
[留學生] 中留學生論文登Nature 大模型對人類可靠性降低
還有人認為,這項研究凸顯了人工智能所面臨的微妙挑戰 (平衡模型擴展與可靠性)。
更大的模型更不可靠,依靠人類反饋也不管用了
為了說明結論,論文研究了從人類角度影響LLMs可靠性的叁個關鍵方面:
1、 難度不壹致:LLMs是否在人類預期它們會失敗的地方失敗?
2、 任務回避:LLMs是否避免回答超出其能力范圍的問題?
3、 對提示語表述的敏感性:問題表述的有效性是否受到問題難度的影響?
更重要的是,作者也分析了歷史趨勢以及這叁個方面如何隨著任務難度而演變。
下面壹壹展開。
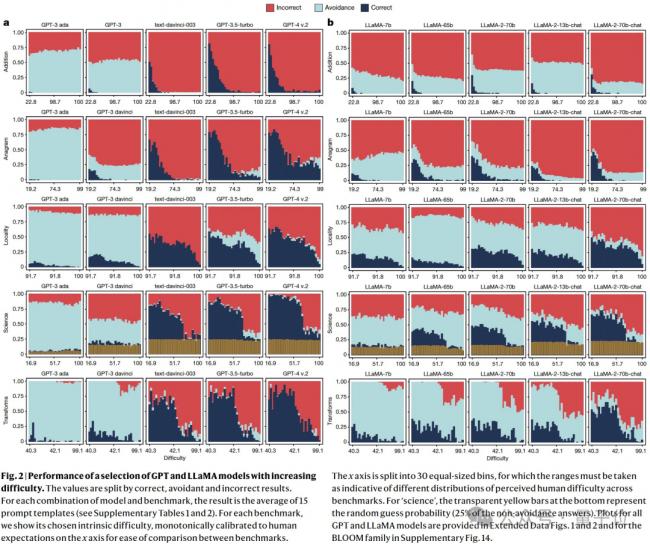
對於第1個問題,論文主要關注 正確性相對於難度的演變。
從GPT和LLaMA的演進來看,隨著難度的增加,所有模型的正確性都會明顯下降。 (與人類預期壹致)
然而,這些模型仍然無法解決許多非常簡單的任務。
這意味著,人類用戶無法發現LLMs的安全操作空間,利用其確保模型的部署表現可以完美無瑕。
令人驚訝的是,新的LLMs主要提高了高難度任務上的性能,而對於更簡單任務沒有明顯的改進。比如, GPT-4與前身GPT-3.5-turbo相比。
以上證明了人類難度預期與模型表現存在不壹致的現象, 並且此不壹致性在新的模型上加劇了。

這也意味著:
目前沒有讓人類確定LLMs可以信任的安全操作條件。
其次,關於第2點論文發現 (回避通常指模型偏離問題回答,或者直接挑明“我不知道”):
[物價飛漲的時候 這樣省錢購物很爽]
還沒人說話啊,我想來說幾句
更大的模型更不可靠,依靠人類反饋也不管用了
為了說明結論,論文研究了從人類角度影響LLMs可靠性的叁個關鍵方面:
1、 難度不壹致:LLMs是否在人類預期它們會失敗的地方失敗?
2、 任務回避:LLMs是否避免回答超出其能力范圍的問題?
3、 對提示語表述的敏感性:問題表述的有效性是否受到問題難度的影響?
更重要的是,作者也分析了歷史趨勢以及這叁個方面如何隨著任務難度而演變。
下面壹壹展開。
對於第1個問題,論文主要關注 正確性相對於難度的演變。
從GPT和LLaMA的演進來看,隨著難度的增加,所有模型的正確性都會明顯下降。 (與人類預期壹致)
然而,這些模型仍然無法解決許多非常簡單的任務。
這意味著,人類用戶無法發現LLMs的安全操作空間,利用其確保模型的部署表現可以完美無瑕。
令人驚訝的是,新的LLMs主要提高了高難度任務上的性能,而對於更簡單任務沒有明顯的改進。比如, GPT-4與前身GPT-3.5-turbo相比。
以上證明了人類難度預期與模型表現存在不壹致的現象, 並且此不壹致性在新的模型上加劇了。
這也意味著:
目前沒有讓人類確定LLMs可以信任的安全操作條件。
其次,關於第2點論文發現 (回避通常指模型偏離問題回答,或者直接挑明“我不知道”):
[物價飛漲的時候 這樣省錢購物很爽]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: