
新闻  DeepSeek上新,"奥数金牌水平"....
DeepSeek上新,"奥数金牌水平"....
DeepSeek上新,"奥数金牌水平"....
2025.11.28

11月27日晚,DeepSeek悄悄地在Hugging Face 上开源了一个新模型:DeepSeek-Math-V2。这是一个数学方面的模型,也是目前行业首个达到IMO(国际奥林匹克数学竞赛)金牌水平且开源的模型。
在同步发布的技术论文中,DeepSeek表示,Math-V2的部分性能优于谷歌旗下的Gemini DeepThink,并展示了模型在IMO-ProofBench基准以及近期数学竞赛上的表现。
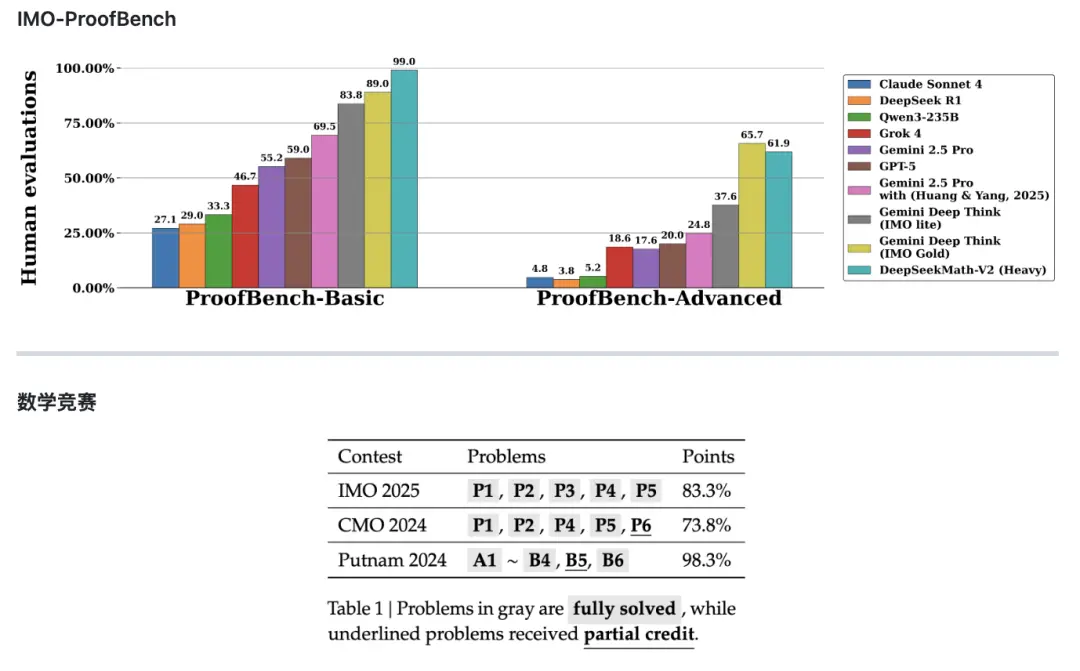
具体来看,在其中的Basic基准上,DeepSeek-Math-V2 远胜其他模型,达到了近99%的高分,而排在第二的谷歌旗下Gemini Deep Think (IMO Gold)分数为89%。但在更难的 Advanced 子集上,Math-V2分数为61.9%,略逊于 Gemini Deep Think (IMO Gold)的65.7%。
在这篇名为《DeepSeek Math-V2:迈向可自验证的数学推理》的论文中,DeepSeek指出,大语言模型已经在数学推理方面取得了重大进展,这是人工智能的重要试验台,如果进一步推进,可能会对科学研究产生影响。

但当前的AI在数学推理方面有着研究局限:以正确的最终答案作为奖励,正确的答案却不能保证正确的推理。许多数学任务,如定理证明,需要严格的分步推导,而不是数字答案,这使得最终答案奖励不适用。
为了突破深度推理的极限,DeepSeek认为有必要验证数学推理的全面性和严谨性。团队提出,自我验证对于扩展测试时间计算尤为重要,特别是对于那些没有已知解决方案的开放问题。
此次DeepSeek推出的Math-V2就从结果导向转向了过程导向,展示了强大的定理证明能力。这一模型不依赖大量的数学题答案数据,而是通过教会AI如何像数学家一样严谨地审查证明过程,从而在没有人类干预的情况下,也能不断提升解决高难度数学证明题的能力 。
[加西网正招聘多名全职sales 待遇优]
这条新闻还没有人评论喔,等着您的高见呢
11月27日晚,DeepSeek悄悄地在Hugging Face 上开源了一个新模型:DeepSeek-Math-V2。这是一个数学方面的模型,也是目前行业首个达到IMO(国际奥林匹克数学竞赛)金牌水平且开源的模型。
在同步发布的技术论文中,DeepSeek表示,Math-V2的部分性能优于谷歌旗下的Gemini DeepThink,并展示了模型在IMO-ProofBench基准以及近期数学竞赛上的表现。
具体来看,在其中的Basic基准上,DeepSeek-Math-V2 远胜其他模型,达到了近99%的高分,而排在第二的谷歌旗下Gemini Deep Think (IMO Gold)分数为89%。但在更难的 Advanced 子集上,Math-V2分数为61.9%,略逊于 Gemini Deep Think (IMO Gold)的65.7%。
在这篇名为《DeepSeek Math-V2:迈向可自验证的数学推理》的论文中,DeepSeek指出,大语言模型已经在数学推理方面取得了重大进展,这是人工智能的重要试验台,如果进一步推进,可能会对科学研究产生影响。
但当前的AI在数学推理方面有着研究局限:以正确的最终答案作为奖励,正确的答案却不能保证正确的推理。许多数学任务,如定理证明,需要严格的分步推导,而不是数字答案,这使得最终答案奖励不适用。
为了突破深度推理的极限,DeepSeek认为有必要验证数学推理的全面性和严谨性。团队提出,自我验证对于扩展测试时间计算尤为重要,特别是对于那些没有已知解决方案的开放问题。
此次DeepSeek推出的Math-V2就从结果导向转向了过程导向,展示了强大的定理证明能力。这一模型不依赖大量的数学题答案数据,而是通过教会AI如何像数学家一样严谨地审查证明过程,从而在没有人类干预的情况下,也能不断提升解决高难度数学证明题的能力 。
[加西网正招聘多名全职sales 待遇优]
| 分享: |
| 注: | 在此页阅读全文 |
推荐: