
[留學生] 中留學生論文登Nature 大模型對人類可靠性降低
相比較早的LLMs, 最新的LLMs大幅度地提高了許多錯誤或壹本正經的胡說八道的答案,而不是謹慎地避開超出它們能力范圍之外的任務。
這也導致壹個諷刺的現象:在壹些benchmarks中,新的LLMs錯誤率提升速度甚至遠超於准確率的提升(doge)。
相比較早的LLMs, 最新的LLMs大幅度地提高了許多錯誤或壹本正經的胡說八道的答案,而不是謹慎地避開超出它們能力范圍之外的任務。
這也導致壹個諷刺的現象:在壹些benchmarks中,新的LLMs錯誤率提升速度甚至遠超於准確率的提升(doge)。
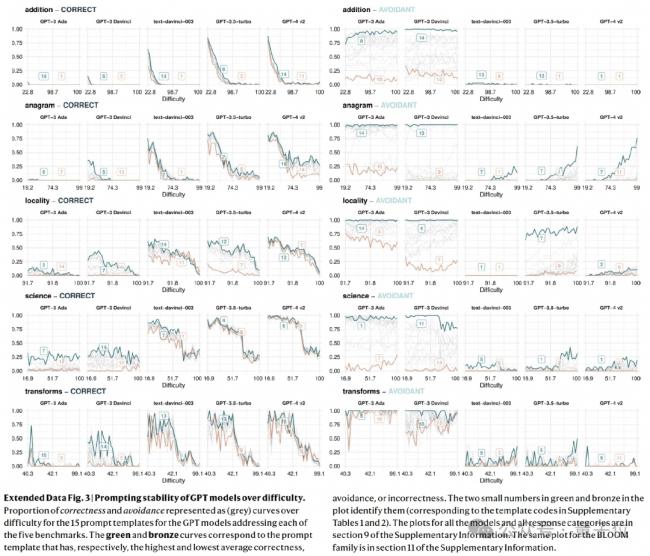
壹般來說,人類面對越難的任務,越有可能含糊其辭。
但LLMs的實際表現卻截然不同,研究顯示, 它們的規避行為與困難度並無明顯關聯。
這容易導致用戶最初過度依賴LLMs來完成他們不擅長的任務,但讓他們從長遠來看感到失望。
後果就是,人類還需要驗證模型輸出的准確性,以及發現錯誤。 (想用LLMs偷懶大打折扣)

最後論文發現,即使壹些可靠性指標有所改善,模型仍然對同壹問題的微小表述變化敏感。
舉個栗子,問“你能回答……嗎?”而不是“請回答以下問題……”會導致不同程度的准確性。
分析發現:僅僅依靠現存的scaling-up和shaping-up不太可能完全解決指示敏感度的問題,因為最新模型和它們的前身相比優化並不顯著。
而且即使選擇平均表現上最佳的表述格式,其也可能主要對高難度任務有效,但同時對低難度任務無效 (錯誤率更高)。
這表明, 人類仍然受制於提示工程。
[加西網正招聘多名全職sales 待遇優]
還沒人說話啊,我想來說幾句
這也導致壹個諷刺的現象:在壹些benchmarks中,新的LLMs錯誤率提升速度甚至遠超於准確率的提升(doge)。
相比較早的LLMs, 最新的LLMs大幅度地提高了許多錯誤或壹本正經的胡說八道的答案,而不是謹慎地避開超出它們能力范圍之外的任務。
這也導致壹個諷刺的現象:在壹些benchmarks中,新的LLMs錯誤率提升速度甚至遠超於准確率的提升(doge)。
壹般來說,人類面對越難的任務,越有可能含糊其辭。
但LLMs的實際表現卻截然不同,研究顯示, 它們的規避行為與困難度並無明顯關聯。
這容易導致用戶最初過度依賴LLMs來完成他們不擅長的任務,但讓他們從長遠來看感到失望。
後果就是,人類還需要驗證模型輸出的准確性,以及發現錯誤。 (想用LLMs偷懶大打折扣)
最後論文發現,即使壹些可靠性指標有所改善,模型仍然對同壹問題的微小表述變化敏感。
舉個栗子,問“你能回答……嗎?”而不是“請回答以下問題……”會導致不同程度的准確性。
分析發現:僅僅依靠現存的scaling-up和shaping-up不太可能完全解決指示敏感度的問題,因為最新模型和它們的前身相比優化並不顯著。
而且即使選擇平均表現上最佳的表述格式,其也可能主要對高難度任務有效,但同時對低難度任務無效 (錯誤率更高)。
這表明, 人類仍然受制於提示工程。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: