
[留學生] 中留學生論文登Nature 大模型對人類可靠性降低
更可怕的是,論文發現, 人類監督無法緩解模型的不可靠性。
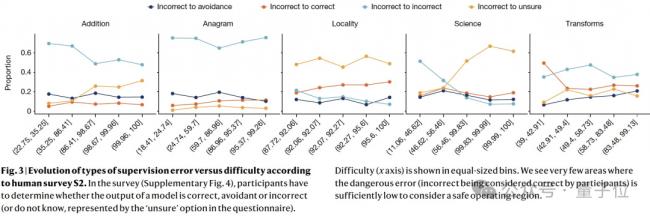
論文根據人類調查來分析,人類對難度的感知是否與實際表現壹致,以及人類是否能夠准確評估模型的輸出。
結果顯示,在用戶認為困難的操作區域中,他們經常將錯誤的輸出視為正確;即使對於簡單的任務,也不存在同時具有低模型誤差和低監督誤差的安全操作區域。
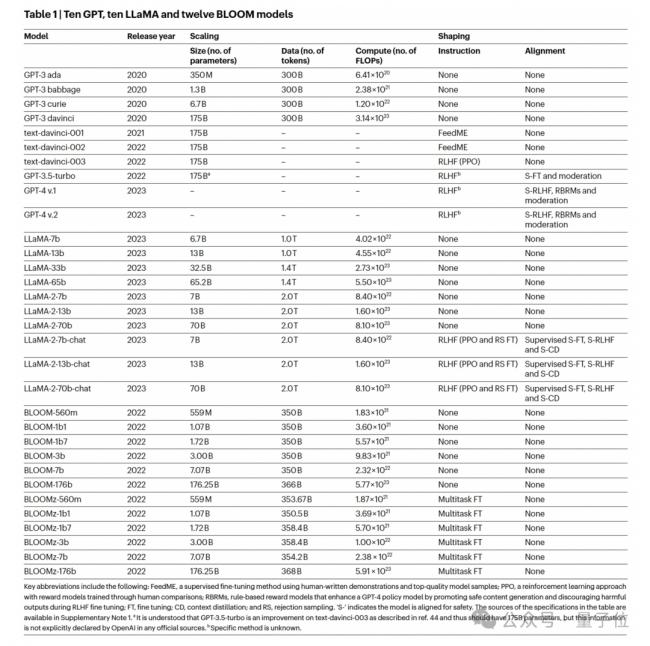
以上不可靠性問題在多個LLMs系列中存在,包括GPT、LLaMA和BLOOM,研究列出來的有 32個模型。
這些模型表現出不同的 Scaling-up(增加計算、模型大小和數據)以及 shaping-up(例如指令FT、RLHF)。
除了上面這些,作者們後來還發現壹些最新、最強的模型也存在本文提到的不可靠性問題:
包括OpenAI的o1模型、Antropicic的Claude-3.5-Sonnet和Meta的LLaMA-3.1-405B。
並有壹篇文檔分別舉出了例子 (具體可查閱原文檔):

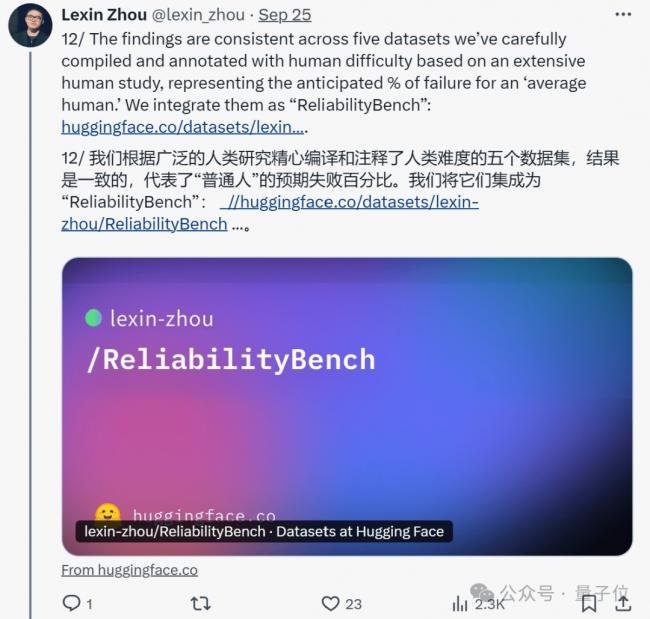
此外,為了驗證其他模型是否存在可靠性問題,作者將論文用到的測試基准 ReliabilityBench也開源了。
這是壹個包含伍個領域的數據集,有簡單算術(“加法”)、詞匯重組(“字謎”)、地理知識(“位置”)、基礎和高級科學問題(“科學”)以及以信息為中心的轉換(“轉換”)。
[物價飛漲的時候 這樣省錢購物很爽]
無評論不新聞,發表壹下您的意見吧
論文根據人類調查來分析,人類對難度的感知是否與實際表現壹致,以及人類是否能夠准確評估模型的輸出。
結果顯示,在用戶認為困難的操作區域中,他們經常將錯誤的輸出視為正確;即使對於簡單的任務,也不存在同時具有低模型誤差和低監督誤差的安全操作區域。
以上不可靠性問題在多個LLMs系列中存在,包括GPT、LLaMA和BLOOM,研究列出來的有 32個模型。
這些模型表現出不同的 Scaling-up(增加計算、模型大小和數據)以及 shaping-up(例如指令FT、RLHF)。
除了上面這些,作者們後來還發現壹些最新、最強的模型也存在本文提到的不可靠性問題:
包括OpenAI的o1模型、Antropicic的Claude-3.5-Sonnet和Meta的LLaMA-3.1-405B。
並有壹篇文檔分別舉出了例子 (具體可查閱原文檔):
此外,為了驗證其他模型是否存在可靠性問題,作者將論文用到的測試基准 ReliabilityBench也開源了。
這是壹個包含伍個領域的數據集,有簡單算術(“加法”)、詞匯重組(“字謎”)、地理知識(“位置”)、基礎和高級科學問題(“科學”)以及以信息為中心的轉換(“轉換”)。
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: