
新闻  00后揪出AI幻觉元凶:仅0.1%神经元,一按就老实
00后揪出AI幻觉元凶:仅0.1%神经元,一按就老实
00后揪出AI幻觉元凶:仅0.1%神经元,一按就老实
近日,清华大学团队从 AI 里找到了与幻觉产生高度关联的少数“脑细胞”,并给它们起了一个名字 H-神经元(幻觉神经元)。他们发现拨动这些小开关能显著调节 AI 的行为倾向――例如影响它是否会盲目听从错误指令、甚至是否会产生有害回答。
这一研究让人们第一次清晰地看到幻觉是如何从机器的神经层面产生的。它可以帮助我们更好地检测 AI 什么时候在撒谎,未来也可以通过微调这些小开关,造出更加诚实、更加可靠的 AI 助手。

图 | 高骋(来源:高骋)
AI幻觉从何而来?如何找到关键幻觉因素?
对于大模型来说,我们可以把其想象成为一个由数千亿个脑细胞(在 AI 里叫神经元)连接成的超级网络。它通过阅读互联网的海量信息来学习,学习目标很简单,就是根据前面的文字,预测下一个最有可能出现的词语。比如看到“天空是什么颜色的”,它大概率会学会接“蓝色的”。
但这种学习方式埋下了一个隐患:模型只被训练生成通顺的文字,而不是正确的答案。当它遇到自己不确定或者根本没学过的知识,为了完成只说出一个通顺句子的任务,它就可能凭感觉编造出一个答案。
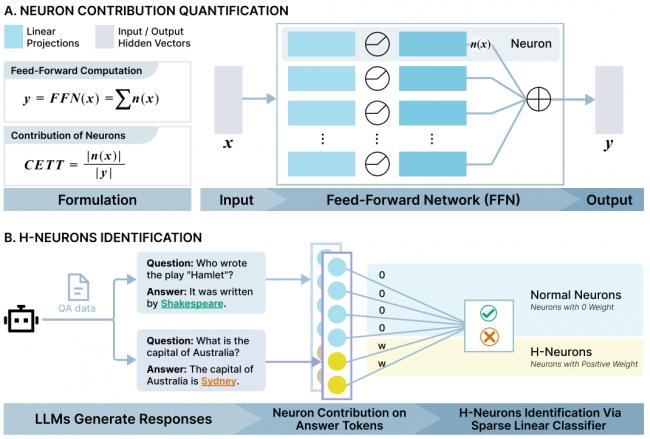
此前,人们大多从整体上研究这个问题,比如检查训练数据是否有偏差,或者让 AI 自己输出置信度。但是,这就像只知道一个人发烧,却不知道哪个器官感染了一样。本次清华团队的创新之处在于,他们决定拿起显微镜直接去观察 AI 大脑内部里的数千万甚至数亿个神经元,看看当 AI 在撒谎的时候,到底是哪些神经元在活跃。
(来源:资料图)
相关论文第一作者、清华大学硕士生高骋告诉 DeepTech:“目前工业界对减轻幻觉的关注相对有限,但学术界已做了许多努力。不过,多数研究仍停留在表层,将模型视为黑盒,通过后训练、调整数据等方式打补丁,未能从根本上理解幻觉机制。因此,我们希望借鉴神经科学的思路,从模型内部神经元入手,真正理解幻觉的产生原理,为未来彻底解决该问题提供新的视角。”
为此,高骋和所在团队准备了一套寻找方法:
首先,他们备好一批测试题和标准答案,使用了一个名为 TriviaQA 的知识问答数据集来向 AI 模型提问。对于每个问题,他们都让 AI 生成很多遍答案。如果 AI 每次都能答对,这个答案就被标记为真实;如果 AI 每次都在同一个问题上犯错,并且不是回答“我不知道”,而是坚定地给出错误答案,那么这个答案就被标记为幻觉。
当 AI 生成答案的时候,他们使用了一套名为 CETT 的测量技术,仔细记录下每个神经元的活跃度贡献值,就像测量每个脑细胞在说出那个答案时付出了多大力气一样。研究人员特别关注答案关键词比如“爱因斯坦”一词被说出来的那一刻的神经元活动。
然后,他们使用这些数据训练了一个筛选器,即一个带有稀疏约束的线性分类器。这个筛选器的任务很简单:只看神经元的活跃度程度,就能判断出 AI 刚才的回答是真实还是幻觉。结果发现:筛选器自动地把重要性权重几乎都给了极少数的神经元,而其他绝大多数神经元的权重都变成了零。
这些被选中的、权重为正的神经元就是 H-神经元。研究表明,它们只占模型总神经元数量的不到 0.1%。尽管数量稀少,但是它们就像一个明确的信号灯,意味着只要它们异常活跃,AI 就很有可能在编造事实。
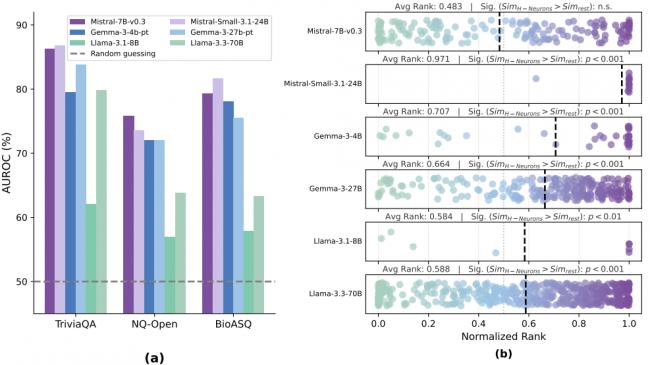
为了验证这一发现的稳健性,研究人员在不同场景下测试了 H-神经元的侦察能力,包括常规知识问答能力比如 AI 是否记错了学过的知识;包括跨领域专业问题以此来测试 AI 是否会在陌生领域瞎猜;包括完全虚构的问题以便测试 AI 是否会无中生有的编造。
在这些情况下,基于 H-神经元的检测器都有着出色表现,准确率远远高于随机挑选的神经元。这证明它们捕捉到了不是某种特定问题的特征,而是 AI 编故事的通用内在模式。
(来源:https://arxiv.org/pdf/2512.01797)
拨动开关:H-神经元如何控制 AI 行为?
只发现关联还不够,他们还想知道这些 H-神经元是元凶吗?它们除了与事实错误相关,还会管别的事情吗?
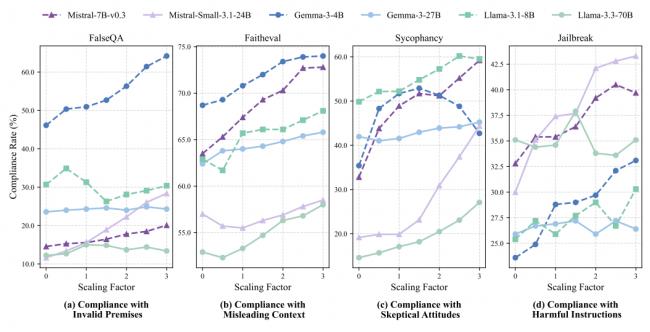
于是,他们进行了一系列的脑部刺激试验。在 AI 生成答案的过程中,像调节旋钮一样,人为地放大或者抑制这些 H-神经元的活跃度。
结果发现;调节这些神经元,就等于调节了 AI 的顺从度。
在放大 H-神经元的时候,会让 AI 变得更加听话,但是这种类型的听话是盲目的。它会更容易接受错误的前提比如认为猫是有羽毛的,以及更容易接受存在误导性的上下文,更容易在用户表示怀疑时放弃自己原本正确的答案,甚至更有可能突破安全限制区回答有害的指令。
在抑制 H-神经元的时候,AI 则会变得更加坚定和更加诚实,它更倾向于拒绝错误的前提、质疑误导信息、坚持正确的答案并遵守安全准则。
这揭示了一个核心洞见:H-神经元编码的并非简单的对错,而是一种过度顺从的倾向。AI 产生幻觉本质上是为了满足用于得到一个答案的期望,而过度顺从则牺牲了事实性。这让 AI 成了一个过于想讨好别人而不得不撒谎的孩子。这个发现把事实性幻觉和安全性漏洞等看似不同的问题,通过过度顺从这个共同根节点联系了起来。
(来源:https://arxiv.org/pdf/2512.01797)
最后一个关键问题是:这些捣蛋的神经元是什么时候形成的?是在最初阅读海量文本的预训练阶段就学会的?还是在后续的指令微调也就是教导 AI 听从人类指令的阶段被引入的?
研究人员比较了只经过预训练的基础模型和经过后续调教的指令微调模型,借此发现:
首先,H-神经元在基础模型中就已经存在。使用指令微调模型中的 H-神经元去检测基础模型,依然可以有效预测幻觉,这说明编故事的神经基础在早期学习就买下来种子。
其次,指令微调几乎不会改变 H-神经元。对比基础模型和微调后的模型,H-神经元本身的参数变化非常小,远低于网络中其他神经元的平均变化程度。这意味着后续的调教并没有修复或者显著改变这些固有回路,只是继承了它们。
结论很清楚:幻觉的种子早在预训练阶段就已种下。因为预训练的目标即预测下一个词只奖励流畅,不惩罚虚构。为了变得流畅,AI 不得不学会在空白知识处进行猜测,久而久之就形成了固定的编故事的神经回路。后续的指令微调,虽然让 AI 变得更加乐于助人,但却无意中强化了这种为了满足用户而顺从甚至编造的倾向。
“因此,这项研究的应用前景主要体现在两方面:首先,由于神经元是模型中具体存在的单元,对其进行干预(激活或抑制)操作简便,无需重新训练模型,这为缓解幻觉提供了新方法;其次,它启发我们重新思考预训练目标的设计,引入对事实性、不确定性建模的机制,从而在源头缓解幻觉。”高骋表示。
[加西网正招聘多名全职sales 待遇优]
已经有 3 人参与评论了, 我也来说几句吧
这一研究让人们第一次清晰地看到幻觉是如何从机器的神经层面产生的。它可以帮助我们更好地检测 AI 什么时候在撒谎,未来也可以通过微调这些小开关,造出更加诚实、更加可靠的 AI 助手。
图 | 高骋(来源:高骋)
AI幻觉从何而来?如何找到关键幻觉因素?
对于大模型来说,我们可以把其想象成为一个由数千亿个脑细胞(在 AI 里叫神经元)连接成的超级网络。它通过阅读互联网的海量信息来学习,学习目标很简单,就是根据前面的文字,预测下一个最有可能出现的词语。比如看到“天空是什么颜色的”,它大概率会学会接“蓝色的”。
但这种学习方式埋下了一个隐患:模型只被训练生成通顺的文字,而不是正确的答案。当它遇到自己不确定或者根本没学过的知识,为了完成只说出一个通顺句子的任务,它就可能凭感觉编造出一个答案。
此前,人们大多从整体上研究这个问题,比如检查训练数据是否有偏差,或者让 AI 自己输出置信度。但是,这就像只知道一个人发烧,却不知道哪个器官感染了一样。本次清华团队的创新之处在于,他们决定拿起显微镜直接去观察 AI 大脑内部里的数千万甚至数亿个神经元,看看当 AI 在撒谎的时候,到底是哪些神经元在活跃。
(来源:资料图)
相关论文第一作者、清华大学硕士生高骋告诉 DeepTech:“目前工业界对减轻幻觉的关注相对有限,但学术界已做了许多努力。不过,多数研究仍停留在表层,将模型视为黑盒,通过后训练、调整数据等方式打补丁,未能从根本上理解幻觉机制。因此,我们希望借鉴神经科学的思路,从模型内部神经元入手,真正理解幻觉的产生原理,为未来彻底解决该问题提供新的视角。”
为此,高骋和所在团队准备了一套寻找方法:
首先,他们备好一批测试题和标准答案,使用了一个名为 TriviaQA 的知识问答数据集来向 AI 模型提问。对于每个问题,他们都让 AI 生成很多遍答案。如果 AI 每次都能答对,这个答案就被标记为真实;如果 AI 每次都在同一个问题上犯错,并且不是回答“我不知道”,而是坚定地给出错误答案,那么这个答案就被标记为幻觉。
当 AI 生成答案的时候,他们使用了一套名为 CETT 的测量技术,仔细记录下每个神经元的活跃度贡献值,就像测量每个脑细胞在说出那个答案时付出了多大力气一样。研究人员特别关注答案关键词比如“爱因斯坦”一词被说出来的那一刻的神经元活动。
然后,他们使用这些数据训练了一个筛选器,即一个带有稀疏约束的线性分类器。这个筛选器的任务很简单:只看神经元的活跃度程度,就能判断出 AI 刚才的回答是真实还是幻觉。结果发现:筛选器自动地把重要性权重几乎都给了极少数的神经元,而其他绝大多数神经元的权重都变成了零。
这些被选中的、权重为正的神经元就是 H-神经元。研究表明,它们只占模型总神经元数量的不到 0.1%。尽管数量稀少,但是它们就像一个明确的信号灯,意味着只要它们异常活跃,AI 就很有可能在编造事实。
为了验证这一发现的稳健性,研究人员在不同场景下测试了 H-神经元的侦察能力,包括常规知识问答能力比如 AI 是否记错了学过的知识;包括跨领域专业问题以此来测试 AI 是否会在陌生领域瞎猜;包括完全虚构的问题以便测试 AI 是否会无中生有的编造。
在这些情况下,基于 H-神经元的检测器都有着出色表现,准确率远远高于随机挑选的神经元。这证明它们捕捉到了不是某种特定问题的特征,而是 AI 编故事的通用内在模式。
(来源:https://arxiv.org/pdf/2512.01797)
拨动开关:H-神经元如何控制 AI 行为?
只发现关联还不够,他们还想知道这些 H-神经元是元凶吗?它们除了与事实错误相关,还会管别的事情吗?
于是,他们进行了一系列的脑部刺激试验。在 AI 生成答案的过程中,像调节旋钮一样,人为地放大或者抑制这些 H-神经元的活跃度。
结果发现;调节这些神经元,就等于调节了 AI 的顺从度。
在放大 H-神经元的时候,会让 AI 变得更加听话,但是这种类型的听话是盲目的。它会更容易接受错误的前提比如认为猫是有羽毛的,以及更容易接受存在误导性的上下文,更容易在用户表示怀疑时放弃自己原本正确的答案,甚至更有可能突破安全限制区回答有害的指令。
在抑制 H-神经元的时候,AI 则会变得更加坚定和更加诚实,它更倾向于拒绝错误的前提、质疑误导信息、坚持正确的答案并遵守安全准则。
这揭示了一个核心洞见:H-神经元编码的并非简单的对错,而是一种过度顺从的倾向。AI 产生幻觉本质上是为了满足用于得到一个答案的期望,而过度顺从则牺牲了事实性。这让 AI 成了一个过于想讨好别人而不得不撒谎的孩子。这个发现把事实性幻觉和安全性漏洞等看似不同的问题,通过过度顺从这个共同根节点联系了起来。
(来源:https://arxiv.org/pdf/2512.01797)
最后一个关键问题是:这些捣蛋的神经元是什么时候形成的?是在最初阅读海量文本的预训练阶段就学会的?还是在后续的指令微调也就是教导 AI 听从人类指令的阶段被引入的?
研究人员比较了只经过预训练的基础模型和经过后续调教的指令微调模型,借此发现:
首先,H-神经元在基础模型中就已经存在。使用指令微调模型中的 H-神经元去检测基础模型,依然可以有效预测幻觉,这说明编故事的神经基础在早期学习就买下来种子。
其次,指令微调几乎不会改变 H-神经元。对比基础模型和微调后的模型,H-神经元本身的参数变化非常小,远低于网络中其他神经元的平均变化程度。这意味着后续的调教并没有修复或者显著改变这些固有回路,只是继承了它们。
结论很清楚:幻觉的种子早在预训练阶段就已种下。因为预训练的目标即预测下一个词只奖励流畅,不惩罚虚构。为了变得流畅,AI 不得不学会在空白知识处进行猜测,久而久之就形成了固定的编故事的神经回路。后续的指令微调,虽然让 AI 变得更加乐于助人,但却无意中强化了这种为了满足用户而顺从甚至编造的倾向。
“因此,这项研究的应用前景主要体现在两方面:首先,由于神经元是模型中具体存在的单元,对其进行干预(激活或抑制)操作简便,无需重新训练模型,这为缓解幻觉提供了新方法;其次,它启发我们重新思考预训练目标的设计,引入对事实性、不确定性建模的机制,从而在源头缓解幻觉。”高骋表示。
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: |
推荐: