
[谷歌] 谷歌憋了十年的大招,让英伟达好日子到头了?
于是,电费大半没花在算数上,全花在送快递的路费上了。最后变成热量,还得拜托风扇吹一吹。
这在做图形渲染时没毛病,因为画面高度随机,要啥素材没法预料,只能回显存现取。
但 AI 的矩阵运算,每个数怎么算,和谁算,算几次都是固定的。我明知道这个数算完了,一会儿还要接着用,GPU 硬是得把它存回去,等着别人再取进计算单元,这不纯纯浪费吗?

所以,作为一个 AI 专属工具人,TPU 就这样出生了。它把 GPU 那些用不上的图形、控制流、调度模块等等拆的拆,压的压。
核心思路,是专门对 AI 最常用的矩阵乘法做优化,搞了一个叫 “ 脉动阵列 ” 的方法。
用上这一招,每个数据一旦开算,就会在密集排列的计算单元之间传递,没用完不许回存储单元。这样,就不需要频繁读写了。
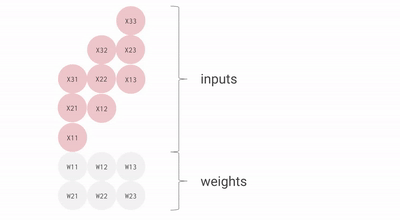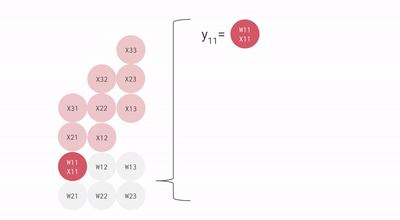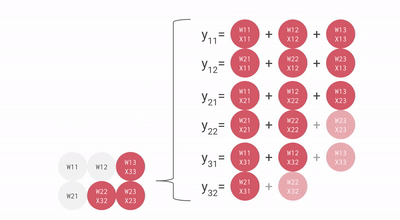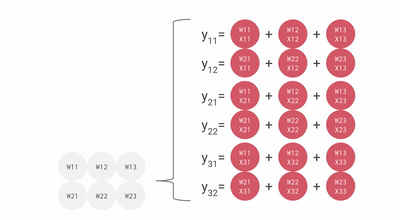
就这样,TPU 每个周期的计算操作次数达到了数十万量级,是 GPU 的近十倍。初代 TPU v1 能效比达到同时期 NVIDIA Tesla K80 的 30 倍,性价比极高。
当然,最开始谷歌也是边缘试探,没玩那么大。TPU 也还只搞推理,不会训练,功能单一,完全没法和 GPU 比。
从第二代起,谷歌才开始往内存上堆料,提升容量和数据传输速度,让 TPU 能一边计算,一边快速记录和修改海量的中间数据(比如梯度和权重),自此点亮了训练的技能树。
随着 TPUv3 规模增加,模型训练速度提升

但这么多年以来,明明用 TPU 训练推理的成本更低,性能也和 GPU 不相上下,为啥巨头们还非得去抢英伟达的芯片呢?
[加西网正招聘多名全职sales 待遇优]
好新闻没人评论怎么行,我来说几句
这在做图形渲染时没毛病,因为画面高度随机,要啥素材没法预料,只能回显存现取。
但 AI 的矩阵运算,每个数怎么算,和谁算,算几次都是固定的。我明知道这个数算完了,一会儿还要接着用,GPU 硬是得把它存回去,等着别人再取进计算单元,这不纯纯浪费吗?
所以,作为一个 AI 专属工具人,TPU 就这样出生了。它把 GPU 那些用不上的图形、控制流、调度模块等等拆的拆,压的压。
核心思路,是专门对 AI 最常用的矩阵乘法做优化,搞了一个叫 “ 脉动阵列 ” 的方法。
用上这一招,每个数据一旦开算,就会在密集排列的计算单元之间传递,没用完不许回存储单元。这样,就不需要频繁读写了。
就这样,TPU 每个周期的计算操作次数达到了数十万量级,是 GPU 的近十倍。初代 TPU v1 能效比达到同时期 NVIDIA Tesla K80 的 30 倍,性价比极高。
当然,最开始谷歌也是边缘试探,没玩那么大。TPU 也还只搞推理,不会训练,功能单一,完全没法和 GPU 比。
从第二代起,谷歌才开始往内存上堆料,提升容量和数据传输速度,让 TPU 能一边计算,一边快速记录和修改海量的中间数据(比如梯度和权重),自此点亮了训练的技能树。
随着 TPUv3 规模增加,模型训练速度提升
但这么多年以来,明明用 TPU 训练推理的成本更低,性能也和 GPU 不相上下,为啥巨头们还非得去抢英伟达的芯片呢?
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: | 在此页阅读全文 |
| 延伸阅读 | 更多... |
推荐: