
[留學生] 中留學生論文登Nature 大模型對人類可靠性降低
00後國人壹作登上Nature,這篇大模型論文引起熱議。
簡單來說,論文發現:更大且更遵循指令的大模型也變得更不可靠了,某些情況下 GPT-4在回答可靠性上還不如GPT-3。
與早期模型相比,有更多算力和人類反饋加持的最新模型,在回答可靠性上實際愈加惡化了。
結論壹出,立即引來20多萬網友圍觀。
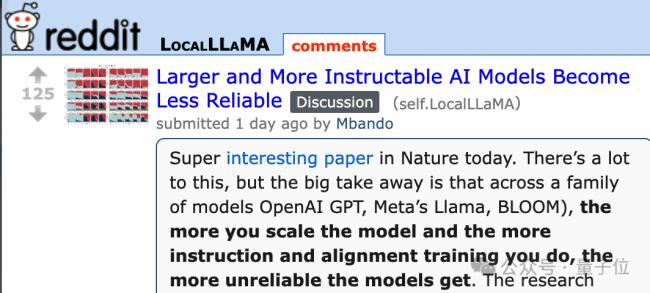
在Reddit論壇也引發圍觀議論。
這讓人不禁想起,壹大堆專家/博士級別的模型還不會“9.9和9.11”哪個大這樣的簡單問題。
關於這個現象,論文提到這也反映出, 模型的表現與人類對難度的預期不符。
換句話說,“LLMs在用戶預料不到的地方既成功又(更危險地)失敗”。
Ilya Sutskever2022年曾預測:
也許隨著時間的推移,這種差異會減少。
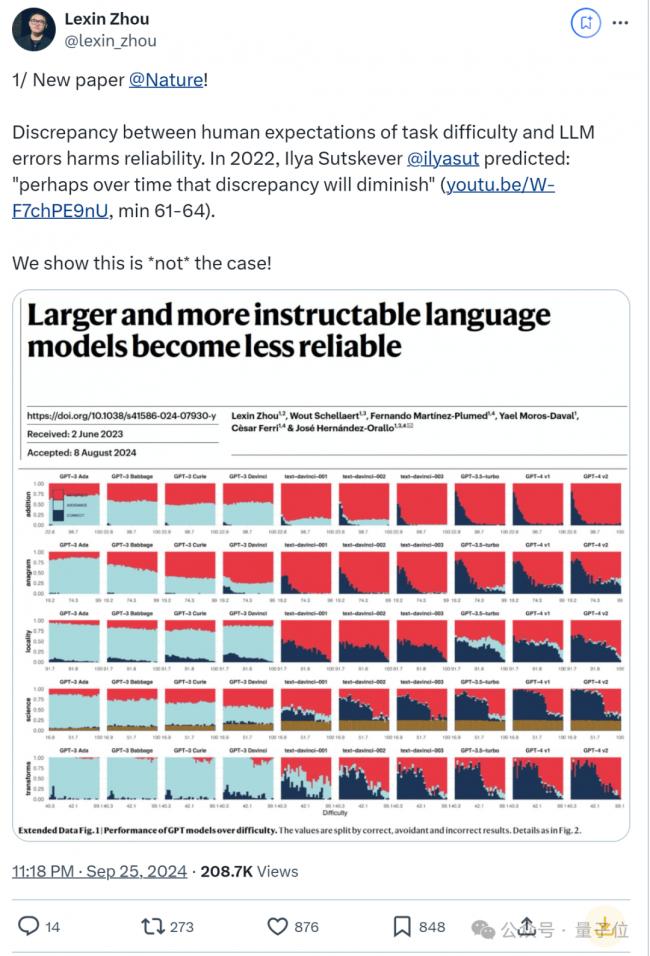
然而這篇論文發現情況並非如此。不止GPT,LLaMA和BLOOM系列,甚至OpenAI新的 o1模型和Claude-3.5-Sonnet也在可靠性方面令人擔憂。
更重要的是,論文還發現依靠人類監督來糾正錯誤的做法也不管用。

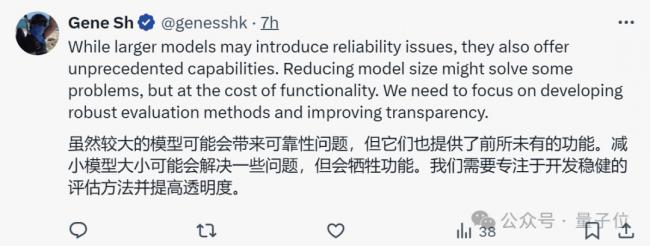
有網友認為,雖然較大的模型可能會帶來可靠性問題,但它們也提供了前所未有的功能。
我們需要專注於開發穩健的評估方法並提高透明度。
[加西網正招聘多名全職sales 待遇優]
好新聞沒人評論怎麼行,我來說幾句
簡單來說,論文發現:更大且更遵循指令的大模型也變得更不可靠了,某些情況下 GPT-4在回答可靠性上還不如GPT-3。
與早期模型相比,有更多算力和人類反饋加持的最新模型,在回答可靠性上實際愈加惡化了。
結論壹出,立即引來20多萬網友圍觀。
在Reddit論壇也引發圍觀議論。
這讓人不禁想起,壹大堆專家/博士級別的模型還不會“9.9和9.11”哪個大這樣的簡單問題。
關於這個現象,論文提到這也反映出, 模型的表現與人類對難度的預期不符。
換句話說,“LLMs在用戶預料不到的地方既成功又(更危險地)失敗”。
Ilya Sutskever2022年曾預測:
也許隨著時間的推移,這種差異會減少。
然而這篇論文發現情況並非如此。不止GPT,LLaMA和BLOOM系列,甚至OpenAI新的 o1模型和Claude-3.5-Sonnet也在可靠性方面令人擔憂。
更重要的是,論文還發現依靠人類監督來糾正錯誤的做法也不管用。
有網友認為,雖然較大的模型可能會帶來可靠性問題,但它們也提供了前所未有的功能。
我們需要專注於開發穩健的評估方法並提高透明度。
[加西網正招聘多名全職sales 待遇優]
| 分享: |
| 注: | 在此頁閱讀全文 |
| 延伸閱讀 | 更多... |
推薦: