出的统一多模态模型,创新性提出统一多模态学习框架并大规模引入视频数据,初步实现多模态自回归预测。
2023年12月,发布Emu2,通过大规模自回归生成式多模态预训练,展现出可泛化的多模态上下文学习能力,可在少量示例和简单指令下完成听、说、读、写、画等任务,是当时开源最大的生成式多模态模型。
2024年10月,发布Emu3,该模型只基于预测下一个token,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。
2025年10月,推出原生多模态世界模型Emu3.5,实现从 “预测下一个token” 到 “预测下一个状态” 的能力跃迁,从长视频数据中学习世界演化规律,提出多模态 Scaling 新范式。
自2020年启动“悟道”大模型研究以来,智源持续聚焦大模型的原始创新与长期技术路径探索。2025年6月,智源发布新一代大模型系列“悟界”,旨在构建人工智能从数字世界迈向物理世界的关键能力,及物理世界的人工智能基座模型。
[物价飞涨的时候 这样省钱购物很爽]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 |
推荐: