
新闻  DeepSeek之后,又一中国大模型登Nature
DeepSeek之后,又一中国大模型登Nature
DeepSeek之后,又一中国大模型登Nature
Emu3的性能与最先进的扩散模型相当
如下图所示,在文生图任务中,其效果达到扩散模型水平;在视觉语言理解方面,其可以与融合CLIP和大语言模型的主流方案比肩。
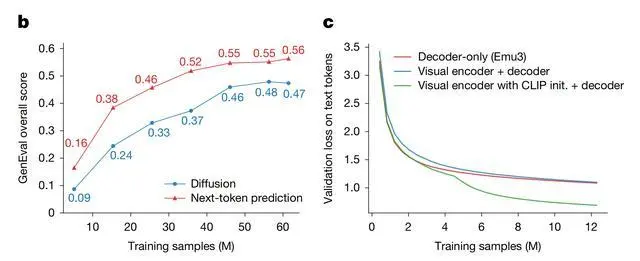
Emu3在文生图和视觉语言理解上比肩主流方案
在视觉语言理解方面,如下图所示,Emu3作为一种纯粹的无编码器方法,在多个基准测试中达到了与其同类方法相当的性能。取得这样的视觉-语言理解能力,Emu3并未依赖专门的预训练大语言模型和CLIP。
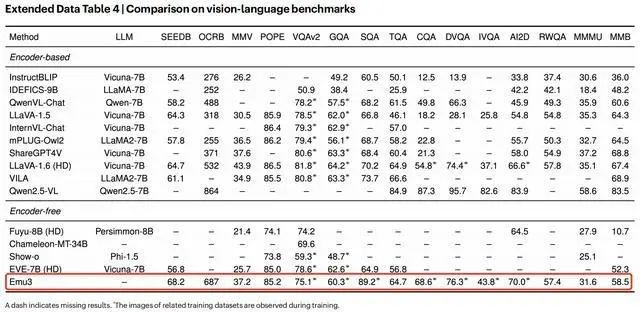
Emu3在视觉-语言理解能力方面的测评成绩
在零样本图像修复案例中,给定输入图像(每行左侧)和相应提示,Emu3能准确填充边界框内的掩码区域,生成语义对齐的内容,且无需特定任务的微调。

Emu3零样本图像修复
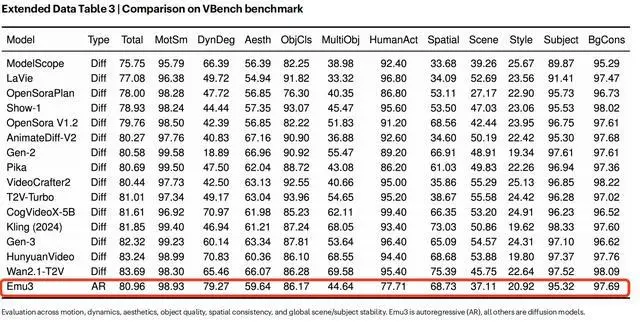
同时,Emu3还具备视频生成能力。Emu3原生支持生成24帧/秒的5秒视频,并可通过自回归方法进行扩展。如图所示,在扩展数据表3中,Emu3所产生的结果与其他视频扩散模型相比具有很强的竞争力:Emu3的性能超过Open Sora V1.2、Kling(2024)、Gen-3等当年的知名专用模型。
[加西网正招聘多名全职sales 待遇优]
还没人说话啊,我想来说几句
如下图所示,在文生图任务中,其效果达到扩散模型水平;在视觉语言理解方面,其可以与融合CLIP和大语言模型的主流方案比肩。
Emu3在文生图和视觉语言理解上比肩主流方案
在视觉语言理解方面,如下图所示,Emu3作为一种纯粹的无编码器方法,在多个基准测试中达到了与其同类方法相当的性能。取得这样的视觉-语言理解能力,Emu3并未依赖专门的预训练大语言模型和CLIP。
Emu3在视觉-语言理解能力方面的测评成绩
在零样本图像修复案例中,给定输入图像(每行左侧)和相应提示,Emu3能准确填充边界框内的掩码区域,生成语义对齐的内容,且无需特定任务的微调。
Emu3零样本图像修复
同时,Emu3还具备视频生成能力。Emu3原生支持生成24帧/秒的5秒视频,并可通过自回归方法进行扩展。如图所示,在扩展数据表3中,Emu3所产生的结果与其他视频扩散模型相比具有很强的竞争力:Emu3的性能超过Open Sora V1.2、Kling(2024)、Gen-3等当年的知名专用模型。
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 |
推荐: