
新闻  华尔街彻夜难眠,Gemini 3屠榜金融"最难考试"
华尔街彻夜难眠,Gemini 3屠榜金融"最难考试"
华尔街彻夜难眠,Gemini 3屠榜金融"最难考试"
三级考试论述题示例:探讨资产配置理论,比较两种资本资产定价模型(CAPM)的应用前提与估计精度,论证其适用差异。
结果显示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依据既定标准通过了所有级别考核,部分成绩甚至接近满分。
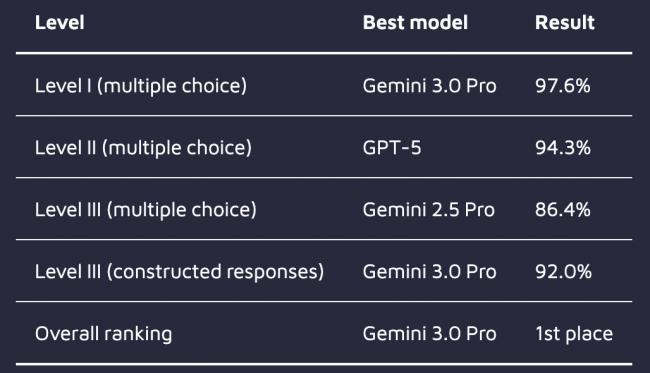
Gemini与GPT-5双雄领跑
在一级考试(基础多选题)中,Gemini 3.0 Pro以97.6%的惊人准确率创下历史新高。GPT-5紧随其后,斩获96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是测试中表现“垫底”的DeepSeek-V3.1,准确率也高达90.9%。
来到侧重应用与分析(案例研究)的二级考试,GPT-5反超夺魁,准确率达94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分别以93.2%和92.6%紧随其后。
研究人员惊叹道,这些模型在此阶段的表现“近乎完美”。不过,“道德规范”(Ethics)板块依然是AI的软肋。数据显示,即便最强模型,在二级考试的道德类题目中也有17%到21%的相对错误率。
到了最复杂的三级考试(包含选择题与开放式问答),Gemini 2.5 Pro在选择题部分拔得头筹,准确率为86.4%。但在更考验生成能力的“论述题”环节,Gemini 3.0 Pro展现了统治力,得分率高达92.0%,相比前代模型的82.8%有了质的飞跃。
为了对开放式问答环节进行评分,研究团队使用了o4-mini模型来实现自动化批改。
研究人员坦言,这种做法可能会引入测量误差,并产生某种“篇幅偏见”(verbosity bias),即回答越长,得分往往越高。因此,这些测试结果只能视为基于模型的估算值。
通过标准沿用了过往合格标准:
一级考试要求单科不低于 60%,总分不低于 70%;
二级考试要求单科不低于 50%,总分不低于 60%;
三级考试则要求在选择题和论述题两部分中,平均得分率至少达到 63%。
研究人员指出,测试结果表明“推理模型的专业能力已超越初级至中级金融分析师的要求,未来甚至可能达到资深分析师的水准”。
如果说此前的大语言模型已经掌握了一级和二级考试中那些“既定的规范化知识”(codified knowledge),那么最新一代模型正在习得三级考试所必需的复杂“综合研判能力”(synthesis skills)。
当然,惯常的局限性依然存在。基准测试,尤其是选择题形式,只能作为评估模型能力和潜在经济价值的参考,犹如管中窥豹。
尽管如此,短短两年间从“不及格”到“近乎满分”的巨大飞跃,足以凸显 AI 在专业领域的进化速度之快。
[加西网正招聘多名全职sales 待遇优]
这条新闻还没有人评论喔,等着您的高见呢
结果显示:Gemini 3.0 Pro、Gemini 2.5 Pro、GPT-5、Grok 4、Claude Opus 4.1和DeepSeek-V3.1均依据既定标准通过了所有级别考核,部分成绩甚至接近满分。
Gemini与GPT-5双雄领跑
在一级考试(基础多选题)中,Gemini 3.0 Pro以97.6%的惊人准确率创下历史新高。GPT-5紧随其后,斩获96.1%,Gemini 2.5 Pro也拿到了95.7%的高分。即便是测试中表现“垫底”的DeepSeek-V3.1,准确率也高达90.9%。
来到侧重应用与分析(案例研究)的二级考试,GPT-5反超夺魁,准确率达94.3%。Gemini 3.0 Pro和Gemini 2.5 Pro分别以93.2%和92.6%紧随其后。
研究人员惊叹道,这些模型在此阶段的表现“近乎完美”。不过,“道德规范”(Ethics)板块依然是AI的软肋。数据显示,即便最强模型,在二级考试的道德类题目中也有17%到21%的相对错误率。
到了最复杂的三级考试(包含选择题与开放式问答),Gemini 2.5 Pro在选择题部分拔得头筹,准确率为86.4%。但在更考验生成能力的“论述题”环节,Gemini 3.0 Pro展现了统治力,得分率高达92.0%,相比前代模型的82.8%有了质的飞跃。
为了对开放式问答环节进行评分,研究团队使用了o4-mini模型来实现自动化批改。
研究人员坦言,这种做法可能会引入测量误差,并产生某种“篇幅偏见”(verbosity bias),即回答越长,得分往往越高。因此,这些测试结果只能视为基于模型的估算值。
通过标准沿用了过往合格标准:
一级考试要求单科不低于 60%,总分不低于 70%;
二级考试要求单科不低于 50%,总分不低于 60%;
三级考试则要求在选择题和论述题两部分中,平均得分率至少达到 63%。
研究人员指出,测试结果表明“推理模型的专业能力已超越初级至中级金融分析师的要求,未来甚至可能达到资深分析师的水准”。
如果说此前的大语言模型已经掌握了一级和二级考试中那些“既定的规范化知识”(codified knowledge),那么最新一代模型正在习得三级考试所必需的复杂“综合研判能力”(synthesis skills)。
当然,惯常的局限性依然存在。基准测试,尤其是选择题形式,只能作为评估模型能力和潜在经济价值的参考,犹如管中窥豹。
尽管如此,短短两年间从“不及格”到“近乎满分”的巨大飞跃,足以凸显 AI 在专业领域的进化速度之快。
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 |
推荐: